强化学习全新里程碑,登顶Nature正刊!作者提出了一种通用强化学习模型,解决了传统方法对人工调参的依赖,使数据效率飙升1000%!
不仅如此,在Science、NerurIPS等顶会顶刊,也都有诸多成果。像是性能提升48.3%的ipp-rl-3d模型、几行代码改个reward,让效果起飞的Passk_Training模型……
其热度可见一斑!主要在于,强化学习不仅应用广泛,更是实现AGI的关键之一。但其也面临诸多局限,对其的改进自然成了迫切需求。
目前热门思路主要有:对其自身改进(层次化RL、多智能体RL、RLHF……);与其他技术结合,像是卡尔曼滤波、注意力、Transformer、LSTM、大模型等。为方便大家研究的进行,我给大家梳理了162种创新思路和源码!

扫描下方二维码,回复「162RL」
免费获取全部论文合集及项目代码

强化学习+注意力机制
AlignSAM: Alig深度之眼整理ning Segment Anything Model to Open Context via Reinforcement Learning
内容:这篇文章提出了一个名为AlignSAM的框架,旨在通过强化学习自动为SAM生成提示,使其能够适应多样化的下游任务。AlignSAM的核心是一个代理(agent),它通过与基础模型的交互,迭代地优化分割预测。该框架引入了一个语义重校准模块,用于为提示提供精确的标签信息,从而提高模型在处理显式和隐式语义任务时的性能。实验表明,AlignSAM在多个具有挑战性的分割任务中优于现有的先进方法,且在保持SAM参数冻结的情况下实现了高效的适应性。

强化学习+卡尔曼滤波
UNCERTAINTY-AWARE TRANSFER ACROSS TASKS USING HYBRID MODEL-BASED SUCCESSOR FEATURE REINFORCEMENT LEARNING
内容:这篇文章提出了一种名为 UaMB-SF的强化学习框架,旨在通过结合模型基(MB)方法和后继特征(SF)方法,实现跨任务的知识迁移和样本高效的学习。该框架利用卡尔曼滤波(KF)的多模型自适应估计来近似环境模型,同时估计模型参数的不确定性,并将其应用于不确定性感知的探索策略中。UaMB-SF能够在不同奖励函数和转移动态的任务之间进行知识迁移,同时保持较低的计算复杂度,并在实验中展示了比现有方法更快的学习速度和更好的样本效率。

强化学习+Transformer
STORM:Efficient Stoc深度之眼整理hastic Transformer based World Models for Reinforcement Learning
内容:这篇文章介绍了一种名为STORM的高效世界模型架构,用于基于模型的强化学习。STORM结合了Transformer的强大序列建模和生成能力以及变分自编码器(VAE)的随机性,通过在Atari 100k基准测试中实现126.7%的人类平均性能,刷新了不使用前瞻搜索技术的最先进方法的记录。此外,STORM在单个NVIDIA GeForce RTX 3090显卡上仅需4.3小时的训练时间,显著提高了训练效率。该方法通过自监督学习构建环境的参数化模拟世界模型,利用模型的想象力来增强智能体的策略,减少对真实环境采样的依赖。
扫描下方二维码,回复「162RL」
免费获取全部论文合集及项目代码

强化学习+大模型
Eureka: Human-Level Reward Design via Coding Large Language Models
内容:这篇文章介绍了一种名为EUREKA的算法,它利用大型语言模型(LLMs)如GPT-4来设计人类水平的奖励函数,用于强化学习中的复杂低级操作任务,例如灵巧的笔旋转。EUREKA通过零样本生成、代码编写和上下文改进能力,执行进化优化以生成奖励代码,这些代码可以用于通过强化学习获得复杂技能。在29个开源的强化学习环境中,EUREKA在83%的任务上超越了人类专家设计的奖励函数,平均性能提升52%。此外,EUREKA还支持一种新的基于人类反馈的强化学习方法,能够将人类输入整合到奖励函数中,以提高生成奖励的质量和安全性。

层次强化学习
Hierarchical Multi-Agent Skill Discovery
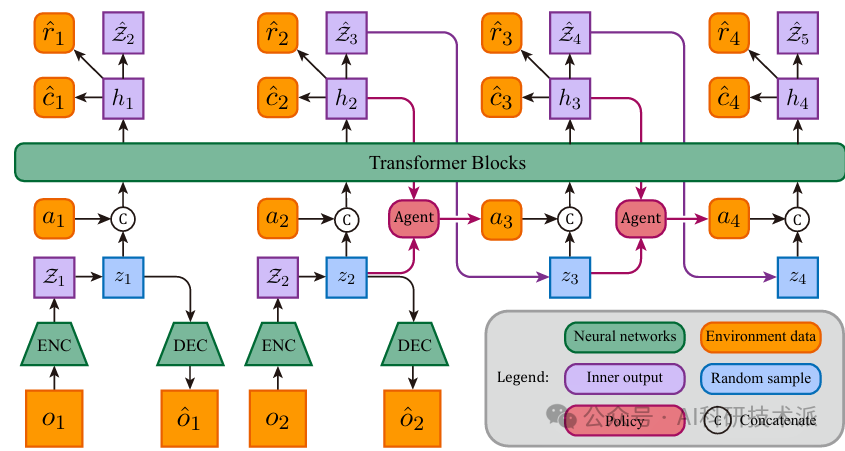
内容:这篇文章介绍了一种名为HMASD的算法,用于在多智能体强化学习(MARL)中发现团队技能和个体技能。HMASD通过将多智能体技能发现问题嵌入到概率图模型(PGM)中,将其转化为一个推理问题,并推导出一个变分下界作为优化目标。该算法采用两层层次结构:高层策略使用Transformer结构进行技能分配,低层策略则学习发现有价值的团队和个体技能。HMASD在稀疏奖励的多智能体基准测试中表现出色,显著优于现有的MARL基线算法。

RLHF
MM-RLHF:TheNextStep Forward in Multimodal LLM Alignment
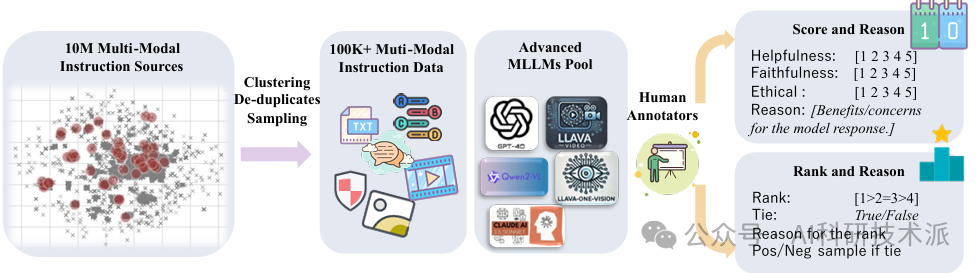
内容:这篇论文介绍了一个名为MM-RLHF的多模态大型语言模型(MLLM)对齐方法。该方法通过构建一个包含12万个人类标注的偏好比较对的数据集,提出了关键创新,如基于批评的奖励模型和动态奖励缩放,以提高奖励模型的质量和对齐算法的效率。实验表明,使用MM-RLHF数据集和对齐算法对LLaVA-ov-7B模型进行微调,可使其对话能力提升19.5%,安全性提高60%。
扫描下方二维码,回复「162RL」
免费获取全部论文合集及项目代码
