
传统视觉模型大多依赖人工标注的大规模数据集,且往往需要为每一个具体任务单独训练。这种方式不仅成本高昂,而且缺乏跨任务的灵活性。
正因如此,我们经常能在最新的具身智能研究论文中看到这样一句话:
“With the development of Vision-Language Models...”——视觉-语言模型(VLMs)的发展,正在深刻改变这一局面。
通过在海量图文对上进行预训练,VLM 学会了视觉与语言之间的深层对应关系,并展现出强大的零样本泛化能力。更重要的是,在具身智能的语境下,VLM 不再只是单纯的感知工具,而是成为机器人“理解—决策—行动”闭环中的关键桥梁:
在 VLN 中,它帮助机器人将语言指令与环境场景对齐;
在 VLA 中,它则进一步承担起从语义理解到动作生成的核心角色。
随之,VLM相关的研究也越来越多:
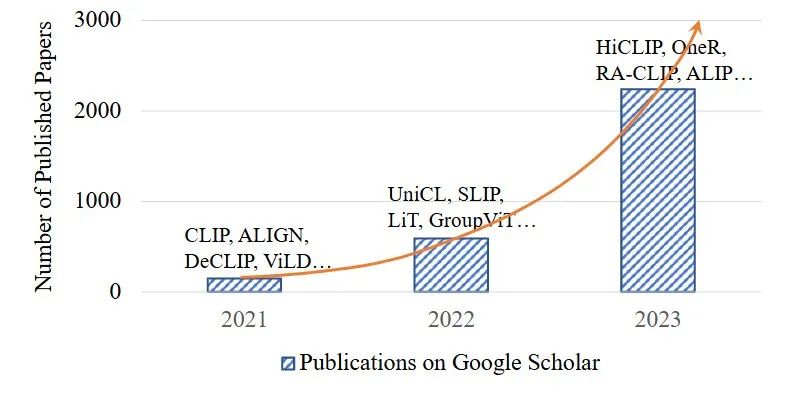
▲图1|Google Scholar上VLM相关论文的发文量统计(从CLIP开始,走出了一个指数上升的趋势)©️【深蓝具身智能】编译
本文将结合VLM的最新动态,系统盘点 VLM 的基础要素——包括主流架构、常用数据集、典型预训练目标与评估方式,并结合 VLN 和 VLA 这两类具身智能中的代表性任务,深入解读 VLM 如何助力机器人迈向更加通用、自然与高效的智能。
注:VLM 是一个体量庞大、发展极其迅速的研究方向,本次盘点尽可能全面,但仍难免有所遗漏或不够深入之处。如果读者朋友们有兴趣进一步拓展,可以参考文末的综述论文作为延伸阅读。同时也非常欢迎大家在评论区补充观点、分享思考,批评指正。

VLM 基础与主流架构
视觉-语言模型(VLM)的核心思想,是通过在大规模图文对上进行预训练,让模型学会图像与文本之间的对应关系,从而在下游任务中实现零样本预测。
换句话说,一个训练好的 VLM,可以在没有特定任务微调的情况下,仅通过比对图像和文本的语义表示,就能完成分类、检索甚至检测与分割等任务。
这篇文章,和大家一起盘点 VLM 中最重要的四个方面:网络架构、预训练目标、预训练框架以及评估与下游任务。
网络架构
VLM 通常由图像编码器和文本编码器组成,用于将输入图像和文本映射到共享的语义空间。
图像特征学习:
CNN 架构:早期方法采用 ResNet、EfficientNet 等卷积网络。其中,ResNet 是最常用的基础结构,研究者在此基础上进一步改进,例如引入 ResNet-D、抗锯齿的下采样操作,以及利用注意力池化来替代全局平均池化。
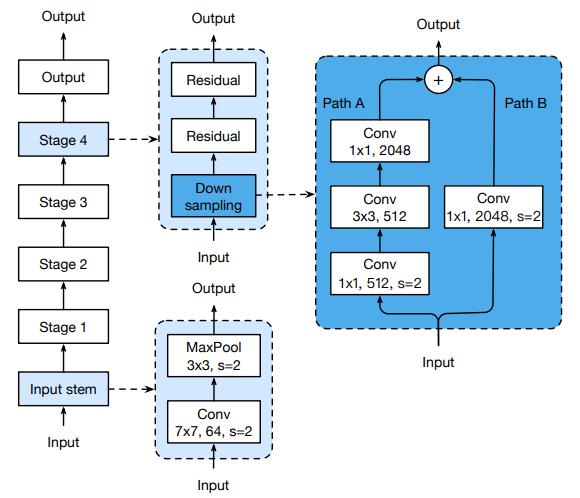
Transformer 架构:近年来,Vision Transformer (ViT) 成为主流选择。它将图像划分为固定大小的 patch,再通过 Transformer 编码器提取特征。研究中也有对 ViT 的改进,例如在编码器前加入归一化层。

文本特征学习:
几乎所有方法都基于 Transformer 及其变体。典型的如 CLIP,直接采用标准 Transformer 结构,或进行轻量化修改(如 GPT-2 风格),用来对自然语言文本进行建模。
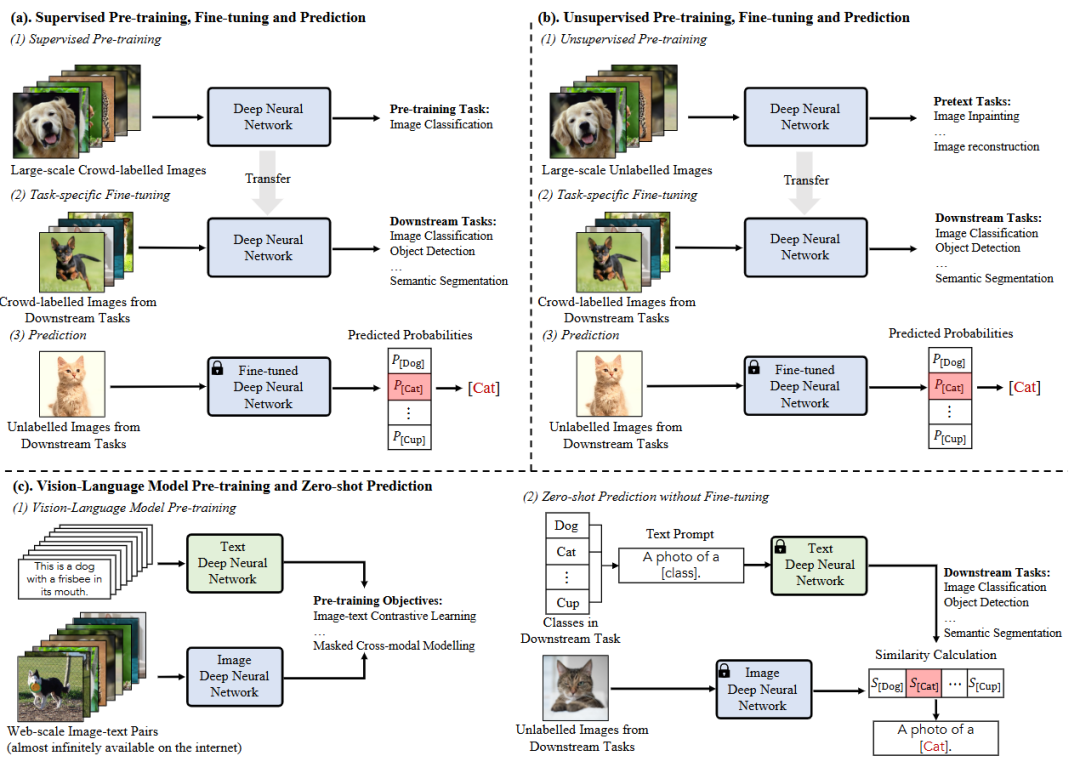
▲图2|视觉识别中的三种DNN训练范式。与(a)和(b)中需要用标注数据对每个特定任务进行微调的方法相比(c)中vlm的新学习范式可以实现对于Web数据的广泛使用和零样本预测©️【深蓝具身智能】编译
预训练目标
为了让模型真正学会视觉与语言之间的相关性,研究者设计了多种预训练任务,大体可分为三类:
(1)对比学习(Contrastive Objectives):
核心思路是“拉近配对,推远不匹配”。最经典的就是 CLIP 的图文对比学习(Image-Text Contrastive),通过 InfoNCE 损失来对齐图像与文本的表示。
(2)生成式目标(Generative Objectives):
要求模型在遮挡或缺失的情况下重建内容,包括 Masked Image Modeling、Masked Language Modeling,以及跨模态的 Masked Cross-Modal Modeling。同时也包括从图像生成文本、或从文本生成视觉特征的任务。
(3)对齐目标(Alignment Objectives):
不仅关注全局的图文匹配,还涉及更细粒度的 region-word 匹配(局部区域与单词的对齐),以便服务于检测和分割等任务。

预训练框架
VLM 的训练框架主要有三种:
(1)Two-tower 框架:
图像和文本分别通过独立的编码器处理,最终在语义空间对齐(如 CLIP)。
(2)Two-leg 框架:
在双编码器的基础上增加多模态融合层,让图像和文本在训练阶段就进行交互。
(3)One-tower 框架:
尝试在同一个编码器里统一建模视觉和语言信息,以提升模态间的通信效率。

▲图3|常见的VLM预训练框架©️【深蓝具身智能】编译
评估与下游任务
综述中总结了常见的两类评估方式:
(1)零样本预测(Zero-shot Prediction):直接将预训练好的 VLM 应用于下游任务。例如:
图像分类:通过 prompt 工程,将类别转化为文本描述,与图像 embedding 匹配。
语义分割:像素级 embedding 与文本对齐。
目标检测:利用辅助数据集的能力,通过 proposal 与文本匹配实现检测。
图文检索:进行 text-to-image 或 image-to-text 的跨模态检索。
(2)线性探针(Linear Probing):冻结 VLM 的参数,只在其特征之上训练一个简单的线性分类器,以评估模型的表示能力。

VLM的数据集与基准
要让视觉-语言模型真正具备理解图像和语言的能力,首先需要足够的数据。
相比传统依赖人工标注的数据集(如早期的图像分类任务),VLM 更强调从“大规模图文对”中学习。这类数据通常来自互联网,既数量庞大,又涵盖了丰富多样的语义表达。
预训练数据集
目前主流的 VLM 都依赖于大规模的图文对数据集进行预训练。这些数据动辄上亿,来源包括网页、开源图片平台和社交媒体。这样的数据规模让模型能够捕捉跨模态的通用关联。
一些方法还会额外引入少量人工标注的数据集,帮助模型在目标检测、语义分割等细粒度任务上获得更强的能力。

▲图4|VLM训练中常用的图像-文本对应数据集©️【深蓝具身智能】编译
评估数据集
如果说预训练数据是模型的“教材”,那么评估数据就是它的“考试”。研究者们建立了多个维度的测试基准:
图像分类:涵盖从细粒度识别到大规模通用分类等不同层次;
目标检测与语义分割:考察模型是否能定位和解析图像中的具体物体;
图文检索:测试模型在跨模态检索中的能力,例如“以文找图”或“以图找文”;
动作识别:进一步拓展到视频和时序场景,检验模型对动态事件的理解能力。
通过这些任务,可以全面评估 VLM 的泛化性和跨任务适应能力。特别是常见的 零样本测试,只需输入图像和文本,不做任何额外训练,就能直接验证模型的表现,这也是它在具身智能领域备受青睐的重要原因。

▲图5|常用于VLM评估的数据集汇总©️【深蓝具身智能】编译

VLM 的预训练目标
在真正进入应用场景之前,视觉-语言模型首先要经历“大规模的自我学习”。这一学习过程,就是通过预训练来建立图像和语言之间的关联。
当前主流的 VLM 预训练大体分为三类目标:对比学习(contrastive)、生成学习(generative)和匹配对齐(alignment)。
对比学习:让模型学会区分
对比学习的核心思想是“拉近正确的图文对,推远错误的图文对”。这样,模型就能逐渐学会在海量图文数据中,找出真正语义相关的匹配关系。
这种机制不仅帮助模型在分类、检索任务中表现突出,也奠定了零样本预测的能力。
在视觉模态内部,可以通过对比目标增强图像特征的判别力;
在跨模态之间,通过图文对比,模型逐步掌握语言描述与视觉内容的对应关系;
甚至还可以把图像的类别标签也纳入对比学习,从而同时学到更细致的判别能力。
对比学习的优势是特征判别性强,缺点是需要设计合适的正负样本,以及控制超参数,这会带来一定挑战。

▲图6|VLM图文对比学习框架示意图©️【深蓝具身智能】编译
生成学习:让模型学会重建
生成学习的思路是“遮住一部分,再让模型自己补回来”。
在图像侧,模型通过遮挡图像块再去重建,迫使自己理解上下文;
在文本侧,模型通过掩码语言建模来恢复被遮住的词语;
在跨模态侧,可以同时遮住图像和文本的一部分,让模型去推断完整信息;
还有一种方式是让模型直接把图像“翻译”成文字,即自动生成描述性文本。
这些生成目标帮助模型学到更丰富的上下文知识,因此常常与其他预训练目标结合使用,以增强语义理解和跨模态关联。

▲图7|一个通过遮挡图像并让图像自行重建从而学习理解上下文的框架©️【深蓝具身智能】编译
匹配对齐:让模型学会判断真假
对齐目标强调的是“判断一对图文是不是配对的”。
这种方式更直接,通常用来训练模型具备快速的配对判断能力:
全局匹配:看整张图和整段文字是否对应;
局部匹配:更细致地把图像中的局部区域与文本中的词语对应起来。
全局匹配让模型在图文检索等任务中很有优势,而局部匹配则为检测、分割等任务提供了细粒度的语义支撑。

▲图8|图文全局匹配的框架示意图©️【深蓝具身智能】编译
小结
可以把这三类目标理解为 VLM 的“学习三步曲”:
对比:拉近和推远,学会判别;
生成:遮挡和补全,学会推理;
对齐:真假配对,学会匹配。
在实际的模型训练中,这些目标往往不是单独使用,而是结合在一起。通过互补,VLM 才能同时具备全局和局部、判别和生成的多重能力。

VLM助力具身智能视觉任务
前面我们盘点了 VLM 的核心构成:大规模图文数据、预训练目标与常见方法。可以把它们理解为“语言+视觉”的通用底座。
在这一环节完成之后,VLM 就不再只是一个静态的模型,而是可以真正被部署到机器人系统中,成为感知与决策的“大脑”。
那么,VLM 在具身智能领域究竟能做什么?
最典型的两个方向就是视觉-语言导航(VLN)和视觉-语言-动作(VLA)。
VLN:让机器人听懂一句自然语言指令,比如“走到书架旁边”,并通过视觉感知找到目标位置并导航过去。
VLA:不仅要看懂和理解,还要把理解转化为具体的动作,比如“拿起桌上的杯子”,这需要模型在视觉与语言的基础上直接生成动作序列。
这两个任务,正好代表了从“认知”到“操作”的完整链路:
前者强调在环境中找到目标,后者则进一步强调与环境的交互。它们也成为了检验 VLM 能否真正助力具身智能的关键试金石。
接下来,我们就以 VLN 和 VLA 为例,看看 VLM 是如何推动机器人在复杂环境中实现自主感知、理解与行动的。
VLM 在 VLN 中的作用
在具身智能中,视觉-语言导航是最具代表性的任务之一。
它要求机器人根据自然语言指令,在复杂环境中感知、理解并找到目标位置。看似简单的一句话指令,比如“从走廊穿过客厅,去到沙发旁边”,实际上涉及到语言理解、场景感知、路径规划等多个环节。
传统方法往往将语言理解和视觉感知分开处理,再通过规则或手工设计的策略拼接。但在多变和复杂的真实环境中,这种方式往往力不从心。VLM 的引入,使得这一任务出现了新的可能。
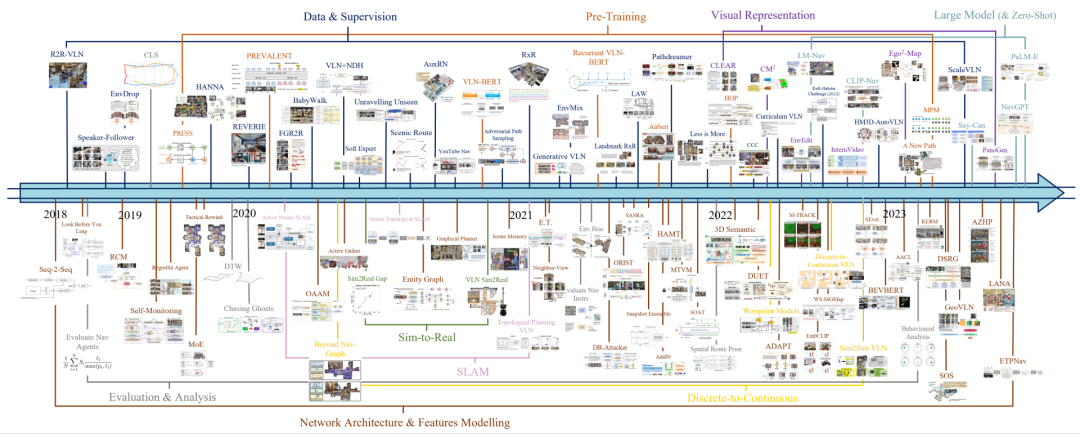
▲图9|VLN的发展脉络:可以清晰的看到正是通用能力极强的VLM模型CLIP发布之后,VLN才逐步“兴起”©️【深蓝具身智能】编译
相关阅读:10年VLN之路:详解具身智能「视觉-语言-导航」三大技术拐点!
第一,VLM 提供了自然语言与视觉语义的统一表达
通过在大规模图文数据上预训练,VLM 学会了如何将“沙发”“走廊”这样的语言描述与视觉场景中的对象或区域对应起来。
这样,机器人接收到指令后,可以直接把语言目标投射到视觉空间中,大幅降低了语言到感知的“翻译成本”。
第二,VLM 增强了目标检索与环境理解的能力
在导航过程中,机器人需要不断确认目标是否出现在当前视野中。VLM 能够为图像画面中的各个区域打分,并与语言目标进行匹配。
这种能力不仅支持零样本场景(即模型从未见过的环境),还让机器人在面对模糊描述时具备更强的泛化能力。
第三,VLM 为规划与行动提供了语义引导
在具备语义匹配能力后,机器人可以在地图或空间表示中标注出与目标相关的区域,从而将路径规划与语义信息结合。
例如,机器人不再仅仅依赖几何上的最短路径,而是能够优先选择那些更可能接近目标的方向。
总体来看,VLM 在 VLN 中起到的作用就像是一座“桥梁”:它让语言和视觉真正贯通,从而帮助机器人听懂人类的指令,并在复杂环境中找到正确的方向
VLM 在 VLA 中的作用
如果说视觉-语言导航是让机器人“走到哪儿去”,那么视觉-语言-动作(VLA)则是进一步回答“到了之后做什么”。
这一任务要求机器人不仅能理解环境和语言,还能将理解直接转化为一连串动作指令,实现与环境的交互。比如,“拿起桌上的水杯递给我”这样一句话,包含了目标识别、物体定位、操作动作生成等多个环节。

▲图10|VLA方法的核心框架:框架中左侧的多模态数据(Multimodal Data)就是通过VLM来进行编码处理的©️【深蓝具身智能】编译
第一,VLM 提供了跨模态的语义对齐能力
通过在大规模图文数据上学习,VLM 能够把“水杯”“书本”这样的语言描述,与视觉场景中的具体对象对齐。
这种统一的语义空间为动作生成奠定了基础——机器人首先要知道“目标是什么”,才能进一步思考“如何操作”。
第二,VLM 支持语言条件下的动作理解与生成
与 VLN 偏向于“目标定位”不同,VLA 更强调“任务执行”。在这一过程中,VLM 可以作为语义感知层,将自然语言转化为高层语义目标,再结合下游的策略模型或控制器,生成可执行的动作序列。
例如,听到“把书放到桌子上”,VLM 能够帮助识别“书”和“桌子”,并把二者之间的关系传递给动作规划模块。
第三,VLM 赋予机器人更强的泛化和适应性
现实世界的任务往往是开放且不可预测的,机器人不可能依赖固定的脚本来完成所有动作。VLM 的优势在于它能够理解从未见过的语言描述,并将其与视觉场景联系起来,从而支持零样本或少样本的操作任务。
这意味着,即便机器人从未专门训练过“把水果放进篮子里”,它也可能凭借跨模态的语义理解完成这一任务。
可以说,VLA 是具身智能的关键落脚点之一,而 VLM 的引入则让这一目标从“看得见”迈向了“做得到”。它使机器人不仅能感知与理解世界,还能基于语言和视觉的融合,真正与世界互动
VLM 赋能具身智能的核心价值
无论是 VLN 的目标定位,还是 VLA 的任务执行,它们都展现出同一个趋势:
VLM 已经成为机器人理解世界和行动的重要基石。
通过统一视觉与语言的语义表达,VLM 打破了感知和指令之间的壁垒,让机器人能够从自然语言中直接获取环境目标和操作需求。它既提升了导航与检索的准确性,也增强了任务执行的灵活性和泛化能力。
换句话说,VLM 让机器人从“看懂”到“做到”之间的距离大大缩短,也让具身智能在真实世界中的应用变得更加可行和高效。

总结
从“看得见”到“做得到”,VLM 已经成为具身智能中最关键的拼图之一。它让机器人能够听懂人类的语言,理解复杂的场景,并将这些理解转化为实际行动。
从 VLN 到 VLA,VLM 的能力正一步步推动机器人走向真正的自主与智能。未来,随着模型规模的扩展和训练方法的演进,VLM 还会带来更多惊喜。或许在不远的将来,我们就能看到真正意义上“能听会看、能理解会操作”的机器人伙伴出现在身边。
编辑|阿豹
审编|具身君
Ref:
工作投稿|商务合作|转载:SL13126828869(微信号)
>>>现在成为星友,特享99元/年<<<

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

商务合作扫码咨询

机器人、自动驾驶、无人机等研发硬件

关于我们:深蓝学院北京总部于2017年成立,2024年成立杭州分公司,2025年成立上海分公司。
学院课程涵盖人工智能、机器人、自动驾驶等各大领域,开设近100门线上课程。拥有多个实训基地助力教学与科研,多台科研平台硬件设备可供开展算法测试与验证。
服务专业用户数达11万+(人工智能全产业链垂直领域的高净值用户),硕博学历用户占比高达70%。已与多家头部机器人企业、头部高校建立深度合作,深度赋能教育 、企业端人才培养与匹配。
工作投稿|商务合作|转载:SL13126828869


点击❤收藏并推荐本文