
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
OpenAI 和 Google 的研究者们总结了 Agentic Deep Researcher 的几大优势:(1)深入的问题理解能力(Comprehensive Understanding):能够处理复杂、多跳的用户提问;(2)强大的信息整合能力(Enhanced Synthesis):能够将广泛甚至冲突的信息源整合为合理的输出;(3)减轻用户的认知负担(Reduced User Effort):整个 research 过程完全自主,不需要用户的过多干预。
现存最先进的 Agentic Deep Research 系统往往基于由可验证结果奖励指导的强化学习训练,尽管该训练范式带来了显著的性能收益,但仍存在以下核心问题:
梯度冲突(Gradients Conflicts):在基于可验证结果奖励的强化学习范式中,即使中间的推理过程或研究策略是有效的,只要最终答案错误,整个推理轨迹都会受到惩罚。这种粗粒度的奖励设计在中间推理步骤与最终答案之间引入了潜在的梯度冲突,阻碍了模型发现更优的推理能力和研究策略,从而限制了其泛化能力
奖励稀疏(Reward sparsity):基于结果的强化学习仅依赖最终答案生成奖励,导致每个训练样本只能提供稀疏的反馈信号。这严重限制了策略优化的效率,因为它增加了对更大规模训练数据和更长训练周期的依赖。
以上两个限制限制了 Agentic Deep Research 系统的性能上线,为决解这两大限制,来自蚂蚁安全与智能实验室团队提出了 Atom-Searcher,进一步推动了 Agentic Deep Research 系统的性能边界。

论文标题:Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward
论文:https://arxiv.org/abs/2508.12800
Github: https://github.com/antgroup/Research-Venus
Huggingface: https://huggingface.co/dikw/Atom-Searcher

方法介绍
本研究提出了一种创新性的 Agentic Deep Research 系统训练框架 Atom-Searcher,结合监督微调(SFT)与基于细粒度奖励的强化学习构建强大的 Agentic Deep Research 系统。
与现存 Agentic Deep Research 训练框架相比,Atom-Searcher 创新地提出了 Atomic Thought 推理范式,引导 LLM 进行更加深入、可信和可解释的推理;然后引入 Reasoning Reward Model(RRM)对 Atomic Thought 式的推理过程进行监督,构建细粒度的 Atomic Thought Reward(ATR);进而提出一种课程学习启发的奖励融合策略将 ATR 与可验证结果奖励进行聚合;最后基于聚合奖励进行强化学习训练。

Atomic Thought 推理范式

针对 Agentic Deep Research 系统中 LLM 生成的推理轨迹(<think>)包含过多冗余 tokens 且推理深度欠缺的问题,Atomic Thought 范式将 <think> 分解为更加细粒度的 “功能单元”,如 <Verification>、<hypothesis > 等,该范式有助于引导 LLM 的推理过程更加符合人的认知行为,且高度模块化的方式能大大减少无意义 tokens。更进一步,为激发 LLM 自主将 < think > 分解为 Atomic Thoughts(<Verification>、<hypothesis > 等)的能力,作者们精心构建了 1000k 高质量 Atomic Thought 指令微调数据,对 LLM 进行 SFT。
细粒度 Atomic Thought Reward 构建
在 Agentic Deep Research 系统中,直接使用 Reasoning Reward Model(RRM)对推理过程进行监督,往往因为 < think > 中的低信噪比(过多冗余 tokens)而效果不佳。而 Atomic Thought 的提出,很好地解决了该问题,除了减少了 < think > 中的冗余 tokens,Atomic Thoughts(<Verification>、<hypothesis > 等)还为 RRM 提供了监督锚点,清晰的模块化结构使得 RRM 能够准确地评估每个功能单元的质量。因此,作者们引入 RRM 对 Atom-Thoughts 进行监督,从而得到细粒度的 Atomic Thought Reward,用于缓解强化学习训练中的梯度冲突和奖励稀疏问题。
课程学习启发的奖励聚合策略
基于可验证结果的奖励的 Agentic Deep Research 系统之所以存在梯度冲突问题,是由于基于结果的奖励在 token 级别的奖励分配上过于粗糙。具体来说,它将中间推理步骤的正确性完全归因于最终答案,常常在不考虑各步骤实际贡献的情况下对其进行奖励或惩罚。这种错位在优化过程中会引发梯度冲突。为解决这一问题,我们将 ATR 与结果奖励相结合,利用 ATR 作为辅助信号来校准结果奖励,从而缓解梯度冲突。
然而,使用静态的奖励加权系数无法与训练动态保持一致。具体而言,在训练初期,模型能力尚有限,难以生成完全正确的答案,但更有可能探索出对最终正确解有贡献的有用 “原子思维”。如果此阶段仅依赖基于结果的奖励,这些有益的原子思维可能因最终答案错误而遭到不公正的惩罚;相反,一些有害的原子思维也可能被错误地强化,导致严重的梯度冲突,因而需要 ATR 进行较强的校准。随着训练的推进,模型能力逐步提升,其推理轨迹与正确答案的对齐程度也日益提高。因此,梯度冲突逐渐减弱,而来自 ATR 的过度校准可能会引入不必要的噪声,反而损害最终的准确性。
强化学习训练
基于混合奖励,本文采用了 GRPO 算法进行强化学习训练。并使用了 Loss Masking 策略保证训练的稳定性。具体而言,在原始的 GRPO 框架中,损失函数会计算整个推理路径中所有 token 的梯度。但在 Atom-Searcher 中,模型的输出路径包含由外部环境检索得到的内容(如搜索结果),这些内容不是模型生成的,也不可训练。为了避免模型在训练时被这些静态、不可控的内容误导,本文采用了 Loss Masking 机制,将检索结果部分的 token 排除在损失计算之外。
实验效果
主实验
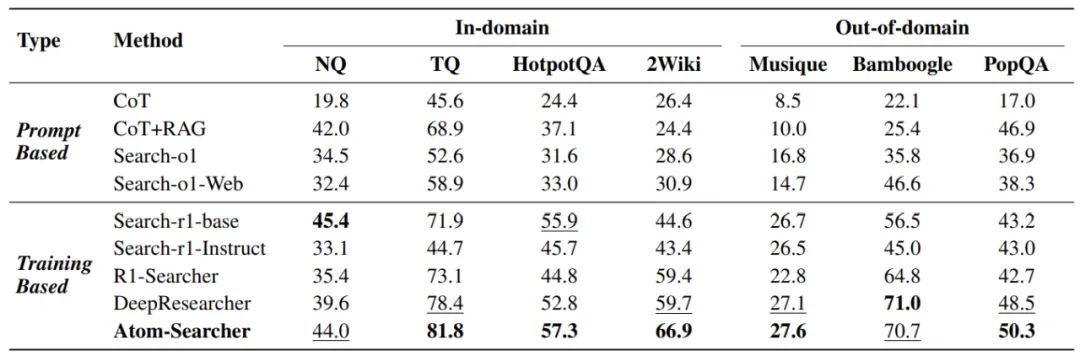
Atom-Searcher 在 In-Domain 和 Out-of-Domain 上的性能表现均十分亮眼。在 In-Domain Benchmarks (NQ、 TQ、HotpotQA、2Wiki)上 Atom-Searcher 相较于最优 baseline——DeepResearcher 取得了 8.5% 的平均性能提升,在 Out-of-Domain Benchmarks(Musique、 Bamboogle、 PopQA)上 Atom-Searcher 相较于最优 baseline——DeepResearcher 取得了 2.5% 的性能提升。
消融实验
作者们证明了 Atom-Searcher 中 Atomic Thought 范式和 ATR 的贡献,并证明了相较于传统的 < think > 推理范式 Atomic Thought 范式为 RRM 提供了有效的监督锚点,从而带来了性能提升

案例分析
作者们通过案例分析对比了 Atom-Searcher 与最优 baseline——DeepResearcher 的推理过程。展示了 Atom-Searcher 的优势:(1)Atom-Searcher 在其推理过程中自主生成了 Atomic Thoughts,展现出更接近人类的认知行为,例如问题分析、提出解决方案假设、预测错误以及规划下一步操作,使其推理过程更加深入且清晰;(2)Atom-Searcher 会触发更多的搜索调用,从而获取更丰富的外部信息,以确保答案的正确性。这些优势表明,Atom-Searcher 在更复杂的 Deep Research 任务中具有巨大潜力。

投递 0 限制:简历可多次投递,心仪岗位大胆冲!
100+ 职位,赛道超丰富,细分方向任你选!
顶级科研平台与资源:超大规模算力集群,PB 级数据,亿级研发投入! 清晰的职业发展通道:由实验室出题,为你链接顶尖高校、科研机构和行业企业!
扫描下方二维码即可投递简历。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










