点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享一篇基于大语言模型(LLM)的智能体
(Agent)推理框架系统性综述,针对当前 LLM 智能体领域 “边界模糊”、“价值低估”的问题,首次以 “框架层面推理方法” 为核心视角,填补了该方向系统性综述的空白,为研究社区提供统一的分析基准。投稿作者为大模型之心特邀嘉宾,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→大模型技术交流群
>>点击进入→Agent技术交流群
写在前面

从微软的AutoGen到“AI程序员”Devin,基于大语言模型(LLM)的智能体(Agent)正以前所未有的速度重塑人工智能的边界。它们会分解任务、推演计划、调用工具、彼此协作——似乎把“机器推理”带入了一个新的时代。
然而,在这股浪潮之下,一个核心的“双重模糊性”问题日益凸出:一个Agent的优秀表现,究竟是归因于背后更强的模型,还是来源于其“框架级”的设计?这种不确定性,使得对不同技术进行横向比较变得异常困难,也让我们容易忽视框架设计在Agent能力构建中的基石作用。

本综述全面梳理了智能体系统的框架级推理的方法、场景和评估策略。

方法论:以“形式化语言”为根基,为混乱的Agent框架建立统一理论 尽管社区中关于Agent的讨论非常活跃,但其工作往往呈现出碎片化、术语不一的局面。本综述的首要创新,便是引入了一套统一的形式化语言与通用推理算法,首次将各类“免训练”的框架级推理过程进行了数学化、结构化的描述。

这套体系将Agent的行为抽象为推理、工具调用、反思等基本动作,使得原本五花八门的设计(如ReAct, AutoGen等)可以被映射到同一个流程中进行严谨的比较与复现,为整个领域从“经验化”走向“科学化”提供了理论基石。在统一的理论基础之上,综述进一步提出了一个清晰、递进的三层方法论分类体系,系统性地解构了现有Agent框架的设计范式。
第一层:单智能体方法 (Single-agent Methods) —— 让个体更强大
这一层聚焦于如何让单个Agent的“认知”与“决策”能力得到增强,主要分为两大路径:
提示工程 (Prompt Engineering) :通过外部引导来“激活”Agent的潜能。这包括赋予其特定身份的角色扮演(如“你是一位资深软件工程师”)、描述其工作环境与可用工具的环境模拟、以及提供范例供其模仿学习的情境学习 (In-context Learning)。

自我改进 (Self-improvement) :让Agent通过“内省”实现自我进化。这包括对历史行为进行复盘总结的反思 (Reflection)机制;在单次任务中不断生成、评判、修正产出的迭代优化 (Iterative Optimization);以及在与动态环境交互中自主提出新目标的交互式学习 (Interactive Learning),这也是像Voyager这类游戏AI实现开放式探索的关键。


第二层:基于工具的方法 (Tool-based Methods) —— 突破原生边界

LLM本身存在知识过时、无法联网、无法执行代码等固有缺陷。工具的引入极大地扩展了Agent的能力边界,使其能够与真实世界交互。综述将工具的使用过程系统性地拆解为三个关键环节:
工具集成 (Tool Integration) :这是工具使用的前提,即如何将工具接入Agent系统。文章总结了三种主流模式:通过标准化接口调用的API模式(如调用搜索引擎);作为内置组件直接运行的插件模式(如在检索增强生成RAG中集成向量数据库);以及通过一个“操作系统”来屏蔽底层复杂性的中间件模式。
工具选择 (Tool Selection) :面对琳琅满目的工具箱,Agent如何挑选最合适的一个?这包括了完全依赖LLM自身推理能力的自主选择;通过预设规则进行匹配的基于规则选择;以及在与环境的交互中通过试错和反馈来动态调整策略的基于学习选择。
工具利用 (Tool Utilization) :选定工具后,如何最高效地使用它?综述归纳了三种模式:将多个工具按顺序依次调用的序列式利用;为提升效率而一次性并行调用多个工具的并行式利用(如LLM-Tool Compiler);以及在一个步骤内反复与某个工具交互直至完美的迭代式利用(如Agent反复调试代码直至解释器成功运行)。
第三层:多智能体方法 (Multi-agent Methods) —— 发挥集体智慧
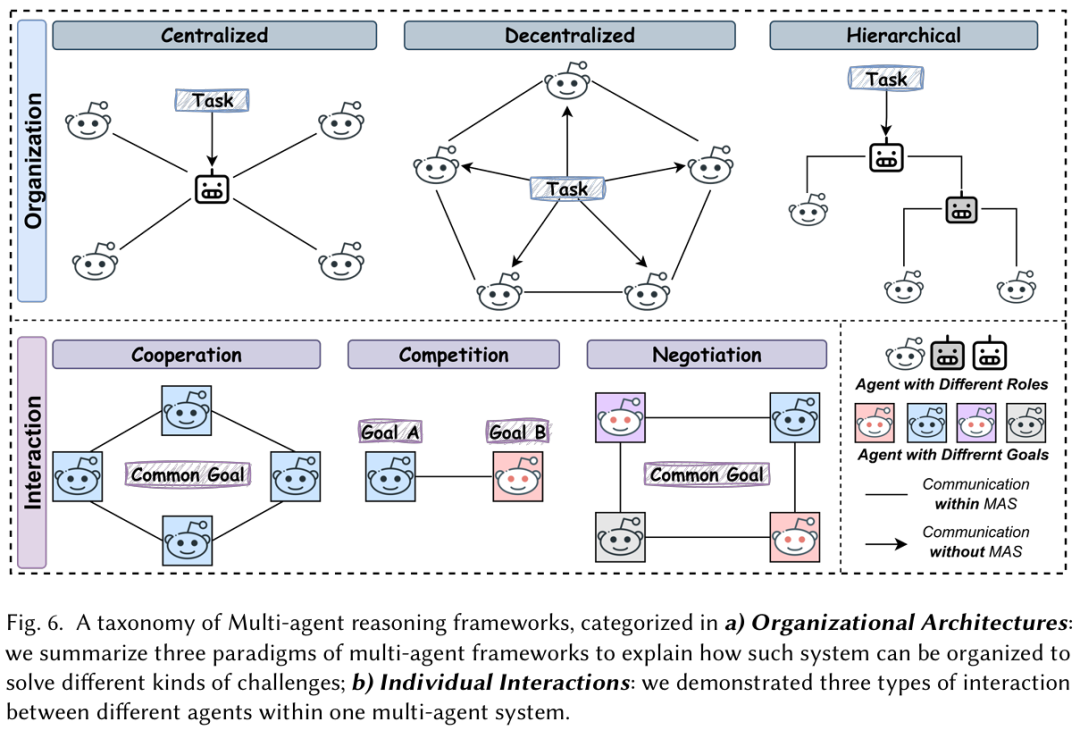
当任务复杂度超出单个Agent的能力时,就需要多个Agent协同作战,“分而治之”的核心在于如何有效协调。文章从两个维度进行了剖析:
组织架构 (Organizational Architecture) :Agent团队是如何构成的?可以是有一个“领导”进行任务分配的中心化结构;也可以是所有成员地位平等、互相讨论的去中心化结构(如同圆桌会议);还可以是模拟真实公司、层级分明的层级化结构。
交互模式 (Individual Interaction) :Agent之间如何互动?可以是为共同目标努力的合作 (Cooperation);也可以是为了提升最终结果鲁棒性而进行辩论的竞争 (Competition);还可以是在冲突与合作间寻求共识的协商 (Negotiation)。 文中进一步用方法论框架,解构了现有领域内的通用agent推理框架

场景:深入四大前沿场景,绘制理论落地的实践蓝图
本综述的核心价值,体现在对Agent在真实世界应用中的系统性剖析。文章将视野从抽象的方法论无缝切换到具体的实践,深入探究了Agent框架如何在以下四大前沿领域落地生根。

科学发现:Agent正成为“AI科学家”的雏形。综述不仅涵盖了在数学领域进行自动化定理证明(如LeanAgent),在天体物理学中进行宇宙学参数分析,更深入到了生物化学领域,剖析了如BioDiscovery-Agent如何通过迭代式学习自主设计基因扰动实验,以及PharmAgents等多智能体系统如何模拟完整的药物研发管线。

医疗健康:Agent正在从辅助诊断走向临床管理的全流程。文章详细梳理了从MedAgents这类通过多专家“会诊”进行零样本推理的诊断助手,到Agent Hospital这样能够让Agent在模拟医院中自主“行医”并从成功与失败案例中不断进化的前沿探索。

软件工程:Agent的目标是实现软件开发全生命周期的自动化。综述介绍了如MetaGPT这样模拟人类软件公司标准作业流程(SOPs)进行团队协作的框架,以及SWE-Agent这类开创性的工作,它通过构建“人-机接口”(ACI),让Agent能像人类一样直接在代码仓库中进行文件编辑、执行测试等操作。
社会与经济模拟:Agent为我们观察复杂的社会经济现象提供了前所未有的“沙盒”。从Generative Agents在虚拟小镇中模拟人类的日常行为,到StockAgent这类大规模系统在模拟环境中复现真实的股票市场撮合机制,再到SocioVerse这样基于千万级真实用户数据构建的“世界模型”,Agent正在成为社会科学研究的强大新工具。

在每个场景下,综述都系统性地归纳了其主流的架构模板、技术侧重点,并详尽地收集和整理了该领域下的主流评测方法、基准(Benchmark)和数据集,为后来者提供了极其宝贵的实践指南。



总结与展望
这篇综述不仅为研究者提供了一套理解和分析框架级推理的理论“语法”,也为开发者绘制了一幅理论在真实场景中落地的应用“蓝图”。它清晰地回答了当前Agent系统的能力边界在何处,并为领域未来的发展,如实现开放式自主学习、构建动态推理框架、确保伦理与安全等,指明了方向。
参考
论文标题: LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios
通讯单位:北京交通大学、兰卡斯特大学、马克思-普朗克信息研究所(马普所)、电子科技大学
论文链接: https://arxiv.org/pdf/2508.17692
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!
