点击下方卡片,关注“具身智能之心”公众号
作者丨Pengxiang Ding等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
出发点与提出背景
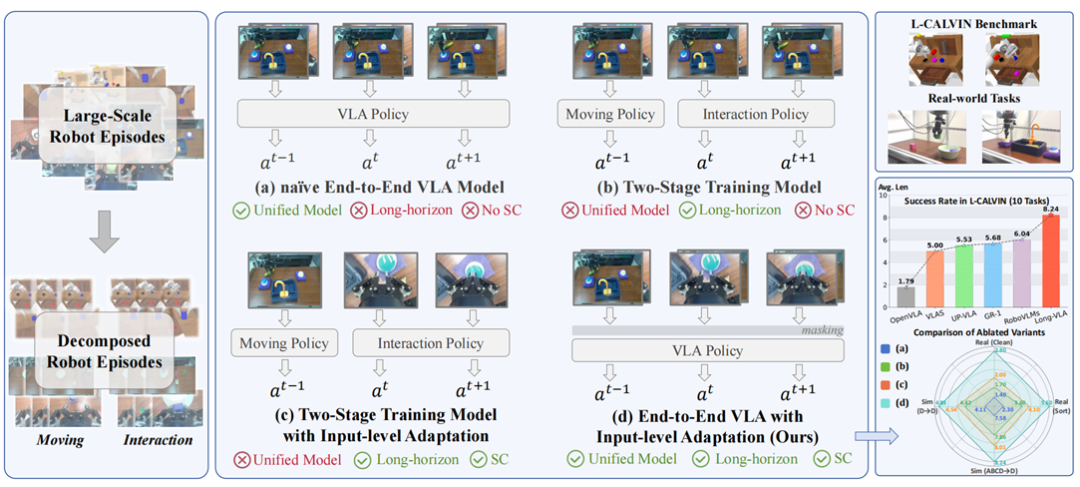
VLA能够利用大规模多模态数据,在近年来逐渐成为机器人学习领域的重要方法。然而,当需要多个任务连续执行时,现有 VLA 模型的效果大幅下降,主要在于长时任务的技能链问题:即子任务之间的衔接不稳定,导致误差逐步累积。
我们提出了Long-VLA,是首个专门针对长时任务设计的端到端 VLA 模型。其核心创新在于引入阶段感知的 输入掩码,将子任务划分为“移动阶段”和“交互阶段”,并在不同阶段动态调整视觉模态输入,使模型能够在移动时关注全局空间线索,在交互时聚焦局部精细感知。通过这种方式,Long-VLA 在保持统—架构和端到端学习优势的 同时,有效解决了技能链问题。实验结果显示,无论在仿真环境还是真实机器人平台上,Long-VLA 都显著超越现有方法,确立了新的性能基准,在机器人长时任务研究中具有突破意义。
标题:Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation
链接:https://arxiv.org/abs/2508.19958
技术介绍
在机器人长时任务中,现有技术大体分为三类:—是端到端统—模型,其能够在短时任务中高效学习,但对长时复杂任务无能为力,尤其在技能链处理上表现不佳;二是任务分解方法,通过将任务拆分为多个子目标并由独立策略 完成,这类方法降低了学习复杂度,但子任务之间缺乏协调,常导致状态漂移和误差累积;三是输入适配地模块化 方法,分别处理运动规划与执行,虽—定程度上缓解了技能链问题,但与 VLA 的统—、数据驱动学习范式相冲突,难以扩展。
与之相比,本文提出的 Long-VLA 兼具统—性与适应性:它在单—架构内实现了任务分解的优势,并通过输入级掩码策略动态调整感知模态,从而在不同阶段聚焦关键信息。与基于奖励驱动的在线优化方法相比,Long-VLA 不依赖在线信号,因而更契合 VLA 的离线大规模训练范式;与模块化方法相比,Long-VLA 保持了端到 端特性,避免了数据切割和训练碎片化;与传统统—模型相比,它通过阶段掩码有效解决了子任务衔接问题。总的 来说, Long-VLA 实现了“端到端”和“长时适应性” 的平衡,既继承了 VLA 的大规模扩展性,又弥补了以往方法在技能链处理上的不足。
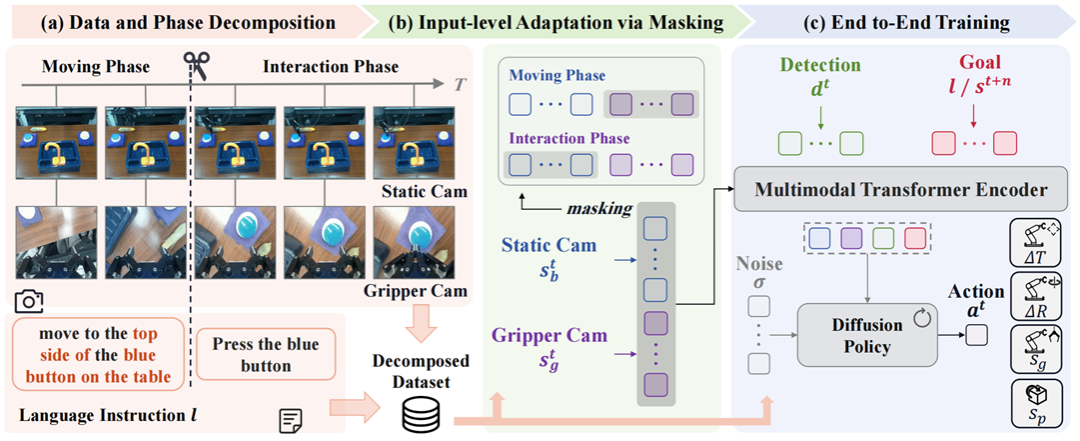
模型介绍
Long-VLA 的核心方法包含三个关键设计:任务阶段划分、输入级适配策略、统—端到端训练。首先,将长时任务 中的每个子任务进—步分解为“移动阶段”与“交互阶段” 。移动阶段主要涉及空间定位与全局导航,交互阶段则涉及 局部操作与精细操控。为此,数据集被重新标注,形成新的 L-CALVIN 数据集,每条轨迹均带有明确的阶段切分 点。其次,在输入适配策略上,模型通过二进制掩码机制动态调整注意力输入:在移动阶段屏蔽机械臂相机视角,
在交互阶段屏蔽静态全局相机视角。该策略在保持输入结构—致性的同时,有效缓解了阶段间模态分布差异,增强 了任务衔接性,并且通过条件扩散模型生成动作序列。
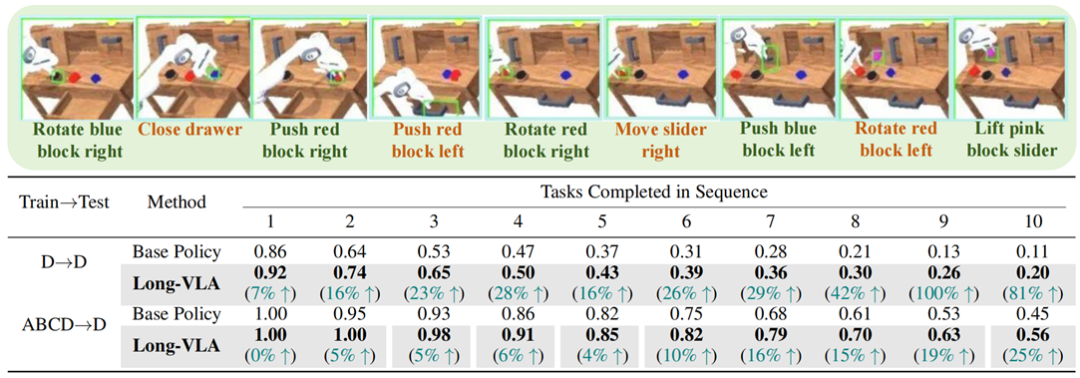
实验
为了更好验证模型的长时执行性能,优化了CALVIN环境将其任务长度提升到连续十个子任务。在此模拟环境(L- CALVIN)中, Long-VLA 在 D→ D 与 ABCD→ D 场景均显著超越基线,显示了其在长时任务中的稳定性。
在真实场景中涉及的两个长时任务Sorting和Cleaning中, Long-VLA 在随机位置、光照变化和视觉干扰三类未见条 件下均显著优于基线,进—步证明了其鲁棒性和泛化性。


此外,该方法对不同方法(如 HULC 、 MDT)具有普适性,可以简单地迁移到其他模型中,证明了方法的实际应用价值。

总结
本研究首次实现了“端到端训练”和“长时适应性” 的平衡,为未来机器人长时任务执行的进—步探索奠定了基础。我们期待通过本研究,能够为社区长时任务执行难题提供思路和环境基础,从而促进机器人在实际生活中帮助人们完 成更具有实际意义的任务。
更多最新内容,欢迎加入国内首个具身智能全栈学习社区,具身智能之心知识星球,和近200家公司机构成员一起交流。
