
你是否也好奇过:现在的模型在各类榜单分数都那么高,实际体验却不符预期?
我们也看过各种 AI Coding 领域的评测,发现大多停留在了 「代码生成」与「封闭题目」的考核,却忽视了环境配置、依赖处理、跨仓库资源利用等开发者必经的真实需求 —— 当下众多 Benchmark 仅通过题目,已难以衡量 Code Agent 的实际效果。
为突破现有评测局限,中科院、北大、港科大、中科大、新加坡国立大学等机构的研究者,与前沿开源学术组织 QuantaAlpha 及阶跃星辰姜大昕团队联合,首次提出并开源了 repo-level 的测评新范式 GitTaskBench:
1)真正考察 Agent 从 仓库理解 → 环境配置 → 增量开发 / 代码修复 → 项目级交付 的全链路能力,指引了迭代新范式
2)首次把「框架 × 模型」的「经济收益」纳入评测指标,给学界、业界以及创业者都带来了很好的思路启发

论文标题:GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
论文地址:https://arxiv.org/pdf/2508.18993
GitHub 链接:https://github.com/QuantaAlpha/GitTaskBench
GitTaskBench 分布一览
其开源版覆盖了 7 大模态 × 7 个领域 × 24 个子领域及 54 个真实任务:
对应后端仓库 18 个,包含平均 204 个文件、1,274.78 个函数、52.63k 行代码,文件彼此引用依赖平均为 1242.72 次。
且每个任务都绑定了完整 GitHub 仓库 + 自然语言指令 + 明确输入输出格式 + 任务特定的自动化评测。
以下图片统计了 GitTaskBench 的领域与模态分布,包括相应的数量。

仓库级的端到端评测的构建
首先从能力角度,GitTaskBench 对 Code Agent 进行了三个维度的分析:
1. 整体编码掌控:读文档、解依赖、生成 / 修改 / 调试代码
2. 任务导向执行:多轮推理与工具使用,产物必须贴合任务交付,利用代码仓库但不局限于仓库
3. 自主环境配置:不借助预置镜像,独立装环境 / 解依赖
下图是从仓库收集到任务测评的全流程概览

整体主要经过四个阶段:
1. 「仓库遴选」:结合文献综述、LLM 辅助检索和专家咨询,先定任务范围;再从 Python 仓库里,挑出 ⭐≥50、近五年活跃、依赖可用且易配置的候选。人工核验 Stars、Forks、许可证、提交历史,确保资源靠谱。
2. 「完备性验证」:包括必要依赖文件、配置文件、所需数据集和预训练模型。严格按文档跑通,确保 100% 人类可复现;若遇到资源门槛 / 外链阻断,将必要信息放进到 README,充分保证自包含所有必要信息。
3. 「执行框架设计」:统一清晰的任务定义、输入 / 输出规范;Agent 接收仓库 + 任务提示,需完成仓库理解 → 代码生成 / 修改 → 环境安装 → 代码执行的多阶段流程。
4. 「自动化评测」:我们实现了一套由人工验证的定制化测试脚本驱动的评测指标体系。所有任务只需一条命令自动评测,可直接产出各任务对应的成功 / 失败状态 + 详细原因,并可进行指标统计。
实在的经济可行性分析
其次,GitTaskBench 还首次提出了「性价比」的概念,结合以下指标:
ECR(Execution Completion Rate):能否成功执行仓库并以合规格式输出(存在、非空、格式可解析)
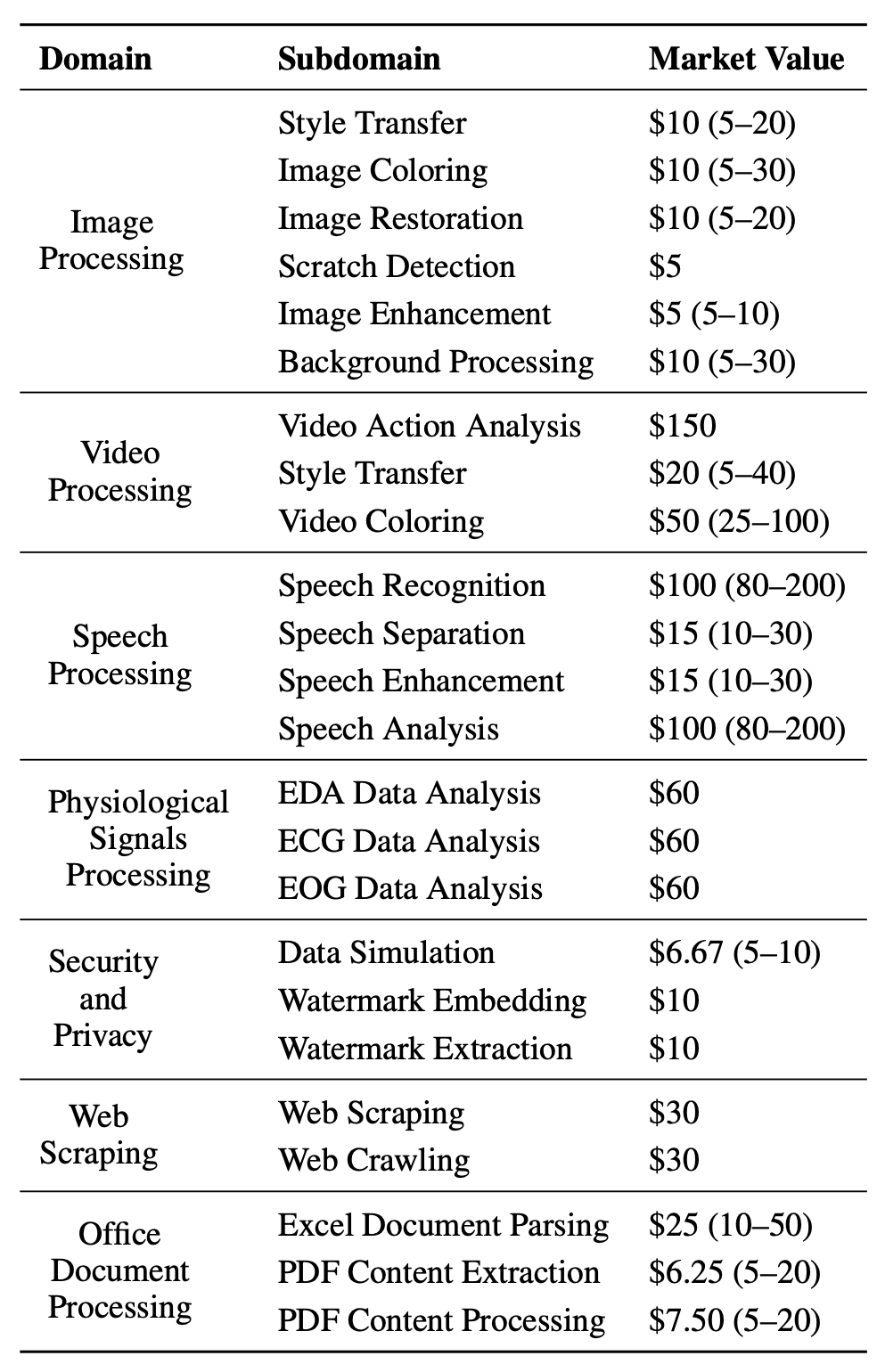
TPR(Task Pass Rate):按任务领域标准判定是否达到成功阈值(如语音增强 PESQ ≥2.0 / SNR ≥15dB;图像类 SSIM/FID 阈值等),不过线即失败。
α 值(Alpha Practical Value):该值为 Agent 在执行任务的平均净收益 —— 把完成度 (T)、市场价 (MV)、质量系数 (Q) 和成本 (C) 融合,回答「这活交给这个 Agent 值不值」的切实问题,具体公式:

n 表示任务数量;
T 为任务成功的二元标记(与 ECR 定义一致,成功为 1,失败为 0);
MV 表示人工完成该任务的市场价值估计;
Q 为质量系数(0 至 1 之间),表示智能体输出与人工执行同一仓库所得结果的接近程度;
C 为智能体的总运行成本(此处近似为 API 费用)。
这很好地反映了 Agent 方案在各领域的经济可行性,通过量化任务自动化与可扩展性带来的成本节省、效率提升及潜在市场收益,真正地评估了 Agent 落地的实际价值。
结果一览:框架与模型的耦合
在适配了主流框架与模型之后,我们实验发现:
OpenHands 整体最强,+ Claude 3.7 拿到最高成绩:ECR 72.22% / TPR 48.15%。
性价比之王? GPT-4.1 在成功率次优的同时,成本仅为 Claude 的 1/10 ~ 1/30(OpenHands 设定下),在 SWE-Agent 中也以更低成本拿到亚军表现。
开源可用性:Qwen3-32B(think 模式) 能以更少 token 达到 Claude 3.5 的约 60% 水平。
任务偏好:纯文本 / 办公文档类稳定,多模态、模型推理密集型更难(如图像修复需多依赖与权重配置)。

更细致地分析,各任务领域下不同框架 + 模型的性能表现:

此外,能力之上的现实价值也值得关注:
虽然在人类市场价值(MV)本身较高的仓库(如 视频类 VideoPose3D 、语音类 FunASR 、时序生理信号类 NeuroKit 场景)中,只要 Agent 顺利完成任务,就能获得最大的正向 alpha 收益。
但对于低 MV 的图像处理等任务(MV≈$5–10),一旦智能体的平均执行成本超过 $1-2,往往会导致 alpha 为负。
这一规律凸显了:在商业潜力有限的任务中,控制运行成本对于确保经济可行性至关重要。

其中,对于不同模型:
DeepSeek V3 在大多数仓库中提供了最高的整体收益与最佳的性价比;
GPT-4.1 在不同场景下表现更加稳定与稳健,很少出现大幅性能下降的情况;
Claude 3.5 的收益分布最为分散,在信息抽取任务上表现突出,但在计算量较大的视觉类任务中对成本较为敏感。
总结
由此可见,现实中我们对「框架 × 模型」的选择,应从效果、成本、API 调用上进行三元权衡,例如:Claude 系列在代码类任务表现出色,但在很多场景下 GPT-4.1 更省钱且稳健,而开源模型可在特定仓库上取得更好的综合 α。
在以下更广泛应用场景,我们也可以直接用 GitTaskBench 来助力:
Agent infra:做基座对比、工作流改进(环境管理 / 依赖修复 / 入口识别 / 执行规划)的回归测试场。
应用落地评审:以 ECR/TPR/α 同时衡量「能不能交付」与「划不划算」,给 PoC / 上线决策提供可解释的三维证据。
任务设计素材库:跨图像 / 语音 / 生理信号 / 办公文件 / 爬虫等七模态任务,可直接复用作为企业内评测用例。
关于 QuantaAlpha
QuantaAlpha 成立于 2025 年 4 月,由来自清华、北大、中科院、CMU、港科大、中科大等学校的教授、博士后、博士与硕士组成。我们的使命是探索智能的「量子」世界,引领智能体研究的「阿尔法」前沿 —— 从 CodeAgent 到自进化智能,再到金融、医疗等跨领域的专用智能体,致力于重塑人工智能的边界。🌟
✨ 2025 年,我们将在 CodeAgent(真实世界任务的端到端自主执行)、DeepResearch、Agentic Reasoning/Agentic RL、自进化与协同学习 等方向持续产出高质量研究成果,欢迎对我们方向感兴趣的同学加入我们!
团队主页:https://quantaalpha.github.io/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com