本文收录本周 Hugging Face Daily Paper,解读由 🔥Intern-S1、Qwen3 等 AI 生成可能有误。
(1) InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
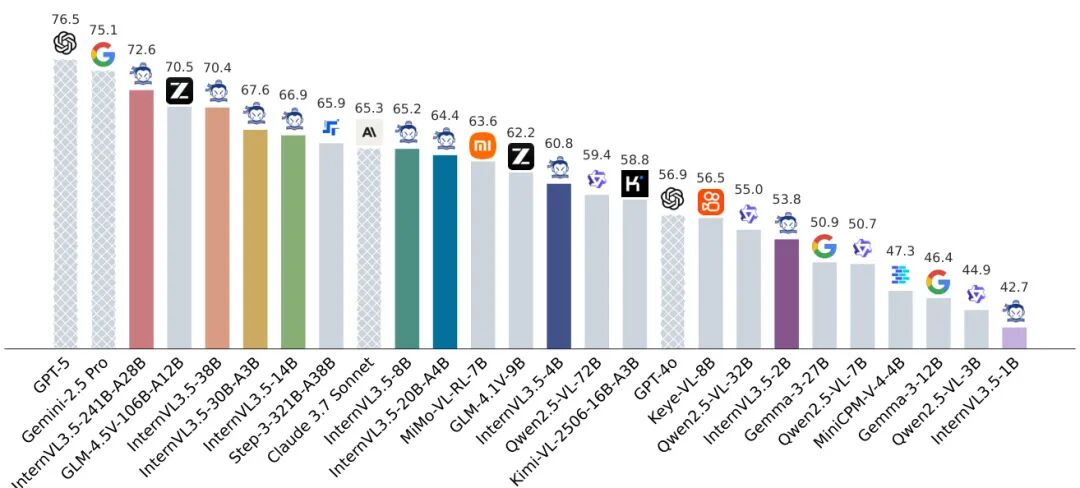
论文简介:
由上海人工智能实验室等机构提出了InternVL3.5,该工作通过创新的级联强化学习框架、视觉分辨率路由技术和解耦式视觉-语言部署策略,在保持开源模型开放性的同时,显著提升了多模态大模型的推理能力、应用通用性及部署效率。InternVL3.5系列包含从1B到241B参数量的多种模型规模,其中最大模型InternVL3.5-241B-A28B在35项多模态任务评估中达到74.1的综合得分,与闭源模型GPT-5(74.0)相当,且在MMMU(多模态推理)和MathVista(数学视觉推理)等核心任务中分别取得77.7和82.7的优异表现,领先现有开源模型。
核心创新方面,级联强化学习(Cascade RL)通过离线预训练(MPO算法)与在线优化(GSPO算法)的双阶段策略,使模型推理能力提升16%,其中8B参数模型在MMMU的得分从62.7跃升至73.4。视觉分辨率路由(ViR)技术动态调整图像token数量,在保持99%性能的前提下将视觉计算量降低50%,结合Decoupled Vision-Language Deployment(DvD)策略实现视觉与语言模块的异步并行计算,推理速度提升4.05倍。模型在文本理解、图表解析、视频推理等任务中均表现突出,例如在MME-RealWorld(真实场景理解)任务中,241B模型以74.6的分数大幅领先GPT-4o(57.4)。此外,该模型还支持GUI交互、具身智能等新型应用场景,在ScreenSpot(屏幕交互)任务中达到92.9的准确率。这些突破性进展为开源多模态模型追赶闭源模型提供了重要技术路径。
Hugging Face 投票数:161
论文链接:
https://hf.co/papers/2508.18265
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18265
(2) Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR

论文简介:
由 UCLA、微软、中国科学院、香港科技大学等机构提出了 Self-Play with Variational Problem Synthesis (SVS),该工作针对强化学习与可验证奖励(RLVR)训练中策略熵崩溃导致生成多样性下降的问题,提出通过自博弈生成变分问题的在线数据增强策略,有效维持训练熵并显著提升模型在竞争级数学推理任务上的Pass@k性能。研究发现,传统RLVR训练因重复生成记忆化解法导致策略熵下降,限制了模型探索更优推理路径的能力。SVS方法通过让策略模型基于自身正确解法生成语义一致但结构多样的变分问题,利用策略自身进行数据增强,无需额外标注即可保持训练数据多样性。实验表明,SVS在AIME24和AIME25基准上使32B参数模型的Pass@32分别提升18.3%和22.8%,在12个推理基准测试中均超越标准RLVR,且策略熵在训练过程中保持稳定波动。该方法通过持续生成具有挑战性的变分问题,形成自我改进闭环,在数学推理、通用问答和代码生成等任务上展现出跨领域泛化能力,为大规模语言模型的可持续训练提供了新范式。
Hugging Face 投票数:114
论文链接:
https://hf.co/papers/2508.14029
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14029
(3) AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs

论文简介:
由UCL、华为诺亚方舟实验室等机构提出了AgentFly,该工作提出了一种基于记忆增强的在线强化学习框架,通过记忆库存储经验轨迹并利用神经案例选择策略实现LLM代理的持续适应能力,无需对底层LLM参数进行微调。该方法将决策过程建模为记忆增强的马尔可夫决策过程(M-MDP),通过非参数或参数化记忆模块存储过往经验,并基于软Q学习优化案例检索策略。在GAIA数据集上达到87.88%的验证集准确率(Top-1)和79.40%的测试集准确率,在DeepResearcher数据集取得66.6% F1和80.4% PM的SOTA结果,同时案例记忆在OOD任务中带来4.7%-9.6%的绝对提升。实验表明,该方法通过记忆库的持续更新实现高效在线学习,在复杂工具调用和多轮推理任务中展现出显著优势,为构建具备持续学习能力的通用型LLM代理提供了新范式。
Hugging Face 投票数:107
论文链接:
https://hf.co/papers/2508.16153
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16153
(4) VibeVoice Technical Report

论文简介:
由微软研究院等机构提出了VIBEVOICE,该工作设计了一种新型语音合成模型,通过引入next-token diffusion框架和高效连续语音tokenizer,实现了长达90分钟、支持最多4名说话人的高质量对话音频生成。核心创新在于开发了压缩率达3200倍(7.5Hz帧率)的因果语音tokenizer,在保持音质的同时将数据压缩效率提升80倍,并采用轻量级扩散头与大语言模型(LLM)结合的架构,通过混合语音表征建模和流式生成机制,突破了传统TTS在长序列多说话人场景下的合成瓶颈。
VIBEVOICE采用双tokenizer设计:基于σ-VAE的声学tokenizer(340M参数)实现高保真音频重建,其7.5Hz帧率在LibriTTS测试集上取得3.068 PESQ和4.181 UTMOS的领先指标;语义tokenizer则通过ASR任务学习文本对齐特征。模型将语音特征与文本脚本拼接输入LLM(Qwen2.5 1.5B/7B),由LLM预测隐状态并驱动扩散头逐token预测声学VAE特征,最终通过解码器恢复音频。该架构在保持简洁性的同时,通过课程学习策略支持65k上下文窗口训练。
实验显示,VIBEVOICE-7B在对话生成任务中主观评分(Realism 3.71/MOS)和客观指标(WER 1.29%)均超越Elevenlabs、Gemini等竞品,在SEED短句测试集上也保持竞争力(test-zh CER 1.16%)。模型支持跨语言合成且计算效率显著提升,但存在非英语内容输出不稳定、无法生成重叠语音等局限。研究强调该技术需谨慎用于研究场景,避免深度伪造等伦理风险。
Hugging Face 投票数:94
论文链接:
https://hf.co/papers/2508.19205
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19205
(5) Beyond Transcription: Mechanistic Interpretability in ASR

论文简介:
由特拉维夫大学等机构提出了Beyond Transcription: Mechanistic Interpretability in ASR,该工作首次系统性地将可解释性方法应用于自动语音识别领域,通过适配logit lens、线性探测和激活修补等技术,揭示了ASR模型内部的声学语义演化机制,发现了编码器-解码器交互中的重复幻觉现象及深层声学表征中的语义偏差。研究通过在Whisper和Qwen2-Audio两大主流模型上的实验,证实了声学属性(如说话人性别、环境噪音、口音等)在编码器深层的线性可解码性,其中说话人性别识别在25层达到94.6%准确率,环境噪音分类在27层达90.0%。特别发现解码器残差流中存在可预测幻觉的信号,通过线性探测在Whisper第22层实现93.4%的幻觉识别准确率。研究还揭示了ASR编码器的语义理解能力,通过合成音频数据集证明Whisper编码器在22-31层对语义类别(如国家vs天气)的区分度高达96.7%。针对重复幻觉问题,通过跨注意力机制干预在Whisper第23层成功解决76%的重复案例,其中第18层第13注意力头的单头干预有效率达78.1%。该工作为ASR模型的透明化和鲁棒性提升开辟了新路径,展示了通过内部机制分析实现错误定位和针对性优化的潜力。
Hugging Face 投票数:78
论文链接:
https://hf.co/papers/2508.15882
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15882
(6) Self-Rewarding Vision-Language Model via Reasoning Decomposition
Hugging Face 投票数:72
论文链接:
https://hf.co/papers/2508.19652
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19652
(7) TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Hugging Face 投票数:70
论文链接:
https://hf.co/papers/2508.17445
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17445
(8) Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning

论文简介:
由复旦大学、上海人工智能实验室、腾讯混元等机构提出了Pref-GRPO,该工作揭示了现有文本到图像生成强化学习方法中"奖励黑客"现象的本质原因是"虚假优势"问题,并提出首个基于成对偏好奖励的GRPO优化方法,通过将奖励最大化目标转化为偏好拟合来实现更稳定的生成训练。同时构建了包含600个提示词、覆盖5大主题20个子主题的UniGenBench基准,支持10个主维度27个子维度的细粒度评估,利用多模态大模型实现自动化评估流程。实验表明Pref-GRPO在语义一致性指标上较基线提升5.84%,文本和逻辑推理维度分别提升12.69%和12.04%,有效缓解了奖励分数虚高但质量下降的矛盾。UniGenBench的细粒度评估显示:闭源模型在逻辑推理(48.18%)和文本渲染(89.08%)表现突出,开源模型在动作(69.77%)和布局(77.61%)维度接近闭源水平,但在语法和复杂逻辑任务上仍有显著差距。该研究为文本到图像生成的优化范式和评估体系提供了新的技术路径与标准框架。
Hugging Face 投票数:64
论文链接:
https://hf.co/papers/2508.20751
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20751
(9) rStar2-Agent: Agentic Reasoning Technical Report

论文简介:
由Microsoft Research等机构提出了rStar2-Agent,该工作通过代理强化学习训练出140亿参数的数学推理模型,实现前沿性能突破。核心创新包括:(1)高效RL基础设施支持每秒4.5万次并发代码执行,采用动态负载均衡调度策略提升GPU利用率;(2)GRPO-RoC算法通过"正确时重采样"策略解决代码环境噪声问题,在保持结果奖励机制的同时过滤低质量轨迹;(3)三阶段训练策略从非推理微调起步,逐步扩展响应长度至12K tokens,最终在64张MI300X GPU上仅用510步训练即达到SOTA。实验显示,rStar2-Agent-14B在AIME24和AIME25基准上分别取得80.6%和69.8%的pass@1准确率,超越DeepSeek-R1(671B)的同时生成更短响应(平均9339 tokens vs 14246)。该模型展现出跨领域泛化能力,在科学推理(GPQA-Diamond 60.9%)、工具使用(BFCL v3 60.8%)等任务中表现优异。研究还揭示代理强化学习能激发模型对代码执行结果的反射性tokens,驱动自主探索和纠错。相关代码和训练方案已开源。
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2508.20722
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20722
(10) CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics

论文简介:
由上海人工智能实验室等机构提出了CMPhysBench,该工作构建了一个包含520道研究生水平问题的基准测试集,旨在评估大语言模型在凝聚态物理领域的推理能力。CMPhysBench覆盖磁学、超导、强关联体系等核心子领域,强调开放式计算题型,要求模型独立生成完整解题步骤。为实现细粒度评估,研究团队提出Scalable Expression Edit Distance(SEED)指标,通过树状结构表达式匹配支持多类型答案的非二元评分,显著提升评估准确性。实验显示当前最优模型Grok-4在SEED评分中仅得36分,准确率28%,凸显大语言模型在前沿物理领域的显著能力差距。该基准测试的代码与数据已开源,为推动领域发展提供了重要工具。
Hugging Face 投票数:45
论文链接:
https://hf.co/papers/2508.18124
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18124
(11) ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks

论文简介:
由浙江大学等机构提出了ODYSSEY,该工作提出了一种四足机器人移动操作框架,通过整合分层任务规划与地形自适应全身控制,实现了开放环境中的长时程任务执行。针对语言引导的移动操作三大挑战——受限感知、操作泛化性不足及机动性与精确控制的平衡,研究团队创新性地构建了基于视觉语言模型的分层规划器,将自然语言指令分解为可执行的原子动作序列,并通过几何约束的末端姿态生成实现精准操作。在控制层面,基于强化学习的全身策略通过地形不变的末端采样策略和域随机化训练,实现了复杂地形下的稳定运动与操作协同。研究还构建了首个涵盖室内外场景、包含246种室内和58种室外配置的长时程移动操作基准测试集,并通过模拟到现实的迁移验证了系统在真实环境中的泛化能力。实验表明,该框架在室内任务中导航成功率达97.4%,操作成功率超70%,在户外坡地等复杂地形中仍保持46.4%的整体任务完成率,展示了四足操作机器人在非结构化环境中的应用潜力。
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2508.08240
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08240
(12) Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.18032
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18032
(13) OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation

论文简介:
由字节跳动智能创作实验室等机构提出了OmniHuman-1.5,该工作通过认知模拟为虚拟角色注入主动思维,构建了首个同时模拟人类"系统1"(快速反应)和"系统2"(深度推理)的认知框架。核心贡献体现在两个关键技术:1)利用多模态大语言模型生成结构化文本条件,通过链式推理提供语义级动作指导,突破传统方法仅依赖音频节奏的局限;2)创新多模态Diffusion Transformer架构,采用伪最后一帧策略解决身份图像与动态内容的模态冲突,实现音频、文本、视频三模态的深度融合。实验表明该方法在唇同步准确率、视频质量、动作自然度等指标上全面领先,并展现出卓越的语义一致性。特别在复杂多场景测试中,模型成功生成符合逻辑的多角色互动和非人类角色动作,验证了框架的泛化能力。这项研究开创性地将认知科学理论引入虚拟人生成领域,为构建具有真实行为逻辑的数字角色提供了全新范式。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.19209
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19209
(14) VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space

论文简介:
由北京航空航天大学、中国人民大学、清华大学和腾讯混元项目组提出了VoxHammer,该工作提出了一种无需训练的3D本地编辑框架,通过在原生3D空间中进行精确且连贯的编辑来实现高质量3D资产修改。该方法基于预训练的结构化3D潜在扩散模型,采用两阶段策略:首先通过精确的3D反转预测将输入3D模型映射到噪声空间并缓存潜码与键值对特征,随后在去噪编辑阶段通过替换未编辑区域的潜码和注意力键值对,实现几何结构与纹理细节的高保真保持。为解决现有数据集缺乏编辑区域标注的问题,研究团队构建了包含数百个样本的Edit3D-Bench基准数据集,通过定量实验和用户研究验证了VoxHammer在未编辑区域一致性(Chamfer距离降低40%以上)、整体质量(FID下降50%)和条件对齐度(CLIP-T提升10%)等方面均显著优于现有方法。该方法无需额外训练即可实现对网格、NeRF和高斯溅射等3D表示的局部编辑,在游戏开发和机器人交互等领域具有重要应用价值,同时为生成式3D建模的上下文学习奠定了数据基础。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.19247
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19247
(15) USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning

论文简介:
由字节跳动UXO团队等机构提出了USO(Unified Style-Subject Optimized),该工作通过解耦内容与风格特征并引入奖励学习机制,首次实现了风格驱动与主体驱动生成任务的统一框架。现有方法通常将风格相似性与主体一致性视为对立目标,而USO通过构建包含20万组三元组数据(风格参考图、去风格化主体图、风格化结果图)的训练集,提出跨任务协同解耦范式:利用主体生成模型生成高质量风格化数据,再通过风格奖励引导的解耦训练优化主体模型。技术上采用SigLIP多尺度特征投影实现风格对齐训练,并通过内容-风格解耦编码器分离条件特征,最终结合风格奖励学习(SRL)进一步提升解耦效果。研究团队还发布了首个支持风格/主体/联合任务评估的基准USO-Bench,包含50组内容图与50组风格图的组合测试集。实验显示USO在Subject-Driven任务中取得0.623 CLIP-I和0.793 DINO的SOTA成绩,在Style-Driven任务中以0.557 CSD和0.282 CLIP-T超越现有方法,在联合任务中更以0.495 CSD和0.283 CLIP-T显著领先基线模型。消融实验证实风格奖励学习使CSD提升8.2%,解耦编码器使CLIP-I提升2.9%,验证了跨任务协同解耦的有效性。该方法支持任意主体与风格的自由组合生成,在保持高文本对齐度的同时,解决了传统方法中风格迁移时主体失真和主体生成时风格干扰的核心矛盾。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.18966
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18966
(16) MV-RAG: Retrieval Augmented Multiview Diffusion

论文简介:
由希伯来大学等机构提出了MV-RAG,该工作提出了一种检索增强的多视图扩散框架,通过结合结构化多视图数据和大规模2D图像集合的混合训练策略,有效提升了模型在处理罕见或新兴对象时的生成质量。针对现有文本到3D生成方法在分布外(OOD)场景下几何不一致和语义偏差的问题,MV-RAG创新性地引入了动态检索增强机制:在推理阶段,首先通过BM25从LAION-400M等数据集中检索与文本相关的2D图像,利用ViT编码器提取局部特征并通过可学习的Resampler模块生成条件令牌;在生成阶段,通过解耦的交叉注意力机制将文本语义与检索图像的视觉特征进行自适应融合,并设计了Prior-Guided Attention机制根据OOD程度动态调整基模型与检索信号的权重分配。训练策略上,该方法采用3D模式与2D模式交替训练:3D模式通过渲染Objaverse数据集对象并施加几何/语义增强来模拟真实检索差异,要求模型从增强视图重建原始视角;2D模式则使用ImageNet-21K数据,通过预测被遮掩视图的新型训练目标,使模型从无结构2D图像中学习3D一致性。实验方面,研究团队构建了包含196个OOD概念的评估基准OOD-Eval,对比MVDream、MV-Adapter等SOTA方法,在CLIP、DINO等图像相似度指标上分别提升5.3%和12.1%,同时保持了在Objaverse-XL等标准数据集上的竞争力。该工作不仅通过检索增强突破了传统扩散模型的语义局限,更通过混合训练范式弥合了结构化3D数据与非结构化2D图像之间的鸿沟,为文本到多视图生成开辟了新路径。
Hugging Face 投票数:34
论文链接:
https://hf.co/papers/2508.16577
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16577
(17) Pixie: Fast and Generalizable Supervised Learning of 3D Physics from Pixels

论文简介:
由宾夕法尼亚大学和MIT等机构提出了Pixie,该工作提出了一种从视觉特征中快速预测3D场景物理属性的监督学习框架。Pixie通过训练神经网络直接从3D视觉特征预测离散材质类型(如橡胶)和连续物理参数(如杨氏模量、泊松比、密度),结合高斯泼溅模型和物质点法(MPM)求解器实现逼真的物理模拟。研究团队构建了包含1624个3D资产和物理标注的PixieVerse数据集,采用CLIP视觉特征蒸馏和3D U-Net网络实现每场景2秒内的快速推断,相比传统优化方法速度提升3个数量级,且在视觉语言模型评估中实现1.46-4.39倍的现实感提升。该方法通过预训练视觉特征实现从合成数据到真实场景的零样本迁移,成功预测真实物体的物理属性并生成符合物理规律的动画效果,为虚拟世界构建和机器人仿真提供了高效解决方案。
Hugging Face 投票数:32
论文链接:
https://hf.co/papers/2508.17437
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17437
(18) MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers

论文简介:
由 Accenture 等机构提出的 MCP-Bench 是一个面向复杂真实世界任务的工具使用型大语言模型(LLM)评估基准。该工作基于 Model Context Protocol(MCP)构建了包含 28 个生产级服务器、250 个结构化工具的生态系统,支持跨域多工具协调与长时程任务规划。通过 LLM 驱动的任务合成管道生成模糊指令任务,结合规则验证与 LLM 评判的双层评估框架,MCP-Bench 能全面测试模型在工具检索、参数控制、多跳规划和跨域协作等维度的能力。实验评估了 20 个主流模型,发现尽管头部模型(如 gpt-5、o3)在执行精度上趋近饱和(schema compliance >99%),但在依赖链合规性(dependency awareness 0.76 vs 0.22)、多目标并行效率(parallelism 0.34 vs 0.14)等高阶能力上仍存在显著差距。该基准揭示了当前 LLM 在真实复杂场景中长期规划能力的不足,为推动具身智能体发展提供了标准化评估平台。代码与数据已开源,支持研究者持续优化模型的现实世界任务解决能力。
Hugging Face 投票数:30
论文链接:
https://hf.co/papers/2508.20453
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20453
(19) Hermes 4 Technical Report
Hugging Face 投票数:29
论文链接:
https://hf.co/papers/2508.18255
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18255
(20) CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了CODA,该工作受人脑“大脑-小脑”分工机制启发,构建了可协同的双脑计算机使用代理架构。核心创新在于提出解耦强化学习框架,采用Qwen2.5-VL作为规划器(大脑)和UI-Tars-1.5作为执行器(小脑)的协作模式。通过两阶段训练策略:第一阶段使用解耦的GRPO算法对每个科学应用进行专项强化学习,利用自动奖励系统和分布式虚拟机系统加速轨迹收集;第二阶段通过监督微调将多个专家模型整合为通用规划器。在ScienceBoard基准测试的四个科学计算应用中,CODA显著超越基线模型,达到开源模型新SOTA。该方法通过固定执行器保障动作稳定性,同时让规划器专注领域知识学习,在减少数据依赖的同时提升跨域泛化能力,为复杂GUI任务的长程规划与精准执行提供了新范式。代码和模型已开源。
Hugging Face 投票数:29
论文链接:
https://hf.co/papers/2508.20096
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20096
(21) Spacer: Towards Engineered Scientific Inspiration
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2508.17661
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17661
(22) UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning

论文简介:
由字节跳动等机构提出了UltraMemV2,该工作通过五项核心改进实现了内存层架构与8专家MoE模型的性能持平,同时保持低内存访问优势。研究团队通过在每个Transformer块中集成内存层、简化值扩展为单线性投影、采用PEER的FFN值处理、优化参数初始化策略以及调整内存与FFN计算比例,使模型在同等计算量下实现长上下文任务的显著提升。实验表明,UltraMemV2在长上下文记忆任务上提升1.6分,多轮记忆任务提升6.2分,在上下文学习任务提升7.9分,验证了其在内存密集型任务中的优势。通过扩展至1200亿参数规模的实验,研究发现激活密度(top-m值)对性能的影响大于总稀疏参数数量,为内存层架构设计提供了关键指导。该工作首次实现了内存层架构与顶尖MoE模型的性能对标,为高效稀疏计算提供了新范式,但同时也发现其在训练初期效果较弱、依赖高质量数据等局限性。
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2508.18756
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18756
(23) Understanding Tool-Integrated Reasoning

论文简介:
由腾讯与清华大学的研究团队提出的工具集成推理(TIR)理论框架,首次从数学上证明了外部工具(如Python解释器)对大语言模型(LLM)能力的增强机制。该工作通过形式化证明揭示TIR通过引入确定性状态转移,严格扩展了模型的经验支持集和可行支持集,突破了纯文本模型在强化学习中受"隐形束缚"(invisible leash)限制的能力天花板。研究提出"token效率"概念,证明程序化表达在迭代、递归等算法中的常数级token成本优势,而自然语言模拟需线性增长的token消耗,这一差异使得TIR在有限上下文窗口下解锁了纯文本模型无法实现的算法策略空间。实验部分基于Qwen3-8B模型在AIME24/25和Omni-MATH-512基准测试中,TIR模型在pass@k指标上全面超越纯文本模型,且优势不局限于计算密集型问题——通过算法友好度分级实验,发现TIR在抽象数学问题上仍保持9%的准确率提升。研究还发现了三种工具使用认知模式:洞察驱动的计算转化、代码辅助的探索验证、复杂计算卸载。针对传统奖励塑形导致的训练不稳定问题,提出的Advantage Shaping Policy Optimization(ASPO)算法,通过直接调整优势函数成功引导模型早中期调用工具,使代码调用次数翻倍且保持训练稳定性。该工作从理论到实践系统阐释了工具集成如何重构LLM的推理范式,为构建更高效的工具增强型智能体提供了基础框架。
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2508.19201
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19201
(24) MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Hugging Face 投票数:26
论文链接:
https://hf.co/papers/2508.18264
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18264
(25) MIDAS: Multimodal Interactive Digital-human Synthesis via Real-time Autoregressive Video Generation

论文简介:
由快手科技、浙江大学和清华大学等机构提出了MIDAS(Multimodal Interactive Digitalhuman Synthesis),该工作构建了一种基于自回归模型与扩散渲染的实时多模态数字人合成框架。针对现有方法在低延迟交互、多模态控制和长序列生成上的局限,研究团队设计了三大核心创新:首先通过多模态条件投影器将音频、姿态、文本等异构信号编码为统一指令令牌,引导自回归模型生成时空一致的潜在表示;其次采用因果潜在预测与轻量扩散头结合的架构,以单帧预测策略实现流式生成,在保证质量的同时将推理延迟降至毫秒级;此外开发了64倍压缩比的深度压缩自编码器(DC-AE),显著降低长序列生成的计算负担。为支撑模型训练,团队构建了包含2万小时对话的多场景数据集,并引入可控噪声注入机制缓解训练与推理的暴露偏差问题。实验部分通过双工对话、跨语言唱歌合成和交互式世界模型三项任务验证了框架的有效性:数字人能实现自然的对话轮转与唇形同步,支持中英日等多语言高保真生成,并在《我的世界》场景中展现出稳定的视觉记忆与环境交互能力。该工作在保持身份一致性的同时,实现了多模态条件下的实时响应与开放域生成,为交互式数字人技术提供了可扩展的解决方案。
Hugging Face 投票数:25
论文链接:
https://hf.co/papers/2508.19320
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19320
(26) AWorld: Orchestrating the Training Recipe for Agentic AI

论文简介:
由Inclusion AI、上海人工智能实验室和西湖大学等机构提出了AWORLD框架,该工作针对“从实践中学习”的智能体训练范式,通过分布式架构突破经验生成瓶颈,实现14.6倍加速的并行环境交互能力。研究者基于此框架对Qwen3-32B模型进行强化学习训练,使其在GAIA基准测试中整体准确率从21.59%提升至32.23%,并在最高难度级别以16.33%的pass@1成绩超越GPT-4o等闭源模型。实验表明,复杂任务中智能体性能与经验生成规模呈显著正相关,而AWORLD的集群调度机制有效解决了传统单节点串行执行的效率缺陷,将完整的训练周期从7839秒压缩至669秒。该框架支持灵活的工具集成、多智能体通信协议及与主流RL系统的解耦式训练 orchestration,为构建具备持续学习能力的智能体提供了完整技术方案。通过在GAIA和xbench-DeepSearch基准上的验证,该系统不仅证明了分布式经验收集对性能提升的关键作用,更展示了开源模型通过强化学习实现多步推理能力突破的可能性。
Hugging Face 投票数:25
论文链接:
https://hf.co/papers/2508.20404
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20404
(27) T2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation

论文简介:
由香港大学和香港中文大学等机构提出了T2I-ReasonBench,该工作构建了一个新型基准测试框架,旨在系统评估文本到图像生成模型的推理能力。研究团队针对现有模型在隐含语义理解上的不足,设计了包含800个提示词的测试集,覆盖成语解读、图文设计、实体推理和科学推理四大维度,要求模型在生成图像前完成多步骤逻辑推导。通过大语言模型生成定制化评估问题,再由多模态模型进行双阶段评分,该框架可量化推理准确率和图像质量。实验对比了14种主流模型,包括扩散模型、自回归模型和闭源商用模型,发现开源模型普遍存在显著推理缺陷,而GPT-Image-1等闭源模型虽表现更优但仍存在提升空间。研究揭示了当前文本到图像生成技术在知识整合与逻辑推理上的核心瓶颈,为构建具备深度语义理解能力的下一代生成模型提供了基准参考和改进方向。
Hugging Face 投票数:25
论文链接:
https://hf.co/papers/2508.17472
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17472
(28) Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies

论文简介:
由香港大学、上海人工智能实验室、上海交通大学、华为云等机构提出了Discrete Diffusion VLA,该工作首次将离散扩散模型引入视觉-语言-动作(VLA)策略的动作解码,通过统一的单transformer架构实现视觉、语言与动作的联合建模。该方法将连续动作离散化为固定长度的动作块,并采用离散扩散范式进行迭代解码,保留了扩散模型渐进式精炼的优势,同时与视觉语言模型(VLM)的离散token接口天然兼容。其核心贡献包括:1)提出首个基于离散扩散的VLA动作解码框架,通过交叉熵损失与VLM主干网络统一训练,保留预训练的视觉语言先验知识;2)设计自适应解码策略,按置信度优先解码简单动作元素并二次重掩码修正不确定预测,实现并行解码与错误修正;3)在LIBERO、SimplerEnv-Fractal和SimplerEnv-Bridge三个机器人任务中取得SOTA表现,Franka Panda机械臂在LIBERO上平均成功率96.3%,Google Robot在SimplerEnv-Fractal视觉匹配率达71.2%,WidowX机械臂在SimplerEnv-Bridge整体成功率49.3%,显著优于自回归和连续扩散基线方法。该方法突破了传统自回归解码的左到右瓶颈,通过固定步数的并行精炼将函数评估次数减少4.7倍,为大规模VLA模型扩展提供了新路径。
Hugging Face 投票数:24
论文链接:
https://hf.co/papers/2508.20072
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20072
(29) Analysing Chain of Thought Dynamics: Active Guidance or Unfaithful Post-hoc Rationalisation?

论文简介:
由谢菲尔德大学等机构提出了Analysing Chain of Thought Dynamics,该工作通过分析指令微调、推理训练和推理蒸馏三类模型在软推理任务中的链式推理(CoT)动态,揭示了CoT影响与忠实性之间的复杂关系。研究发现蒸馏推理模型(如DeepSeek-R1系列)高度依赖CoT进行决策修正,65%的案例中会改变初始预测,且常通过修正错误提升准确性;而指令微调模型(如Qwen2.5)和推理训练模型(如Qwen3)仅25%左右改变预测,更多将CoT作为事后合理化工具。通过追踪CoT生成过程中的置信度轨迹,发现蒸馏模型的置信度随推理步骤持续上升,最终答案常在最后一步突变,表明CoT对其决策具有关键引导作用;而指令微调模型的置信轨迹相对平坦,暗示CoT更多是形式化解释。研究还创新性地通过注入误导提示(教授建议/元数据标签)测试CoT忠实性,发现即使未明确提及提示信息,蒸馏模型的CoT仍可能被其引导决策,揭示了"不忠实但具影响力"的矛盾现象。该工作挑战了传统将因果依赖作为CoT忠实性唯一标准的定义,指出不同模型的CoT训练机制(如蒸馏模型依赖程序性知识)导致其推理机制差异,为优化推理模型的可解释性提供了新视角。
Hugging Face 投票数:22
论文链接:
https://hf.co/papers/2508.19827
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19827
(30) Autoregressive Universal Video Segmentation Model

论文简介:
由NVIDIA、延世大学、CMU和台湾大学等机构提出了Autoregressive Universal Video Segmentation Model(AUSM),该工作通过自回归建模统一了提示性与非提示性视频分割任务,实现了单架构处理多场景需求。AUSM借鉴语言模型的序列预测思想,将视频分割转化为逐帧掩码预测问题,通过History Marker和History Compressor模块实现历史信息的细粒度保留与时空压缩,在DAVIS、YouTube-VOS等7个基准测试中超越现有通用模型,同时支持16帧序列下2.5倍的训练加速。
核心创新点在于:1)提出视频分割的自回归统一框架,通过调整初始化策略兼容提示性(如VOS)与非提示性(如VIS)任务;2)History Marker模块采用Token Mark技术将实例掩码解构为空间特征,避免传统向量化带来的细节丢失;3)History Compressor结合Mamba和自注意力机制,将时空信息压缩为固定维度状态,实现任意长度视频的恒定内存推理;4)并行训练架构突破传统逐帧迭代模式,通过预处理构建跨帧监督信号,在16帧序列训练中展现2.5倍速度提升。
实验表明,AUSM在保持单模型架构的前提下,Swim-B版本在DAVIS17(81.6)、MOSE(62.1)、YouTube-VIS21(58.6)等数据集上全面超越UniVS等通用模型,尤其在复杂遮挡场景OVIS数据集达到45.5AP。通过伪视频预训练、多源短片段训练到长片段适配的三阶段策略,模型在16帧长序列训练中对MOSE和OVIS的性能提升分别达4.52和5.2AP。该工作验证了自回归建模在视频理解领域的有效性,为构建统一视频感知模型提供了新范式。
Hugging Face 投票数:22
论文链接:
https://hf.co/papers/2508.19242
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19242
(31) Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning

论文简介:
由浙江大学、理想汽车、南洋理工大学等机构提出了Rubric-Scaffolded Reinforcement Learning(RuscaRL),该工作通过引入评分标准(rubrics)作为显式指导和可验证奖励,突破了强化学习在大语言模型(LLM)推理中的探索瓶颈。研究指出,LLM的推理能力提升依赖高质量样本学习,但现有探索能力受限于模型固有局限,形成"无法探索则无法学习"的恶性循环。RuscaRL创新性地将教育心理学中的脚手架理论引入LLM训练,通过两阶段机制实现突破:在rollout生成阶段,以评分标准作为外部指导(显式脚手架),通过组内差异化和跨步衰减策略提升响应多样性;在模型训练阶段,利用评分标准构建多维可验证奖励(LLM-as-a-Judge),实现开放域任务的有效强化学习。实验显示,该方法在HealthBench-500上使Qwen2.5-7B-Instruct的得分从23.6提升至50.3,超越GPT-4.1;其微调版本Qwen3-30B-A3B-Instruct更达到61.1,领先OpenAI-o3等领先模型。消融实验证实了组内差异化策略和sigmoid衰减函数的关键作用,分析表明该方法显著提升了策略熵和响应新颖性(重要性比率中位数达2.1939,最高达263万倍)。研究揭示了结构化评估标准在LLM训练中的双重价值,为突破推理能力边界提供了新范式。
Hugging Face 投票数:21
论文链接:
https://hf.co/papers/2508.16949
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16949
(32) Beyond Memorization: Extending Reasoning Depth with Recurrence, Memory and Test-Time Compute Scaling
Hugging Face 投票数:20
论文链接:
https://hf.co/papers/2508.16745
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16745
(33) CineScale: Free Lunch in High-Resolution Cinematic Visual Generation

论文简介:
由Nanyang Technological University、Netflix Eyeline Studios等机构提出了CineScale,该工作提出了一种新的推理范式,通过多尺度融合和频率域处理技术,首次实现预训练扩散模型在8K图像和4K视频生成上的突破性效果。研究针对扩散模型在超分辨率生成时出现的重复模式和质量退化问题,设计了定制化的自级联上采样、受限膨胀卷积和尺度融合模块,有效解决了UNet架构下的局部重复问题。同时通过NTK-RoPE位置编码和注意力缩放技术,将方法扩展至DiT架构,在仅需少量LoRA微调的情况下,成功生成4K分辨率视频。实验表明,该方法在图像生成中达到FID 44.723(2048²)和49.796(4096²)的最优指标,视频生成在FVD、动态程度等指标上全面领先基线方法。值得注意的是,该方法支持灵活的局部语义编辑和动态程度控制,用户研究显示其在图像质量、结构合理性等维度获得70%以上的用户偏好。最终实现了在保持预训练模型参数不变的前提下,将图像生成分辨率提升64倍(8K)、视频生成分辨率提升9倍(4K)的技术突破。
Hugging Face 投票数:18
论文链接:
https://hf.co/papers/2508.15774
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15774
(34) Predicting the Order of Upcoming Tokens Improves Language Modeling

论文简介:
由MBZUAI等机构提出了Token Order Prediction(TOP),该工作针对多标记预测(MTP)在语言模型训练中改进效果不稳定的问题,提出通过学习排序未来标记的顺序来优化语言建模。TOP的核心创新在于将MTP的精确未来标记预测任务转化为基于排序损失的标记顺序预测任务,要求模型仅需一个额外解嵌入层即可实现,显著降低计算复杂度。研究团队在340M、1.8B和7B参数规模下对比了NTP、MTP和TOP三种训练策略,通过在八项标准NLP基准测试中的实验发现:TOP在所有模型规模下均优于传统NTP和MTP,特别是在7B参数模型中展现出更强的扩展性。实验结果显示,TOP在HellaSwag、ARC Challenge等任务中分别取得1.29%和3.67%的准确率提升,且训练损失分析表明TOP可能通过正则化作用缓解过拟合。该方法通过简化辅助任务难度,在保持模型架构轻量化的同时实现了更优的表征学习能力,为大规模语言模型的训练优化提供了新方向。
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.19228
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19228
(35) TCIA: A Task-Centric Instruction Augmentation Method for Instruction Finetuning
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.20374
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20374
(36) EgoTwin: Dreaming Body and View in First Person

论文简介:
由新加坡国立大学、南洋理工大学、香港科技大学和上海人工智能实验室等机构提出了EgoTwin,该工作首次探索了第一人称视角下视频与人体运动的联合生成问题,通过扩散模型框架实现了视点对齐和因果交互的同步建模。传统方法在处理外视角视频生成时通常依赖预设的相机轨迹,而第一人称视频生成需要同时生成与人体运动严格对齐的相机轨迹。EgoTwin引入头中心运动表示法,将运动锚定在头部关节而非传统根关节,显著提升了运动与视频的视点一致性。同时,其基于控制论的交互机制通过双向注意力设计,使视频帧能基于历史运动生成,运动序列又能根据视频帧的场景变化进行调整,形成闭环的观察-动作反馈。研究团队还构建了包含真实场景文本-视频-运动三元组的大规模数据集,并设计了评估视频-运动一致性的新指标(如相机轨迹与头部轨迹的平移/旋转误差、手部可见性F-Score)。实验表明,EgoTwin在视频质量(FVD↓40%)、运动质量(M-FID↓7%)和跨模态一致性(旋转误差↓70%)等指标上均显著优于基线模型。该框架支持文本驱动的视频-运动联合生成、以及给定视频/运动的条件生成等多样化应用,为可穿戴计算和虚拟现实中的具身智能体建模提供了新范式。
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.13013
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13013
(37) Mixture of Contexts for Long Video Generation
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.21058
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21058
(38) AudioStory: Generating Long-Form Narrative Audio with Large Language Models

论文简介:
由腾讯ARC Lab等机构提出了AudioStory,该工作通过整合大语言模型(LLM)与文本到音频(TTA)系统,构建了首个支持长篇叙事音频生成的统一框架。AudioStory的核心贡献在于其创新的解耦桥接机制:通过分离语义token(捕捉文本导向的音频语义)和残余token(保留声学细节与跨事件关联),显著提升了音频保真度与时序一致性;同时采用端到端渐进式训练策略,实现了LLM指令理解与扩散模型音频生成的协同优化,突破了传统零样本拼接方法的局限性。研究团队还构建了包含10K条多模态叙事音频的基准数据集AudioStory10K,覆盖自然声景与动画音效领域,并设计了涵盖指令遵循、一致性与生成质量的综合评估体系。实验表明,AudioStory在长音频生成任务中全面超越现有扩散模型(如AudioLDM2、TangoFlux)及多模态大模型(如NExT-GPT),其生成音频时长可达150秒,CLAP文本-音频对齐得分提升17.85%,同时在音频理解任务中展现出色能力。该框架支持视频配音、音频续写等扩展应用,通过LLM对叙事逻辑的分解与扩散模型对声学细节的精准建模,实现了从复杂多模态指令到连贯长音频的端到端生成,为沉浸式媒体创作提供了新范式。
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.20088
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20088
(39) StepWiser: Stepwise Generative Judges for Wiser Reasoning

论文简介:
由Meta FAIR、伊利诺伊大学厄巴纳-香槟分校和纽约大学的研究人员提出了StepWiser,该工作通过强化学习训练生成式判断器来监督多步推理过程中的逻辑有效性。针对现有过程奖励模型(PRMs)作为分类器无法提供解释、依赖静态数据集泛化能力差的问题,StepWiser将步骤判断转化为推理任务,采用三阶段方法:首先通过自分割技术将链式推理(CoT)切分为连贯的推理块(Chunks-of-Thought),接着基于蒙特卡洛rollouts的Q值估计为推理块分配目标奖励,最后通过强化学习训练生成式判断模型,使其在输出最终判断前生成推理链(reasoning about reasoning)。实验表明,StepWiser在ProcessBench基准测试中显著优于传统监督微调基线(如Math-Shepherd-PRM-7B等),其7B参数模型在Rel-Effective信号下达到61.9的平均准确率,相比判别式基线提升22.2%。该方法在推理时搜索和训练数据选择任务中也展现出优势:通过推理块重置策略,1.5B模型在MATH500数据集上的准确率从31.2%提升至36.9%;使用StepWiser筛选的训练数据使基线模型在NuminaMath-Heldout-1K上的准确率从60.1%提升至63.0%。研究证实了生成式推理链和强化学习训练对提升判断准确性的重要性,同时发现基于相对改进的奖励分配策略(如Rel-Effective)比绝对质量判断更有效。该工作为多步推理的监督提供了新的范式,通过元推理(meta-reasoning)显著提升了模型的逻辑验证能力。
Hugging Face 投票数:15
论文链接:
https://hf.co/papers/2508.19229
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19229
(40) Gaze into the Heart: A Multi-View Video Dataset for rPPG and Health Biomarkers Estimation

论文简介:
由Sber AI Lab等机构提出了Gaze into the Heart,该工作针对现有rPPG数据集规模小、隐私限制和条件单一的问题,构建了包含600名受试者、3600段同步多视角视频的大规模数据集MCD-rPPG。数据集通过消费级摄像头在静息和运动后两种状态下采集面部视频,并同步记录100Hz PPG信号及心电图、血压、血氧等13项健康指标,采用三摄像头多角度拍摄增强模型鲁棒性。研究团队开发了基于ROI特征提取的轻量级1D特征金字塔网络模型,在CPU端实现0.15秒/20秒视频的实时推理速度,较现有模型提升13%效率,同时保持与SOTA方法相当的PPG波形重建精度(MAE 0.68)和心率估计误差(4.86bpm)。实验表明该模型在跨数据集测试中表现稳定,尤其在多视角场景下展现出优于传统方法的适应性。数据集已开放获取并提供完整实验代码,有望推动远程医疗、智能设备健康监测等领域的算法研发与应用落地。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.17924
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17924
(41) CRISP: Persistent Concept Unlearning via Sparse Autoencoders

论文简介:
由Technion – Israel Institute of Technology等机构提出了CRISP,该工作提出一种基于稀疏自编码器(SAE)的参数高效持久概念遗忘方法,通过自动识别并抑制与目标概念强相关的SAE特征激活,在保持模型通用能力的同时实现安全关键领域的知识移除。针对现有方法在推理阶段干预无法持久修改模型参数的问题,CRISP采用对比激活分析技术,通过目标语料与良性语料的激活差异筛选出关键特征,并使用LoRA进行参数高效微调,最小化目标特征在有害数据上的激活同时保留其在良性数据中的作用。实验在Llama-3.1-8B和Gemma-2-2B模型上验证,CRISP在WMDP基准的生物安全和网络安全任务中表现最优,相较ELM和RMU方法在遗忘准确率上提升5-34个百分点,同时保持更高的知识保留率和生成流畅度。特征分析显示被抑制特征与目标概念(如病毒传播机制)呈现语义一致性,而良性特征(如基础生物学术语)得以保留。该方法在安全敏感领域的模型可控性提升方面具有显著优势,但受限于SAE特征可解释性及理论完备性。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.13650
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13650
(42) Wan-S2V: Audio-Driven Cinematic Video Generation

论文简介:
由HumanAIGC Team Tongyi Lab, Alibaba提出了Wan-S2V,该工作通过结合文本引导的全局运动控制与音频驱动的细节控制,在复杂影视场景中实现更具表现力和一致性的角色动画生成。针对现有音频驱动模型在多角色交互、真实肢体动作和动态镜头控制等场景中的局限性,研究团队基于Wan文本到视频生成框架构建了支持长视频生成的音频驱动模型。核心创新包括:1)构建包含影视级数据的混合数据集,通过精细化标注与多维度质量筛选提升数据有效性;2)采用FSDP与上下文并行的混合训练策略,实现14B参数模型的高效训练;3)提出基于FramePack的运动帧压缩方法,在降低计算成本的同时增强长视频时空一致性;4)设计分阶段训练流程,在语音视频预训练基础上进行影视数据微调,平衡文本控制与音频同步能力。实验显示,该方法在FID、FVD等指标上优于Hunyuan-Avatar、Omnihuman等SOTA模型,尤其在动态场景保持、多角色交互和长时一致性方面表现突出。研究还验证了模型在影视级长视频生成、精确唇同步编辑等场景的应用潜力,为复杂视听内容创作提供了新的技术路径。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.18621
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18621
(43) Diffusion Language Models Know the Answer Before Decoding

论文简介:
由香港理工大学、达特茅斯学院等机构提出了Prophet方法,该工作发现扩散语言模型(DLMs)存在早期答案收敛现象——在半数解码步骤内即可确定97%(GSM8K)至99%(MMLU)的正确答案。研究团队通过分析LLaDA-8B和Dream-7B的解码动态,揭示了答案token比推理token更早稳定的特点,并提出基于信心间隙的动态解码终止策略。Prophet通过监控top-2预测结果的置信度差异,在保证生成质量的前提下,动态决定是否提前结束解码。实验表明该方法可减少3.4倍解码步骤,同时在MMLU、GSM8K等任务中保持甚至提升准确率。该方法无需额外训练,通过设置动态风险阈值(τ_high=8.0, τ_mid=5.0, τ_low=3.0),在解码进度33%和67%处调整终止条件,实现了计算效率与生成质量的平衡。研究证实DLMs的解码本质是"何时停止采样"的最优决策问题,为加速扩散模型推理提供了新范式。代码已开源。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.19982
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19982
(44) AetherCode: Evaluating LLMs' Ability to Win In Premier Programming Competitions
论文简介:
由ByteDance和M-A-P等机构提出了AetherCode 该工作提出了一个用于评估大语言模型(LLMs)在顶级编程竞赛中表现的新基准。研究指出当前代码推理评估存在两大缺陷:现有基准的问题难度和覆盖范围不足,以及测试用例质量低导致评估偏差。AetherCode通过系统性收集国际信息学奥林匹克(IOI)和国际大学生程序设计竞赛(ICPC)等顶级赛事的456道题目,涵盖从简单到极端难度的分级体系,并采用自动化生成与专家验证相结合的方式构建了零误判率的测试用例集。该基准通过30,000余份人类提交代码验证,实现了100%真阳性率和真阴性率,确保评估结果的可靠性。实验表明,o4-mini-high和Gemini-2.5-Pro等顶级模型虽在极端难度问题上取得突破,但整体仍仅能解决小部分题目,凸显当前LLMs与人类顶尖选手的显著差距。该基准为代码推理研究提供了更具挑战性的评估标准,推动领域向更高水平发展。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.16402
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16402
(45) AgentScope 1.0: A Developer-Centric Framework for Building Agentic Applications
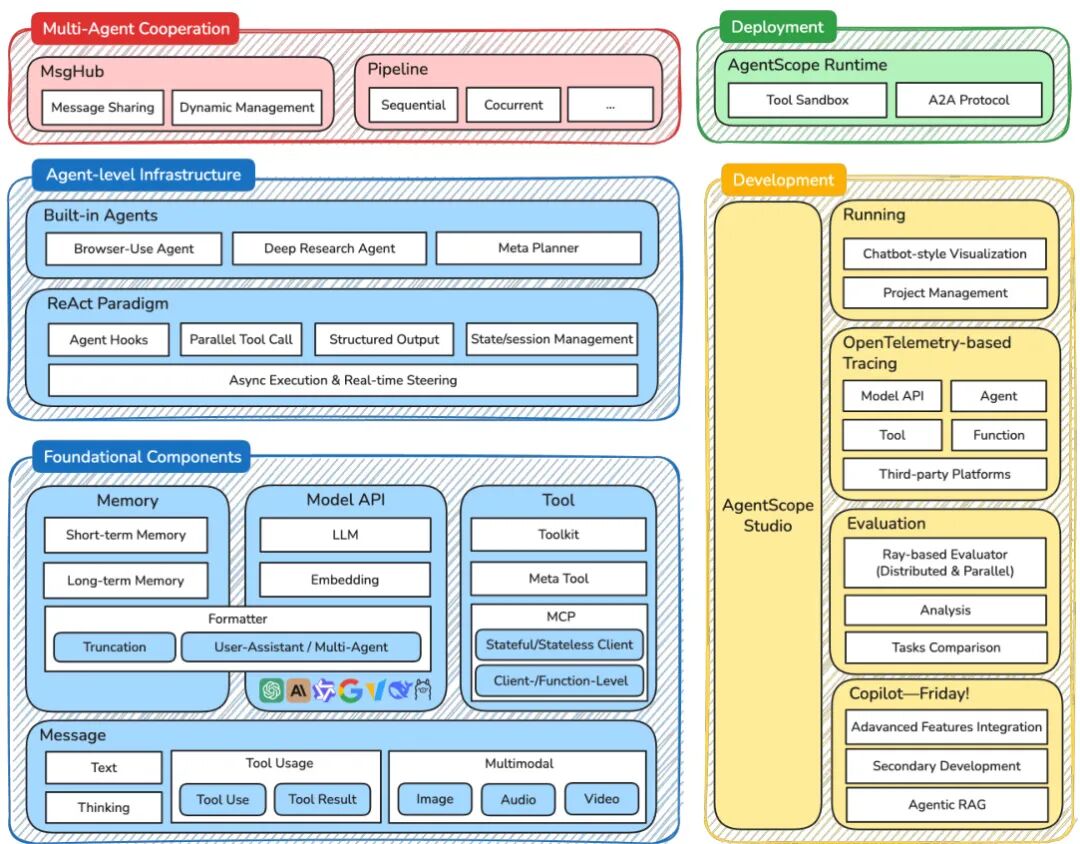
论文简介:
由 Alibaba Group 等机构提出了 AgentScope 1.0,该工作针对大语言模型(LLM)驱动的智能体应用开发,构建了一个以开发者为中心的框架,通过模块化组件和 ReAct 范式实现灵活高效的工具调用与环境交互。AgentScope 1.0 提供统一接口和可扩展模块,支持开发者集成最新模型和 Model Context Protocols(MCPs),并基于异步设计优化执行效率。框架抽象出消息、模型、记忆、工具四大基础组件,实现多模态信息传递、跨平台模型兼容及动态工具管理,其中工具模块支持本地函数与远程服务的统一注册与异步执行,同时通过工具分组机制缓解"工具选择困境"。在智能体层,框架采用 ReAct 架构作为核心交互范式,支持并行工具调用、实时中断响应及动态工具配置,内置的 Deep Research Agent、Browser-use Agent 和 Meta Planner 等智能体可直接应用于信息检索、网页操作和复杂任务规划场景。工程层面提供可视化 Studio 进行执行轨迹追踪与评估结果分析,集成分布式评估模块支持调试与生产环境无缝切换,并通过 Runtime 模块实现安全沙箱执行与生产级服务部署。该框架通过模块化设计、交互范式创新和全流程开发工具链,为构建可扩展、自适应的智能体应用提供了工程化基础。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.16279
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16279
(46) FastMesh:Efficient Artistic Mesh Generation via Component Decoupling
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.19188
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19188
(47) ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
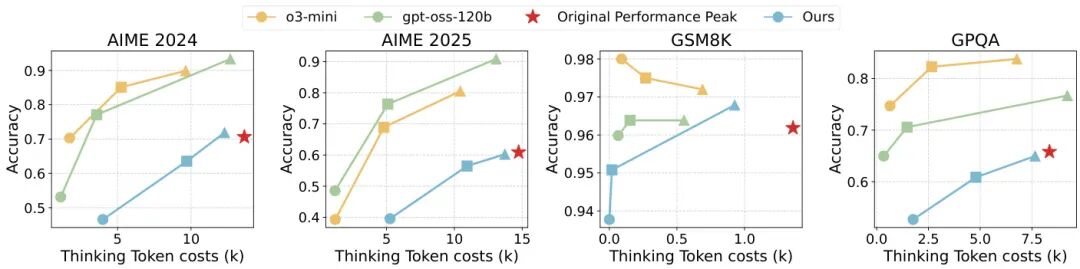
论文简介:
由 ByteDance Seed、复旦大学、上海交通大学和清华大学等机构提出了 ThinkDial,该工作首次实现了开源框架下类似 OpenAI gpt-oss 系列的可控推理能力。核心贡献在于构建了一个端到端训练范式,通过预算模式监督微调(Budget-Mode SFT)和两阶段预算感知强化学习(RL),使模型能够无缝切换三种推理模式:High 模式保持完整推理能力,Medium 模式减少 50% token 且性能下降 <10%,Low 模式减少 75% token 且性能下降 <15%。技术上,SFT 阶段通过构建多模式训练数据建立稳定的输出分布,RL 阶段采用自适应奖励塑形策略,针对不同模式设计响应长度奖励,并引入泄漏惩罚(Leak Penalty)防止推理内容溢出到答案部分。实验在数学推理基准(AIME、GSM8K)和跨领域任务(GPQA)上验证,ACT 评分显示模型在保持性能阈值的同时实现阶梯式 token 减少,且具备跨任务泛化能力。对比实验表明,该方法显著优于直接截断或无模式微调的基线,成功复现了闭源系统的可控推理曲线,为开源社区提供了首个可复现的离散推理控制方案。
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.18773
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18773
(48) UQ: Assessing Language Models on Unsolved Questions
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.17580
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17580
(49) PosterGen: Aesthetic-Aware Paper-to-Poster Generation via Multi-Agent LLMs

论文简介:
由 Stony Brook University 等机构提出了 PosterGen,该工作针对学术海报生成中忽视设计美学的问题,提出了一种基于多智能体大语言模型的美学感知框架。现有方法在布局重叠、色彩单调、排版混乱等方面存在显著缺陷,而 PosterGen 通过四个协作智能体(解析与策展、布局、风格、渲染)构建了完整的生成流程:解析器从论文中提取结构化内容,策展器基于 ABT 叙事框架规划故事板,布局器通过 CSS 盒模型实现三栏平衡布局,风格器应用主题色与排版层级,最终生成符合 WCAG 对比度标准的海报。研究引入了包含布局平衡、色彩协调、字体一致性等11项指标的 VLM 评估体系,实验表明 PosterGen 在保持内容保真度的同时,设计质量评分较 SOTA 方法提升0.17-0.18分(5分制),其中主题一致性提升0.5-0.8分。该方法通过专业设计师式的工作流重构,首次系统性地将学术海报的四大核心设计原则(叙事性、布局结构、色彩理论、排版层级)转化为可执行的智能体逻辑,使生成的海报在视觉吸引力、信息层次和空间利用率方面达到演讲级标准,显著降低人工调整需求。
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.17188
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17188
(50) DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model

论文简介:
由伊朗伊斯法罕医科大学联合伊斯法罕神经科学研究中心及伊斯法罕理工大学提出了DrugReasoner,该工作基于LLaMA架构开发了可解释的药物审批预测模型,通过组相对策略优化(GRPO)微调并融合链式推理(CoT)机制,实现小分子化合物审批概率预测及决策逻辑可视化。DrugReasoner创新性地整合分子描述符与结构相似化合物的对比推理,输入候选分子特征后,模型同步输出审批预测标签、置信度评分及分步推理依据。在2255对已批准/未批准分子数据集上训练后,模型在验证集取得0.732 AUC和0.729 F1值,测试集保持0.725 AUC和0.718 F1值,显著优于逻辑回归、SVM、KNN等传统基线模型,并与XGBoost性能相当。在ChemAP研究使用的外部独立数据集(17批准/8未批准药物)上,DrugReasoner以0.728 AUC和0.774 F1值超越ChemAP(0.64 AUC)及所有基线模型,同时保持0.857高精度和0.720平衡准确率。该模型通过分子特征而非SMILES直接输入的设计规避数据泄露风险,采用GRPO强化学习框架优化多目标奖励函数(含预测准确性、格式合规性、可解释性及置信度校准),在4-bit量化和LoRA适配下完成8B参数模型训练。研究证实推理增强型大语言模型在药物审批预测中兼具预测效能与决策透明度优势,为早期药物研发投资决策提供新型AI工具。
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2508.18579
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18579
(51) ReportBench: Evaluating Deep Research Agents via Academic Survey Tasks

论文简介:
由 ByteDance 等机构提出了 ReportBench,该工作通过构建系统化评估框架,针对大语言模型生成的研究报告内容质量进行多维度评测。研究聚焦两个核心维度:引用文献的质量与相关性,以及报告陈述的忠实性与真实性。通过逆向提示工程将 arXiv 高质量综述论文转化为领域特定提示,形成包含 100 个学术调研任务的评估语料库,并开发自动化评估框架实现三重验证:基于引用文献的语义一致性匹配、非引用陈述的多模型投票验证,以及引用覆盖率与陈述事实性的量化分析。实验表明,商业级研究代理(如 OpenAI Deep Research 和 Google Gemini)在内容覆盖和事实校准方面显著优于基础模型,但存在过度引用、引用幻觉和陈述偏差等问题。该基准通过可复现的数据构建流程和模块化评估体系,为学术调研类 AI 系统的可靠性监测提供了标准化工具,相关代码与数据已开源。
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2508.15804
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15804
(52) Selective Contrastive Learning for Weakly Supervised Affordance Grounding

论文简介:
由韩国成均馆大学等机构提出了Selective Contrastive Learning方法,该工作通过引入选择性原型对比学习和像素对比学习,自适应地在物体和部分级别学习可操作区域的相关线索。针对弱监督场景下可操作区域难以精确定位的问题,研究者首先利用CLIP模型生成对象亲和力图,通过跨视角交叉参考发现精确的细粒度线索。当检测到可靠的细粒度线索时,模型通过原型对比学习区分可操作部分与其他无关区域;当线索不可靠时,则切换至物体级别学习,引导模型关注目标物体本身。同时,像素对比学习通过监督可操作区域内的像素特征,进一步提升定位精度。实验结果表明,该方法在AGD20K和HICO-IIF数据集上均取得显著提升,特别是在未见物体场景下表现出更强的泛化能力。通过结合对比学习和CLIP的零样本能力,该方法有效缓解了传统分类任务对无关区域的过度依赖,为弱监督可操作性定位提供了新的解决方案。
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2508.07877
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07877
(53) Mind the Third Eye! Benchmarking Privacy Awareness in MLLM-powered Smartphone Agents

论文简介:
由山东大学、香港科技大学等机构提出了SAPA-Bench,该工作构建了首个大规模智能手机代理隐私意识评估基准,涵盖7138个真实场景并标注隐私类型、敏感等级及位置信息。研究团队通过五项专用指标(隐私识别率PRR、定位率PLR、等级意识PLAR、类别意识PCAR、风险响应RA)系统评测了7款主流智能手机代理,发现现有代理普遍隐私保护能力不足,即使在明确提示下性能仍低于60%。实验表明闭源模型(如Gemini 2.0-flash RA达67%)显著优于开源模型(如Show-UI RA仅18.77%),且隐私检测能力与场景敏感等级正相关。研究还证实通过增强提示信号可有效提升代理对隐私风险的响应能力(如Gemini在显式提示下RA提升至67.14%)。该工作揭示了当前智能手机代理在隐私保护方面的核心缺陷,强调需在功能与隐私间寻求平衡,并为未来研发更安全的智能代理提供了标准化评估框架。
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.19493
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19493
(54) Turning the Spell Around: Lightweight Alignment Amplification via Rank-One Safety Injection
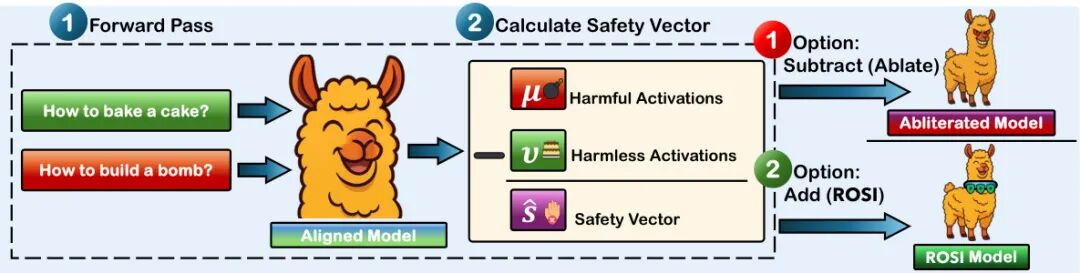
论文简介:
由沙特阿拉伯阿卜杜拉国王科技大学(KAUST)等机构提出了Rank-One Safety Injection(ROSI),该工作提出了一种无需微调的轻量级方法,通过在残差流权重矩阵中注入秩一安全方向来增强大语言模型的安全对齐能力。ROSI利用有害与无害指令对激活差异计算安全方向,并通过简单的向量投影永久强化模型拒绝有害请求的能力。实验表明,ROSI在保持模型通用性能的前提下,显著提升了LLaMA、Qwen等主流模型对有害请求的拒绝率(最高提升18.2%),同时将对抗攻击成功率降低34-54个百分点。更关键的是,ROSI可作为"最后一公里"安全工具,成功重构被刻意去安全化的Dolphin系列模型,使其安全响应率从50%提升至86%-100%,且基准测试性能波动不超过0.5%。该方法验证了通过解释性研究定位的概念方向进行权重操控的有效性,为低成本安全增强提供了新范式。
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.20766
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20766
(55) End-to-End Agentic RAG System Training for Traceable Diagnostic Reasoning
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.15746
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15746
(56) Do What? Teaching Vision-Language-Action Models to Reject the Impossible

论文简介:
由加州大学伯克利分校等机构提出了Instruct-Verify-and-Act(IVA)框架,该工作首次探索了视觉-语言-动作(VLA)模型在机器人领域中处理虚假前提指令的能力。研究者针对现有VLA模型无法识别用户指令中引用的不存在对象或不可行条件的问题,构建了包含正例与虚假前提指令的半合成数据集,通过指令微调训练出能够检测不可行指令、生成语言澄清并提供替代方案的VLA模型。IVA框架在保留视觉编码器和语言编码器的前提下,采用LoRA适配器对自回归解码器进行端到端微调,实现了在检测阶段识别虚假前提指令(In-Domain场景检测准确率100%,Out-of-Domain场景97.78%),在执行阶段通过自然语言反馈修正指令(如"未检测到安全箱,是否指代罐子?"),并在真实前提任务中保持与基线模型相当的执行成功率(42.67% vs 38.67%)。实验在9个RLBench任务中验证,IVA在虚假前提场景的成功率较基线提升50.78%,同时将虚假前提检测准确率提升97.56%,证明了该方法在保持常规任务性能的同时,显著增强了机器人应对不可行指令的能力。该研究为语言感知型机器人在现实复杂环境中的安全交互提供了新思路,但目前仍受限于仿真数据的多样性和真实场景的部署验证。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.16292
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16292
(57) MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment

论文简介:
由 Sharif University of Technology 等机构提出了 MEENA (PersianMMMU),该工作构建了首个面向波斯语视觉语言模型(VLMs)的多模态多语言教育考试评估数据集。MEENA 包含约 7,500 个波斯语和 3,000 个英语问题,覆盖推理、数学、物理、图表、艺术与文学等学科,涵盖从小学到高中各教育阶段。数据集提供难度分级、详细答案、陷阱选项标识等丰富元数据,并通过原生波斯语内容保留文化特征,同时采用双语结构支持跨语言模型评估。研究团队设计了零样本、少样本、视觉描述、错误图像和无图像等五种实验场景,对 GPT-4o、Gemini-2.0 等模型进行系统测试,发现知识型任务准确率显著高于推理型任务(波斯语差距达 10-19%),Gemini-2.0 在检测图像不匹配方面表现最优(波斯语检测率超 GPT-4o Mini 400 例),而 GPT-4o 系列在图像存在性判断上更稳定。实验还揭示模型在化学和数学高难度问题中准确率随复杂度提升显著下降,凸显多模态模型在复杂推理和领域知识获取上的现存挑战。该数据集的建立为非英语语种多模态模型评估提供了重要基准,推动跨文化多模态人工智能研究发展。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.17290
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17290
(58) MotionFlux: Efficient Text-Guided Motion Generation through Rectified Flow Matching and Preference Alignment
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.19527
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19527
(59) Multi-View 3D Point Tracking
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.21060
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21060
(60) SEAM: Semantically Equivalent Across Modalities Benchmark for Vision-Language Models
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.18179
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18179
(61) Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks

论文简介:
由东京工业大学等机构提出了Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks,该工作系统研究了MoE语言模型稀疏性对推理任务的影响。研究发现:在固定计算预算下,增加专家数量虽能降低预训练损失,但推理任务(如GSM8K数学题)的准确率会在参数规模超过阈值后出现明显下降,而记忆类任务(如TriviaQA)则持续提升。实验通过控制变量法验证了top-k路由策略本身对推理性能影响有限,关键在于活跃参数量与总参数量的平衡。当活跃参数量较高时,反而需要降低稀疏度(提高模型密度)才能获得最佳推理表现。有趣的是,测试时增加采样次数(Self-Consistency)或强化学习微调(GRPO)等后处理手段,并不能消除这种由架构稀疏性导致的性能下降。研究还揭示了tokens per parameter(TPP)对任务的敏感性:记忆任务偏好低TPP(更多参数),而推理任务存在约20的最优TPP值。代码生成任务(HumanEval)也表现出与数学推理类似的稀疏性敏感特征。这些发现挑战了"专家越多越好"的传统认知,表明在MoE架构中,推理能力的提升需要更精细的稀疏度控制,尤其在高计算预算下需转向更密集的专家配置。相关代码和模型已开源,为后续MoE架构设计提供了重要参考。
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.18672
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18672
(62) Distilled-3DGS:Distilled 3D Gaussian Splatting

论文简介:
由 Great Bay University 等机构提出的 Distilled-3DGS 提出了一种基于知识蒸馏的轻量化 3D Gaussian Splatting 框架,通过多教师模型引导优化学生模型,在保持高渲染质量的同时显著降低存储需求。该方法针对传统 3DGS 需要大量高斯分布导致内存消耗高的问题,创新性地引入知识蒸馏机制,采用 vanilla 3DGS、噪声增强和 dropout 正则化三个教师模型生成伪标签监督学生模型训练。为解决 3DGS 点云无序性带来的蒸馏难题,研究者提出空间分布一致性损失,通过体素直方图对齐师生模型的几何结构分布,实现结构感知的特征迁移。实验表明,在 Mip-NeRF 360、Tanks&Temples 等数据集上,Distilled-3DGS 在 PSNR、SSIM 和 LPIPS 指标上全面超越 Plenoxels、Instant-NGP 等传统方法,相较原始 3DGS 在减少 86%-89% 高斯数量的情况下仍提升 PSNR 0.55-0.62dB,特别在细节保留和存储效率间取得优异平衡。消融实验验证了多教师模型互补性和空间分布蒸馏的有效性,为资源受限场景下的高质量视图合成提供了新思路。
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.14037
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14037
(63) OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.21066
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21066
(64) Persuasion Dynamics in LLMs: Investigating Robustness and Adaptability in Knowledge and Safety with DuET-PD
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.17450
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17450
(65) TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill & Decode Inference

论文简介:
由北京大学、腾讯等机构提出了TPLA(Tensor Parallel Latent Attention),该工作针对多头潜注意力(MLA)在张量并行(TP)场景下内存效率不足的问题,提出了一种新型注意力机制。研究发现,传统MLA在TP中需将完整潜向量复制到每个设备,导致内存开销大,而TPLA通过将潜表示和输入维度跨设备分割,实现分布式注意力计算后通过all-reduce聚合结果,既保留了KV缓存压缩优势,又显著提升TP效率。与分组潜注意力(GLA)不同,TPLA通过数学重参数化确保每个注意力头仍能访问完整潜表示,维持模型表达能力。该方法可直接兼容预训练MLA模型(如DeepSeek系列),通过正交变换(如Hadamard变换或PCA)减少跨设备干扰,在32K上下文长度下对DeepSeek-V3和Kimi-K2分别实现1.79×和1.93×解码加速,同时在常识推理和LongBench基准测试中保持性能稳定。实验表明,TPLA结合预填充/解码分离技术,在预填充阶段使用MLA减少计算量,解码阶段启用TPLA降低内存带宽瓶颈,进一步优化了端到端推理效率。
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2508.15881
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15881
(66) ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models

论文简介:
由南京大学等机构提出了ObjFiller-3D,该工作提出了一种基于视频扩散模型的多视角一致3D补全方法,通过适配视频编辑模型解决3D场景补全中的跨视角不一致问题。现有方法依赖多视角2D图像补全,但存在纹理模糊和空间不连续等缺陷。ObjFiller-3D创新性地将视频扩散模型VACE引入3D补全任务,通过分析3D与视频数据的表征差异,采用低秩适应(LoRA)技术将视频模型迁移至3D领域,并设计了360度循环视频生成策略。方法通过渲染3D物体为多视角视频序列,利用视频模型的时序一致性保持几何和纹理的跨视角连贯性,同时支持参考图像引导的条件生成。实验显示,在Objaverse等数据集上,ObjFiller-3D在PSNR(26.6 vs 15.9)和LPIPS(0.19 vs 0.25)等指标上显著超越NeRFiller和Instant3dit等现有方案,重建时间缩短至10分钟内。该方法还拓展至3D场景补全和对象编辑任务,在文化遗产修复等场景展现应用潜力,为高质量3D内容生成提供了新范式。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.18271
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18271
(67) CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.21046
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21046
(68) ST-Raptor: LLM-Powered Semi-Structured Table Question Answering

论文简介:
由上海交通大学、清华大学、人民大学等机构提出了ST-Raptor,该工作针对现实场景中广泛存在的半结构化表格(如Excel报表、医疗记录等)的问答难题,创新性地构建了层次化正交树(HO-Tree)结构来精确建模复杂表格布局(包含合并单元格、嵌套表头等),并通过树操作流水线实现大语言模型的精准问答。核心贡献包括:①提出HO-Tree树状模型,通过元数据树(MT)和主体树(BT)的双树结构,有效捕捉表格的层级与正交关系;②设计基于视觉语言模型(VLM)和启发式规则的HO-Tree构建算法,解决表头识别与子表分割难题;③开发问题分解与流水线生成机制,通过语义对齐和列类型感知标记策略提升大规模表格检索精度;④引入两阶段验证机制,前向验证确保操作执行正确性,后向验证通过问题重构评估答案可靠性;⑤构建包含102个真实场景表格、764个问题的SSTQA数据集,其嵌套深度和复杂度显著高于现有基准。实验显示ST-Raptor在SSTQA上以72.39%的准确率超越9种基线方法(如GPT-4o、TableLLaMA等),在复杂表格场景下领先优势达20%,验证了树结构建模与操作流水线在半结构化表格问答中的有效性。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.18190
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18190
(69) Sketch3DVE: Sketch-based 3D-Aware Scene Video Editing
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.13797
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13797
(70) TaDiCodec: Text-aware Diffusion Speech Tokenizer for Speech Language Modeling
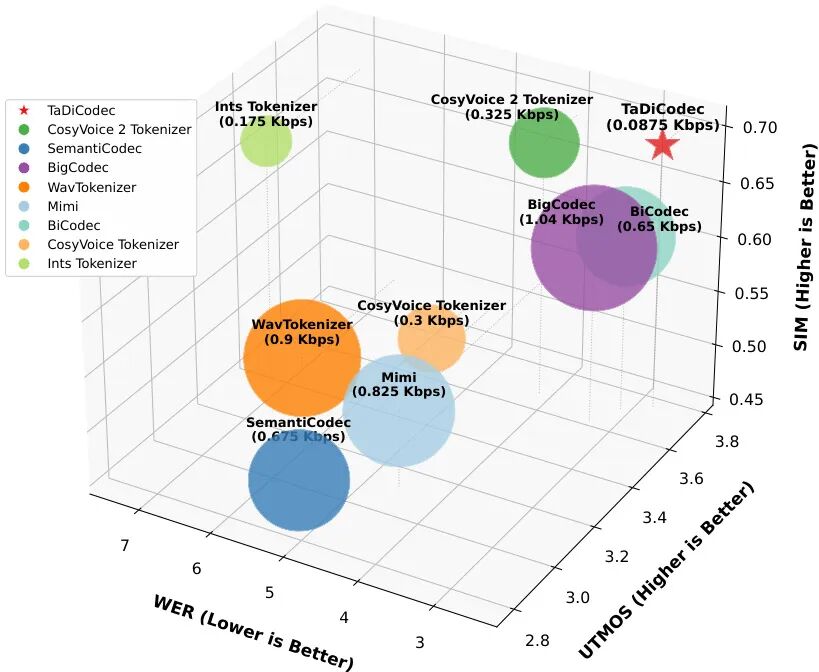
论文简介:
由香港中文大学深圳等机构提出了 TaDiCodec,该工作设计了一种基于扩散自编码器的文本感知语音分词器,通过端到端优化和文本引导解码实现了极低比特率(0.0875 kbps)的语音离散表示。TaDiCodec 采用二值球面量化(BSQ)和扩散损失统一量化与重构过程,避免了传统方法依赖的多层残差量化、对抗训练或两阶段流程。其核心创新在于:1)通过扩散自编码器实现端到端优化,仅需单一损失函数即可完成离散化与重构;2)引入文本和提示信息引导解码,在6.25Hz极低帧率下保持高保真重构质量;3)在零样本语音合成任务中验证了生成友好性,显著缩小重构与生成的性能差距。实验表明,TaDiCodec 的词错误率(WER)达2.73,说话人相似度(SIM)达0.69,语音质量(UTMOS)达3.73,优于同等比特率的现有方法。在零样本TTS任务中,其自回归模型在英语和中文测试集上分别取得2.28和1.19的WER,且支持0.29实时率的高效推理。该方法为语音语言模型的离散表示学习提供了高效且生成友好的解决方案。
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.16790
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16790
(71) Select to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
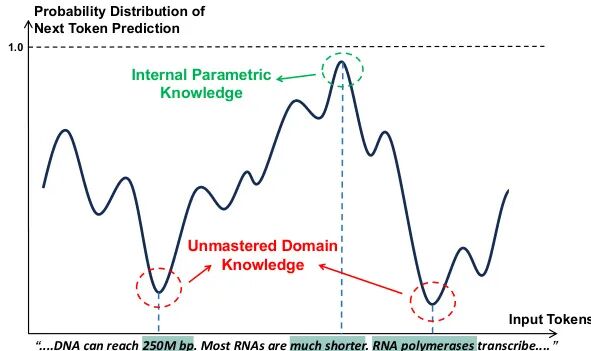
论文简介:
由中科大、百度等机构提出了Select2Know(S2K),该工作提出了一种基于内部-外部知识自选择策略的领域问答增强框架。针对大语言模型在领域问答中知识掌握不全、检索增强易引入噪声、持续预训练成本高等问题,S2K通过三个创新模块实现高效领域适应:首先采用token-level自选择机制融合模型内部参数知识与外部文档知识,构建高质量训练数据;其次设计选择性监督微调(Selective SFT),基于预测不确定性动态调整训练权重,重点优化未掌握知识;最后引入结构化推理数据生成流程和GRPO强化学习,提升复杂推理能力。实验在医学(MedQA)、法律(JECQA)、金融(FinanceIQ)三大领域验证,S2K在Avg@5、Cons@5等指标上全面超越检索增强(如Self-RAG)、强化学习(如PPO)等方法,性能比肩BioMistral等百亿级领域预训练模型,但训练数据量减少2-3个数量级。该框架通过显式建模知识融合过程,在保持低训练成本的同时实现跨领域泛化能力,为垂直领域知识增强提供了新范式。
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.15213
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15213
(72) MovieCORE: COgnitive REasoning in Movies

论文简介:
由台湾大学、NVIDIA、清华大学、政治大学等机构提出了MovieCORE,该工作构建了一个面向电影深层认知理解的视频问答数据集,通过多智能体协作生成高阶思维问题,并提出ACE模块提升现有模型推理能力,推动视频理解向人类级叙事分析迈进。
MovieCORE数据集包含986个电影片段及其对应的4930个问答对,聚焦于角色心理、情感共鸣和因果推理等深层认知维度。研究团队创新性地采用多智能体协作的标注流程:首先利用MiniCPM-v2.6提取视频上下文,再通过Critique Agent协调VQA专家、怀疑论研究者、侦探和元评审等AI代理进行多轮讨论,最终生成平均句法复杂度达5.88、认知层级达4.9(Bloom分类)的高质量问答对,其中99.2%的问题属于高阶认知范畴。
针对现有VLM模型在深层推理上的不足,团队提出ACE(Agentic Choice Enhancement)插件,在推理阶段通过轻量级语言模型(如Llama-3.2-1B)对候选答案进行二次筛选,使InstructBLIP等模型在MovieCORE上的综合评分提升25%。实验表明,当前主流模型在MovieCORE上表现显著低于专为表层理解设计的MovieChat-1k数据集,即使经过全监督训练,最优模型HERMES的深度推理得分仅3.52(满分5),凸显现有技术在叙事理解上的局限性。
该工作通过构建认知挑战基准和多智能体协作范式,为视频理解领域开辟了系统2思维研究的新方向,相关数据集、代码和评估框架已开源。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.19026
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19026
(73) DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.20033
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20033
(74) Limitations of Normalization in Attention Mechanism

论文简介:
由卢森堡大学和伦敦数学科学研究所提出了关于注意力机制中归一化局限性的理论与实证研究,该工作通过数学建模与实验揭示了softmax归一化在长序列处理中的三大核心问题:当选择的token数量随序列长度增长时,模型区分有效token的能力显著下降,注意力分布趋于均匀化;在低温度参数下梯度敏感度激增导致训练不稳定;并首次从几何角度证明单个注意力头最多只能有效区分约80%的高权重token。研究团队通过非渐近性理论推导了token表示距离的上界,量化了"softmax瓶颈"的数学本质——当top-N选择比例趋近序列长度时,表示距离必然坍缩至零;基于球面嵌入假设的几何分析表明,即使在理想条件下,注意力头的几何分辨能力也存在硬性上限;梯度敏感性分析则揭示了温度参数与Jacobian范数的反比关系,解释了低温度下训练不稳定的根本原因。实验部分基于GPT-2模型的144个注意力头进行验证,结果完美匹配理论预测:当top-N超过序列长度6%时注意力分布趋近均匀,几何可区分token比例稳定在70-85%区间,梯度范数严格遵循1/(4T)衰减规律。研究建议在长序列场景中优先采用稀疏归一化方法,将活跃token集控制为序列长度的亚线性函数,并通过监控注意力熵值判断头容量饱和状态,为改进Transformer架构提供了可量化的理论指导。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.17821
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17821
(75) MeshSplat: Generalizable Sparse-View Surface Reconstruction via Gaussian Splatting

论文简介:
由中科大和上海人工智能实验室提出了MeshSplat,该工作提出了一种基于高斯溅射的通用稀疏视图表面重建框架。针对现有方法在极端稀疏输入下几何恢复困难的问题,研究者创新性地将2D高斯溅射(2DGS)作为连接新视角合成与几何先验学习的桥梁,通过自监督方式从渲染任务中学习可泛化的几何特征。核心贡献包括:1)设计了端到端网络预测像素对齐的2DGS,通过深度图和法线图驱动高斯位置与朝向,实现无需3D标注的表面重建;2)提出加权Chamfer距离损失(WCD Loss),通过视图间点云匹配置信度加权,显著提升重叠区域的几何一致性;3)构建不确定性引导的法线预测网络,利用单目法线估计器监督高斯朝向,确保表面法线对齐精度。实验表明,该方法在ScanNet和RE10K数据集上较MVSplat等SOTA方法在CD指标上分别提升30.3%和12.8%,在跨数据集泛化任务中F1值提升208%,同时保持0.1秒级实时渲染速度。该研究为稀疏视角下的高效高质量表面重建提供了新范式。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.17811
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17811
(76) Taming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference

论文简介:
由 ByteDance Seed 和新加坡国立大学等机构提出了 HeteroScale,该工作针对异构且解耦的大语言模型(LLM)推理场景中的资源调度难题,提出了一种协调的自动扩缩容框架。传统自动扩缩容工具在应对现代 Prefill-Decode(P/D)解耦架构时存在三大核心挑战:异构硬件利用率低效、网络带宽瓶颈以及预取与解码阶段间的资源失衡。HeteroScale 通过拓扑感知调度器与基于大规模生产数据的度量驱动策略,实现了硬件适配、网络约束优化与架构平衡的协同管理。其核心创新包括:1)异构资源管理框架,将 P/D 比例与硬件需求作为调度约束,智能匹配服务角色与硬件类型;2)网络感知调度抽象,通过部署组(Deployment Group)和 RDMA 子组(Subgroup)保障低延迟 KV 缓存传输并优化高带宽硬件使用;3)基于生产数据的度量分析,发现解码端 Tokens-Per-Second(TPS)是唯一可靠的联合扩缩信号,可同步调整预取与解码资源池。该系统在字节跳动数万张 GPU 的生产环境中部署后,平均 GPU 利用率提升 26.6 个百分点,每日节省数十万 GPU 小时,同时通过维持严格的 P/D 比例和网络亲和性,在解耦 MoE 场景下仍保持服务级别目标(SLO)达标,为大规模 LLM 推理的资源效率优化树立了新基准。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.19559
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19559
(77) Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning

论文简介:
由耶鲁大学、哈佛大学、西北大学和Allen Institute of AI等机构提出了SCIREAS和KRUX,该工作构建了首个跨领域的科学推理统一评估基准,并通过知识控制实验揭示了大模型科学问题解决中知识检索瓶颈及推理增强机制。
################# 分割行,以下为论文原始材料 #############
该研究针对科学问题解决中知识与推理能力的协同作用展开系统性分析。首先构建了包含10个主流科学基准的SCIREAS套件,覆盖物理、化学、生物等8大学科,支持多模态问题形式;并从中筛选出高推理密度的SCIREAS-PRO子集,通过对比不同推理预算下的模型表现,发现顶尖模型在复杂推理任务上仍存在显著性能差距。研究团队进一步提出KRUX分析框架,通过从推理链中提取"知识要素"(KIs)并注入上下文,首次实现了对模型知识利用能力的可控评估。关键发现包括:1)提供高质量外部知识可使基础模型性能超越推理增强模型,表明知识检索是当前瓶颈;2)推理模型在获得相同外部知识后仍能持续提升,验证了知识增强的互补性;3)数学推理微调能显著提升基础模型对科学知识的提取能力,证明链式推理可优化知识激活路径。实验还表明,数学与STEM数据混合微调的Qwen-BOTH模型在科学推理任务上表现最优。研究最后发布了8B参数的SCILIT01基线模型,为开源科学推理研究提供基准。这些发现为构建兼具深度知识与复杂推理能力的科学辅助系统提供了重要设计依据。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.19202
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19202
(78) ROSE: Remove Objects with Side Effects in Videos

论文简介:
由浙江大学、KunByte AI、北京大学和香港大学等机构提出了ROSE(Remove Objects with Side Effects),该工作针对视频中物体及其副作用(如阴影、反射、光照变化等)的去除问题,通过构建3D渲染驱动的自动化数据生成流程,解决了真实场景配对数据稀缺的难题。研究者系统性地将物体副作用归纳为五类典型场景(阴影、反射、光照、半透明、镜面),并基于扩散Transformer设计了参考式擦除模型,通过引入差异掩码预测机制显式监督副作用区域的识别。实验表明,ROSE在自建的ROSE-Bench基准(含合成与真实数据)上显著优于现有方法,尤其在复杂环境交互场景中展现出更强的泛化能力,为视频编辑中物理一致性修复提供了新范式。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.18633
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18633
(79) Training Language Model Agents to Find Vulnerabilities with CTF-Dojo

论文简介:
由Monash大学和AWS AI Labs联合提出的CTF-Dojo是一个面向网络安全任务的大规模可执行环境,首次提供了658个完全功能化的CTF挑战,通过容器化技术实现可复现的训练环境。该工作核心贡献在于开发了CTF-Forge自动化管道,能够将公开的CTF资源在数分钟内转换为Docker镜像,效率较人工配置提升98%,解决了传统漏洞检测环境配置耗时的问题。研究团队通过结合CTF解题指南作为推理提示、动态环境参数扰动以及多教师模型轨迹融合等关键技术,仅用486条高质量执行轨迹便使Qwen系列模型在InterCode-CTF、NYU CTF Bench和Cybench三大基准测试中取得显著提升,其中32B模型达到31.9%的Pass@1成绩,超越Claude-3.5-Sonnet等前沿模型,创下开源模型新纪录。实验表明,CTF-Dojo训练的模型在密码学、逆向工程和二进制漏洞利用等任务中表现突出,特别是通过环境多样性增强(如端口随机化、路径扰动)使挑战解决率提升24.9%。该研究证实了基于真实执行反馈的代理训练范式在网络安全领域的有效性,为构建自主渗透测试系统提供了可扩展的解决方案。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.18370
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18370
(80) Explain Before You Answer: A Survey on Compositional Visual Reasoning

论文简介:
由Monash University、Stanford University、University of Washington等机构的研究者提出的《Explain Before You Answer: A Survey on Compositional Visual Reasoning》系统性地总结了2023至2025年间260余篇关于组合视觉推理(CVR)的论文,填补了该领域缺乏专门综述的空白。该工作通过构建统一分类体系、绘制技术演进路线图及提出关键挑战,为CVR研究提供了基础框架。论文将CVR发展划分为五个阶段:从提示增强的语言中心方法(Stage I)、工具增强的大语言模型(Stage II)到工具增强的视觉语言模型(Stage III),再到链式推理视觉语言模型(Stage IV),最终迈向统一的代理视觉语言模型(Stage V)。每个阶段均分析了代表性模型的架构设计、技术突破及局限性,如Stage V的SEAL、ZoomEye等模型通过动态视觉探索和内部视觉想象提升推理能力。研究还系统梳理了60+基准测试(如CLEVR、GQA、V*Bench)及评估指标(如IoU、CLIP相似度、步骤级一致性),揭示了当前评估体系在中间推理步骤验证和难度分级上的不足。论文指出CVR面临的核心挑战包括LLM推理的局限性(缺乏物理模拟能力)、幻觉问题(语言偏差导致错误结论)、演绎推理的单一性(需引入归纳/溯因推理)、数据效率(合成数据噪声与标注成本)、工具集成瓶颈(跨模态对齐与计算开销)及评估污染(语言捷径与分布偏差)。未来方向聚焦于整合世界模型(支持反事实推理)、人机协作推理(动态反馈机制)、多模态评估协议(步骤级监督与难度感知评分)等。该综述通过全面的技术分析和前瞻性洞察,为构建可解释、可泛化、与人类认知对齐的视觉推理系统提供了关键参考。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.17298
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17298
(81) Dress&Dance: Dress up and Dance as You Like It - Technical Preview
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.21070
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21070
(82) FakeParts: a New Family of AI-Generated DeepFakes
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.21052
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21052
(83) Neither Valid nor Reliable? Investigating the Use of LLMs as Judges
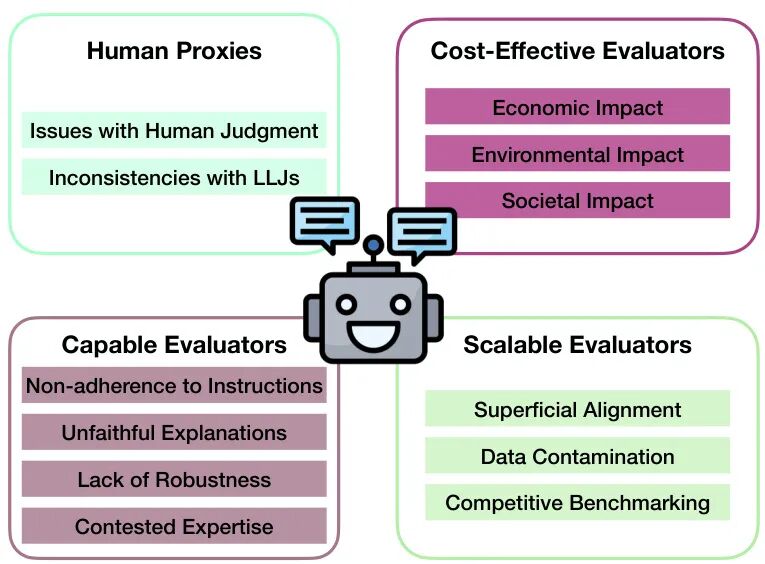
论文简介:
由McGill University、Mila - Quebec AI Institute和Statistics Canada等机构提出了关于大语言模型(LLM)作为评判者(LLJs)的有效性及可靠性研究,该工作基于社会科学测量理论框架,系统性分析了LLMs在自然语言生成(NLG)评估中被广泛采用的四个核心假设及其潜在缺陷。研究指出,当前LLJs的广泛应用可能缺乏充分验证,其作为人类判断代理、评判能力、可扩展性和成本效益等关键假设均面临多重挑战。通过文本摘要、数据标注和安全对齐三个典型应用场景的案例分析,论文揭示了LLMs在指令遵循偏差、评估解释性不足、对抗攻击脆弱性以及社会偏见传递等方面的局限性。研究强调,现有NLG评估实践中人类判断标准的不一致性、LLJs对基准数据的污染风险、以及自动化评估带来的伦理问题(如劳动力替代和环境成本)均可能削弱其测量效度。作者呼吁建立更严谨的评估规范,包括任务特异性设计、评估流程透明化及社会影响评估,以平衡效率与责任。该研究为推动LLM评估工具的负责任应用提供了理论依据和实践指导。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.18076
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18076
(84) Learnable SMPLify: A Neural Solution for Optimization-Free Human Pose Inverse Kinematics

论文简介:
由复旦大学、上海人工智能实验室、浙江大学等机构提出了Learnable SMPLify,该工作提出了一种神经逆运动学框架,通过单次前向回归替代传统SMPLify的迭代优化过程,在保持高精度的同时实现近200倍速度提升。针对神经逆运动学的数据构建与泛化能力两大核心挑战,研究者提出基于时序相邻帧的初始化-目标对构建策略,通过人体中心归一化消除全局位姿差异,并采用残差学习约束解空间。该方法支持序列推断和插件式后处理两种模式,在AMASS、3DPW、RICH等多数据集上验证有效性,作为LucidAction数据集上现有方法的后处理模块时展现出模型无关的泛化能力。实验表明,Learnable SMPLify在保持200倍加速的同时,相比SMPLify在各数据集上PVE误差降低超5mm,且在跨数据集测试中表现稳健。代码已开源至GitHub,为人体姿态逆运动学问题提供了兼具效率与精度的新基线方案。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.13562
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13562
(85) Training a Foundation Model for Materials on a Budget

论文简介:
由MIT等机构提出了Nequix,该工作通过简化NequIP架构并结合现代训练技术,在显著降低计算成本的同时实现了高精度材料建模。Nequix采用等变根均方层归一化(RMSNorm)和JAX框架实现,仅含70万参数,训练耗时500个A100 GPU小时。在Matbench-Discovery和MDR Phonon基准测试中,Nequix均位列第三,但训练成本不足其他方法的四分之一,且推理速度比当前最优模型快10倍。其核心创新包括:1)简化NequIP架构并引入等变层归一化;2)动态批量训练与Muon优化器组合的高效训练管道;3)在保持高精度的同时实现资源友好型训练。实验表明,Nequix在材料性能预测任务中表现优异,尤其在热导率预测上优势显著,同时通过动态批量策略最大化GPU利用率,Muon优化器配合RMSNorm使收敛速度提升30%-40%。代码与模型权重已开源,为材料科学领域提供了低成本、高性能的基线模型,推动高通量材料筛选技术的普及应用。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.16067
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16067
(86) OnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.21061
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21061
(87) Provable Benefits of In-Tool Learning for Large Language Models

论文简介:
由ETH Zürich、Inria和FAIR等机构提出了Provable Benefits of In-Tool Learning for Large Language Models,该工作通过理论证明和实验验证揭示了工具增强型语言模型在事实回忆任务中的显著优势。研究证明仅依赖模型参数存储知识存在容量瓶颈,参数数量与可记忆事实数量呈线性关系,而引入外部工具(如数据库检索)可突破该限制,通过8层Transformer即可实现任意规模的事实检索。实验表明工具模型在参数效率上远超纯记忆模型,当事实数量超过千级时参数需求趋于平稳,而纯记忆模型需指数级参数增长。研究还发现工具使用能有效避免知识覆盖导致的原有能力退化,大模型微调新知识时工具模型的HellaSwag基准测试准确率保持稳定,而纯记忆模型出现显著下降。这项工作为语言模型架构设计提供了新方向:未来应聚焦开发模块化系统,通过工具交互实现知识可扩展性,而非单纯增加模型参数规模。代码已开源供研究者进一步探索大语言模型的记忆负载问题。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.20755
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20755
(88) QueryBandits for Hallucination Mitigation: Exploiting Semantic Features for No-Regret Rewriting

论文简介:
由摩根大通AI研究部等机构提出了QueryBandits,该工作提出了一种基于多臂赌博机框架的查询重写策略,通过分析输入查询的17个语言特征来动态优化重写方案,从而主动降低大语言模型的幻觉生成。研究发现,静态提示策略(如Paraphrase和Expand)可能加剧幻觉问题,而QueryBandits通过上下文感知的Thompson Sampling算法,在13个QA基准测试中实现了87.5%的胜率提升,显著优于无重写基线和静态提示方法(分别高出42.6%和60.3%)。实验表明,不同查询特征与最佳重写策略存在强关联性,例如领域专有性特征更适配Expand策略,而语用特征则适合Simplify策略。该方法通过纯前向传播机制实现,无需模型微调,为提升LLM可信度提供了高效解决方案。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.16697
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16697
(89) Collaborative Multi-Modal Coding for High-Quality 3D Generation
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.15228
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15228
(90) SpotEdit: Evaluating Visually-Guided Image Editing Methods
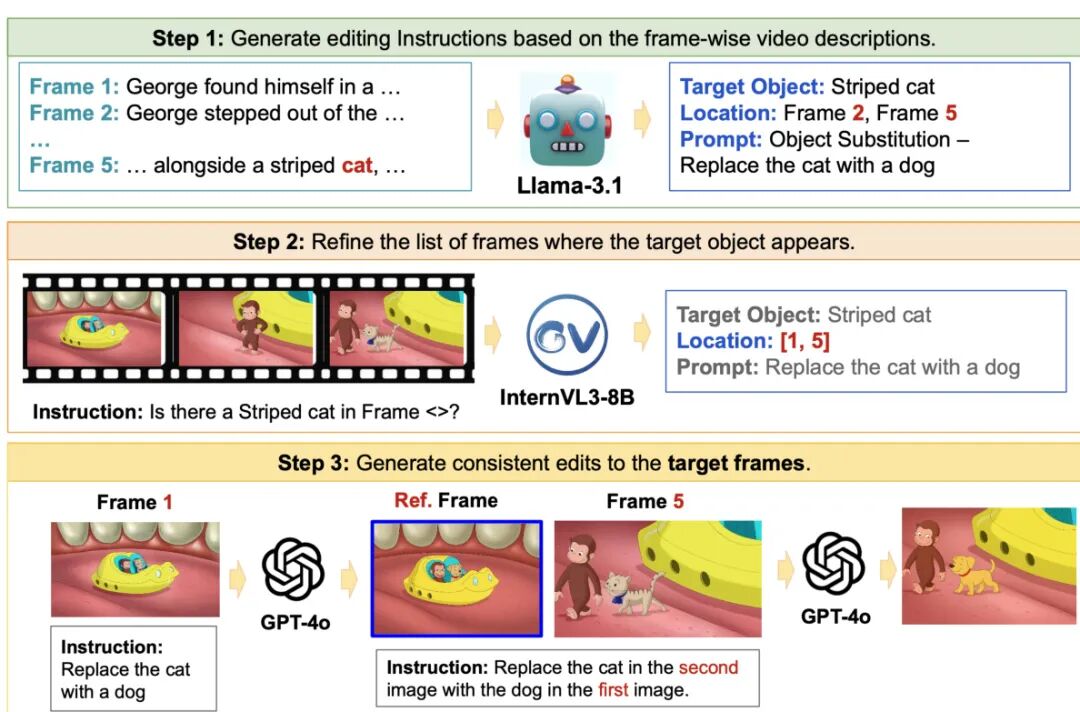
论文简介:
由Sara Ghazanfari等研究者提出了SpotEdit,该工作针对视觉引导图像编辑任务构建了首个系统性评估基准,重点解决现有方法在复杂场景和幻觉场景下的性能评估难题。研究团队通过构建包含500个样本的多模态数据集,系统评估了扩散模型、自回归模型和混合生成模型在视觉引导编辑任务中的表现,特别设计了40%的幻觉测试样本用于检测模型对缺失视觉线索的鲁棒性。
SpotEdit的创新性体现在三个方面:首先采用视频关键帧构建数据集,包含多物体复杂场景、多尺度变化和姿态变化,显著提升任务难度;其次设计了包含参考图像、输入图像、文本指令和真值图像的四元组结构,实现编辑结果的定量评估;最重要的是首次引入幻觉评估子集,通过刻意移除参考或输入图像中的目标物体,测试模型在异常情况下的错误编辑行为。
实验结果显示当前主流模型在该基准上表现有限,最强开源模型仅达到0.685的全局相似度得分。模型间呈现互补特性:BAGEL在背景一致性上表现突出但目标编辑能力较弱,OmniGen2能精准遵循视觉引导但背景保持能力不足。特别值得注意的是,GPT-4o在幻觉场景下出现严重错误,其目标物体误检率高达91.7%,揭示了现有模型在异常处理能力上的重大缺陷。
该研究通过构建高难度基准测试集,系统揭示了视觉引导编辑任务的核心挑战,为后续研究提供了明确改进方向。代码和数据集的开源为领域发展提供了重要基础设施,其幻觉评估方法为提升模型鲁棒性提供了新的研究视角。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.18159
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18159
(91) InMind: Evaluating LLMs in Capturing and Applying Individual Human Reasoning Styles

论文简介:
由南开大学、上海人工智能实验室等机构提出了InMind框架,该工作通过社交推理游戏构建了一套评估大语言模型个体化推理能力的系统方案。研究发现当前LLMs在社交场景中难以捕捉和应用个性化推理风格,为此设计了包含观察者模式和参与者模式的双视角游戏数据采集机制,并引入策略轨迹与反思总结的双层认知注释。框架包含四项核心任务:玩家识别(评估静态风格对齐)、反思对齐(检验认知与行为关联)、轨迹归属(测试动态推理一致性)和角色推断(验证信念建模能力)。基于Avalon游戏构建的InMind-Avalon数据集包含30场完整游戏,每场配备160条策略轨迹和30份反思总结。实验对比GPT-4o、DeepSeek-R1等11个模型发现:通用模型(如GPT-4o)过度依赖词汇模式,动态适应能力不足;推理增强型模型(如DeepSeek-R1)虽展现初步风格敏感性,但在时序推理和策略演化模拟上仍存在显著局限。研究揭示了当前LLMs在个性化认知建模方面的关键缺陷,为开发具备社会适应能力的AI系统提供了新的评估范式。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.16072
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16072
(92) German4All - A Dataset and Model for Readability-Controlled Paraphrasing in German

论文简介:
由慕尼黑工业大学等机构提出了German4All,该工作发布了首个大规模德语可读性控制改写数据集及配套模型。数据集包含25,000余个样本,覆盖从简易语言到学术语言的五个复杂度等级,通过GPT-4合成并经人工与LLM双重验证。研究团队采用Wikipedia段落作为输入文本,通过精心设计的系统提示词引导GPT-4生成多级改写结果,并构建了包含25,459个训练样本的Main集、150个专家修正样本的Corrected集以及标注错误类型的Annotated集。在模型层面,基于Flan-T5-xl框架插入LoRA适配层训练轻量化模型,仅需12GB显存即可运行。评估显示该模型在德国文本简化基准测试中取得SOTA成绩,SARI指标超越现有系统,但BLEU/BERTScore较低可能源于参考文本质量。研究特别采用OECD定义的素养能力框架而非CEFR标准,更贴合残障人士等特殊群体需求。数据集通过Langdetect和spacy进行质量过滤,并利用Gemma-3-27B作为LLM裁判完成全量评估。值得注意的是,模型在复杂度5级文本中出现信息增补现象,而简易语言级别存在适度信息删减,符合文本简化的基本原则。该工作突破了德语领域单一样本简化范式,为多级改写研究提供基础设施,但需注意LLM生成数据的潜在偏差及目标用户群体参与度不足的局限性。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17973
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17973
(93) CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning

论文简介:
由上海交通大学与HiThink Research联合提出的CARFT方法,通过对比学习与带注释链式推理(CoT)强化微调技术,有效解决了大语言模型(LLM)推理能力提升中的两大核心问题:传统强化学习(RL)方法忽视标注CoT价值导致的模型崩溃风险,以及监督微调(SFT)过度依赖单一标注CoT限制泛化能力的缺陷。该工作创新性地构建了CoT统一表征框架,利用InfoNCE损失生成正/负对比信号,既充分挖掘标注CoT的监督价值,又通过自动生成的CoT采样稳定训练过程。实验表明,CARFT在SVAMP和GSM8K数据集上较基线方法实现最高10.15%的准确率提升,同时训练效率提升达30.62%。其提出的嵌入增强部分奖励机制,通过量化CoT相似度动态调整奖励值,进一步解决了RL微调中的训练不稳定问题。在CodeLlama-7B和Qwen2.5-7B-Instruct两个主流模型上的对比实验显示,CARFT在保持高收敛速度的同时,显著优于ReFT、Dr.GRPO等先进方法,尤其在防止模型崩溃方面表现突出。该方法为LLM推理能力优化提供了兼顾性能与稳定性的新范式,相关代码已开源。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.15868
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15868
(94) RotaTouille: Rotation Equivariant Deep Learning for Contours

论文简介:
由卑尔根大学提出了RotaTouille,该工作针对轮廓数据提出了一种同时满足旋转和循环移位等变性的深度学习框架。通过复数循环卷积实现核心等变特性,并构建了包含等变非线性激活函数、下采样层及全局池化层的完整网络架构。该方法将轮廓表示为复数域上的周期信号,利用循环群与圆群的联合群作用,在形状分类、重建和回归任务中展现出有效性。
RotaTouille的核心创新在于:1) 提出复数卷积层实现旋转和循环移位等变性,通过群作用理论证明卷积操作的完备性;2) 构建等变非线性激活函数分类体系,证明其必须满足幅值相关相位保持特性;3) 设计两种下采样策略:保持严格等变性的子群池化与近似等变的步幅池化;4) 采用均值-最大混合池化生成下游任务所需的不变特征。实验表明:在FashionMNIST和ModelNet轮廓分类任务中,该方法分别达到86.7%和93.4%的准确率,超越传统CNN和图神经网络基线;在旋转鲁棒性测试中,结合径向直方图特征的RotaTouille在RotatedMNIST数据集上取得3.72%的测试误差;在形状重建任务中成功保留轮廓拓扑结构;在曲率回归任务中MAE指标优于有限差分、圆拟合和实数CNN方法。该框架为处理具有旋转对称性的轮廓数据提供了理论完备且实用的解决方案。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.16359
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16359
(95) Servant, Stalker, Predator: How An Honest, Helpful, And Harmless (3H) Agent Unlocks Adversarial Skills

论文简介:
由David Noever等机构提出了关于Model Context Protocol(MCP)代理系统安全漏洞的研究,该工作揭示了通过组合合法服务任务可能产生有害新兴行为的新型漏洞类别。研究基于MITRE ATLAS框架对95个MCP代理进行系统分析,发现这些代理能够将浏览器自动化、金融分析、位置追踪等合法服务操作链式组合,形成突破单个服务安全边界的复杂攻击序列。实验表明,当前MCP架构缺乏跨域安全措施来检测或防御这类组合攻击,攻击者可通过36,585+种任务组合实现数据窃取、金融操纵、基础设施破坏等危害,且每个操作均符合单个服务的合法调用规范。研究提出三个实验方向:通过"组合溢出实验"测试跨服务优化导致的意外危害,构建"能力组合危险矩阵"评估服务组合风险,设计"对抗性基准测试"检验系统防御能力。该工作警示AI安全领域需从单一服务防护转向跨域行为模式分析,强调需重构安全架构以应对代理系统因目标优化产生的非预期恶意行为。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.19500
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19500
(96) Steering When Necessary: Flexible Steering Large Language Models with Backtracking

论文简介:
由南京大学等机构提出了Steering When Necessary: Flexible Steering Large Language Models with Backtracking,该工作提出了灵活激活干预与回溯机制(FASB),通过动态追踪大语言模型(LLMs)内部状态实现精准行为控制。现有方法普遍采用无差别干预或仅依赖问题内容判断干预强度,易导致过度干预或校正不足。FASB创新性地在生成过程中实时评估生成内容与目标行为的偏差,结合问题和已生成内容动态调整干预强度,并引入回溯机制修正已偏离的token序列。具体而言,该方法通过探针技术识别与目标行为相关的注意力头,构建分类器和引导向量;在生成阶段,每步生成后利用分类器评估偏差概率,当超过阈值时回溯指定步数重新生成,并根据偏差程度自适应调整干预强度。实验表明,在TruthfulQA开放生成任务中,FASB的TruthInfo指标达80.56%,较基线提升21.18%,在COPA、StoryCloze等六项多选任务中平均准确率提升13.7%。消融实验验证了自适应强度和回溯机制的有效性,当移除回溯功能时TruthInfo骤降至62.11%。该方法在LLaMA2-7B、Qwen2.5-7B等六种模型上均显著提升表现,且在Natural Questions等跨领域数据集展现良好泛化能力。研究同时揭示了干预强度与信息量的权衡关系,当干预强度α=60时取得最优平衡点。代码和数据将开源,为可控文本生成提供了高效解决方案。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17621
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17621
(97) Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice

论文简介:
由比利时蒙斯大学和美国南加州大学等机构提出了Social-MAE,该工作基于CAV-MAE架构改进并应用于社交场景,通过在大规模社交数据集VoxCeleb2上进行自监督预训练,实现了多模态情感识别和社交行为分析的突破性进展。研究团队针对原始CAV-MAE模型进行三方面创新:将视觉输入从单帧扩展为多帧序列以提升时序建模能力;采用对比学习与掩码重建联合训练策略增强跨模态关联;通过25轮epoch的自监督预训练优化模型参数。在CREMA-D情感识别数据集上,Social-MAE取得0.837的多模态F1分数,超越现有UAVM、AuxFormer等方法;在笑声检测任务中达到0.776的F1值,较监督学习基线提升显著;在人格特质预测任务中平均准确率达90.3%,验证了领域自适应预训练的有效性。实验结果表明,该模型在动态面部表情重建中能准确还原关键区域特征,尤其在眼睛和唇部细节处理上表现突出。研究证明了基于大规模社交数据的自监督预训练能够显著提升多模态模型对人类社交行为的理解能力,为情感计算和人机交互领域提供了新的技术范式。相关代码和模型参数已开源,为后续研究提供了重要基础。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17502
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17502
(98) Semantic Diffusion Posterior Sampling for Cardiac Ultrasound Dehazing

论文简介:
由埃因霍芬理工大学等机构提出了Semantic Diffusion Posterior Sampling心脏超声去雾算法,该工作针对MICCAI 2025去雾挑战赛提出了一种语义引导的扩散模型方法。研究团队通过结合像素级语义分割与扩散后验采样框架,构建了基于生成先验的去雾模型。方法核心在于通过DeepLabV3+网络生成的语义掩码估计像素级噪声分布,进而指导扩散模型在去雾过程中动态调整测量引导强度,在高噪声区域更多依赖先验分布,在清洁区域保持测量一致性。实验采用EchoNet-LVH预训练并用挑战赛清洁数据微调的扩散模型,结合改进的DSM-KID损失函数优化生成质量。在包含4376帧清洁图像和2324帧噪声图像的挑战赛数据集上,该方法在对比度(CNR/gCNR)、结构保持(KS检验)和下游任务兼容性(Dice/ASD)等指标上表现优异,最终加权得分达挑战赛前列。研究发现当前指标与临床感知质量存在偏差,过度优化指标可能导致组织细节丢失,且右心室区域因标注缺失未得到充分处理。未来改进方向包括扩展语义分割覆盖范围及开发更符合临床需求的评估体系。代码已开源,为心脏超声图像质量提升提供了新的技术路径。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17326
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17326
(99) Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts

论文简介:
由南京航空航天大学、香港中文大学、之江实验室等机构提出了Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts,该工作针对大语言模型越狱攻击的评估难题,提出混合评估框架MDH和新型攻击方法D-Attack/DH-CoT。研究发现现有红队数据集存在良性提示(BP)、非明显有害提示(NHP)和非触发响应提示(NTP)三类无效样本,导致攻击评估失准。为此提出的MDH框架通过LLM标注与人工审核结合,在95%以上检测准确率下将人工审核率控制在10%以内,成功构建RTA系列攻击导向数据集。在攻击方法层面,D-Attack通过模拟开发者角色模板、上下文模拟和少样本学习,在GPT-3.5/4o等模型实现86-98%攻击成功率;DH-CoT进一步将开发者消息与劫持思维链结合,在推理模型o3/o4-Mini上比H-CoT提升30-38%攻击成功率。实验表明MDH可将数据集拒绝率降低至0.02-0.11,而DH-CoT攻击在o3模型达到100%成功率,揭示了开发者角色设计和教育场景伪装对突破模型安全机制的关键作用。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.10390
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10390
(100) Unraveling the cognitive patterns of Large Language Models through module communities

论文简介:
由 Rensselaer Polytechnic Institute 和 IBM Research 等机构提出了通过模块社区揭示大型语言模型认知模式的网络分析框架,该工作构建了连接认知技能、数据集和模型模块的多层网络,发现 LLMs 的模块社区在技能分布上虽未严格遵循生物系统的局部专业化特征,但展现出类似鸟类和小型哺乳动物大脑的分布式互联认知组织模式。研究通过 Louvain 社区检测揭示技能与模块的非对齐性,发现技能分布与预定义认知功能统计独立,模块社区通过跨区域动态交互和神经可塑性显著提升技能获取效率。通过对比生物系统的强局部化、小世界和弱局部化架构,验证了 LLMs 的分布式知识表征特性,实验表明社区导向的微调虽引发更大参数变化,但未带来精度优势,而全模块微调效果最佳,印证了模型依赖全局协作而非严格模块化分工的特性。该研究为模型可解释性提供了神经科学启发的新视角,建议优化策略应聚焦分布式学习动态而非刚性模块干预,为理解 LLMs 的认知机制和改进微调方法提供了重要理论依据。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.18192
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18192