
原文链接:https://developer.nvidia.com/blog/cutlass-principled-abstractions-for-handling-multidimensional-data-through-tensors-and-spatial-microkernels
在生成式AI时代,充分利用GPU的潜力对于训练更好的模型并大规模服务用户至关重要。通常,这些模型的层由于细微修改而无法表示为现成的库操作,而深度学习编译器通常会放弃最后几个百分点的优化,以使部署变得可行。
为了为NVIDIA CUDA开发者提供最大化深度学习(DL)和高性能计算(HPC)内核性能所需的控制力和能力,我们从2017年开始构建并迭代CUTLASS。
现在,它正进入下一个开发阶段,引入了新的Python接口。CUTLASS 3.x重设计引入的基本抽象在CUTLASS 4.0中直接暴露在Python中。在这篇文章中,我们讨论了CUTLASS 3.x的设计原则、其核心后端库CUDA Tensors and Spatial Microkernels (CuTe),以及利用CuTe关键功能的优化示例。
CUTLASS 3.x的亮点
CUTLASS 3引入了CuTe,这是一个新库,以布局概念作为统一且可组合的抽象,用于描述和操作线程和数据。通过将布局提升为编程模型的一等公民,使用CuTe大大简化了线程-数据组织。CuTe以可理解且静态可检查的方式向开发者揭示索引逻辑,同时保留了与CUTLASS 2.x相同的高性能水平和Tensor Core操作覆盖范围。
除了这种更有意义的布局方法之外,CUTLASS 3与所有先前版本的CUTLASS共享相同的目标——通过围绕最新硬件特性开发直观的编程模型,帮助CUDA开发者编写高性能GPU线性代数内核。在这个新的主要迭代中,我们强调了以下内容:
能够自定义库设计中的任何层,同时保留与其他层的可组合性,以提高开发者生产力和更清晰的移动部件分离 编译时检查以确保内核构造的正确性。这保证如果编译通过,它将正确运行,否则提供可操作的静态断言消息。 减少API表面面积,使用更少的命名类型,并通过单一入口点(也是自定义钩子)来平摊学习曲线。 在NVIDIA Hopper H100和NVIDIA Blackwell B200上表现出色,利用如WGMMA(针对Hopper)或UMMA(针对Blackwell)、Hopper的Tensor Memory Accelerator (TMA)以及线程块集群等特性。
CuTe
CUTLASS 3.x的核心是CuTe,这是一个新库,用于描述和操作线程和数据的张量。CuTe由两部分组成:强大的布局表示和作用于这些布局的操作代数。
CuTe的布局表示天生是分层的,自然支持静态和动态信息,并用于表示多维张量。相同的布局表示用于描述数据张量和线程张量。在多个独立资源中使用相同的词汇类型展示了CuTe Layout概念的广泛适用性。
基于这种表示能力,CuTe提供了布局的正式化代数,使用户能够从简单已知布局构建复杂布局,或将一个布局分区到另一个布局。这让程序员专注于算法的逻辑描述,而CuTe为他们处理机械性的簿记工作。借助这些工具,用户可以快速设计、实现和修改稠密线性代数算法。
与其他任何先前的GPU编程模型不同,线程和数据张量的函数组合消除了GPU编程中最复杂的障碍之一,即一致地将大量线程映射到它们操作的数据上。一旦线程布局独立于它们将操作的数据布局被描述,CuTe的布局代数就可以将数据分区到线程上,而不是手动实现复杂的后分区迭代方案。
CuTe布局和张量
有关布局和张量的更多CuTe文档可以在其专用文档目录中找到。
CuTe提供了Layout和Tensor对象,这些对象紧凑地打包了数据的类型、形状、内存空间和布局,同时为用户执行复杂的索引。
Layout<Shape,Stride>提供了Shape内逻辑坐标与使用Stride计算的索引之间的映射。(参见Figure 1作为示例)Shape定义一个或多个坐标空间并在它们之间映射。Stride定义将坐标转换为索引的索引映射。Tensor<Engine,Layout>提供了Layout与迭代器的组合。迭代器可以是全局内存、共享内存、寄存器内存或其他提供随机访问偏移和解引用的指针。
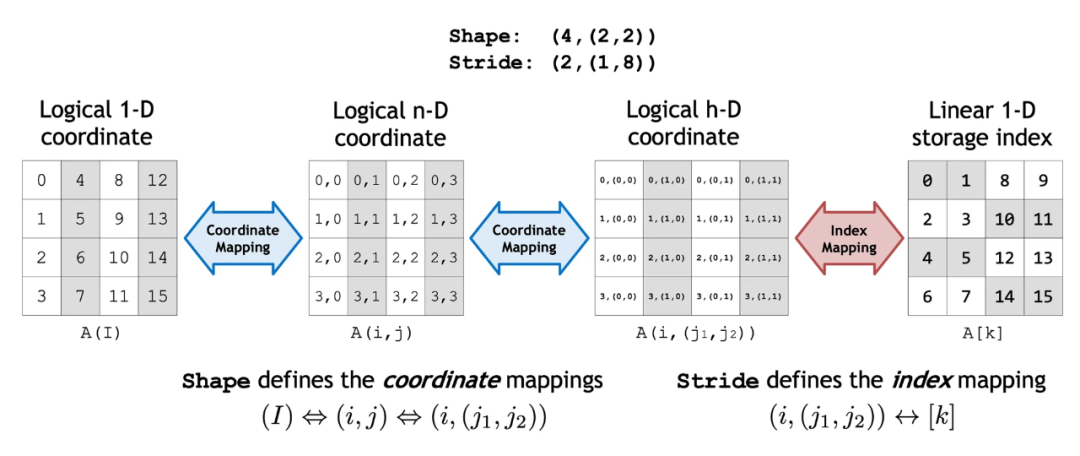
Figure 1. 多个矩阵类型可以通过Shape和Stride函数操作来创建索引
值得强调的是,CuTe中的布局是分层的,并受张量代数中折叠张量操作的启发。如图所示,分层Shape和Stride使布局表示远远超出简单的行优先和列优先。同时,分层布局仍然可以像正常张量一样访问(例如,所示的逻辑2-D坐标),因此这些更高级的数据布局在算法开发中被抽象化。
CUTLASS 3.x中的CuTe
CUTLASS 3.x使用单一词汇类型(cute::Layout),从而实现了简化、正式化和统一的布局表示,帮助用户轻松编写极快的内核。

Figure 2. 显示了CUTLASS函数如何简化为单一词汇类型调用
CuTe布局的变换和分区
CuTe Layout支持函数组合作为核心操作。函数组合可用于变换另一个布局的形状和顺序。如果我们有一个具有坐标(m,n)的数据布局,并且我们想使用坐标(thread_idx,value_idx)代替,那么我们将数据布局与描述映射(thread_idx,value_idx)->(m,n)的布局组合。
结果是一个具有坐标(thread_idx,value_idx)的数据布局,我们可以轻松访问每个线程的每个值!
作为一个示例,考虑一个4×8的数据布局。此外,假设我们想为该4×8数据的每个坐标分配线程和值。我们编写一个“TV布局”来记录特定的分区模式,然后在数据布局和TV布局之间执行函数组合。

Figure 3. 一个4×8数据布局如何被分配线程和值对,以帮助协调对4×8数据的访问。这被称为“TV布局”
如图所示,组合对数据进行排列和重塑,使得每个线程的值排列在结果的每一行。只需使用我们的线程索引对结果进行切片,即可完成分区。
分区模式的一个更直观的视图是TV布局的逆。
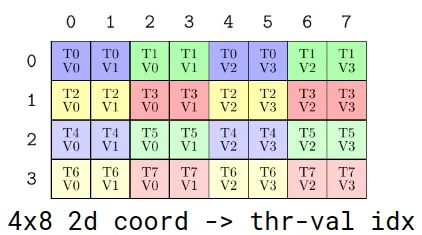
Figure 4. 另一个4×8矩阵,表示原始数据如何被映射,这是TV布局的逆
这个布局显示了从4×8数据布局中每个坐标到线程和值的映射。任意分区模式可以被记录并应用于任意数据布局。
有关CuTe Layout Algebra的附加文档可以在GitHub上找到。
CuTe矩阵乘法-累加原子
原子是最小的线程和数据集合,必须合作参与硬件加速的数学或复制操作的执行。
原子将PTX指令与关于必须参与该指令的线程和值的形状和排列的元数据结合。该元数据表示为CuTe TV布局,然后可用于分区任意输入和输出数据张量。一般来说,用户不需要扩展这一层,因为我们将为新架构提供CuTe原子的实现。

Figure 5. SM70_8x8x4_F32F16F16F32_NT指令及其关联的MMA_Traits元数据
上图显示了SM70_8x8x4_F32F16F16F32_NT指令及其关联的MMA_Traits元数据。在左侧,TV布局映射(thread_id,value_id) -> coord被记录在traits中,在右侧,traits使用inverse coord -> (thread_id,value_id)映射可视化。右侧图像可以使用
print_latex(make_tiled_mma(cute::SM70_8x8x4_F32F16F16F32_NT{}))
生成。
有关矩阵乘法-累加 (MMA) 原子的附加CuTe文档在GitHub上。
CuTe tiled MMAs
Tiled MMA和tiled copy分别是MMA原子和copy原子的平铺。我们称这一层为“tiled”,因为它在原子之上构建更大的操作,就像将单个瓷砖拼合起来构建马赛克的可重用组件一样。平铺在线程和数据上复制原子,可能包括原子的排列和交织。
这一层最类似于CUTLASS 2.x中MMA指令的warp级平铺;然而,它从参与操作的所有线程的角度查看平铺,并将概念泛化到复制操作。这一层的目的是从众多硬件加速的数学和数据移动操作中构建可组合的GPU微内核,每个操作可能有自己的线程和数据内在布局。tiled MMA和tiled Copy类型为所有这些各种硬件加速的CuTe原子提供单一、一致的API,用于分区数据。
例如,CuTe可能提供一个MMA原子,用户可以在单个warp上调用它,对于固定的M、N和K维度。然后,我们可以使用CuTe操作make_tiled_mma将此原子转换为适用于整个线程块的操作,对于更大的M、N和K维度。我们已经在上一节中看到了一个Tiled MMA的示例,即SM70_8x8x4_F32F16F16F32_NT的1x1x1平铺。
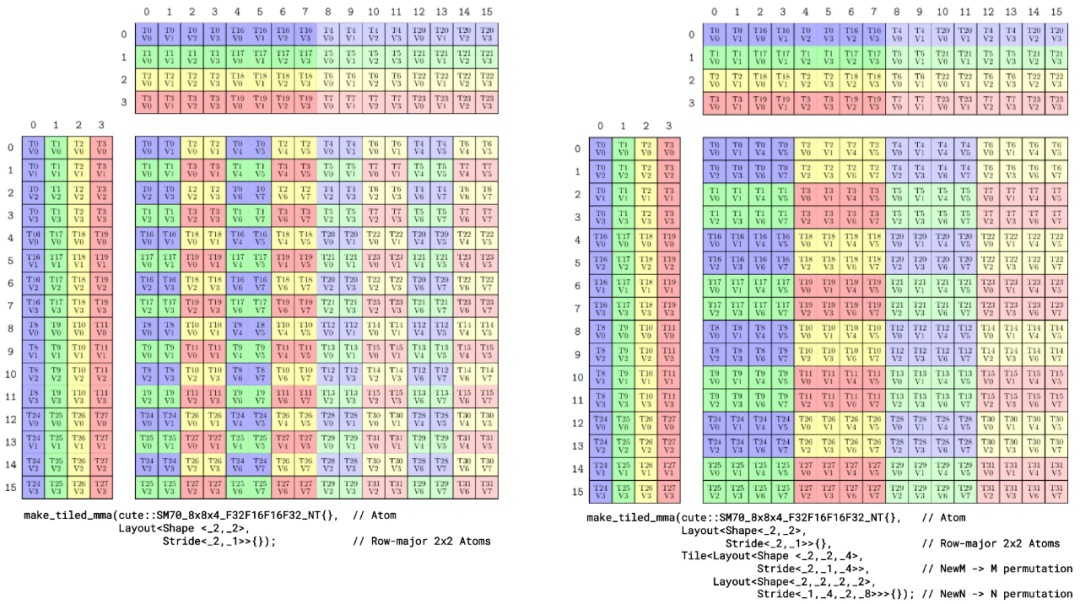
Figure 6. 上图显示了使用相同SM70_8x8x4_F32F16F16F32_NT原子的两个更多tiled MMAs
此图像显示了使用相同SM70_8x8x4_F32F16F16F32_NT原子的两个更多tiled MMAs。在左侧,四个这些原子以2×2行优先布局组合,产生一个one-warp 16x16x4 MMA。在右侧,四个这些原子以2×2行优先布局产生一个one-warp 16x16x4 MMA,然后行(M)和列(N)被排列以交织原子。这两者都产生可以应用于任何数据布局的分区模式,如下一节所示。
CuTe GEMMs和主循环
借助架构无关的tiled API,用户可以构建一致的GEMM外循环接口,内循环来自原子层。
Tensor gA = . . . // Tile of 64x16 gmem for A
Tensor gB = . . . // Tile of 96x16 gmem for B
Tensor gC = . . . // Tile of 64x96 gmem for C
// 64x16 static-layout padded row-major smem for A
Tensor sA = make_tensor(make_smem_ptr<TA>(smemAptr),
Layout<Shape < _64,_16>,
Stride<Int<17>, _1>>{});
// 96x16 static-layout interleaved col-major smem for B
Tensor sB = make_tensor(make_smem_ptr<TB>(smemBptr),
Layout<Shape <Shape <_32, _3>,_16>,
Stride<Stride< _1,_512>,_32>>{});
// Partition tensors across threads according to the TiledMMA
ThrMMA thr_mma = tiled_mma.get_slice(thread_idx);
Tensor tCsA = thr_mma.partition_A(sA); // (MMA, MMA_M, MMA_K) smem
Tensor tCsB = thr_mma.partition_B(sB); // (MMA, MMA_N, MMA_K) smem
Tensor tCgC = thr_mma.partition_C(gC); // (MMA, MMA_M, MMA_N) gmem
// Make register tensors the same shape/layout as above
Tensor tCrA = thr_mma.make_fragment_A(tCsA); // (MMA, MMA_M, MMA_K) rmem
Tensor tCrB = thr_mma.make_fragment_B(tCsB); // (MMA, MMA_N, MMA_K) rmem
Tensor tCrC = thr_mma.make_fragment_C(tCgC); // (MMA, MMA_M, MMA_N) rmem
// COPY from smem to rmem thread-level partitions
cute::copy(tCsA, tCrA);
cute::copy(tCsB, tCrB);
// CLEAR rmem thread-level partition (accumulators)
cute::clear(tCrC);
// GEMM on rmem: (V,M,K) x (V,N,K) => (V,M,N)
cute::gemm(tiled_mma, tCrA, tCrB, tCrC);
// Equivalent to
// for(int k = 0; k < size<2>(tCrA); ++k)
// for(int m = 0; m < size<1>(tCrC); ++m)
// for(int n = 0; n < size<2>(tCrC); ++n)
// tiled_mma.call(tCrA(_,m,k), tCrB(_,n,k), tCrC(_,m,n));
// AXPBY from rmem to gmem thread-level partitions
cute::axpby(alpha, tCrC, beta, tCgC);
// Equivalent to
// for(int i = 0; i < size(tCrC); ++i)
// tCgC(i) = alpha * tCrC(i) + beta * tCgC(i)
现在,对于上述代码,有许多关于计算和复制指令的时间交织的决策需要做出
将rmem分配为仅 A: (MMA,MMA_M)和B: (MMA,MMA_N)以及C: (MMA,MMA_M,MMA_N)张量,并在每个k-block迭代中复制到它。考虑gmem的多个k-tile,并在每个k-tile迭代中复制到smem。 使用异步方式将上述复制阶段与计算阶段重叠。 通过找到改善smem -> rmem复制访问模式的更好smem布局来优化。 通过找到gmem -> smem复制的有效TiledCopy分区模式来优化。
这些关注点被视为“时间微内核”的一部分,而不是CuTe提供的“空间微内核”。一般来说,有关CuTe张量上指令的流水线和执行的决策留给CUTLASS级别,并将在本系列的下一部分中讨论。
总结
总之,CuTe通过抽象张量布局和线程映射的低级细节,并为现代NVIDIA GPU上的稠密线性代数提供统一的代数接口,使开发者能够编写更易读、可维护和高性能的CUDA代码。
-- 完 --
机智流推荐阅读:
1. 聊聊大模型推理系统之 Arrow:自适应调度实现请求吞吐提升7.78倍背后的三大创新
2. 1.5 倍加速 MoE 训练:从零构建基于 Blackwell 的 MXFP8 Kernels
3. 3D/4D World Model(WM)近期发展的总结和思考
4. 港大联合月之暗面发布OpenCUA:32B模型力压GPT-4o登顶CUA榜,还提供端到端的CUA研究解决方案!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群