
转载自书生Intern
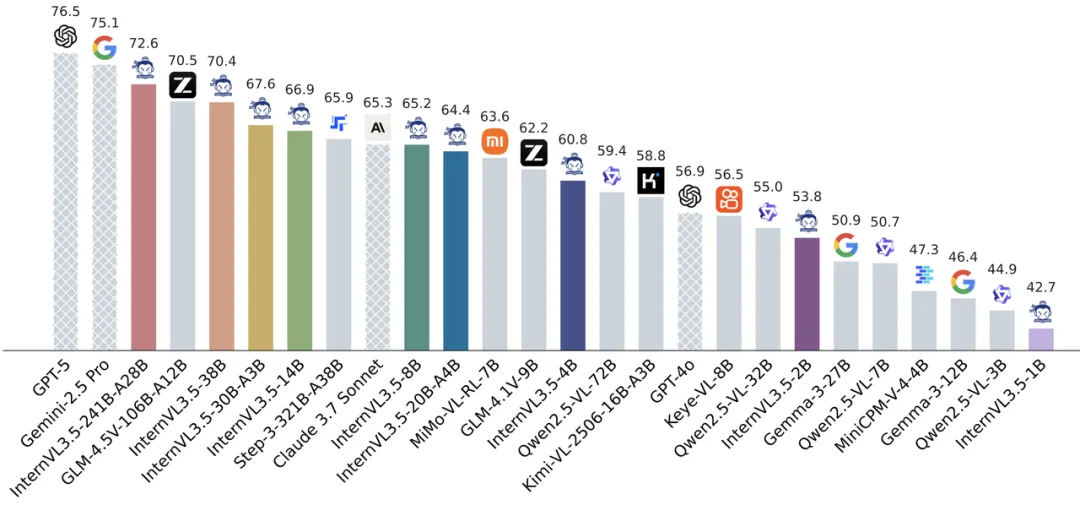
提供10亿至2410亿参数共九种尺寸模型,覆盖不同资源需求场景,包含稠密模型和专家混合模型(MoE),首个支持GPT-OSS语言模型基座的开源多模态大模型; 旗舰模型InternVL3.5-241B-A28B在多学科推理基准MMMU中获得开源模型最高分77.7分,多模态通用感知基准MMStar和OCRBench分别取得77.9分和90.7分,超越GPT-5(75.7分/80.7分),文本推理基准AIME25和MMLU-Pro分别达到75.6和81.3分,全面领先现有开源多模态大模型; 依托级联式强化学习框架(Cascade RL),全系列模型推理性能相比上一代平均提升16.0分。其中InternVL3.5-241B-A28B综合推理性能达到66.9分,超越上一代模型的54.6分以及Claude-3.7-Sonnet的53.9分,在数学推理、逻辑推理等复杂任务中表现突出; 借助创新的视觉分辨率路由(ViR)与解耦部署框架(DvD),38B模型在896分辨率下的响应速度大幅提升,单次推理延迟由369 ms缩短至91 ms(提升约4倍);与此同时,轻量化的InternVL3.5-Flash在将视觉序列长度减少 50% 的情况下,仍能保持接近 100% 的性能水平; 加强GUI智能体、具身智能体、SVG图形理解与生成等智能体核心能力,在ScreenSpot GUI定位(92.9分)、VSI-Bench空间推理(69.5分)、SGP-Bench矢量图理解(70.6分)等任务中超越主流开源模型。

探索级联式强化学习,解锁稳定、有效、可扩展的后训练框架
传统强化学习在多模态模型中常面临“效率低”或“性能上限低”的两难——离线强化学习训练快但推理能力弱,在线强化学习效果好但计算成本高。InternVL3.5创新提出级联式强化学习(Cascade RL)框架,通过“离线预热-在线精调”两阶段流程,实现粗到精的渐进式推理能力提升。离线强化学习阶段采用混合偏好优化(MPO)算法快速让模型达到基础推理水平,为后续训练提供高质量输出样本;后续的在线强化学习阶段则基于GSPO算法,以模型自身生成的样本为基础,动态调整输出分布,无需依赖外部参考模型,在MoE大模型中训练稳定性显著提升。对比单阶段强化学习,级联式强化学习仅通过50%的GPU训练时间即可达到更优的综合性能,同时在1B到241B全参数规模中均实现稳定性能增益,例如2B模型推理得分从38.5分提升至50.7分,241B-A28B模型从60.4分提升至66.9分。
创新多模态加速部署框架,实现实际部署场景吞吐效率4倍提升
多模态模型的视觉模块往往因高分辨率输入而成为效率瓶颈。InternVL3.5通过“动态压缩 + 硬件适配”的双重优化实现突破:一方面,引入动态视觉分辨率路由(ViR),基于视觉一致性学习(ViCO)为每个图像切片动态选择 1/4 或 1/16 的压缩率,在语义密集区域(如文字、图表)保留高分辨率,在背景区域自适应压缩,从而减少 50% 视觉 tokens,在 DocVQA、OCRBench 等高分辨率任务上几乎无损性能的同时显著提升推理速度;另一方面,提出 DvD 解耦部署方案,将视觉编码器(ViT+MLP)与语言模型(LLM)分置于不同 GPU,并结合 BF16 精度特征传输与异步流水线设计,使视觉计算与语言生成能够并行执行。在 896 高分辨率输入下,38B 模型的吞吐量提升达 4.05 倍,有效解决了传统串行部署的资源阻塞问题。
实现全场景能力提升与拓展,推动模型从“理解”到“行动”的跨越
InternVL3.5在通用多模态、多模态推理、文本能力等方面实现显著提升,并强化了面向实际应用的“智能体”与“文本思考”能力,覆盖GUI交互、具身空间推理和矢量图形处理等多个关键场景。具体而言,在图像、视频问答等多模态感知任务中,241B-A28B模型以74.1的平均得分超越现有开源模型,并与商业模型GPT-5(74.0)接近;在多模态推理方面,241B-A28B模型在MMMU基准获得77.7分,较前代提升超5个百分点,位列开源榜首,数学与逻辑推理也达到高水平;在表现文本能力的AIME、GPQA及IFEval等多个基准中,模型可以取得85.3的均分,处于开源领先。GUI交互部分,模型在ScreenSpot-v2元素定位任务以92.9分超越同类模型,同时支持Windows/Ubuntu自动化操作,并在WindowsAgentArena任务大幅领先Claude-3.7-Sonnet;在具身智能体测试当中,模型表现出理解物理空间关系并规划导航路径的能力,在VSI-Bench以69.5分超过Gemini-2.5-Pro;模型对于矢量图形的理解与生成也展现了优秀的能力,在SGP-Bench以70.7分刷新开源纪录,生成任务FID值也优于GPT-4o和Claude-3.7-Sonnet,能够有效应用于网页图形生成与工程图纸解析等专业场景。

2、根据文字指令编辑矢量图文件


通用推理能力
问题
解答这道题


(中间思考过程略)


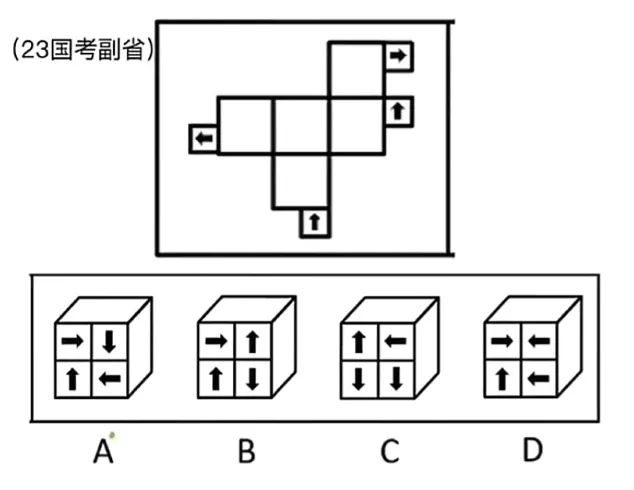
问题
上面大方框中的纸折叠成一个正方形盒子之后,形成的箭头的形状,应该是下面A B C D中的哪个

(中间思考过程略)


这是什么桌游?给出判断依据,分析场上局势,给出下一步的行动建议


(中间思考过程略)


书生·万象多模态大模型InternVL,作为实验室“通专融合”的书生大模型体系的重要组成部分,首创渐进式对齐技术,探索高效Scaling Law,较经典方法节约80%算力成本。自2024年1月 InternVL 1.0发布至今,书生·万象多模态大模型全网全系列下载量已经突破2300万次,凸显了在学术界与产业界的广泛影响力与认可度。从科研创新到产业落地,InternVL正通过“更强推理、更快速度、更泛应用”的技术突破,为多模态AI注入新动能——在数字办公中,GUI智能体可自动化处理 Excel 数据录入与公式计算、PPT 版式设计与内容排版等软件操作;在具身智能场景中,通过视觉感知与动作规划,辅助机器人完成家居环境、工业场景中的物理交互任务;在 AI for Science 场景中,凭借多模态协同推理能力,结合实验数据图表与领域知识,协助科研人员进行分子结构解析、材料性能预测等复杂推导。未来,随着模型能力的进一步迭代与开源生态的完善,书生·万象多模态大模型InternVL将持续推动多模态技术从“实验室”走向“生产线”,为人工智能通用化、低成本落地提供核心基座,为我国“人工智能+”行动提供坚实支撑。
-- 完 --
机智流推荐阅读:
1. 聊聊大模型推理系统之 Arrow:自适应调度实现请求吞吐提升7.78倍背后的三大创新
2. 1.5 倍加速 MoE 训练:从零构建基于 Blackwell 的 MXFP8 Kernels
3. 3D/4D World Model(WM)近期发展的总结和思考
4. 港大联合月之暗面发布OpenCUA:32B模型力压GPT-4o登顶CUA榜,还提供端到端的CUA研究解决方案!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










