本文论文选自 Hugging Face 八月论文,解读由 Intern-S1、Qwen3 等 AI 生成可能有误,今天先给大家简单的分享一下排行榜前 100 名的论文,接下来的几天再分多模态、Agent、强化学习等方向盘点 Hugging Face 8 月这 452 篇论文。
(1) Intern-S1: A Scientific Multimodal Foundation Model

论文简介:
由上海人工智能实验室提出的Intern-S1是一款面向科学领域的多模态基础模型,该工作通过创新的混合专家架构、科学数据增强策略及强化学习框架,在通用推理与科学专业任务中均展现出卓越性能。Intern-S1采用280亿激活参数、2410亿总参数的混合专家(MoE)架构,依托2.5万亿token科学领域数据进行持续预训练,并在InternBootCamp环境中通过混合奖励(MoR)框架实现千余任务的在线强化学习。其核心创新包括:1)动态分词器针对科学数据(如分子式、蛋白质序列)设计差异化分词策略,压缩率较传统方法提升70%;2)多模态编码器集成视觉、时序信号处理模块,支持高分辨率图像与长时序数据输入;3)混合奖励框架通过统一化反馈机制协同优化逻辑推理、学术问题解决与对话能力,样本效率较基线提升10倍。实验表明,Intern-S1在MMLU-Pro、MathVista等通用基准上超越主流开源模型,在ChemBench、MatBench等科学专项任务中性能优于闭源模型如OpenAI o3,尤其在分子合成规划、晶体热力学预测等专业场景实现突破。该模型的开源为科学智能研究提供了兼具广度与深度的基础工具,其训练范式为低资源领域模型优化提供了可扩展范例。
Hugging Face 投票数:242
论文链接:
https://hf.co/papers/2508.15763
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15763
(2) Qwen-Image Technical Report

论文简介:
由Qwen团队提出了Qwen-Image,该工作针对复杂文本渲染和精确图像编辑两大挑战,构建了综合性数据管道与渐进式学习策略。通过引入多阶段文本合成技术,模型在中英文文本渲染精度上取得显著突破,尤其在中文字符生成方面超越现有模型。创新性地设计了双编码机制,将Qwen2.5-VL的语义特征与VAE的重建特征融合,结合改进的多任务训练范式,有效提升了图像编辑的语义连贯性与视觉保真度。模型采用流匹配训练目标与混合并行策略,在256×256至1328×1328多分辨率数据上实现稳定训练。实验表明,Qwen-Image在GenEval、DPG等基准测试中均位列前三,在LongText-Bench中文长文本渲染任务中准确率达到58.3%,显著优于现有模型。其图像编辑能力在GEdit-Bench多语言指令跟随测试中取得8.00的语义一致性评分,刷新了文本到图像生成模型的编辑性能上限。该工作推动了视觉生成模型向精准图文对齐与多模态交互方向的发展,为构建具象化语言界面提供了技术范式。
Hugging Face 投票数:239
论文链接:
https://hf.co/papers/2508.02324
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02324
(3) Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens

论文简介:
由亚利桑那州立大学等机构提出了Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens,该工作通过数据分布视角揭示了大语言模型链式推理(CoT)的本质局限性。研究团队构建了可控实验框架DataAlchemy,从任务结构、推理长度和查询格式三个维度系统验证CoT推理能力,发现其有效性高度依赖训练数据分布,当测试数据与训练分布存在偏差时,看似连贯的推理过程会迅速失效,暴露出模式匹配而非真实逻辑推理的本质。实验表明:在任务维度,模型无法有效迁移至新变换或新元素组合;在长度维度,推理性能随文本或步骤长度偏离训练分布呈指数级下降;在格式维度,轻微的提示词扰动即可导致推理崩溃。研究证明CoT的"推理幻觉"源于对训练数据分布的结构化归纳偏置,其有效性边界由训练-测试分布差异严格限定。该工作为评估大模型推理能力提供了新范式,警示从业者需谨慎对待CoT输出的可靠性,强调开发具备真正泛化推理能力模型的必要性。相关代码已开源。
Hugging Face 投票数:228
论文链接:
https://hf.co/papers/2508.01191
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01191
(4) DINOv3

论文简介:
由 Meta AI Research 等机构提出了 DINOv3,该工作旨在通过自监督学习创建一个通用的视觉基础模型,消除对人工数据标注的需求。为了实现这一目标,研究人员首先通过精心的数据准备、设计和优化,扩大了数据集和模型的规模。其次,他们引入了一种名为“Gram anchoring”的新方法,有效解决了长时间训练中密集特征图退化的问题。最后,他们应用了后处理策略,进一步增强了模型在分辨率、模型大小和文本对齐方面的灵活性。最终的 DINOv3 模型是一个多功能的视觉基础模型,无需微调即可在广泛的设置中超越专业化的现有技术。它能生成高质量的密集特征,在各种视觉任务上取得了出色的性能,显著优于以往的自监督和弱监督基础模型。
Hugging Face 投票数:221
论文链接:
https://hf.co/papers/2508.10104
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10104
(5) GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
论文简介:
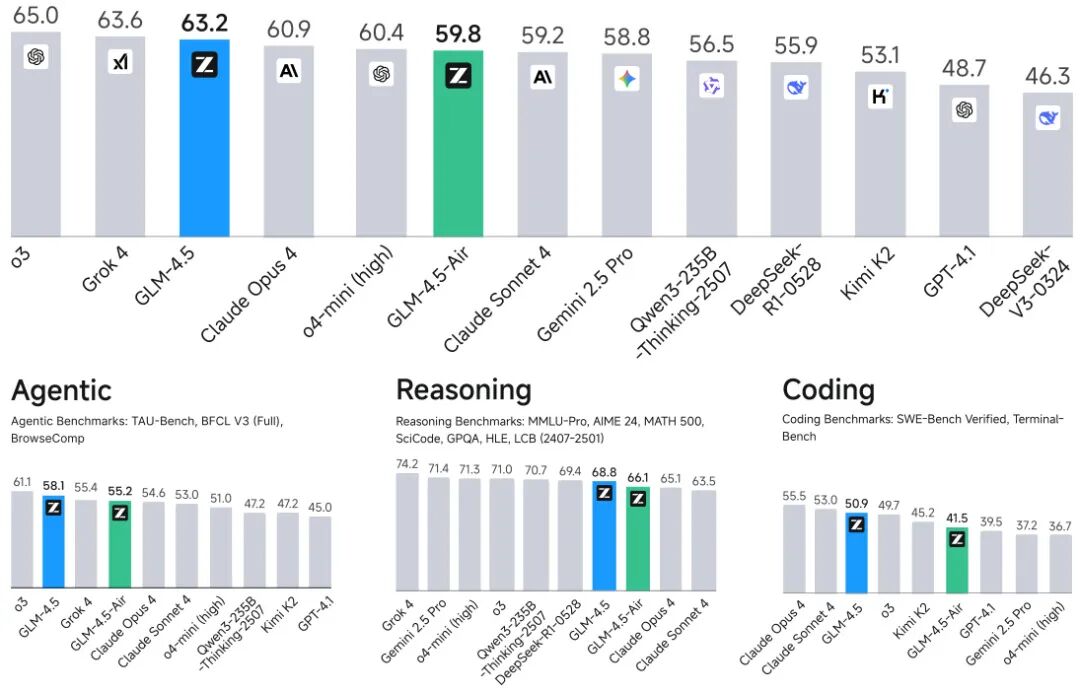
由智谱AI与清华大学提出了GLM-4.5系列模型,该工作推出了开源的Mixture-of-Experts(MoE)大语言模型GLM-4.5(355B总参数/32B激活参数)及其轻量版GLM-4.5-Air(106B参数),通过混合推理模式(支持思考与直接响应)和多阶段训练策略,在代理、推理、编码(ARC)任务上实现突破。模型采用深度MoE架构,创新性地通过损失平衡路由、动态采样温度、专家模型迭代等技术,在23T token预训练基础上,结合强化学习与专家模型蒸馏,最终在12项ARC基准测试中综合排名第三(代理任务第二),参数效率显著:GLM-4.5参数量仅为DeepSeek-R1的53%、Kimi K2的34%,却在AIME 24(91.0%)、TAU-Bench(70.1%)、SWE-Bench Verified(64.2%)等任务中超越GPT-4.1、Claude Opus 4等竞品。特别在编码任务中,GLM-4.5-Air以106B参数实现SWE-Bench Verified 57.6%的性能,超越Qwen3-235B的54.1%。研究还创新性地提出XML函数调用模板减少转义字符、动态难度课程学习、单阶段64K上下文强化学习等优化方法,其Slime1强化学习框架支持同步/异步混合训练模式,显著提升代理任务训练效率。模型已全面开源,配套发布评估工具包,为多模态智能体、复杂推理等研究提供重要基础。
Hugging Face 投票数:168
论文链接:
https://hf.co/papers/2508.06471
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06471
(6) On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
论文简介:
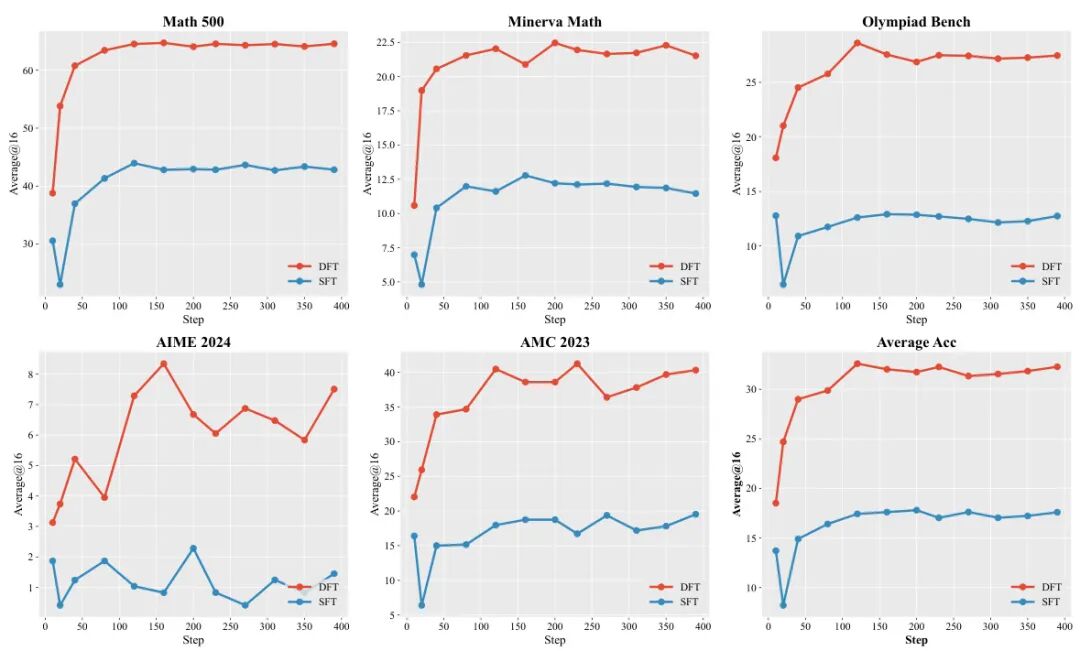
由东南大学、独立研究者、加州大学洛杉矶分校等机构的研究者提出了Dynamic Fine-Tuning(DFT),该工作通过动态调整token概率实现监督微调(SFT)的梯度稳定化,显著提升大语言模型的泛化能力。研究团队通过数学分析揭示了标准SFT梯度中存在隐含的病态奖励结构问题——模型对专家动作的低概率预测会导致梯度方差无界增长,形成病态优化景观。针对这一理论发现,DFT在token级别对SFT目标函数进行动态缩放,通过乘以token概率抵消逆概率加权带来的偏差,将梯度更新转化为稳定、均匀的更新机制。实验表明,在数学推理任务中,DFT在Qwen2.5-Math-1.5B等模型上相比标准SFT平均提升15.66个百分点,性能提升幅度达5.9倍;在Olympiad Bench等挑战性任务中,DFT将Qwen2.5-Math-7B的准确率从2.48%提升至8.56%,而标准SFT反而导致性能下降。值得注意的是,该方法在离线强化学习场景中同样表现出色,以单行代码修改超越DPO、RFT等复杂算法,在数学推理基准测试中平均得分达35.43,较最佳离线方法RFT提升11.46分,甚至优于在线强化学习算法PPO和GRPO。研究还发现DFT会形成独特的token概率分布,通过主动抑制语法性token(如冠词、标点)的概率,使模型更聚焦于语义核心内容。这项工作不仅建立了SFT与强化学习的理论等价性,更通过极简的动态重加权策略,为提升大语言模型泛化能力提供了兼具理论深度与工程实用性的解决方案。
Hugging Face 投票数:167
论文链接:
https://hf.co/papers/2508.05629
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05629
(7) InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency

论文简介:
由上海人工智能实验室等机构提出了InternVL3.5,该工作通过创新的级联强化学习框架、视觉分辨率路由技术和解耦式视觉-语言部署策略,在保持开源模型开放性的同时,显著提升了多模态大模型的推理能力、应用通用性及部署效率。InternVL3.5系列包含从1B到241B参数量的多种模型规模,其中最大模型InternVL3.5-241B-A28B在35项多模态任务评估中达到74.1的综合得分,与闭源模型GPT-5(74.0)相当,且在MMMU(多模态推理)和MathVista(数学视觉推理)等核心任务中分别取得77.7和82.7的优异表现,领先现有开源模型。
核心创新方面,级联强化学习(Cascade RL)通过离线预训练(MPO算法)与在线优化(GSPO算法)的双阶段策略,使模型推理能力提升16%,其中8B参数模型在MMMU的得分从62.7跃升至73.4。视觉分辨率路由(ViR)技术动态调整图像token数量,在保持99%性能的前提下将视觉计算量降低50%,结合Decoupled Vision-Language Deployment(DvD)策略实现视觉与语言模块的异步并行计算,推理速度提升4.05倍。模型在文本理解、图表解析、视频推理等任务中均表现突出,例如在MME-RealWorld(真实场景理解)任务中,241B模型以74.6的分数大幅领先GPT-4o(57.4)。此外,该模型还支持GUI交互、具身智能等新型应用场景,在ScreenSpot(屏幕交互)任务中达到92.9的准确率。这些突破性进展为开源多模态模型追赶闭源模型提供了重要技术路径。
Hugging Face 投票数:165
论文链接:
https://hf.co/papers/2508.18265
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18265
(8) VeriGUI: Verifiable Long-Chain GUI Dataset

论文简介:
由 VeriGUI 团队提出了 VeriGUI 数据集,该工作聚焦于构建可验证的长链 GUI 数据集以推动通用型计算机交互代理的发展。现有研究多关注短时交互与结果验证,而 VeriGUI 通过两个核心维度突破局限:一是长链复杂性,任务被分解为 4-8 个相互依赖的子任务,每个子任务均可作为独立起点,要求代理处理跨应用/网页的数百步操作;二是子任务级验证,允许代理在子任务内探索多样化策略的同时,通过子任务目标完成度提供细粒度监督信号。数据集包含桌面与网页双场景,由人类专家标注超过 2.7 万步操作轨迹,平均每个任务需 214 步完成。实验部分测试了多类代理框架(深研代理、搜索代理、浏览器代理等)与多种基础模型(GPT-4、Gemini、Claude 等),结果显示所有配置的任务成功率均低于 10%,完成率最高仅 28.8%,凸显长时任务规划与多步推理仍是当前瓶颈。研究进一步通过任务难度分级(5 级体系)和动作效率分析,揭示代理在信息检索、状态跟踪和错误恢复等环节的系统性缺陷。该数据集为开发具备真实世界适应能力的 GUI 代理提供了关键基准,其子任务验证机制为多模态模型的交互式学习开辟了新路径。
Hugging Face 投票数:156
论文链接:
https://hf.co/papers/2508.04026
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04026
(9) We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning

论文简介:
由北京邮电大学、腾讯微信AI、清华大学等机构提出了We-Math 2.0,该工作构建了包含数学知识系统、数据空间建模和强化学习训练范式的统一框架,旨在全面提升多模态大语言模型的数学推理能力。核心贡献包括:1)构建了五层知识体系MathBook,涵盖491个知识点和1819条基础原理,实现结构化数学知识监督;2)开发MathBook-Standard和MathBook-Pro两个数据集,前者通过双扩展策略实现概念灵活性,后者通过三维难度建模(步骤复杂度、视觉复杂度、语境复杂度)实现渐进式学习;3)提出两阶段强化学习框架MathBook-RL,包含冷启动微调和渐进对齐RL,通过平均奖励机制和动态调度策略提升模型泛化能力;4)构建覆盖491个知识点的综合评估基准MathBookEval,支持多维度推理能力分析。实验表明该方法在四个主流基准测试中表现优异,尤其在跨难度泛化和知识迁移能力上显著优于现有方法,其基于GeoGebra生成的高质量几何图像在空间严谨性上超越传统Python渲染方法,为数学推理模型的可解释性和教育应用提供了新范式。
Hugging Face 投票数:142
论文链接:
https://hf.co/papers/2508.10433
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10433
(10) NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale

论文简介:
由StepFun等机构提出了NextStep-1,该工作通过140亿参数的自回归模型与1.57亿参数的flow matching头,实现了基于连续图像token的文本到图像生成范式突破。模型采用离散文本token与连续图像token的统一序列建模,通过next-token预测目标训练,在GenEval、GenAI-Bench和DPG-Bench等基准测试中分别取得0.63、0.67和85.28的优异成绩,显著超越同类自回归模型并逼近扩散模型表现。其核心创新在于:1)设计通道归一化与随机扰动的图像tokenizer,解决高维连续token训练不稳定问题;2)采用patch-wise flow matching头替代传统扩散模型,实现纯自回归架构下的连续token生成;3)构建包含400B文本、550M图文对、4.5M指令引导图像和80M多模态序列的多样化训练集。在图像编辑任务中,NextStep-1-Edit在GEdit-Bench和ImgEdit-Bench分别达到6.58和3.71的SOTA指标,验证了模型的多功能性。研究还揭示自回归生成质量与tokenizer重建能力的强相关性,以及flow matching头尺寸对生成性能的非敏感性等关键发现,为后续研究提供了重要方向。
Hugging Face 投票数:139
论文链接:
https://hf.co/papers/2508.10711
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10711
(11) Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference

论文简介:
由ByteDance Seed、清华大学AIR及SIA-Lab联合提出的Seed Diffusion Preview,通过离散状态扩散模型实现了代码生成领域的速度与质量双重突破。该工作创新性地采用两阶段课程训练策略(前80%步骤使用掩码扩散,后20%引入编辑扩散增强校准),结合轨迹空间定制化优化和在线策略学习机制,在H20 GPU上达到2146 tokens/s的推理速度,相较Mercury Coder和Gemini Diffusion提升显著,同时在HumanEval、MBPP、BigCodeBench等八大代码基准测试中保持与同规模自回归模型相当的性能。其核心突破在于通过约束生成轨迹训练和块级并行采样,在保证生成质量的前提下突破传统扩散模型的迭代延迟瓶颈,尤其在代码编辑任务(Aider/CanItEdit)中表现突出。实验数据显示,该模型在保持8B参数量级竞争力的同时,推理速度较DeepSeek-Coder-33B-Instruct提升近5倍,为离散扩散模型的工程化应用树立了新的速度-质量帕累托最优标杆。
Hugging Face 投票数:128
论文链接:
https://hf.co/papers/2508.02193
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02193
(12) R-Zero: Self-Evolving Reasoning LLM from Zero Data
论文简介:
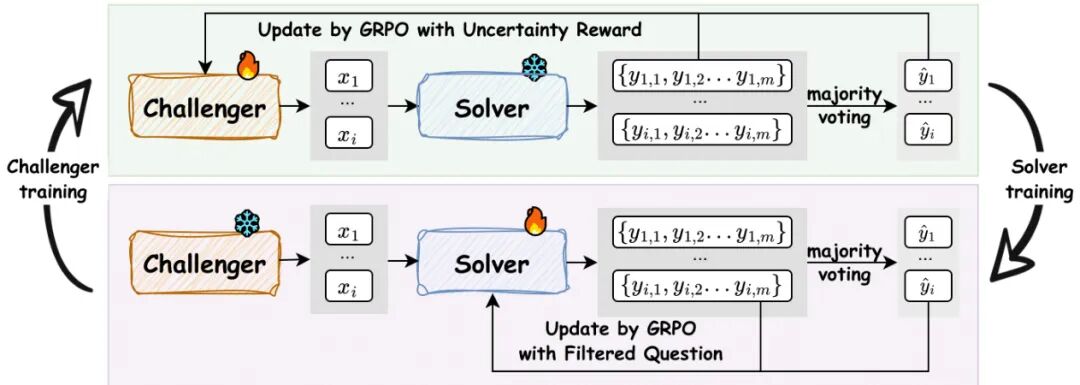
由腾讯AI Seattle实验室、华盛顿大学等机构提出了R-Zero,该工作开创性地构建了一种完全自主的推理大语言模型(LLM)进化框架。针对现有自进化模型仍依赖人工标注数据的瓶颈,R-Zero通过初始化两个独立模型角色——挑战者(Challenger)和解题者(Solver)——实现无外部数据的协同进化。框架采用Group Relative Policy Optimization(GRPO)算法,让挑战者通过生成接近解题者能力边界的数学问题获得奖励,而解题者则通过解决这些自生成问题进行强化学习。这种动态循环不仅构建了针对性的自我提升课程,更通过理论证明了50%正确率的不确定性奖励函数能最大化KL散度优化效率。实验显示,该方法在Qwen3-4B-Base等多架构模型上实现显著提升,数学推理基准平均提升+6.49分,通用推理任务MMLU-Pro等也获得+7.54分的跨领域增益。值得注意的是,R-Zero生成的训练数据准确率虽随迭代下降(从79%至63%),但其动态难度调节机制始终维持解题者50%左右的挑战成功率。分析表明该框架与监督微调存在协同效应,预训练模型经R-Zero优化后在标注数据上表现更优。这项研究标志着向完全自主进化的AI系统迈出了关键一步,为突破人类标注瓶颈提供了可行路径。
Hugging Face 投票数:123
论文链接:
https://hf.co/papers/2508.05004
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05004
(13) WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent

论文简介:
由阿里巴巴达摩院提出了WebWatcher,该工作构建了首个具备深度视觉-语言推理能力的网页智能体。针对现有研究代理多局限文本模态的问题,团队创新性地设计了多模态轨迹生成框架,通过结合高质量合成数据训练与强化学习优化,使模型在复杂视觉问答任务中展现出超越专有系统的推理能力。研究核心贡献包括:1)构建了包含17个子领域的BrowseComp-VL基准,采用实体模糊化设计提升推理难度;2)开发了自动化轨迹生成系统,通过LLM驱动的"思考-行动-观察"循环生成多工具协同的推理路径;3)提出基于GRPO的策略优化方法,通过组内相对优势计算实现稳定策略更新。实验显示,WebWatcher-32B在HLE考试中取得18.2%的平均正确率,较GPT-4o基线提升38%,在LiveVQA和MMSearch等视觉搜索基准上分别达到58.7%和55.3%的准确率。特别在需要跨模态推理的KenKen数独案例中,模型通过OCR识别、网页检索和代码执行的协同,成功破解需要多步骤数学推导的难题。该研究标志着智能体从文本研究向多模态深度推理的重要突破,为构建具备真实世界问题解决能力的AI系统提供了新范式。
Hugging Face 投票数:121
论文链接:
https://hf.co/papers/2508.05748
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05748
(14) Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL

论文简介:
由OPPO AI Agent Team等机构提出了Chain-of-Agents(CoA)框架,该工作通过多智能体蒸馏和代理强化学习构建端到端的代理基础模型(AFM)。CoA创新性地将多智能体协作能力整合到单一模型中,支持动态激活不同工具代理和角色代理进行多轮协作求解。研究团队提出多智能体蒸馏框架,将OAgents等先进多智能体系统的协作轨迹转化为CoA兼容的训练数据,并采用分阶段过滤策略确保轨迹质量。在此基础上,通过工具感知的强化学习优化模型策略,设计了基于答案正确性的奖励函数。实验表明,AFM在Web代理和代码代理任务中均取得显著突破:在GAIA基准测试中达到55.3%的SOTA成功率,在BrowseComp和HLE任务分别获得11.1%和18.0%的准确率;代码生成任务中,AFM-32B在LiveCodeBench和CodeContests基准上分别达到47.9%和32.7%的通过率。特别在数学推理领域,AFM在AIME25基准上实现59.8%的解题率,较ReTool等方法提升超10.5%。分析显示AFM将推理成本降低84.6%的同时保持竞争力,并展现出优异的零样本代理泛化能力。所有代码、数据和模型均已开源,为代理模型研究提供完整技术栈支持。
Hugging Face 投票数:119
论文链接:
https://hf.co/papers/2508.13167
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13167
(15) AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs
论文简介:
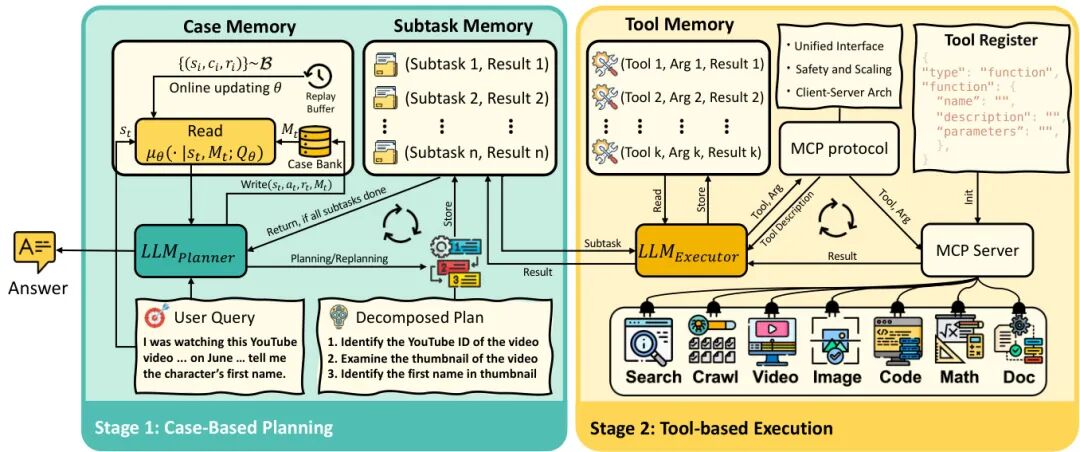
由UCL、华为诺亚方舟实验室等机构提出了AgentFly,该工作提出了一种基于记忆增强的在线强化学习框架,通过记忆库存储经验轨迹并利用神经案例选择策略实现LLM代理的持续适应能力,无需对底层LLM参数进行微调。该方法将决策过程建模为记忆增强的马尔可夫决策过程(M-MDP),通过非参数或参数化记忆模块存储过往经验,并基于软Q学习优化案例检索策略。在GAIA数据集上达到87.88%的验证集准确率(Top-1)和79.40%的测试集准确率,在DeepResearcher数据集取得66.6% F1和80.4% PM的SOTA结果,同时案例记忆在OOD任务中带来4.7%-9.6%的绝对提升。实验表明,该方法通过记忆库的持续更新实现高效在线学习,在复杂工具调用和多轮推理任务中展现出显著优势,为构建具备持续学习能力的通用型LLM代理提供了新范式。
Hugging Face 投票数:115
论文链接:
https://hf.co/papers/2508.16153
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16153
(16) Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR

论文简介:
由 UCLA、微软、中国科学院、香港科技大学等机构提出了 Self-Play with Variational Problem Synthesis (SVS),该工作针对强化学习与可验证奖励(RLVR)训练中策略熵崩溃导致生成多样性下降的问题,提出通过自博弈生成变分问题的在线数据增强策略,有效维持训练熵并显著提升模型在竞争级数学推理任务上的Pass@k性能。研究发现,传统RLVR训练因重复生成记忆化解法导致策略熵下降,限制了模型探索更优推理路径的能力。SVS方法通过让策略模型基于自身正确解法生成语义一致但结构多样的变分问题,利用策略自身进行数据增强,无需额外标注即可保持训练数据多样性。实验表明,SVS在AIME24和AIME25基准上使32B参数模型的Pass@32分别提升18.3%和22.8%,在12个推理基准测试中均超越标准RLVR,且策略熵在训练过程中保持稳定波动。该方法通过持续生成具有挑战性的变分问题,形成自我改进闭环,在数学推理、通用问答和代码生成等任务上展现出跨领域泛化能力,为大规模语言模型的可持续训练提供了新范式。
Hugging Face 投票数:115
论文链接:
https://hf.co/papers/2508.14029
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14029
(17) ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability

论文简介:
由中国人民大学高瓴人工智能学院、百度公司和卡内基梅隆大学等机构提出了ReasonRank,该工作通过自动化推理密集型训练数据合成框架和两阶段训练方法,显著提升了段落重排序的推理能力。针对现有重排序器在复杂推理场景中表现不足的问题,研究者首先构建了包含13K高质量训练数据的多领域数据集(涵盖复杂问答、编程、数学和网络搜索),利用DeepSeek-R1生成带有推理链的排序标签,并设计自一致性过滤机制保障数据质量。进一步提出冷启动监督微调(SFT)和强化学习(RL)两阶段训练框架:SFT阶段通过学习推理链模式掌握排序逻辑;RL阶段创新性设计多视角排序奖励(结合NDCG@10、Recall@10和RBO指标),优化滑动窗口策略下的多轮排序效果。实验表明,ReasonRank在BRIGHT和R2MED基准测试中分别超越现有SOTA模型5和4个百分点,其中32B参数模型在BRIGHT榜单取得40.6的平均NDCG@10成绩,同时相比点式重排序器Rank1实现2-2.7倍推理加速。该研究通过数据构建范式创新和训练方法优化,为构建高效推理型信息检索系统提供了新范式。
Hugging Face 投票数:114
论文链接:
https://hf.co/papers/2508.07050
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07050
(18) Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving

论文简介:
由ByteDance Seed AI4Math团队提出的Seed-Prover,通过结合形式化语言验证与深度学习技术,显著提升了自动化定理证明的能力。该工作创新性地采用引理驱动的全证明生成模式,通过迭代优化、测试时扩展策略及专用几何推理引擎Seed-Geometry,在国际数学奥林匹克(IMO)等高难度基准上取得突破性进展。Seed-Prover在形式化数学基准MiniF2F-valid/test上分别达到100%/99.6%的证明率,超越此前最佳模型DeepSeek-Prover-V2达7.4个百分点;在PutnamBench上解决331/657题,性能提升超3倍;对155道历史IMO问题实现78.1%的证明率,其中包含2025年赛事中5/6题的正式证明。其核心创新包括:1)引理驱动证明框架,通过模块化引理生成与复用实现复杂证明分解;2)三阶段测试时推理策略(light/medium/heavy),在计算预算内平衡深度验证与广度探索;3)Seed-Geometry几何引擎,通过C++加速的前向推理与分布式搜索,在IMO-AG-50基准上以43/50题超越AlphaGeometry 2,并于2秒内解决2025年IMO几何题。该系统通过形式化语言的精确验证信号,突破了传统自然语言证明监督的局限,为自动化数学推理提供了兼具准确性与扩展性的新范式。
Hugging Face 投票数:112
论文链接:
https://hf.co/papers/2507.23726
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23726
(19) WideSearch: Benchmarking Agentic Broad Info-Seeking

论文简介:
由 ByteDance Seed 等机构提出了 WideSearch,该工作构建了一个新型基准测试框架,用于系统评估大语言模型代理在大规模信息收集任务中的可靠性。研究团队通过200个跨语言(中英各100题)、覆盖15+领域的复杂问题,要求代理完成需要高精度、高完整性的表格化信息整理任务。每个任务需从公开网页中提取数千个数据点,且必须完全准确才能判定成功,这种"全或无"的评估标准凸显了真实应用场景的严苛性。实验测试了10+主流系统,包括单智能体、多智能体框架和商业系统,结果显示当前技术存在显著瓶颈:即使最优的多智能体系统成功率仅5.1%,而人类在充分时间下可达近100%成功率。分析表明,核心问题在于现有代理缺乏复杂任务分解能力,在搜索失败时缺乏反思机制,且存在证据误用和知识幻觉等问题。特别值得注意的是,通过测试时扩展实验发现,随着尝试次数增加,单元格级准确率可达80%,但表格级成功率仍不足20%,这揭示了大规模信息整合任务的特殊挑战。研究提出多智能体协同验证机制是突破方向,并为未来开发具备人类协作特性的搜索系统提供了明确路径。该基准的建立填补了现有评估体系在广域信息收集能力评测的空白,为推动智能代理技术向实用化发展提供了关键基础设施。
Hugging Face 投票数:105
论文链接:
https://hf.co/papers/2508.07999
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07999
(20) Ovis2.5 Technical Report

论文简介:
由阿里巴巴Ovis团队提出了Ovis2.5,该工作通过原生分辨率视觉感知和深度推理能力升级显著提升了多模态大语言模型的性能。Ovis2.5采用原生分辨率视觉变换器(NaViT)处理可变分辨率图像,避免传统固定分辨率切片导致的细节丢失和全局结构破坏,特别适用于复杂图表等高密度视觉内容分析。在推理能力方面,模型通过训练学习包含自我检查与修正的"思考模式",支持在推理时切换模式以权衡延迟与准确性。训练策略采用五阶段课程式学习,涵盖视觉预训练、多模态预训练、指令微调、DPO对齐及GRPO强化学习,并通过多模态数据打包和混合并行技术实现3-4倍训练加速。模型发布9B和2B参数版本,其中Ovis2.5-9B在OpenCompass榜单取得78.3的平均分,超越同规模开源模型并接近前沿闭源模型,Ovis2.5-2B以73.9分刷新小型模型性能记录。在STEM、图表分析、视觉定位和视频理解等专项测试中均表现突出,尤其在复杂图表分析任务中实现同规模模型的最优表现,同时通过高效训练基础设施优化显著提升训练吞吐量。
Hugging Face 投票数:104
论文链接:
https://hf.co/papers/2508.11737
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11737
(21) VibeVoice Technical Report

论文简介:
由微软研究院等机构提出了VIBEVOICE,该工作设计了一种新型语音合成模型,通过引入next-token diffusion框架和高效连续语音tokenizer,实现了长达90分钟、支持最多4名说话人的高质量对话音频生成。核心创新在于开发了压缩率达3200倍(7.5Hz帧率)的因果语音tokenizer,在保持音质的同时将数据压缩效率提升80倍,并采用轻量级扩散头与大语言模型(LLM)结合的架构,通过混合语音表征建模和流式生成机制,突破了传统TTS在长序列多说话人场景下的合成瓶颈。
VIBEVOICE采用双tokenizer设计:基于σ-VAE的声学tokenizer(340M参数)实现高保真音频重建,其7.5Hz帧率在LibriTTS测试集上取得3.068 PESQ和4.181 UTMOS的领先指标;语义tokenizer则通过ASR任务学习文本对齐特征。模型将语音特征与文本脚本拼接输入LLM(Qwen2.5 1.5B/7B),由LLM预测隐状态并驱动扩散头逐token预测声学VAE特征,最终通过解码器恢复音频。该架构在保持简洁性的同时,通过课程学习策略支持65k上下文窗口训练。
实验显示,VIBEVOICE-7B在对话生成任务中主观评分(Realism 3.71/MOS)和客观指标(WER 1.29%)均超越Elevenlabs、Gemini等竞品,在SEED短句测试集上也保持竞争力(test-zh CER 1.16%)。模型支持跨语言合成且计算效率显著提升,但存在非英语内容输出不稳定、无法生成重叠语音等局限。研究强调该技术需谨慎用于研究场景,避免深度伪造等伦理风险。
Hugging Face 投票数:102
论文链接:
https://hf.co/papers/2508.19205
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19205
(22) SSRL: Self-Search Reinforcement Learning

论文简介:
由清华大学、上海人工智能实验室等机构提出的SSRL(Self-Search Reinforcement Learning)研究揭示了大型语言模型(LLMs)作为内部知识源的潜力,通过结构化提示和重复采样实验证明LLMs在搜索任务中存在显著的性能上限,且参数规模更大的模型表现更优。该方法通过强化学习框架优化LLM的自我搜索能力,设计格式奖励(确保推理步骤结构化)和规则奖励(提升结果准确性),使模型能够自主分解问题、生成搜索查询并整合信息。实验显示SSRL训练的模型在通用问答和多跳推理任务中均超越基于外部搜索的基线方法(如Search-R1和ZeroSearch),在不依赖实时搜索的情况下,Llama-3.1-8B-Instruct模型在HotpotQA等基准测试中达到48.0%的准确率,较基线提升10.7%。研究还验证了Sim2Real迁移能力,当结合真实搜索引擎时,SSRL模型通过熵引导策略动态选择是否调用外部搜索,使平均搜索次数减少20%的同时保持性能。此外,测试时强化学习(TTRL)的应用进一步提升了复杂任务(如BrowseComp)的表现,Llama-3.2-3B-Instruct模型在TTRL训练后准确率提升59%。研究发现指令微调模型比基础模型更擅长利用内部知识,而不同模型家族(如Llama和Qwen)在知识检索效率上存在差异。该方法为降低搜索代理对实时搜索的依赖、提升推理效率和可解释性提供了新思路,相关代码和数据已开源。
Hugging Face 投票数:90
论文链接:
https://hf.co/papers/2508.10874
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10874
(23) Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training

论文简介:
由腾讯AI Lab等机构提出了Cognitive Kernel-Pro,该工作设计了一个完全开源的多模块深度研究代理框架,通过最大化利用免费工具实现先进AI代理的开发与评估。研究团队系统探索了代理基础模型训练数据的构建方法,涵盖网页、文件、代码和推理四大领域的高质量查询-轨迹-答案对生成,并创新性提出测试时反思与投票机制以提升代理鲁棒性。实验表明,该框架在GAIA基准测试中取得开源代理的最佳性能,其基于Qwen3-8B开发的模型在完全免费工具支持下超越了依赖付费工具的WebDancer和WebSailor等系统,在文本子集测试中Pass@1和Pass@3指标均位列同参数量级模型首位。框架采用主代理与网页/文件子代理的分层架构,通过Python代码执行动作空间最大化模型推理能力,同时开发了基于中间过程提示的训练轨迹采样方法和多代理数据增强技术。研究还发现,集成GPT-4.1的多模态能力可使8B参数模型的Pass@3达到38.18%,验证了基础模型能力对代理性能的关键作用。该工作为可复现、可扩展的开源代理研究提供了完整解决方案,推动了AI代理技术的普惠化发展。
Hugging Face 投票数:89
论文链接:
https://hf.co/papers/2508.00414
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00414
(24) A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems

论文简介:
由Jinyuan Fang等学者提出的《A Comprehensive Survey of Self-Evolving AI Agents》系统梳理了从静态预训练模型到多代理自我进化的技术演进路径。研究提出"自我进化AI代理"的三大核心定律:安全适应(Endure)、性能保持(Excel)和自主进化(Evolve),构建了包含系统输入、代理系统、环境和优化器四要素的概念框架。该框架揭示了代理系统通过持续交互环境获取反馈,动态优化提示、记忆、工具使用等组件的闭环进化机制。
在技术层面,研究梳理出单代理优化(如推理增强、提示进化)、多代理优化(拓扑结构搜索、联合提示优化)和领域定制优化(医疗诊断、程序调试)三大技术路径。特别值得关注的是基于蒙特卡洛树搜索的拓扑优化方法,以及通过多代理辩论机制实现的动态工作流重构技术。评估体系方面,研究强调构建包含基准测试(如工具调用、网页导航)、LLM评测和安全对齐的多维评估体系,提出代理法官(Agent-as-a-Judge)等新型评估范式。
当前面临的核心挑战包括:安全适应与性能提升的平衡难题,多模态环境中的进化稳定性问题,以及工具动态构建机制的缺失。未来研究方向聚焦于:开发支持自主工具演化的仿真环境,建立领域定制的进化协议,设计兼顾效率与效果的多代理优化算法,以及构建全生命周期安全评估体系。该研究为构建具备持续学习能力的智能代理系统提供了系统性方法论,标志着AI代理技术正从静态部署迈向自主进化的范式变革。
Hugging Face 投票数:88
论文链接:
https://hf.co/papers/2508.07407
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07407
(25) Efficient Agents: Building Effective Agents While Reducing Cost

论文简介:
由OPPO AI Agent Team提出了Efficient Agents,该工作系统研究了大语言模型驱动智能体系统的效率与效果权衡问题,提出了通过优化框架设计实现成本效益最大化的解决方案。研究发现,当前主流智能体系统存在显著的成本效率瓶颈,特别是在复杂任务处理中推理模型的token消耗与性能提升呈现非线性关系。通过在GAIA基准测试中对LLM骨干选择、规划模块设计、工具调用策略等关键组件的实证分析,团队发现稀疏架构模型在保持基础性能的同时可降低60%以上推理成本,而动态规划步长控制和多源工具调用策略能进一步优化资源分配。基于这些发现构建的Efficient Agents框架,在GAIA测试中实现OWL框架96.7%的性能保持率,同时将单次任务处理成本从0.398美元降至0.228美元,成本效率提升28.4%。该工作通过量化分析揭示了智能体系统各组件的成本敏感度,为构建可扩展的实用化AI系统提供了关键设计范式,其提出的cost-of-pass评估指标和模块化优化策略对产业界部署具有重要参考价值。
Hugging Face 投票数:84
论文链接:
https://hf.co/papers/2508.02694
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02694
(26) Beyond Transcription: Mechanistic Interpretability in ASR

论文简介:
由特拉维夫大学等机构提出了Beyond Transcription: Mechanistic Interpretability in ASR,该工作首次系统性地将可解释性方法应用于自动语音识别领域,通过适配logit lens、线性探测和激活修补等技术,揭示了ASR模型内部的声学语义演化机制,发现了编码器-解码器交互中的重复幻觉现象及深层声学表征中的语义偏差。研究通过在Whisper和Qwen2-Audio两大主流模型上的实验,证实了声学属性(如说话人性别、环境噪音、口音等)在编码器深层的线性可解码性,其中说话人性别识别在25层达到94.6%准确率,环境噪音分类在27层达90.0%。特别发现解码器残差流中存在可预测幻觉的信号,通过线性探测在Whisper第22层实现93.4%的幻觉识别准确率。研究还揭示了ASR编码器的语义理解能力,通过合成音频数据集证明Whisper编码器在22-31层对语义类别(如国家vs天气)的区分度高达96.7%。针对重复幻觉问题,通过跨注意力机制干预在Whisper第23层成功解决76%的重复案例,其中第18层第13注意力头的单头干预有效率达78.1%。该工作为ASR模型的透明化和鲁棒性提升开辟了新路径,展示了通过内部机制分析实现错误定位和针对性优化的潜力。
Hugging Face 投票数:80
论文链接:
https://hf.co/papers/2508.15882
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15882
(27) DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization

论文简介:
由 ByteDance Seed 和南京大学等机构提出了 DuPO(Dual Learning-based Preference Optimization),该工作通过广义对偶框架突破传统对偶学习的局限性,构建了无需人工标注的自监督奖励机制,显著提升了大语言模型在数学推理和多语言翻译等任务上的性能。
DuPO 的核心创新在于提出了一种广义对偶框架,将输入分解为已知和未知部分,通过构建对偶任务重建未知部分来生成自监督奖励信号。该方法解决了传统对偶学习的两大瓶颈:一是不可逆任务中输入输出无法完全互逆的问题(如数学题求解后无法通过答案反推原题),二是模型在主任务和对偶任务间的能力不对称问题(如模型擅长解题但不擅长出题)。具体而言,DuPO 将输入分解为已知部分 和未知部分 ,要求模型在完成主任务(如解数学题)后,利用输出 和已知部分 重建 (如用答案反推题目中的某个变量),通过重建误差生成奖励信号。这种设计既降低了对偶任务的复杂度,又确保了奖励信号的可靠性。
实验部分,DuPO 在多语言翻译和数学推理两大任务上展现出显著效果。在翻译任务中,将 70 亿参数的 Seed-X 模型性能提升至与超大规模模型相当的水平,在 28 种语言 756 个翻译方向上平均 COMET 得分提高 2.13;在数学推理任务中,对 15 亿至 70 亿参数模型均有稳定增益,Qwen3-4B 模型在 AMC23/AIME24/AIME25 三大基准上平均准确率提升 6.4 个百分点。特别值得注意的是,DuPO 作为推理阶段的重排序机制,在不进行训练的情况下,通过 K 次采样验证对偶任务一致性,使 Qwen3-4B 的数学推理准确率提升 9.3 分,甚至超过 DeepSeek-R1 等超大规模模型。
该研究通过解耦输入空间、构建互补对偶任务的方式,为大语言模型提供了一种通用的自监督优化范式。其价值在于摆脱了对人工标注或预定义规则的依赖,通过任务内在结构生成奖励信号,既适用于训练阶段的策略优化,也可作为推理阶段的增强手段,为大规模语言模型的无监督优化提供了新的技术路径。
Hugging Face 投票数:79
论文链接:
https://hf.co/papers/2508.14460
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14460
(28) Deep Think with Confidence

论文简介:
由Yichao Fu等人提出的DeepThink with Confidence(DeepConf)提出了一种基于模型内部置信度的高效推理方法,通过动态过滤低质量推理轨迹显著提升大语言模型的推理效率与准确性。该方法采用局部置信度测量(如最低组置信度、尾部置信度)替代传统全局置信度指标,有效捕捉推理过程中的关键质量波动。在离线模式下,DeepConf通过置信度加权投票与过滤机制,在AIME 2025等数学推理任务中,使用GPT-OSS-120B模型实现99.9%的准确率,相比传统多数投票减少84.7%的token消耗。在线模式下,其自适应采样策略通过实时监控最低组置信度实现动态早停,在保持或提升精度的同时,生成token量减少43-79%。实验覆盖DeepSeek-8B、Qwen3-32B等多参数模型及AIME、HMMT等高难度基准,验证了方法的普适性。DeepConf无需额外训练,可无缝集成于现有推理框架,为资源受限场景下的高效推理提供新范式。
Hugging Face 投票数:78
论文链接:
https://hf.co/papers/2508.15260
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15260
(29) Thyme: Think Beyond Images

论文简介:
由Kwai Keye、CASIA、NJU、THU和USTC联合提出了Thyme(Think Beyond Images),该工作开创性地赋予多模态大语言模型自主生成并执行代码的能力,使其能够动态调用图像裁剪、旋转、对比度增强等操作及数学计算功能,突破传统"用图像思考"范式的局限。研究团队构建了包含50万样本的高质量SFT数据集,涵盖单轮与多轮交互场景,并设计了掩码沙盒内容、末轮训练优先等策略提升代码生成可靠性;在RL阶段创新性提出GRPO-ATS算法,通过文本生成温度1.0与代码生成温度0.0的动态切换,在保证推理探索性的同时确保代码执行精度。实验部分不仅构建了包含3万张高分辨率图像的复杂视觉问答数据集,更在近20项基准测试中展现出显著优势:在MME-Realworld感知任务中提升6.5%,在数学推理任务中超越32B参数模型,且通过代码执行将幻觉率降低5.4%。该工作开源了训练代码、沙盒环境及数据集,为多模态模型的动态工具调用研究提供了完整技术路径。
Hugging Face 投票数:77
论文链接:
https://hf.co/papers/2508.11630
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11630
(30) Self-Rewarding Vision-Language Model via Reasoning Decomposition
Hugging Face 投票数:77
论文链接:
https://hf.co/papers/2508.19652
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19652
(31) Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
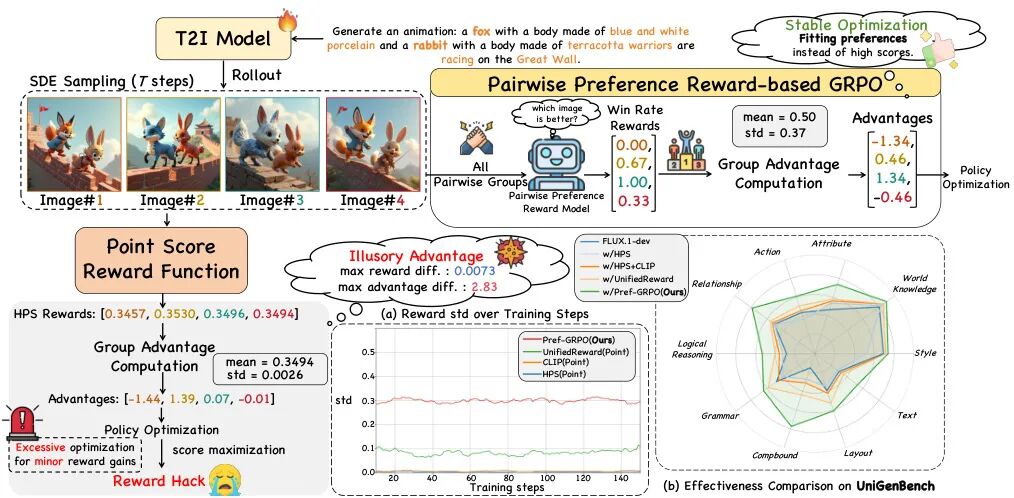
论文简介:
由复旦大学、上海人工智能实验室、腾讯混元等机构提出了Pref-GRPO,该工作揭示了现有文本到图像生成强化学习方法中"奖励黑客"现象的本质原因是"虚假优势"问题,并提出首个基于成对偏好奖励的GRPO优化方法,通过将奖励最大化目标转化为偏好拟合来实现更稳定的生成训练。同时构建了包含600个提示词、覆盖5大主题20个子主题的UniGenBench基准,支持10个主维度27个子维度的细粒度评估,利用多模态大模型实现自动化评估流程。实验表明Pref-GRPO在语义一致性指标上较基线提升5.84%,文本和逻辑推理维度分别提升12.69%和12.04%,有效缓解了奖励分数虚高但质量下降的矛盾。UniGenBench的细粒度评估显示:闭源模型在逻辑推理(48.18%)和文本渲染(89.08%)表现突出,开源模型在动作(69.77%)和布局(77.61%)维度接近闭源水平,但在语法和复杂逻辑任务上仍有显著差距。该研究为文本到图像生成的优化范式和评估体系提供了新的技术路径与标准框架。
Hugging Face 投票数:75
论文链接:
https://hf.co/papers/2508.20751
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20751
(32) TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Hugging Face 投票数:74
论文链接:
https://hf.co/papers/2508.17445
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17445
(33) Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation

论文简介:
由 AgiBot Genie Team、NUS LV-Lab、BUAA 等机构提出了 Genie Envisioner(GE),该工作构建了一个统一的机器人操作基础平台,通过视频生成框架整合策略学习、评估与仿真。GE-Base 作为核心模块,是一个大规模指令条件视频扩散模型,通过结构化潜在空间捕捉真实机器人交互的空间、时间及语义动力学。基于此,GE-Act 通过轻量级流匹配解码器将潜在表示映射为可执行动作轨迹,实现跨形态机器人系统在极少监督下的精确策略推理。GE-Sim 作为动作条件神经模拟器,通过高保真回放支持闭环策略开发,而 EWMBench 则提供标准化基准套件,从视觉保真度、物理一致性及指令-动作对齐三方面评估模型性能。实验表明,GE-Act 在 AgiBot G1 平台上生成54步扭矩轨迹仅需200ms,且在 Franka 和 Agilex Cobot Magic 等新形态系统中,仅需1小时特定任务演示数据即可实现复杂变形物体操作。GE-Sim 通过分布式集群并行化实现每小时数千次策略回放评估,显著加速能力验证。EWMBench 基准测试显示 GE-Base 在机器人世界建模任务中优于现有视频生成模型,其生成视频与人类评估结果高度一致。该平台通过统一的视觉生成框架,为指令驱动的通用具身智能提供了可扩展的实用基础。
Hugging Face 投票数:72
论文链接:
https://hf.co/papers/2508.05635
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05635
(34) Matrix-3D: Omnidirectional Explorable 3D World Generation

论文简介:
由上海人工智能实验室等机构提出了Matrix-3D,该工作提出了一种基于全景表示的宽覆盖可探索3D世界生成框架,通过结合条件视频生成与全景3D重建技术,解决了传统方法在场景生成范围和几何一致性上的局限性。核心创新包括:1)设计了轨迹引导的全景视频扩散模型,采用场景网格渲染作为条件输入,有效缓解了点云渲染导致的摩尔纹和错误遮挡问题,显著提升了生成视频的视觉质量和几何一致性;2)开发了两种3D重建方案——基于关键帧优化的高精度重建流水线和基于Transformer的前馈式全景重建模型,前者通过多视角超分与高斯溅射优化实现细节丰富的3D场景生成,后者则通过两阶段训练策略(先深度预测后属性优化)实现了快速重建;3)构建了首个大规模全景视频数据集Matrix-Pano,包含116K条高分辨率静态全景视频序列,每条数据配备精确的相机轨迹、深度图和文本注释,为全景视频生成与3D重建研究提供了关键数据支撑。实验表明,该方法在全景视频生成质量(PSNR达23.9,FVD低至140)和3D重建精度(PSNR达27.62)上均超越现有方案,生成场景的探索范围显著优于同期工作WorldLabs。该研究为构建广域覆盖的沉浸式3D环境提供了完整的技术路径,对自动驾驶仿真、元宇宙内容生成等领域具有重要应用价值。
Hugging Face 投票数:70
论文链接:
https://hf.co/papers/2508.08086
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08086
(35) ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning

论文简介:
由华南理工大学未来技术学院、Pazhou Lab、腾讯微信AI模式识别中心等机构提出了ComoRAG,该工作提出了一种受认知启发的动态记忆工作空间框架,通过迭代推理循环实现长篇叙事理解中的状态化推理。该方法模仿人类前额叶皮层的元认知调节机制,构建了包含层次化知识源、动态记忆池和元认知控制循环的架构:①层次化知识源从字面证据、语义抽象、情节流程三个维度组织信息;②动态记忆池通过Mem-Encode和Mem-Fuse操作持续整合新证据与历史线索;③元认知循环在推理受阻时触发,通过Self-Probe生成探索性查询,经Tri-Retrieve获取多层证据,最终由Try-Answer生成答案。实验表明,ComoRAG在四个长文本基准测试(200K+ tokens)中持续超越强基线方法,在EN.MC数据集上相对最强基线提升11%,尤其在需要全局理解的叙事性查询上取得19%的F1值提升。其模块化设计可无缝集成到现有RAG方法(如RAPTOR),带来21%的准确率提升,且通过更换更强的LLM可进一步提升性能(GPT-4.1版本在EN.MC达到78.17%准确率)。该工作为长文本理解提供了从信息检索到认知推理的范式转变,通过动态记忆整合机制有效解决了传统RAG方法的状态缺失问题。
Hugging Face 投票数:70
论文链接:
https://hf.co/papers/2508.10419
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10419
(36) rStar2-Agent: Agentic Reasoning Technical Report

论文简介:
由Microsoft Research等机构提出了rStar2-Agent,该工作通过代理强化学习训练出140亿参数的数学推理模型,实现前沿性能突破。核心创新包括:(1)高效RL基础设施支持每秒4.5万次并发代码执行,采用动态负载均衡调度策略提升GPU利用率;(2)GRPO-RoC算法通过"正确时重采样"策略解决代码环境噪声问题,在保持结果奖励机制的同时过滤低质量轨迹;(3)三阶段训练策略从非推理微调起步,逐步扩展响应长度至12K tokens,最终在64张MI300X GPU上仅用510步训练即达到SOTA。实验显示,rStar2-Agent-14B在AIME24和AIME25基准上分别取得80.6%和69.8%的pass@1准确率,超越DeepSeek-R1(671B)的同时生成更短响应(平均9339 tokens vs 14246)。该模型展现出跨领域泛化能力,在科学推理(GPQA-Diamond 60.9%)、工具使用(BFCL v3 60.8%)等任务中表现优异。研究还揭示代理强化学习能激发模型对代码执行结果的反射性tokens,驱动自主探索和纠错。相关代码和训练方案已开源。
Hugging Face 投票数:67
论文链接:
https://hf.co/papers/2508.20722
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20722
(37) PRELUDE: A Benchmark Designed to Require Global Comprehension and Reasoning over Long Contexts

论文简介:
由腾讯微信AI、香港科技大学、香港中文大学和南京工业大学等机构提出了PRELUDE,该工作设计了一个用于评估长文本上下文理解与推理能力的基准测试。核心贡献在于通过判断角色前传故事与原著叙事的一致性,构建了需要全局理解与深度推理的任务场景。研究发现88%的实例需要跨文本多处证据支持,实验显示当前主流大语言模型(如GPT-4o、Gemini-2.5-Pro等)在该任务上比人类表现低15%以上,且存在30%的推理准确率差距。研究团队通过构建包含795个标注实例的数据集(涵盖13部中英文经典文学作品),制定了超越记忆、全局依赖、推理深度、人机差距和超越摘要性等五项评估标准。实验对比了上下文学习、检索增强生成(RAG)、领域内微调等方法,发现模型普遍存在正确答案与错误推理并存的问题,揭示了当前模型在长文本推理上的根本性局限。该工作为评估大语言模型的流体智力提供了自然语言空间的新范式,强调了多证据整合与多步骤推理在长文本理解中的核心地位。
Hugging Face 投票数:66
论文链接:
https://hf.co/papers/2508.09848
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09848
(38) Story2Board: A Training-Free Approach for Expressive Storyboard Generation

论文简介:
由 Hebrew University of Jerusalem 等机构提出了 Story2Board,该工作提出了一种无需训练的分镜生成框架,通过结合潜在面板锚定(LPA)和循环注意力值混合(RAVM)机制,在保持扩散模型生成多样性的同时增强跨面板一致性。方法通过语言模型将故事分解为共享参考提示和面板级提示,利用扩散模型生成双面板图像后裁剪保留目标面板。LPA通过在去噪过程中同步参考面板特征实现跨面板一致性,而RAVM基于双向注意力分数混合语义对齐token的值向量,强化角色身份特征的同时保留空间布局多样性。研究引入了包含100个开放式故事的Rich Storyboard Benchmark数据集,重点评估布局灵活性和环境叙事能力,并提出场景多样性(Scene Diversity)指标量化角色在面板序列中的尺度、姿态和位置变化。实验表明该方法在保持角色一致性的同时,生成的分镜在构图动态性和叙事表现力上显著优于StoryDiffusion、OminiControl等基线方法,用户研究显示其整体偏好度领先。该方法无需模型微调或架构修改,可直接应用于Stable Diffusion 3等扩散模型,为文本到分镜生成提供了兼顾一致性与表现力的轻量化解决方案。
Hugging Face 投票数:66
论文链接:
https://hf.co/papers/2508.09983
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09983
(39) Agent Lightning: Train ANY AI Agents with Reinforcement Learning

论文简介:
由 Microsoft Research 的 Xufang Luo 等人提出了 Agent Lightning,该工作实现了强化学习(RL)训练与 AI 代理执行的完全解耦,允许无缝集成现有代理(如 LangChain、OpenAI Agents SDK、AutoGen 等)而无需代码修改。核心贡献在于:通过将代理执行建模为马尔可夫决策过程(MDP),定义统一数据接口并提出 LightningRL 分层强化学习算法,将任意代理生成的轨迹分解为可训练的过渡状态,从而支持复杂交互逻辑(如多代理协作和动态工作流)的优化。系统层面采用 Training-Agent Disaggregation 架构,通过 Lightning Server 和 Client 实现训练与执行的标准化分离,并引入 OpenTelemetry 等可观测性框架增强数据采集。实验在文本到 SQL、检索增强生成和数学工具使用任务中均展现出稳定性能提升,验证了框架在真实场景中的应用潜力。
Hugging Face 投票数:65
论文链接:
https://hf.co/papers/2508.03680
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03680
(40) DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
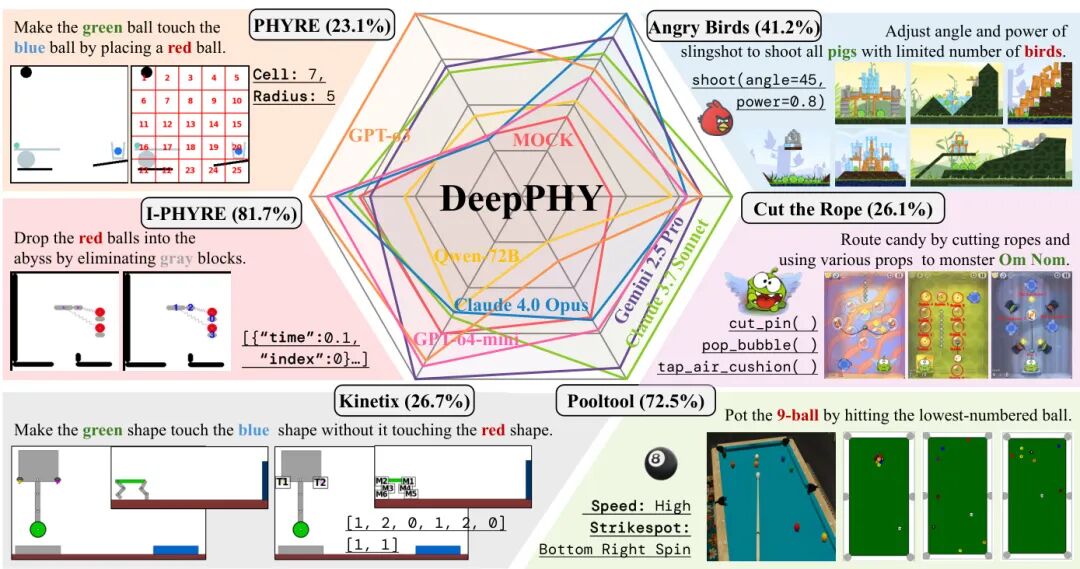
论文简介:
由 Xinrun Xu 等人提出的 DeepPHY 是首个专门评估视觉语言模型(VLMs)交互式物理推理能力的基准测试框架。该工作通过整合 PHYRE、I-PHYRE、Kinetix、Pooltool、Angry Birds 和 Cut the Rope 六个物理模拟环境,系统性地测试了当前主流 VLMs 在动态物理交互、长期规划和动态适应方面的能力边界。研究发现,即使最先进的闭源模型(如 GPT-4o、Claude 4.0)在复杂物理任务中仍存在显著局限:在 PHYRE 环境中顶级模型成功率达 23.1%(10次尝试),但在需要多阶段规划的 Cut the Rope 环境中最高仅 26.14%,远低于人类基准(41.36%)。实验揭示了模型普遍存在"描述性理解"与"程序性控制"的割裂——模型虽能预测物理现象,却难以将知识转化为精确动作。例如在 Pooltool 环境中,GPT-4o-mini 通过固定动作序列达到 100% 成功率,实为暴力策略而非物理推理。研究还发现视觉标注在简单任务中提升性能,但在复杂任务中反而成为认知负担。该工作通过标准化评估协议和多样化物理场景,为推进具身智能体的物理推理能力提供了关键基准,揭示了当前模型在动态交互、因果推理和时序规划方面的核心缺陷。
Hugging Face 投票数:63
论文链接:
https://hf.co/papers/2508.05405
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05405
(41) FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction

论文简介:
由字节跳动、复旦大学、斯坦福大学和普林斯顿大学等机构提出了FutureX,该工作构建了一个面向LLM代理未来预测任务的动态实时基准测试。FutureX通过半自动化流程从全球195个权威网站每日抓取未来事件问题,结合自动化的预测收集与结果验证系统,实现了无数据污染的实时评估闭环。研究发现,具备搜索与推理能力的模型(如Grok-4和GPT-4o-mini)在开放域高波动性任务中表现突出,但整体仍落后于人类专家水平。实验覆盖25个模型,包括基础LLM、增强搜索推理模型和深度研究代理,发现工具使用能力对复杂任务性能提升显著,而基模型在简单任务中仍具优势。特别地,Grok-4在实时金融预测中达到33%的胜率,接近华尔街分析师水平,但深度研究代理易受伪造网站误导,暴露安全漏洞。该基准通过难度分层(基础级到超级代理级)和多模态评估协议(涵盖政治、经济、科技等11个领域),揭示了当前模型在动态信息整合与不确定性推理上的关键短板,为开发具备专家级预测能力的AI系统提供了新方向。
Hugging Face 投票数:62
论文链接:
https://hf.co/papers/2508.11987
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11987
(42) Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models

论文简介:
由香港中文大学和上海人工智能实验室提出了DAEDAL,该工作提出了一种无需训练的动态自适应长度扩展策略,解决了扩散语言模型(DLLMs)依赖预定义固定生成长度的瓶颈问题。DAEDAL通过利用模型内部的预测置信度信号,在生成前动态调整初始长度,并在去噪过程中实时插入掩码令牌扩展不足区域,使模型能够从统一短初始长度出发,实现任务自适应的灵活生成。
################# 分割行,以下为论文原始材料 #############
DAEDAL的核心创新在于双阶段动态调整机制:第一阶段通过计算序列末尾EOS令牌的置信度,在生成前逐步扩展初始长度至任务适配的粗略长度;第二阶段在去噪过程中识别低置信度区域,通过插入掩码令牌进行局部扩展,为复杂推理提供充足空间。实验表明,该方法在数学推理(GSM8K、MATH500)和代码生成(MBPP、HumanEval)任务上,以统一64-token初始长度启动,性能全面超越需人工调优的固定长度基线,同时提升有效令牌利用率(如GSM8K任务有效令牌比率达73.5% vs 基线14.4%)。消融实验证实了双阶段设计的协同效应,且对超参数设置(扩展因子、置信度窗口等)表现出强鲁棒性。该方法突破了扩散模型静态长度限制,显著提升了生成灵活性和计算效率,为非自回归语言模型的动态推理提供了新范式。
Hugging Face 投票数:62
论文链接:
https://hf.co/papers/2508.00819
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00819
(43) MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds

论文简介:
由上海人工智能实验室、清华大学等机构提出的MeshCoder,该工作通过构建大规模点云-代码配对数据集并训练多模态大语言模型,实现了将3D点云转换为可编辑Blender Python脚本的创新框架。核心贡献包括:1)开发了支持复杂几何生成的Blender Python API体系,突破传统DSL仅能表示简单几何体的限制;2)通过参数化生成1000万点云-代码对(含41个类别、单物体超100个部件),构建了首个面向程序化建模的大规模数据集;3)提出两阶段训练策略:先训练部件级代码生成模型,再通过部件拼接生成完整物体代码,最终模型在重建任务中相较Shape2Prog和PLAD等基线方法,在Chamfer Distance和IoU指标上分别提升98.9%和91.8%;4)实现代码驱动的形状编辑能力,通过修改生成代码中的参数即可完成几何拓扑修改(如调整部件尺寸、改变网格分辨率);5)验证了代码表示对3D理解任务的赋能效果,将生成代码输入GPT-4后可准确回答物体结构相关问题。该方法在保持高精度重建的同时,为逆向工程、智能设计等场景提供了兼具可解释性和可编辑性的解决方案。
Hugging Face 投票数:62
论文链接:
https://hf.co/papers/2508.14879
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14879
(44) Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation

论文简介:
由上海人工智能实验室、北京智源人工智能研究院等机构提出了Skywork UniPic,该工作通过解耦编码策略与渐进式训练方法,构建了一个1.5B参数的统一自回归模型,实现了图像理解、文本到图像生成与图像编辑的深度融合。核心创新包括:1)采用Masked Autoregressive Encoder(MAR)与SigLIP2双编码器分别优化生成与理解任务,通过共享解码器实现跨任务知识迁移;2)设计从256×256到1024×1024的分辨率渐进训练策略,动态解冻参数以平衡模型容量与训练稳定性;3)构建百万级高质量多模态数据集,并引入基于Group Relative Policy Optimization的图像质量奖励模型与编辑对齐奖励模型。实验表明,该模型在GenEval(0.86)、DPG-Bench(85.5)等生成基准测试中超越多数同类模型,在GEditBench-EN(5.83)和ImgEdit-Bench(3.49)等编辑任务中表现优异,且支持在RTX 4090显卡上生成1024×1024图像。与BAGEL(14B)、UniWorld-V1(19B)等大模型相比,其参数效率提升近十倍,验证了紧凑架构实现多模态统一建模的可行性。代码与模型权重已开源,为资源受限场景下的多模态应用提供新范式。
Hugging Face 投票数:59
论文链接:
https://hf.co/papers/2508.03320
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03320
(45) 4DNeX: Feed-Forward 4D Generative Modeling Made Easy

论文简介:
由南洋理工大学和上海人工智能实验室等机构提出了4DNeX,该工作首次实现了从单张图像生成动态3D场景的前馈式生成框架。研究者通过构建包含1000万帧伪标注的4DNeX-10M数据集解决4D数据稀缺问题,提出RGB与XYZ序列联合建模的6D视频表示法,并设计了宽度维度特征融合、XYZ初始化等策略适配预训练视频扩散模型。实验表明该方法在保持高动态场景生成质量的同时,将生成时间从现有方法的60分钟压缩至15分钟,生成的动态点云可直接用于高质量多视角视频渲染。通过宽度维度特征融合策略有效缩短跨模态交互距离,显著提升了几何与外观的一致性。该方案为单图像驱动的4D世界模型构建提供了高效可扩展的解决方案,在AR/VR和数字内容创作领域具有重要应用价值。
Hugging Face 投票数:58
论文链接:
https://hf.co/papers/2508.13154
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13154
(46) Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
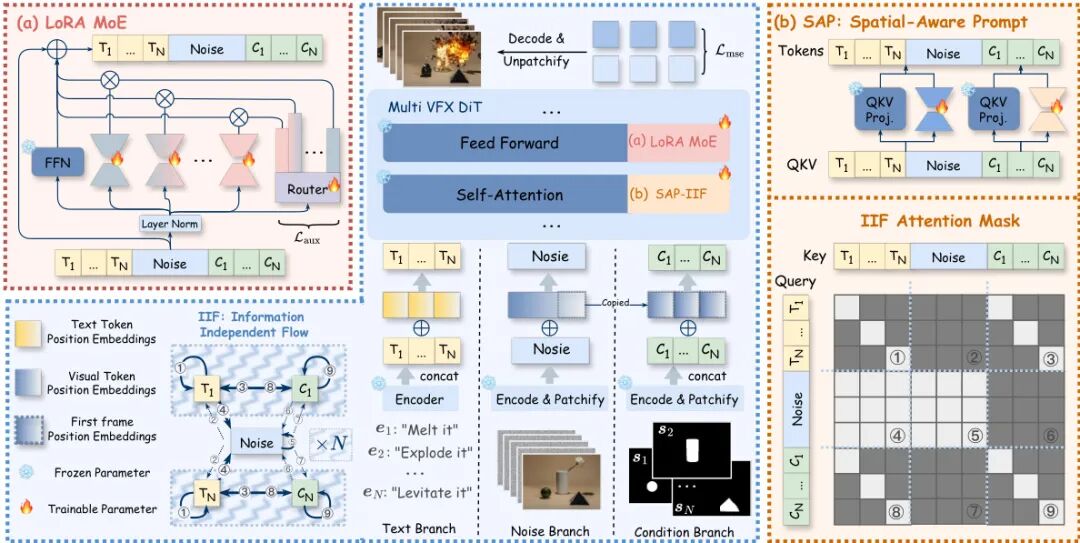
论文简介:
由阿里巴巴等机构提出了Omni-Effects,该工作构建了一个统一的视觉效果生成框架,支持通过文本提示和空间掩码实现单效、多效及空间可控的视觉效果生成。针对传统方法在多效生成中的任务干扰和空间控制不足问题,研究者创新性地引入LoRA-MoE模块,通过专家LoRA组的动态路由机制实现多效协同训练,有效抑制跨任务干扰;同时设计空间感知提示(SAP)机制,将空间掩码信息嵌入文本token,并通过独立信息流(IIF)模块隔离不同控制信号,避免效果混合。为支撑研究,团队构建了包含55类视觉效果的Omni-VFX数据集,并提出包含区域动态度(RDD)、效果触发率(EOR)等指标的评估体系。实验表明,Omni-Effects在多效生成任务中FVD指标优于传统LoRA方法20%以上,在空间控制任务中EOR达到0.97,ECR达0.88,显著优于CogVideoX等基线模型。该框架在电影特效、游戏开发等领域具有广阔应用前景,为可控视觉生成提供了新范式。
Hugging Face 投票数:58
论文链接:
https://hf.co/papers/2508.07981
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07981
(47) From Scores to Skills: A Cognitive Diagnosis Framework for Evaluating Financial Large Language Models

论文简介:
由武汉大学、南京审计大学等机构提出了FinCDM,该工作构建了首个面向金融大语言模型的认知诊断评估框架,通过知识技能级评估揭示模型在金融领域的具体能力分布。针对现有金融模型评估依赖单一分数且数据集覆盖片面的问题,研究团队创新性地将教育评估中的认知诊断模型(CDM)引入金融领域,开发了包含70个核心金融概念的CPA-QKA数据集,该数据集基于注册会计师考试体系构建,经三阶段专家标注验证,实现0.937的高标注一致性。实验基于30个主流模型(含闭源、开源及金融专用模型)的对比显示:FinCDM能有效识别模型在税务、租赁分类等关键领域的知识盲区,发现Claude3.7等高分模型实际仅掌握39/70概念,而Doubao-1.5-Pro在财务成本管理领域表现突出;同时揭示现有基准如FinEval-KQA存在70%问题集中于5个概念的结构性偏差。通过非负矩阵分解技术,该框架将模型响应矩阵分解为问题-技能-概念的三维表征,实现对模型能力的可解释诊断,相关代码与数据集将开源以推动领域发展。
Hugging Face 投票数:58
论文链接:
https://hf.co/papers/2508.13491
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13491
(48) Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off

论文简介:
由NXN Labs等机构提出了Voost,该工作提出了一种统一且可扩展的扩散Transformer框架,通过单个模型同时实现双向虚拟试穿(Virtual Try-On)和试脱(Try-Off)任务。Voost通过联合建模两个方向的任务,使每个服装-人体对能够互相监督,从而增强服装与人体的空间对应关系,无需依赖任务特定的网络结构、辅助损失函数或额外标注数据。方法上,Voost采用水平拼接的输入布局,将服装图像与人体图像作为共享嵌入空间的条件输入,并通过任务令牌(task token)动态编码生成方向(试穿/试脱)和服装类别(上装/下装/全身装),支持灵活的多任务学习。此外,研究者引入了两种推理优化技术:注意力温度缩放(根据输入分辨率和掩码比例动态调整注意力分布)和自修正采样(通过双向一致性约束迭代优化生成结果),显著提升了生成质量与鲁棒性。实验表明,Voost在VITON-HD和DressCode等基准数据集上均超越了现有方法,在结构一致性(如SSIM、LPIPS)、视觉保真度(FID、KID)等指标上取得最优结果,同时在野外图像(in-the-wild)的复杂姿态、光照和背景条件下表现出优异的泛化能力。用户研究表明,Voost在照片级真实感、服装细节保留和结构一致性方面均获得最高评价。该工作通过统一框架实现双向服装-人体交互建模,为虚拟试衣技术提供了高效且可扩展的新范式。
Hugging Face 投票数:57
论文链接:
https://hf.co/papers/2508.04825
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04825
(49) LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos

论文简介:
由 National Yang Ming Chiao Tung University 和 NVIDIA Research 等机构提出了 LongSplat,该工作针对随意拍摄的长视频提出了一种鲁棒的无位姿 3D 高斯分布渲染框架。该方法通过增量联合优化策略同步优化相机位姿和 3D 高斯分布,有效避免局部最优并确保全局一致性。其核心贡献包括:1)增量联合优化方法,通过全局优化和可见性自适应的局部窗口交替优化,在长序列中保持几何一致性;2)鲁棒的位姿估计模块,利用学习到的 3D 先验进行对应引导的 PnP 初始化和光度细化,显著提升位姿精度;3)高效的八叉树锚点形成机制,根据空间密度动态调整体素大小,将密集点云转换为锚点表示,在保持细节的同时降低内存占用。实验表明,该方法在 Tanks and Temples、Free 和 Hike 等复杂数据集上均取得最优结果,渲染质量(PSNR 提升 3.5dB)、位姿精度(ATE 降低 70%)和计算效率(训练速度提升 30 倍)均显著优于 COLMAP+NeRF、NoPe-NeRF、LocalRF 等主流方法。特别在复杂轨迹和长序列场景中,通过自适应八叉树压缩(7.92× 内存缩减)和可见性约束的局部优化,有效解决了传统方法存在的内存溢出、位姿漂移和细节丢失问题,为大规模动态场景重建提供了新思路。
Hugging Face 投票数:57
论文链接:
https://hf.co/papers/2508.14041
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14041
(50) SitEmb-v1.5: Improved Context-Aware Dense Retrieval for Semantic Association and Long Story Comprehension

论文简介:
由 HKUST、WeChat AI 等机构提出了 SitEmb-v1.5 情境感知嵌入模型,该工作针对长文档检索中短文本块依赖上下文理解的问题,提出通过将短文本块与其周围语境结合生成情境化嵌入的解决方案。研究发现现有嵌入模型在处理长上下文时存在信息压缩瓶颈,单纯增加文本块长度反而降低检索性能。为此,团队创新性地构建了基于用户书评数据的训练范式,通过残差学习机制强化模型对上下文信息的利用能力。实验表明,基于 BGE-M3 的 SitEmb-v1 模型以 10 亿参数规模超越了多款 70 亿参数级模型,在书情节检索任务 Recall@50 指标上提升达 10% 以上。最新推出的 80 亿参数 SitEmb-v1.5 模型进一步将性能提升 15%,并在跨语言任务和故事理解、语义关联等下游应用中展现显著优势。团队通过控制实验验证了训练数据与测试数据重叠不会影响模型泛化能力,并证明模型对不同长度上下文的鲁棒性。该研究为长文本理解提供了新的技术路径,在智能阅读助手、剧情分析等实际场景具有重要应用价值。
Hugging Face 投票数:56
论文链接:
https://hf.co/papers/2508.01959
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01959
(51) BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining

论文简介:
由 DatologyAI 团队提出的 BeyondWeb,该工作通过系统性研究揭示了合成数据生成的关键因素,并提出了一种基于网络数据改写的高效预训练数据生成框架。研究发现,简单扩大网络数据规模会导致收益递减,而高质量合成数据可突破数据瓶颈。BeyondWeb 通过格式转换(如问答对生成)、风格优化(增强教学语气)和内容重构提升信息密度,在14项基准测试中,其生成的合成数据使3B参数模型在180B token训练后超越8B模型的性能,训练速度较开放网络数据提升7.7倍,较Nemotron-CC的高质量子集提升2.7倍。实验表明:1)数据质量比新颖性更重要,基于高质量网络数据的改写优于低质量数据的生成;2)风格匹配(如增加对话式数据)能提升下游任务表现,但需控制比例;3)生成策略的多样性对大规模训练至关重要,单一生成模式易导致过拟合;4)生成器模型家族差异对结果影响有限,3B参数的改写模型即可产生优质数据。研究还发现,BeyondWeb生成的合成数据在1B/3B/8B模型上分别取得+3.1pp/+2.0pp/+2.6pp的提升,建立新的效率-性能帕累托前沿。这项工作证明,合成数据生成需要同时优化数据选择、生成策略、多样性保持和质量控制等多维度因素,其提出的系统性优化方法为大规模预训练数据构建提供了重要参考。
Hugging Face 投票数:56
论文链接:
https://hf.co/papers/2508.10975
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10975
(52) Mobile-Agent-v3: Foundamental Agents for GUI Automation

论文简介:
由阿里云等机构提出了Mobile-Agent-v3和GUI-Owl,该工作构建了面向GUI自动化的基础模型与多智能体框架。GUI-Owl基于Qwen2.5-VL架构,通过大规模环境基础设施构建的自演进轨迹数据生成管道,实现了感知、规划、推理与执行的统一建模。其创新点包括:1)多平台环境支持的虚拟化训练基础设施,结合查询生成、轨迹校验和定向指导模块,形成数据-模型闭环优化;2)多维度能力构建,涵盖UI定位、任务规划、动作语义等基础能力,以及离线拒绝采样、多智能体蒸馏等推理增强策略;3)面向长序列任务的轨迹感知相对策略优化(TRPO)算法,通过轨迹级奖励分配和重放缓冲机制解决信用分配难题。在AndroidWorld和OSWorld基准测试中,GUI-Owl-7B分别取得66.4和29.4的SOTA成绩,Mobile-Agent-v3进一步提升至73.3和37.7。该框架包含四大核心模块:基于RAG的动态任务规划器、执行动作的Worker、反馈修正的Reflector以及持久化记忆的Notetaker,通过角色分工与协同实现复杂任务的鲁棒执行。实验表明其在多智能体协作场景中成功率达62.1%,显著优于现有开源模型。相关代码与模型已开源,为GUI自动化领域提供了先进的技术范式。
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2508.15144
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15144
(53) Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning

论文简介:
由Nebius AI等机构提出了基于强化学习训练长上下文多轮软件工程代理的方法,该工作通过改进的Decoupled Advantage Policy Optimization(DAPO)算法,成功将Qwen2.5-72B-Instruct模型在SWE-bench Verified基准的通过率从20%提升至39%,且无需依赖教师模型。研究针对软件工程任务的多轮交互特性,设计了包含拒绝式微调(RFT)和多阶段RL优化的两阶段训练框架:首先通过RFT提升模型与环境交互的指令遵循能力,再通过动态调整上下文长度(从65k扩展至131k tokens)和任务难度的RL阶段,实现策略优化。实验表明,该方法在SWE-rebench基准上超越DeepSeek-V3-0324和Qwen3-235B等主流开源模型,验证了RL在复杂状态环境中的有效性。核心创新点包括:改进DAPO算法的不对称裁剪策略、动态轨迹过滤机制及基于token级别的损失计算;针对长时程依赖问题设计的上下文并行训练架构;以及通过任务动态筛选策略聚焦高价值学习样本。研究还揭示了RL训练中采样与优化分布一致性对稳定性的影响,并提出未来在奖励塑形、不确定性建模等方向的优化路径,为构建自主软件工程代理提供了新范式。
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2508.03501
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03501
(54) Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory

论文简介:
由ByteDance、浙大和上海交大等机构提出的M3-Agent,构建了一个具备长期记忆的多模态智能体框架。该框架通过实时处理视频和音频流,生成包含情景记忆(具体事件)和语义记忆(通用知识)的实体中心化长期记忆网络,实现跨模态的持续知识积累。其核心创新在于:1)采用面部识别和语音识别工具构建稳定的人物身份表示,确保跨视频片段的身份一致性;2)设计强化学习驱动的多轮推理机制,通过迭代检索记忆库中的相关片段完成复杂指令;3)开发包含1,276个问题的M3-Bench-robot机器人视角数据集,以及涵盖929个视频的M3-Bench-web数据集,重点考察人物理解、跨模态推理等能力。
实验对比了Socratic模型、在线视频理解方法等基线,M3-Agent在M3-Bench-robot、M3-Bench-web和VideoMME-long基准测试中分别取得6.7%、7.7%和5.3%的准确率提升。消融实验表明:语义记忆缺失会导致准确率下降17.1%-19.2%,强化学习训练带来10.0%-9.3%的性能增益。案例分析显示,该框架能有效关联人物身份、推理人物性格(如判断角色是否富有想象力),但在空间推理和细节记忆方面仍存在挑战。这项工作为多模态智能体的长期记忆构建提供了新范式,推动智能体向更接近人类的持续学习能力发展。
Hugging Face 投票数:53
论文链接:
https://hf.co/papers/2508.09736
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09736
(55) PixNerd: Pixel Neural Field Diffusion

论文简介:
由南京大学、ByteDance Seed和新加坡国立大学的研究人员提出了PixNerd(Pixel Neural Field Diffusion),该工作通过引入神经场建模大块补丁解码,构建了首个单阶段、单尺度的像素空间扩散模型。针对传统扩散模型依赖预训练VAE导致的解码伪影和训练复杂性问题,PixNerd创新性地将扩散Transformer的最终线性投影替换为隐式神经场,通过预测各补丁神经场MLP权重,结合坐标编码与噪声像素值进行逐像素速度预测,在保持与潜在扩散模型相似计算成本的前提下,实现了端到端的像素空间生成。
在ImageNet 256×256分辨率上,PixNerd-XL/16达到2.15 FID和4.55 sFID,显著优于PixelFlow等像素生成模型;在512×512分辨率下通过微调保持2.84 FID。文本到图像生成任务中,PixNerd-XXL/16在GenEval基准获得0.73综合得分,在DPG基准取得80.9平均分。模型通过DCT基坐标编码和归一化策略优化神经场设计,采用Adams-2nd求解器实现25步快速采样,训练吞吐量较ADM-G提升8倍。该工作验证了像素空间扩散模型的可行性,为消除VAE依赖提供了新范式,但复杂场景下的细节生成能力仍需提升。
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2507.23268
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23268
(56) ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing

论文简介:
由腾讯ARC Lab、香港中文大学等机构提出了ToonComposer,该工作提出了一种生成式后关键帧技术,通过稀疏草图注入和空间低秩适配策略,将传统动画制作中的中间帧生成与上色阶段整合为统一自动化流程。ToonComposer基于DiT架构构建,支持仅用单张关键帧草图和彩色参考帧生成高质量卡通视频,其核心创新包括:1)稀疏草图注入机制,通过位置编码映射和位置感知残差模块实现跨时间步的精确草图控制;2)空间低秩适配器(SLRA),在保留时序先验的前提下,通过空间维度低秩分解实现卡通域适配;3)区域级控制功能,允许艺术家指定空白区域由模型根据上下文生成动态内容。研究团队构建了包含3.7万条卡通视频片段的PKData数据集,并推出含真实手绘草图的PKBench基准测试。实验表明,ToonComposer在视觉质量(LPIPS降低52.5%)、运动一致性(DISTS降低73.3%)和生产效率方面全面超越现有方法,支持从单草图到多关键帧的灵活控制,为动画制作提供了兼具精度与效率的生成式解决方案。该方法通过消除传统流程中的误差累积问题,显著降低了人工干预需求,同时保持了艺术风格一致性。
#################
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2508.10881
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10881
(57) Speed Always Wins: A Survey on Efficient Architectures for Large Language Models

论文简介:
由上海人工智能实验室、香港科技大学(广州)、澳门大学等机构提出了《Speed Always Wins: A Survey on Efficient Architectures for Large Language Models》,该工作系统梳理了大语言模型(LLMs)高效架构的最新进展,重点解决传统Transformer模型在长序列处理中的计算效率瓶颈。研究团队从语言建模出发,全面分析了线性序列建模、稀疏注意力、混合专家系统(MoE)、扩散模型等技术的优化路径,提出通过降低自注意力机制的二次复杂度(O(N²))或改进计算范式(如硬件感知优化)来提升模型效率。核心贡献包括:1)提出线性序列建模的统一框架,涵盖线性注意力、线性RNN、状态空间模型(SSM)及测试时训练(TTT)等方法,通过核函数近似、矩阵分解或动态记忆更新实现线性复杂度(O(N));2)总结稀疏注意力的静态(如滑动窗口、块稀疏)与动态(如哈希分桶、可学习路由)策略,强调通过选择性交互减少计算冗余;3)提出混合架构设计,如层内/层间线性与全注意力的协同、稀疏MoE的条件计算,平衡效率与性能;4)拓展高效架构至多模态场景,验证其在视觉、音频等领域的通用性。研究指出,高效架构需兼顾算法创新与硬件适配(如FlashAttention系列优化显存访问),未来方向包括动态计算分配、跨模态迁移及可持续的AI系统设计,为构建资源友好的智能模型提供系统性指导。
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2508.09834
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09834
(58) SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了SEAgent,该工作提出了一种自演进的计算机使用代理框架,使代理能够通过自主探索和经验学习掌握新软件。核心创新包括:1)设计World State Model进行细粒度轨迹评估,结合状态变化描述提升奖励信号精度;2)构建Curriculum Generator生成动态任务序列,通过软件指南记忆实现课程学习;3)采用对抗模仿学习失败动作与GRPO优化成功动作的混合强化学习策略;4)提出专家到通才的训练范式,先训练各软件专家模型再蒸馏为通用模型。实验显示,SEAgent在OS-World五个专业软件环境中成功率从11.3%提升至34.5%,超越现有开源代理UI-TARS 23.2个百分点。其专家到通才策略更使通用模型性能反超各专家模型集成效果。该框架突破了传统依赖人工标注数据的训练范式,通过全开源模型构建了完整的自主进化系统,为开发无需人工干预的通用计算机代理提供了新思路。
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2508.04700
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04700
(59) LongVie: Multimodal-Guided Controllable Ultra-Long Video Generation

论文简介:
由复旦大学、南洋理工大学等机构提出的LongVie,针对可控超长视频生成任务,通过多模态引导和退化感知训练策略,解决了现有方法在生成一分钟以上视频时面临的时间不一致和视觉质量退化问题。该工作创新性地提出统一噪声初始化策略,通过共享跨片段的噪声输入维持生成一致性;采用全局控制信号归一化确保全视频范围的场景对齐;引入密集(深度图)与稀疏(关键点)控制信号的多模态融合框架,并设计特征级与数据级的退化训练机制平衡模态贡献。为验证方法有效性,团队构建了包含100个真实场景与游戏画面的LongVGenBench基准数据集,每个视频时长均超过一分钟。实验显示,LongVie在时间一致性、视觉质量等7项指标上全面超越CogVideoX、StreamingT2V等基线模型,用户研究得分提升40%以上。该框架还支持视频编辑、运动迁移、三维网格驱动等下游任务,在影视制作和内容创作领域具有重要应用价值。
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2508.03694
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03694
(60) Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL

论文简介:
由清华大学、蚂蚁集团和华盛顿大学的研究团队提出了ASearcher,该工作通过大规模异步强化学习训练解锁了搜索代理的长时程搜索能力。核心贡献包括:1)可扩展的完全异步强化学习训练框架,支持单轨迹最高128轮的长时程搜索,训练效率提升显著;2)基于提示词的LLM代理可自主生成高质量QA数据集,通过注入事实和模糊信息等操作构建25,624个高难度样本;3)在xBench和GAIA等基准测试中,基于QwQ-32B的ASearcher-Web-QwQ模型取得42.1和52.8的Avg@4分数,较基线提升20.8%-46.7%。实验表明,该方法不仅在本地知识库任务中超越32B模型,更在网页搜索场景中展现出强大的长时程规划能力,工具调用超过40轮、生成文本超15万tokens。ASearcher通过开源训练框架和高质量数据集,为构建具备复杂问题解决能力的搜索代理提供了可复用的解决方案。
Hugging Face 投票数:48
论文链接:
https://hf.co/papers/2508.07976
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07976
(61) Next Visual Granularity Generation

论文简介:
由Yikai Wang等学者提出了Next Visual Granularity (NVG)图像生成框架,该工作通过将图像分解为具有不同视觉粒度的结构化序列,实现从全局布局到细节纹理的分层生成。NVG通过多粒度量化自编码器构建视觉粒度序列,每个阶段使用不同数量的唯一token表示图像,在相同空间分辨率下形成从粗到细的层次结构。生成过程采用迭代方式,先生成结构图再生成对应内容,通过结构感知的旋转位置编码(RoPE)和残差建模机制,有效缓解了传统自回归模型的误差累积问题。
实验表明,NVG在ImageNet 256×256图像生成任务中表现出色,与VAR系列模型相比,FID指标从3.30提升至3.03,IS和Recall等指标也全面超越。模型通过结构嵌入技术实现了显式的布局控制能力,可复用参考图像的结构图生成新内容,在保持结构一致性的同时保证细节多样性。该方法在生成过程中自然融入结构控制,无需额外条件模块,为图像生成提供了更直观的控制维度。研究还展示了通过固定不同阶段的结构/内容实现渐进式生成控制的能力,为可控图像生成提供了新的技术路径。
Hugging Face 投票数:46
论文链接:
https://hf.co/papers/2508.12811
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12811
(62) CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics

论文简介:
由上海人工智能实验室等机构提出了CMPhysBench,该工作构建了一个包含520道研究生水平问题的基准测试集,旨在评估大语言模型在凝聚态物理领域的推理能力。CMPhysBench覆盖磁学、超导、强关联体系等核心子领域,强调开放式计算题型,要求模型独立生成完整解题步骤。为实现细粒度评估,研究团队提出Scalable Expression Edit Distance(SEED)指标,通过树状结构表达式匹配支持多类型答案的非二元评分,显著提升评估准确性。实验显示当前最优模型Grok-4在SEED评分中仅得36分,准确率28%,凸显大语言模型在前沿物理领域的显著能力差距。该基准测试的代码与数据已开源,为推动领域发展提供了重要工具。
Hugging Face 投票数:46
论文链接:
https://hf.co/papers/2508.18124
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18124
(63) USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning

论文简介:
由字节跳动UXO团队等机构提出了USO(Unified Style-Subject Optimized),该工作通过解耦内容与风格特征并引入奖励学习机制,首次实现了风格驱动与主体驱动生成任务的统一框架。现有方法通常将风格相似性与主体一致性视为对立目标,而USO通过构建包含20万组三元组数据(风格参考图、去风格化主体图、风格化结果图)的训练集,提出跨任务协同解耦范式:利用主体生成模型生成高质量风格化数据,再通过风格奖励引导的解耦训练优化主体模型。技术上采用SigLIP多尺度特征投影实现风格对齐训练,并通过内容-风格解耦编码器分离条件特征,最终结合风格奖励学习(SRL)进一步提升解耦效果。研究团队还发布了首个支持风格/主体/联合任务评估的基准USO-Bench,包含50组内容图与50组风格图的组合测试集。实验显示USO在Subject-Driven任务中取得0.623 CLIP-I和0.793 DINO的SOTA成绩,在Style-Driven任务中以0.557 CSD和0.282 CLIP-T超越现有方法,在联合任务中更以0.495 CSD和0.283 CLIP-T显著领先基线模型。消融实验证实风格奖励学习使CSD提升8.2%,解耦编码器使CLIP-I提升2.9%,验证了跨任务协同解耦的有效性。该方法支持任意主体与风格的自由组合生成,在保持高文本对齐度的同时,解决了传统方法中风格迁移时主体失真和主体生成时风格干扰的核心矛盾。
Hugging Face 投票数:45
论文链接:
https://hf.co/papers/2508.18966
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18966
(64) SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens

论文简介:
由AIRI、MSU等机构提出了SONAR-LLM,该工作提出了一种新型自回归Transformer模型,其核心创新在于将连续的句子嵌入预测与离散的token级交叉熵监督相结合。模型在SONAR嵌入空间中进行语义级推理,同时通过冻结的SONAR解码器将损失反向传播至token层级,既保留了语义抽象优势又解决了传统概念模型(如LCM)的训练稳定性问题。实验表明,SONAR-LLM在39M至1.3B参数规模下均表现出色,在XSum/CNN/DM摘要任务中超越MSE和Diffusion LCM基线,接近传统LLM水平;理论分析显示其在长序列(>4096 tokens)推理时计算效率显著优于token级模型。研究团队还系统分析了扩展定律,验证了模型参数增长与性能提升的幂律关系,并全面开源了代码与预训练模型,为后续研究提供了重要基础。该工作通过混合连续-离散建模范式,在保持生成质量的同时优化了长文本生成效率,为下一代语言模型架构设计提供了新思路。
Hugging Face 投票数:45
论文链接:
https://hf.co/papers/2508.05305
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05305
(65) S^2-Guidance: Stochastic Self Guidance for Training-Free Enhancement of Diffusion Models

论文简介:
由清华、阿里等机构提出了S²-Guidance,该工作针对扩散模型中广泛使用的无分类器引导(CFG)存在的语义不一致和低质量输出问题,提出了一种无需额外训练的随机自引导方法。通过理论分析高斯混合模型发现,CFG的次优预测可通过模型自身子网络进行有效修正,进而提出利用前向过程中的随机块丢弃构建潜在子网络,动态生成引导信号以规避低质量预测区域。该方法在文本到图像和文本到视频生成任务中均表现出显著优势:在HPSv2.1基准上,SD3模型的平均得分提升0.61%,SD3.5提升0.74%,且在复杂场景理解指标(如颜色、形状)上提升超10%;在视频生成领域,Wan1.3B模型的总分提升0.64%,Wan14B提升0.19%。实验表明,S²-Guidance不仅保持了与CFG相当的计算效率(单步块丢弃即可),还能生成更精细的纹理细节(如宇航员头盔透明度)、更连贯的动态效果(如汽车加速运动的动态模糊),同时避免了传统弱模型构建的训练依赖和架构限制。通过引入基于模型不确定性的反向引导机制,该方法在美学质量(Qalign)和提示对齐度等维度全面超越CFG及APG、CFG++等先进方法,为扩散模型的条件引导提供了新的优化范式。
Hugging Face 投票数:44
论文链接:
https://hf.co/papers/2508.12880
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.12880
(66) Phi-Ground Tech Report: Advancing Perception in GUI Grounding

论文简介:
由 Microsoft 等机构提出了 Phi-Ground 模型家族,该工作通过系统性研究 GUI 接地任务中的数据、算法和训练策略,显著提升了计算机使用代理(CUA)在界面交互中的坐标定位能力。研究聚焦于鼠标点击坐标预测这一核心挑战,采用两阶段方案:先由大模型生成详细参考表达式(RE),再由轻量级模型输出坐标。通过分析输入输出格式、数据分布、计算效率等关键因素,团队构建了包含4000万样本的多源训练集,并设计了针对高分辨率界面的数据增强策略。
实验表明,输入顺序(文本先于图像)可使模型关注指令相关区域,而坐标文本化表示配合交叉熵损失在大规模训练中优于传统回归方法。在 ScreenSpot-pro 和 UI-Vision 等五项基准测试中,Phi-Ground-7B-16C-DPO 模型分别取得55.0%和36.2%的点击准确率,显著超越现有方法。研究还发现:1)多轮 DPO 微调可提升领域适配能力;2)计算效率需综合参数量与图像令牌数考量;3)语言偏差和空间推理缺陷是主要错误来源。该成果不仅推动了 GUI 接地技术发展,其数据策略和训练范式对多模态感知任务也具普适参考价值。
Hugging Face 投票数:44
论文链接:
https://hf.co/papers/2507.23779
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23779
(67) Prompt Orchestration Markup Language

论文简介:
由Microsoft Research上海团队提出了Prompt Orchestration Markup Language(POML),该工作通过构建首个专为提示工程设计的结构化标记语言体系,系统性解决了大语言模型应用中长期存在的提示结构混乱、多模态数据集成困难、格式敏感性高及开发工具链缺失四大核心挑战。POML的核心创新包括:(1)基于HTML语法的分层标记系统,通过
Hugging Face 投票数:44
论文链接:
https://hf.co/papers/2508.13948
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13948
(68) ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks

论文简介:
由浙江大学等机构提出了ODYSSEY,该工作提出了一种四足机器人移动操作框架,通过整合分层任务规划与地形自适应全身控制,实现了开放环境中的长时程任务执行。针对语言引导的移动操作三大挑战——受限感知、操作泛化性不足及机动性与精确控制的平衡,研究团队创新性地构建了基于视觉语言模型的分层规划器,将自然语言指令分解为可执行的原子动作序列,并通过几何约束的末端姿态生成实现精准操作。在控制层面,基于强化学习的全身策略通过地形不变的末端采样策略和域随机化训练,实现了复杂地形下的稳定运动与操作协同。研究还构建了首个涵盖室内外场景、包含246种室内和58种室外配置的长时程移动操作基准测试集,并通过模拟到现实的迁移验证了系统在真实环境中的泛化能力。实验表明,该框架在室内任务中导航成功率达97.4%,操作成功率超70%,在户外坡地等复杂地形中仍保持46.4%的整体任务完成率,展示了四足操作机器人在非结构化环境中的应用潜力。
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2508.08240
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08240
(69) LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries

论文简介:
由杜克大学和Zoom团队提出的LiveMCP-101构建了一个包含101个真实世界查询的基准测试集,旨在评估AI代理在动态环境中协调使用多领域MCP工具解决复杂任务的能力。该基准通过LLM迭代重写和人工审核优化查询复杂度,覆盖网页搜索、文件操作、数学推理等多类型工具组合场景,并创新性采用基于预设执行计划的评估方法,通过双线程实时验证代理输出与参考轨迹的匹配度,有效应对动态环境下的评估一致性挑战。实验结果显示当前最先进大模型在该基准上的任务成功率均低于60%,其中GPT-5以58.42%的综合成功率位居榜首,但面对高难度任务时成功率骤降至39.02%。研究团队通过深入分析发现模型普遍存在语义参数错误、冗余思考、工具选择偏差等7类典型失效模式,并揭示闭源模型呈现token效率对数曲线特征,而开源模型存在"token消耗-性能提升"脱节现象。该工作通过构建高复杂度测试集和动态评估框架,系统性揭示了当前工具增强型AI在真实场景落地中的核心瓶颈,为改进多工具协调、参数推理和执行效率提供了关键研究方向。
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2508.15760
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15760
(70) Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery

论文简介:
由香港理工大学、上海人工智能实验室等机构提出了Mol-R1,该工作针对分子发现领域中文本生成分子结构任务的推理能力不足问题,构建了首个面向显式长链式推理的大语言模型框架。研究团队通过Prior Regulation via In-context Distillation(PRID)策略,利用专家标注示例和逻辑规则指导推理轨迹生成,在仅需单个高质量样本的情况下,高效产出符合化学原理的推理数据。在此基础上,创新性地设计了Molecular Iterative Adaptation(MoIA)训练范式,通过监督微调与强化策略优化的交替迭代,在保持训练稳定性的同时显著提升模型对分子结构的精准生成能力。实验表明,Mol-R1在BLEU、有效率等指标上较QWQ-32B等先进基线模型提升超354%,其推理轨迹质量通过Consistent-F1指标验证达到最优水平。该框架不仅解决了分子领域专家标注数据稀缺的痛点,更通过信息论证明揭示了显式推理路径在降低预测不确定性中的理论价值,为可解释性AI在科学发现中的应用提供了新范式。
Hugging Face 投票数:42
论文链接:
https://hf.co/papers/2508.08401
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08401
(71) Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning

论文简介:
由阿里巴巴、北京交通大学等机构提出了Tricks or Traps? A Deep Dive into RL for LLM Reasoning,该工作系统性地评估了强化学习(RL)在大语言模型(LLM)推理中的应用现状。研究发现,尽管RL在提升LLM推理能力方面取得显著进展,但缺乏标准化技术指南和对机制的深入理解,导致实验设置、训练数据和模型初始化的差异引发结论冲突,给从业者选择技术带来困难。团队通过统一开源框架对常用RL技术进行复现和隔离评估,分析了不同数据难度、模型规模和架构下的技术适用性。研究揭示了关键机制:群体级归一化在多数奖励设置中表现稳健,而批量级归一化在大规模奖励场景更优;令牌级损失聚合对基础模型有效,但对对齐模型提升有限;过长过滤在短中推理任务中能提升准确性,但在长尾任务中效果有限。基于此,团队提出仅需群体均值+批量标准差归一化与令牌级损失聚合的极简组合Lite PPO,在无critic网络的情况下超越了GRPO和DAPO等复杂算法。实验表明,该组合在4B/8B基础模型上持续提升性能,尤其在困难数据集上展现出更强的长尾生成能力。研究强调了技术选择的场景依赖性,为RL在LLM推理中的工程实践提供了清晰的路线图,同时证明了"少即是多"的设计哲学在该领域的有效性。
Hugging Face 投票数:42
论文链接:
https://hf.co/papers/2508.08221
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.08221
(72) MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Hugging Face 投票数:41
论文链接:
https://hf.co/papers/2508.14704
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14704
(73) MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers

论文简介:
由 Accenture 等机构提出的 MCP-Bench 是一个面向复杂真实世界任务的工具使用型大语言模型(LLM)评估基准。该工作基于 Model Context Protocol(MCP)构建了包含 28 个生产级服务器、250 个结构化工具的生态系统,支持跨域多工具协调与长时程任务规划。通过 LLM 驱动的任务合成管道生成模糊指令任务,结合规则验证与 LLM 评判的双层评估框架,MCP-Bench 能全面测试模型在工具检索、参数控制、多跳规划和跨域协作等维度的能力。实验评估了 20 个主流模型,发现尽管头部模型(如 gpt-5、o3)在执行精度上趋近饱和(schema compliance >99%),但在依赖链合规性(dependency awareness 0.76 vs 0.22)、多目标并行效率(parallelism 0.34 vs 0.14)等高阶能力上仍存在显著差距。该基准揭示了当前 LLM 在真实复杂场景中长期规划能力的不足,为推动具身智能体发展提供了标准化评估平台。代码与数据已开源,支持研究者持续优化模型的现实世界任务解决能力。
Hugging Face 投票数:41
论文链接:
https://hf.co/papers/2508.20453
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20453
(74) Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.18032
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18032
(75) XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
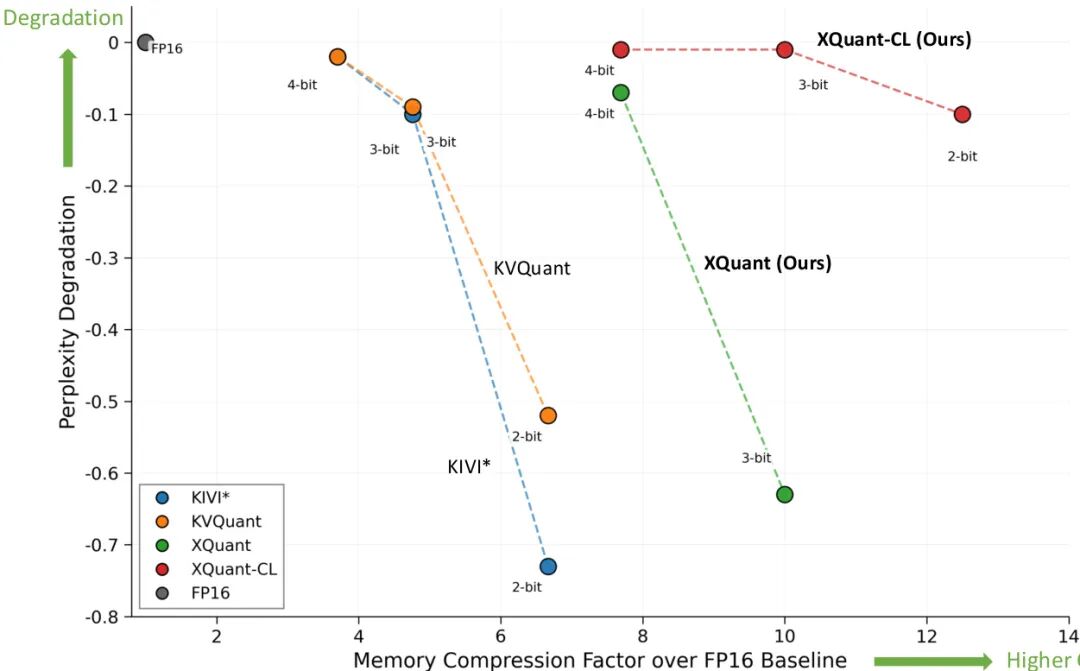
论文简介:
由 UC Berkeley、FuriosaAI 等机构提出了 XQuant,该工作通过量化输入激活 并在推理时动态重建 KV 缓存,实现大语言模型推理内存消耗的显著降低,同时保持接近 FP16 的精度。核心贡献包括:1) XQuant 通过量化 替代传统 KV 缓存量化,实现 2 倍内存节省,结合标准均匀量化在 7.7 倍内存压缩下困惑度下降 <0.1;2) XQuant-CL 利用跨层 的相似性,通过量化层间差值实现极端压缩,在 2-bit 量化下实现 12.5 倍内存节省且困惑度仅下降 0.1,3-bit 下 10 倍节省且困惑度下降 0.01;3) 针对群组查询注意力模型提出 SVD 分解投影方案,在保持相同内存占用下提升量化精度;4) 系统级分析表明该方法在计算与内存带宽比例持续扩大的硬件趋势下具有前瞻性优势。实验显示 XQuant-CL 在 Llama-2-7B 上超越 KVQuant 等复杂非均匀量化方法,以更少内存消耗实现更低困惑度,为内存受限场景下的大模型推理提供高效解决方案。
#################
论文标题:XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization 论文摘要:大语言模型(LLM)推理面临内存墙挑战,其计算能力增长持续快于内存容量与带宽。本文提出 XQuant,通过量化输入激活 替代传统 KV 缓存量化,实现 2 倍内存节省,并在推理时动态重建 KV 缓存。该方法利用 的跨层相似性,通过量化层间差值(XQuant-CL)进一步实现极端压缩。在 Llama-2-7B 上,XQuant-CL 在 2-bit 量化下实现 12.5 倍内存节省且困惑度仅下降 0.1,3-bit 下 10 倍节省且困惑度下降 0.01。针对群组查询注意力模型,提出 SVD 分解投影方案,在保持相同内存占用下提升量化精度。系统分析表明该方法在计算与内存带宽比例持续扩大的硬件趋势下具有前瞻性优势,为内存受限场景下的大模型推理提供高效解决方案。
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.10395
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10395
(76) MolmoAct: Action Reasoning Models that can Reason in Space

论文简介:
由Allen Institute for AI和University of Washington等机构提出了MolmoAct,该工作提出了一种新型视觉-语言-动作推理模型,通过结构化三阶段推理框架(深度感知、空间规划、动作预测)实现可解释的机器人操作。核心贡献包括:1)首创动作推理模型(ARM)架构,将深度感知令牌、视觉推理轨迹与动作预测结合,实现空间感知的决策链;2)在SimplerEnv和LIBERO等基准测试中超越π₀、GR00T N1等闭源模型,零样本下取得70.5%准确率,长时任务提升6.3%;3)提出可编辑的视觉推理轨迹实现动作引导,较语言指令提升33%成功率;4)发布包含10,689条高质量轨迹的MolmoAct数据集,mid-training使性能平均提升5.5%;5)全面开源模型权重、代码及数据集,为构建具身智能体提供开放基准。该模型在单臂/双臂真实场景任务进度分别领先π₀-FAST 10%和22.7%,并实现23.3%的分布外泛化提升,推动机器人操作向可解释、可引导的通用智能体发展。
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.07917
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07917
(77) UI-Venus Technical Report: Building High-performance UI Agents with RFT

论文简介:
由蚂蚁集团提出了UI-Venus,该工作基于Qwen2.5-VL模型通过强化微调(RFT)构建了高性能UI代理,包含7B和72B参数规模的UI-Venus-Ground和UI-Venus-Navi模型。核心贡献包括:1)针对UI定位任务设计点框命中和格式奖励函数,在ScreenSpot-V2/Pro等基准上取得95.3%/61.9%的SOTA成绩;2)提出自演进轨迹历史对齐和稀疏动作增强框架,通过动态调整推理历史与模型决策模式匹配,并强化低频关键动作学习,使72B模型在AndroidWorld导航任务成功率达65.9%;3)构建三阶段数据清洗流程,从107k/350k高质量样本中学习定位和导航能力,有效解决开源数据噪声问题;4)开源模型权重与评估代码,推动UI代理领域发展。实验表明该模型在多语言界面理解、专业软件元素定位和复杂导航任务中均显著超越现有方法,验证了RFT范式在UI代理训练中的有效性。
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.10833
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10833
(78) Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization

论文简介:
由快手Klear团队提出了Klear-Reasoner,该工作通过梯度保留剪枝策略优化(GPPO)显著提升了大模型的长推理能力。研究团队系统分析了当前强化学习剪枝机制的两大缺陷:高熵令牌剪枝导致探索信号丢失,以及次优轨迹梯度截断引发的延迟收敛问题。创新性提出的GPPO方法在保留传统剪枝稳定性的基础上,通过将剪枝令牌梯度约束在可控范围内,实现了探索能力与训练稳定性的平衡。在监督微调阶段,研究发现高质量数据源(如OpenThoughts、DeepSeek-R1)的精炼训练效果显著优于多源数据混合,且对困难样本无需进行准确性过滤。实验结果显示,Klear-Reasoner-8B在数学推理(AIME2024 90.5%、AIME2025 83.2%)和代码生成(LiveCodeBench V5 66.0%、V6 58.1%)任务中全面超越同规模模型,其64K推理窗口下的性能甚至超过部分96K模型。研究还验证了软奖励机制对稀疏奖励问题的改善效果,以及测试用例过滤对代码RL训练的优化作用。该工作为构建高效推理模型提供了数据筛选、监督微调和强化学习优化的完整解决方案,证明了高质量数据与创新优化算法的协同价值。
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.07629
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07629
(79) Stand-In: A Lightweight and Plug-and-Play Identity Control for Video Generation

论文简介:
由腾讯微信视觉团队提出了Stand-In,该工作提出了一种轻量级且即插即用的身份控制框架,用于高保真视频生成。研究者通过在预训练视频生成模型中引入条件图像分支,利用受限自注意力与条件位置映射机制实现身份信息注入,仅需训练约1%的额外参数即可在身份保持、视频质量和提示词跟随方面达到SOTA效果。该方法通过预训练VAE将参考图像与视频映射到同一隐空间,避免了传统方法对显式人脸编码器的依赖,同时通过低秩适配(LoRA)和条件位置编码策略,在保持模型轻量化的同时确保身份特征的有效融合。实验表明,该方法在OpenS2V基准测试中面部相似度达0.724,自然度3.922,显著优于现有方法,且在2000对训练数据上快速收敛。其即插即用特性使其可无缝扩展至姿势引导生成、视频风格化、换脸等任务,通过与VACE框架集成更可提升姿态引导生成的面部一致性。该框架的高效性(推理速度仅下降2.3%)与泛化能力(支持卡通/物体等非人类主体)为个性化视频生成提供了灵活解决方案。
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.07901
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07901
(80) When Punctuation Matters: A Large-Scale Comparison of Prompt Robustness Methods for LLMs

论文简介:
由AIRI、Skoltech等机构提出了Prompt鲁棒性方法系统性评估框架,该工作针对大语言模型对提示格式敏感的问题,首次在统一实验框架下对比了5种主流鲁棒性增强方法(包括Batch Calibration、Template Ensembles、Sensitivity-Aware Decoding、LoRA格式增强和LoRA一致性损失),覆盖Llama、Qwen、Gemma家族8个模型在52个Natural Instructions任务上的表现。研究发现:在无分布偏移场景下,Batch Calibration通过校准类别概率显著降低格式敏感性(在6/8模型上取得最优效果),但对类别不平衡场景表现脆弱;Template Ensembles虽能降低预测方差,但可能因劣质模板导致准确率下降;LoRA微调虽提升准确率却难以改善格式鲁棒性。针对前沿模型测试显示,GPT-4.1和DeepSeek V3虽整体鲁棒性较强,但部分任务仍存在8-10个百分点的准确率波动,通过引入多数投票的Template Ensembles可将方差降低44%以上。该研究为实际应用中选择鲁棒性优化方案提供了关键洞见,揭示了模型规模与鲁棒性的正相关性,并强调了统一评估框架对方法比较的重要性。
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.11383
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11383
(81) Tinker: Diffusion's Gift to 3D--Multi-View Consistent Editing From Sparse Inputs without Per-Scene Optimization

论文简介:
由浙江大学等机构提出了Tinker,该工作提出了一种无需逐场景优化的通用3D编辑框架,通过复用预训练扩散模型的3D感知能力,实现了基于稀疏输入的多视角一致编辑。Tinker的核心创新在于构建了首个大规模多视角编辑数据集和数据管道,并开发了两个关键组件:参考多视角编辑器通过LoRA微调使模型能够跨视角传播编辑意图,任意视角到视频合成器则利用视频扩散模型的空间时间先验,在深度条件约束下完成高质量场景补全。实验表明,Tinker在单样本和少样本场景下均优于现有方法,在Mip-NeRF-360和IN2N数据集上实现了0.959的DINO相似度和6.338的美学评分,同时将编辑时间缩短至15分钟。该方法不仅支持物体级和场景级编辑,还能通过深度引导的视频重建实现高效视频压缩,并通过测试时优化迭代提升生成质量。Tinker通过消除逐场景微调需求,显著降低了3D内容创作的技术门槛,为零样本3D编辑提供了可扩展的解决方案。
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2508.14811
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.14811
(82) CharacterShot: Controllable and Consistent 4D Character Animation

论文简介:
由同济大学、上海人工智能实验室等机构提出了CharacterShot,该工作构建了一个可控且一致的4D角色动画框架,能够从单个参考图像和2D姿态序列生成动态3D角色。研究者首先基于DiT架构的图像到视频模型CogVideoX进行预训练,通过引入姿态条件实现对角色运动的精确控制;接着提出双注意力模块并结合相机先验,在生成多视角视频时同步建模时空与视点间的一致性;最终通过邻域约束的4D高斯溅射优化,将多视角视频转化为连续稳定的4D角色表示。为解决角色动画数据匮乏问题,团队构建了包含13,115个高保真角色的Character4D数据集,并搭建了首个4D角色动画基准CharacterBench。实验表明,CharacterShot在多视角视频生成和4D优化任务中均显著优于现有方法,在SSIM、FVD等指标上取得最优结果,同时用户研究显示其对跨域角色具有优异泛化能力。该方法将传统数周的CGI流程压缩至分钟级,为个体创作者提供了低成本的动态角色生成方案。
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2508.07409
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.07409
(83) CellForge: Agentic Design of Virtual Cell Models

论文简介:
由耶鲁大学、宾夕法尼亚大学、Helmholtz Zentrum Munchen等机构提出的CellForge,是一种基于多智能体框架的虚拟细胞建模系统。该工作通过自动化设计优化计算模型,解决了生物系统复杂性、数据异质性和跨学科专业知识需求等挑战。CellForge采用任务分析、方法设计和实验执行三大模块协同工作:任务分析模块通过数据解析和文献检索生成分析报告;方法设计模块由数据专家、单细胞专家等角色代理组成图结构讨论网络,通过多轮批评-refinement机制达成共识性模型架构;实验执行模块则生成可执行代码并自动调试训练。该系统在六种不同扰动类型(基因敲除、药物处理、细胞因子刺激)和多模态数据(scRNA-seq、scATAC-seq、CITE-seq)上验证,相比现有方法(如ChemCPA、scGen等)实现显著性能提升,其中药物扰动预测任务Pearson相关系数提高20%,稀疏高维scATAC-seq数据的差异表达基因预测相关性提升约16倍。其创新性在于通过代理间知识融合与迭代优化,突破了传统预训练模型在新扰动场景下的泛化瓶颈,展示了多智能体协作在生物计算领域的独特优势。代码已开源供社区使用。
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2508.02276
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02276
(84) Complex Logical Instruction Generation

论文简介:
由德克萨斯大学达拉斯分校与Zoom视频通讯公司等机构提出了LogicIFGen框架,该工作构建了首个系统化生成复杂逻辑指令的自动化工具,并推出了包含426个验证性任务的LogicIFEval基准测试集。研究发现当前主流大语言模型在遵循复杂逻辑指令方面存在显著缺陷,GPT-4o等模型的准确率仅20.66%,而表现最佳的GPT-5也仅达到84.98%。
LogicIFGen通过匿名化代码函数、注入状态追踪器、多轮难度进化等模块,将编程竞赛中的复杂模拟问题转化为自然语言指令。生成的指令要求模型仅依赖文本描述复现代码逻辑,同时输出结果与状态变量需与代码执行结果完全匹配。研究团队从CodeForces和POJ平台筛选出1107个模拟问题,经两阶段过滤后保留426个高难度函数,结合o4-mini模型生成的指令通过专家验证率达97%。
实验表明模型性能随逻辑复杂度提升显著下降:GPT-5在简单任务中表现良好(90.85%),但在困难任务中准确率降至74.1%。值得注意的是,具备推理能力的模型(如Claude-4-Sonnet)表现优于同类非推理模型(43.9% vs 69.72%),但小型模型(如Qwen3-32B)的推理模式未见提升。错误分析显示,控制流错误(如循环次数错误)、指令误解(如条件判断错误)和状态追踪错误(如变量更新遗漏)是主要失败原因,其中控制流错误占比最高(如Gemma-3-27B达53.5%)。
该研究揭示了当前大模型在逻辑指令遵循能力上的根本性缺陷,为开发具备可靠指令执行能力的智能系统提供了基准测试工具和改进方向。研究者建议未来工作可探索将LogicIFGen用于模型训练,并强化多步推理过程中的状态追踪能力。
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2508.09125
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09125
(85) RecGPT Technical Report

论文简介:
由RecGPT团队提出了RecGPT,该工作通过将大语言模型(LLM)深度集成到推荐系统核心流程,构建了以用户意图为中心的下一代推荐框架。针对传统推荐系统依赖历史行为数据导致的过滤气泡、长尾效应等问题,RecGPT创新性地利用LLM的推理与生成能力,在淘宝APP"猜你喜欢"场景中实现了用户兴趣挖掘、物品标签预测和个性化解释生成的全链路优化。其核心贡献包括:1)首次在工业级推荐系统中部署百亿参数推理增强型推荐模型,通过多阶段训练框架(包含推理增强预对齐和自训练演化)实现LLM与推荐任务的深度适配;2)提出用户-物品-标签三塔检索架构,将LLM生成的语义标签与协同过滤信号融合,提升推荐多样性与长尾覆盖;3)构建人机协同评估系统,通过LLM-as-a-Judge与人工监督的结合,实现高效可靠的模型迭代。在线实验表明,RecGPT在用户侧显著提升点击品类多样性(CICD+6.96%)和停留时长(DT+4.82%),在平台侧实现点击率(CTR+6.33%)、商品详情页访问量(IPV+9.47%)和日点击用户数(DCAU+3.72%)的全面增长。该框架通过缓解马太效应、增强推荐透明性,构建了用户、商家与平台三方共赢的生态系统,验证了大语言模型驱动意图中心化推荐的可行性与商业价值。
Hugging Face 投票数:37
论文链接:
https://hf.co/papers/2507.22879
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.22879
(86) VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space

论文简介:
由北京航空航天大学、中国人民大学、清华大学和腾讯混元项目组提出了VoxHammer,该工作提出了一种无需训练的3D本地编辑框架,通过在原生3D空间中进行精确且连贯的编辑来实现高质量3D资产修改。该方法基于预训练的结构化3D潜在扩散模型,采用两阶段策略:首先通过精确的3D反转预测将输入3D模型映射到噪声空间并缓存潜码与键值对特征,随后在去噪编辑阶段通过替换未编辑区域的潜码和注意力键值对,实现几何结构与纹理细节的高保真保持。为解决现有数据集缺乏编辑区域标注的问题,研究团队构建了包含数百个样本的Edit3D-Bench基准数据集,通过定量实验和用户研究验证了VoxHammer在未编辑区域一致性(Chamfer距离降低40%以上)、整体质量(FID下降50%)和条件对齐度(CLIP-T提升10%)等方面均显著优于现有方法。该方法无需额外训练即可实现对网格、NeRF和高斯溅射等3D表示的局部编辑,在游戏开发和机器人交互等领域具有重要应用价值,同时为生成式3D建模的上下文学习奠定了数据基础。
Hugging Face 投票数:37
论文链接:
https://hf.co/papers/2508.19247
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19247
(87) OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation

论文简介:
由字节跳动智能创作实验室等机构提出了OmniHuman-1.5,该工作通过认知模拟为虚拟角色注入主动思维,构建了首个同时模拟人类"系统1"(快速反应)和"系统2"(深度推理)的认知框架。核心贡献体现在两个关键技术:1)利用多模态大语言模型生成结构化文本条件,通过链式推理提供语义级动作指导,突破传统方法仅依赖音频节奏的局限;2)创新多模态Diffusion Transformer架构,采用伪最后一帧策略解决身份图像与动态内容的模态冲突,实现音频、文本、视频三模态的深度融合。实验表明该方法在唇同步准确率、视频质量、动作自然度等指标上全面领先,并展现出卓越的语义一致性。特别在复杂多场景测试中,模型成功生成符合逻辑的多角色互动和非人类角色动作,验证了框架的泛化能力。这项研究开创性地将认知科学理论引入虚拟人生成领域,为构建具有真实行为逻辑的数字角色提供了全新范式。
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2508.19209
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19209
(88) Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models

论文简介:
由浙江大学、蚂蚁集团、浙江工业大学和斯坦福大学等机构提出了利用扩散语言模型时间动态性的新方法,该工作揭示了扩散语言模型(dLLMs)在迭代去噪过程中存在的“时间振荡”现象——正确答案常在中间步骤出现却被后续步骤覆盖。针对这一问题,研究者提出两种互补策略:1)时间自一致性投票(Temporal Self-Consistency Voting),一种无需训练的测试时解码策略,通过聚合各去噪步骤的预测结果提升准确性;2)时间一致性强化(Temporal Consistency Reinforcement),一种后训练方法,利用时间语义熵(TSE)作为奖励信号鼓励生成稳定性。实验显示,仅使用负TSE奖励在Countdown数据集上使现有dLLM平均提升24.7%,结合准确率奖励后在GSM8K、MATH500、SVAMP和Countdown数据集分别实现2.0%、4.3%、6.6%和25.3%的绝对增益。研究通过量化时间一致性,为dLLM解码提供了新视角,并展示了利用时间动态性的有效工具。
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2508.09138
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09138
(89) BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent

论文简介:
由 Zijian Chen 等机构提出了 BrowseComp-Plus,该工作针对现有深度研究代理评估基准(如 BrowseComp)依赖动态网络API导致的公平性、透明度和可访问性问题,构建了一个固定且人工验证的语料库,为深度研究代理的组件化评估提供了新基准。BrowseComp-Plus 通过两阶段管道收集证据文档:首先利用 OpenAI o3 模型生成候选URL并经人工验证筛选,最终保留830个有效查询,每个查询平均包含6.1篇证据文档、76.28个硬负样本和2.9篇金文档。实验显示,闭源模型(如 GPT-5)与 Qwen3-Embedding-8B 结合时准确率达70.12%,显著优于开源模型(如 Qwen3-32B 的10.36%)。研究揭示了检索质量对深度研究系统效能的关键影响:更强的检索器(如 Qwen3-Embedding-8B)不仅提升准确率(如 GPT-5 从55.9%升至70.12%),还减少搜索次数(如平均调用次数下降1.5次)。通过全文档阅读工具实验,发现闭源模型能更有效利用完整文档信息(如 GPT-4.1 准确率提升8.19%),而开源模型受限于工具调用能力。该基准的发布为研究检索-代理协同优化、跨工具泛化能力及上下文工程提供了可控实验平台,其固定语料库(10万文档)和人工标注机制有效解决了传统基准的动态性缺陷,为深度研究系统的可重复性研究奠定了基础。
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2508.06600
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06600
(90) Beyond the Trade-off: Self-Supervised Reinforcement Learning for Reasoning Models' Instruction Following

论文简介:
由复旦大学、蚂蚁集团等机构提出了Beyond the Trade-off: Self-Supervised Reinforcement Learning for Reasoning Models’ Instruction Following,该工作针对推理模型在复杂问题解决中推理能力与指令遵循能力间的权衡问题,提出了一种无需外部监督的自监督强化学习框架。现有方法依赖更强的外部模型进行指令遵循能力提升,存在方法瓶颈和实际限制,而该研究通过利用推理模型自身的内部信号,构建了基于课程分解的约束逐步递增训练数据,并设计了结合规则验证与软约束二分类的高效奖励建模方法。实验表明,该框架在保持推理性能的同时显著提升了指令遵循能力,在多约束指令基准测试中表现优异,且方法具有跨模型架构和规模的普适性。研究通过消融实验证明了课程分解和混合奖励机制的有效性,并在开源数据和代码支持下展示了方法的可复现性,为提升推理模型的实际应用能力提供了新范式。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.02150
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02150
(91) Enhancing Vision-Language Model Training with Reinforcement Learning in Synthetic Worlds for Real-World Success

论文简介:
由 T-Tech 等机构提出了 Vision-Language Decoupled Actor-Critic (VL-DAC),该工作提出一种轻量级无超参数强化学习算法,通过将策略损失与值函数损失解耦,实现视觉语言模型在合成环境中的高效训练并有效迁移到真实任务。VL-DAC 在 token 级别应用 PPO 更新策略网络,同时在环境步骤级别学习值函数,通过停止梯度回传避免交叉信号干扰,显著提升训练稳定性。该方法在 MiniWorld、ALFWorld 等低成本模拟器中训练单一模型,即可在 BALROG(+50%)、VSI-Bench(+5%)和 VisualWebBench(+2%)等真实场景基准测试中取得显著提升,且不损害通用图像理解能力。实验表明,VL-DAC 比 RL4VLM 更稳定,比 LOOP 更适合长时序任务,其 token/step 分离设计消除了传统方法对超参数调优、重放缓冲区或密集奖励的依赖。研究证实通过多样化模拟器训练和算法简化,可实现从合成环境到真实任务(包括具身控制、空间规划和网页导航)的有效技能迁移,为视觉语言模型的强化学习训练提供了可扩展的实用方案。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.04280
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04280
(92) VertexRegen: Mesh Generation with Continuous Level of Detail

论文简介:
由 UC San Diego 和 Meta Reality Labs Research 提出了 VertexRegen,该工作提出了一种基于连续细节层次的网格生成框架。传统自回归方法以部分到完整的方式生成网格,中间步骤产生不完整结构,而 VertexRegen 受渐进式网格启发,将生成过程重构为边坍缩操作的逆过程——顶点分裂,并通过生成模型学习这一过程。实验表明,VertexRegen 在保持与当前最佳方法相当质量的同时,独特地支持任意阶段中断生成,输出具有不同细节层次的有效网格。
核心创新在于:1)将网格生成转化为边坍缩逆过程的生成问题,实现从粗糙到精细的渐进式生成;2)基于半边数据结构设计高效的渐进式网格参数化方法,通过顶点分裂序列实现网格细化;3)提出支持连续细节控制的生成框架,每个生成步骤对应网格细节的增量提升。方法采用 Transformer 架构建模顶点分裂序列,通过预测目标顶点及其邻接关系实现网格细化,并在解码时结合几何约束确保有效性。
实验部分验证了方法在无条件生成和条件生成任务中的有效性。在 Objaverse-XL 数据集上,VertexRegen 的 COV、MMD、1-NNA 等指标与 MeshXL、MeshAnything 等方法相当,同时在 face count 约束条件下展现出显著优势。条件生成实验中,模型能从简单基元(如四面体)开始,逐步生成与输入点云匹配的复杂几何结构。消融实验证明,基于半边结构的参数化使 token 序列压缩率达到 0.73,guided decoding 机制有效提升生成序列长度和网格质量。该方法为 3D 内容生成提供了灵活的细节控制能力,为实时渲染、多尺度建模等应用开辟了新途径。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.09062
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09062
(93) MV-RAG: Retrieval Augmented Multiview Diffusion

论文简介:
由希伯来大学等机构提出了MV-RAG,该工作提出了一种检索增强的多视图扩散框架,通过结合结构化多视图数据和大规模2D图像集合的混合训练策略,有效提升了模型在处理罕见或新兴对象时的生成质量。针对现有文本到3D生成方法在分布外(OOD)场景下几何不一致和语义偏差的问题,MV-RAG创新性地引入了动态检索增强机制:在推理阶段,首先通过BM25从LAION-400M等数据集中检索与文本相关的2D图像,利用ViT编码器提取局部特征并通过可学习的Resampler模块生成条件令牌;在生成阶段,通过解耦的交叉注意力机制将文本语义与检索图像的视觉特征进行自适应融合,并设计了Prior-Guided Attention机制根据OOD程度动态调整基模型与检索信号的权重分配。训练策略上,该方法采用3D模式与2D模式交替训练:3D模式通过渲染Objaverse数据集对象并施加几何/语义增强来模拟真实检索差异,要求模型从增强视图重建原始视角;2D模式则使用ImageNet-21K数据,通过预测被遮掩视图的新型训练目标,使模型从无结构2D图像中学习3D一致性。实验方面,研究团队构建了包含196个OOD概念的评估基准OOD-Eval,对比MVDream、MV-Adapter等SOTA方法,在CLIP、DINO等图像相似度指标上分别提升5.3%和12.1%,同时保持了在Objaverse-XL等标准数据集上的竞争力。该工作不仅通过检索增强突破了传统扩散模型的语义局限,更通过混合训练范式弥合了结构化3D数据与非结构化2D图像之间的鸿沟,为文本到多视图生成开辟了新路径。
Hugging Face 投票数:34
论文链接:
https://hf.co/papers/2508.16577
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16577
(94) Llama-3.1-FoundationAI-SecurityLLM-8B-Instruct Technical Report

论文简介:
由 Foundation AI、Cisco Systems Inc.、Yale University 和 Carnegie Mellon University 等机构提出了 Llama-3.1-FoundationAI-SecurityLLM-8B-Instruct,该工作针对网络安全领域数据稀缺、表征复杂及安全合规挑战,基于 Foundation-Sec-8B 基础模型进一步开发了具备指令遵循和对话能力的网络安全专用语言模型。该模型通过结合领域知识与人类偏好对齐技术,在保持通用指令遵循能力的同时,显著提升了在网络安全任务中的表现,尤其在 CTIBench-RCM 基准上超越了 Llama 3.1-70B-Instruct 和 GPT-4o-mini,并在 AlpacaEval 2 等通用指令遵循评估中领先其他网络安全模型。研究团队通过分析开源数据集中的网络安全内容分布,发现现有数据集存在应用安全领域过度覆盖而云安全等领域不足的问题,并采用分层污染检测框架评估了训练数据与基准测试的重叠风险。实验表明,Foundation-Sec-8B-Instruct 在保持网络安全知识完整性的同时,能有效适配 SOC 分析师、红队人员等多角色对话场景,且通过 LlamaGuard 集成可将恶意请求拒绝率提升至 99%。该模型作为首个专为网络安全对话优化的 8B 参数级模型,已在 HuggingFace 平台开源,为从业者提供零样本解决威胁情报分析、漏洞管理等任务的能力,同时通过系统提示词设计确保了安全性和专业性。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.01059
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01059
(95) A Survey on Diffusion Language Models

论文简介:
由Tianyi Li等学者提出了《A Survey on Diffusion Language Models》,该工作系统性地梳理了扩散语言模型(DLMs)的技术脉络、核心优势及未来挑战。研究指出,DLMs通过并行迭代去噪过程实现高效文本生成,在保持与自回归模型(AR)相当性能的同时,显著提升推理速度并支持双向上下文建模。论文从技术范式、训练策略、推理优化、多模态扩展等维度展开深度分析,揭示了DLMs在代码生成、科学计算及跨模态任务中的潜力。
DLMs主要分为连续空间和离散空间两大技术路线。连续DLMs(如Diffusion-LM)通过嵌入空间扩散建模,结合ODE/SDE求解器加速生成;离散DLMs(如LLaDA)直接在token空间定义扩散过程,采用掩码预测策略实现并行解码。研究发现,离散DLMs在数学推理任务中表现突出,例如LLaDA在GSM8K基准上超越同规模AR模型。
训练策略方面,DLMs常基于AR模型权重初始化以提升效率,并通过监督微调(SFT)和强化学习(如diffu-GRPO、UniGRPO)增强推理能力。推理优化技术包括并行解码、动态掩码策略(如Fast-dLLM)、无分类器引导(CFG)及缓存机制(如dKV-Cache),可实现最高34倍加速。多模态扩展方面,LLaDA-V、MMaDA等模型通过统一的扩散框架实现图文联合建模,在视觉问答和图像生成任务中表现优异。
挑战与未来方向聚焦于并行性与质量的权衡、长序列建模、可扩展性及基础设施支持。研究指出,DLMs在动态长度生成中存在计算复杂度高(O(N³))问题,且当前最大模型参数量(8B)仍落后于AR模型。未来需探索低比特量化、剪枝蒸馏等压缩技术,并推动DLM原生部署框架开发。该综述为理解扩散语言模型的技术演进提供了全面视角,为后续研究指明了方向。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.10875
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10875
(96) CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning

论文简介:
由上海交通大学、上海人工智能实验室等机构提出了CODA,该工作受人脑“大脑-小脑”分工机制启发,构建了可协同的双脑计算机使用代理架构。核心创新在于提出解耦强化学习框架,采用Qwen2.5-VL作为规划器(大脑)和UI-Tars-1.5作为执行器(小脑)的协作模式。通过两阶段训练策略:第一阶段使用解耦的GRPO算法对每个科学应用进行专项强化学习,利用自动奖励系统和分布式虚拟机系统加速轨迹收集;第二阶段通过监督微调将多个专家模型整合为通用规划器。在ScienceBoard基准测试的四个科学计算应用中,CODA显著超越基线模型,达到开源模型新SOTA。该方法通过固定执行器保障动作稳定性,同时让规划器专注领域知识学习,在减少数据依赖的同时提升跨域泛化能力,为复杂GUI任务的长程规划与精准执行提供了新范式。代码和模型已开源。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.20096
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20096
(97) Pixie: Fast and Generalizable Supervised Learning of 3D Physics from Pixels

论文简介:
由宾夕法尼亚大学和MIT等机构提出了Pixie,该工作提出了一种从视觉特征中快速预测3D场景物理属性的监督学习框架。Pixie通过训练神经网络直接从3D视觉特征预测离散材质类型(如橡胶)和连续物理参数(如杨氏模量、泊松比、密度),结合高斯泼溅模型和物质点法(MPM)求解器实现逼真的物理模拟。研究团队构建了包含1624个3D资产和物理标注的PixieVerse数据集,采用CLIP视觉特征蒸馏和3D U-Net网络实现每场景2秒内的快速推断,相比传统优化方法速度提升3个数量级,且在视觉语言模型评估中实现1.46-4.39倍的现实感提升。该方法通过预训练视觉特征实现从合成数据到真实场景的零样本迁移,成功预测真实物体的物理属性并生成符合物理规律的动画效果,为虚拟世界构建和机器人仿真提供了高效解决方案。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.17437
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17437
(98) Waver: Wave Your Way to Lifelike Video Generation

论文简介:
由字节跳动团队提出了Waver,该工作提出了一种高性能统一图像与视频生成模型,通过Hybrid Stream DiT架构实现文本/图像到视频的多任务融合生成,支持5-10秒原生720p视频生成并可上采样至1080p。核心贡献包括:1)创新Hybrid Stream DiT架构,通过双流/单流混合设计优化模态对齐与参数效率;2)构建全流程数据处理体系,包含多阶段过滤、质量标注模型和语义平衡策略,处理超2亿视频片段;3)开发级联上采样器,采用窗口注意力和像素/潜在空间降质策略实现40%推理加速;4)提出运动幅度优化、美学增强、模型平衡等训练策略,在Artificial Analysis排行榜T2V和I2V任务均位列前三,尤其在复杂运动场景中相较竞品提升显著。该工作通过详尽的技术细节开源和多维度优化策略,为视频生成领域提供了可复现的高性能解决方案。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.15761
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15761
(99) Memp: Exploring Agent Procedural Memory

论文简介:
由浙江大学与阿里巴巴团队提出了Memp框架,该工作探索了如何为大语言模型(LLM)驱动的智能体构建可学习、可更新的程序性记忆系统。研究聚焦于程序性记忆的构建(Build)、检索(Retrieve)和更新(Update)三大核心策略,通过动态机制持续优化记忆库内容,使智能体能够从过往经验中提炼可复用的技能模板。实验在TravelPlanner(长时信息检索)和ALFWorld(家庭任务仿真)两个基准上验证,发现随着记忆库迭代优化,智能体在相似任务中的成功率与执行效率显著提升。具体而言,构建阶段通过轨迹存储(Trajectory)与脚本抽象(Script)的混合策略实现细粒度步骤指令与高层逻辑的双重编码;检索阶段采用查询向量匹配(Key=Query)与关键词平均相似度(Key=AveFact)策略,前者捕捉语义关联性,后者聚焦任务核心要素,两者均较随机采样提升15%以上任务完成率;更新机制中基于反思的修正策略(Adjustment)在连续任务组测试中较次优方案多获得0.7分奖励且减少14步执行。研究还发现程序性记忆具有跨模型迁移能力,将GPT-4o生成的记忆库迁移到参数量小5倍的Qwen2.5-14B模型后,后者的任务完成率提升5%并减少1.6步执行。该工作通过系统性对比实验揭示:程序性记忆的规模扩展与检索精度提升能持续增强智能体性能,但过度检索可能导致干扰;动态更新机制是实现持续学习的关键,其中错误修正策略显著优于单纯记忆累加。研究为构建具备经验积累能力的自优化智能体提供了可扩展的框架参考。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.06433
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06433
(100) CompassVerifier: A Unified and Robust Verifier for LLMs Evaluation and Outcome Reward

论文简介:
由上海人工智能实验室、澳门大学等机构提出了CompassVerifier,该工作开发了一个统一且鲁棒的验证模型,用于大语言模型(LLM)的评估和结果奖励。研究指出当前答案验证方法存在两大局限:缺乏系统性评估基准以及验证器开发的不成熟。为此,团队构建了VerifierBench基准测试,通过多阶段验证(包括多模型共识判断、工具辅助清洗和人工校准)收集了130万条数据样本,覆盖数学、知识、科学和推理四大领域,并标注了30余种元错误模式。同时提出CompassVerifier系列轻量级验证模型,采用错误驱动对抗增强、复杂公式增强和通用性增强三大技术,显著提升多领域验证能力。实验表明,CompassVerifier-32B在VerifierBench上实现84.1%-95.1%的准确率和80.8%-94.8%的F1值,超越GPT-4o等大模型及专用验证器。特别在数学验证领域,其3B参数模型的F1值比同规模基线模型提升41.3%。作为奖励模型应用于强化学习时,CompassVerifier使训练模型在AIME24等基准上达到21.2%的性能提升,验证了其作为可靠反馈信号的有效性。该工作为答案验证、评估协议优化和强化学习研究提供了重要基础设施。
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2508.03686
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03686