作者:马修·哈里斯
日期:2025年8月30日
事实已经证明,关键不在于船的尺寸,而在于驾驭风浪的本领。这绝非自我安慰。
过去三年,人工智能领域的话语权,一直被庞大的参数量、耗资数亿的算力训练,以及那些大到不切实际的中心化模型所垄断。
值得庆幸的是,那些关于人工智能一夜崛起、无限自我迭代甚至带来末日的夸张说法,最终都被证实只是捕风捉影的猜测。
世界并未走向由一个“上帝模型”主宰一切的未来。相反,小语言模型异军突起,它们不是大语言模型的廉价替代品,而是支撑起本地化人工智能的核心骨架。

参数量通常在百亿以下的小语言模型,如今在特定任务上的表现,已经能达到大语言模型八到九成的水准。
更关键的是,在那些对延迟、隐私和能耗要求极高的场景里,小语言模型的经济效益和实用价值无可比拟。
这是一个最理想的局面:大语言模型继续探索技术的最前沿,而深入各个垂直行业的应用,将基于这些小巧、高效的小语言模型来构建。
随着大语言模型的发展速度从爆发式增长转为平稳迭代,一种全新的模型架构很可能也即将诞生。
设备端的变革
正在发生什么?
小语言模型的体积正被压缩到几百兆到几G之间,使其能轻松运行在手机、可穿戴设备和智能眼镜上。
它们已经可以直接在消费设备上处理翻译、摘要、代码辅助和视觉语言交互等任务。
从高通的增强现实芯片到阿里巴巴的AI眼镜,硬件厂商正将它们深度集成,以实现脱离云端的实时处理能力。
这意味着什么?
这一变化将我们身边的日常设备,转变成了功能强大的本地AI处理器,极大地降低了延迟,并保护了用户隐私。
它让智能推理不再是顶级硬件的专属,普通消费设备也能拥有强大的AI能力,从而让更多人受益。
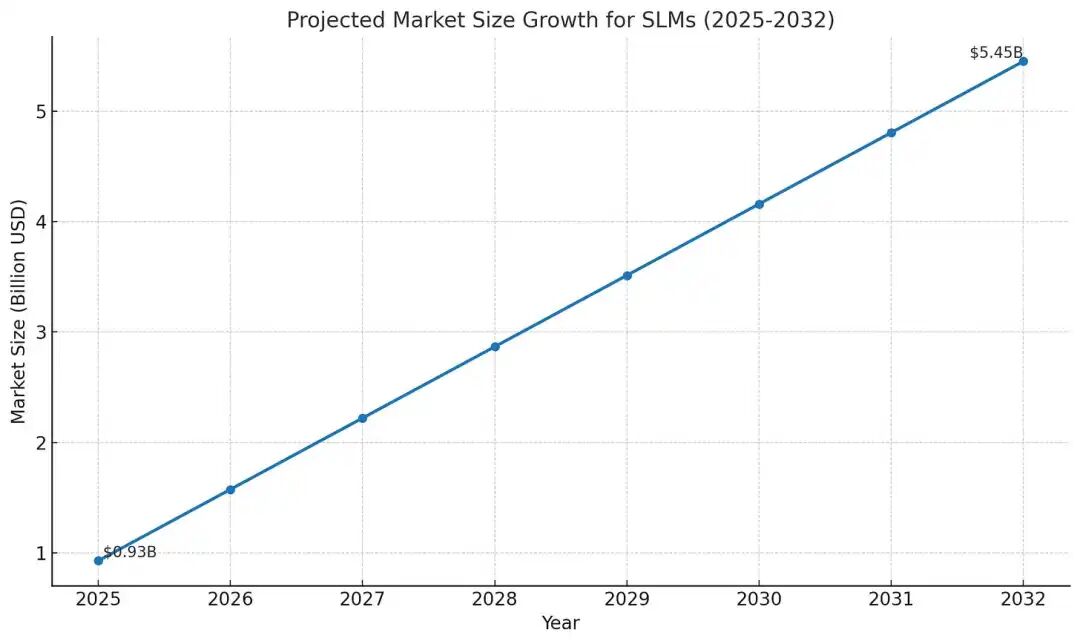
随着小语言模型市场规模预计在2032年前增长近六倍,运行效率和边缘集成能力,将成为决定未来竞争格局的核心。
2025年的新风口:智能体
正在发生什么?
小语言模型正从被动的执行工具,进化为能够自主规划、推理和行动的智能体系统。
英伟达2025年的测试数据显示,在边缘设备上,小语言模型的延迟降低了十倍,功耗也大幅减少。
xLAM-2-8B、Nemotron-H等模型证明,即便参数规模小于五十亿,也足以处理复杂的结构化推理和长达128k的上下文窗口,其成本和速度甚至优于更大的模型。
这意味着什么?
智能化的个人助理正走入生活。可穿戴设备能主动调整你的健身计划,智能眼镜能实时理解你看到的世界。
智能导师能用20%的成本,达到大语言模型80%的教学效果。这里的核心战略,不是挑战像GPT-5那样的顶尖模型。
而是在延迟和效率至关重要的场景下,率先实现足够好的自主智能。这将催生一个全新的消费市场:最终胜出的AI,不是最聪明的,而是最快、最经济、最无缝融入我们日常设备的那个。
算力层的革新
正在发生什么?
高通的骁龙AR1 Plus芯片,已经能在增强现实眼镜上,以45 TOPS的性能实时运行Llama 3.2模型。
英伟达的Jetson系列芯片,让可穿戴设备的功耗降低了90%。苹果的神经网络引擎,则在手表上支撑着Phi-3.5模型进行持续的健康分析。
这些成就,得益于 4bit 量化和稀疏化等技术,它们让低功耗、低发热的推理运算成为现实。
这意味着什么?
未来的技术前沿,不再仅仅是模型算法的设计,更是模型与硬件的协同设计。
专为小语言模型定制的加速芯片,能将单次推理的成本降低五到十倍。竞争优势将向那些能将高效模型与定制芯片完美结合的生态倾斜。
对企业来说,制胜的关键是更贴近底层硬件,而不是盲目堆砌参数。

小而精,专而美
正在发生什么?
小语言模型的架构日趋成熟。像Mistral Small 3、Qwen 2等模型,通过蒸馏和合成数据技术,在很小的规模下就实现了惊人的性能。
仅有256M参数的SmolVLM,已能流畅处理浏览器内的多模态任务。这标志着模型设计的重心,正从追求「大而全」转向「小而专」。
这些模型为特定领域量身定制,效率极高,可以完全在本地消费设备上独立运行。
这意味着什么?
这种趋势意味着,驱动AI进步的真正杠杆,不再是海量的训练数据和算力,而是高效利用数据的能力。
通过专有数据进行微调,医疗、视觉、金融等垂直行业,可以用小模型撬动巨大的商业价值。
未来的赢家,将是那些能用最少的数据和算力,实现最强推理能力,并将其部署到每个用户身边的人。
模块化设计与隐私保护
正在发生什么?
应用层让小语言模型的优势变得触手可及。谷歌的Gemini模型就采用了分层设计,小版本在设备端处理个性化需求,大版本在云端待命处理复杂任务。
可穿戴设备集成了智能教练,眼镜提供实时翻译,这些功能都无需时刻连接云端。
联邦学习技术进一步强化了这种模式,它允许模型在本地数据上训练,只将学习成果进行聚合,既提升了模型能力,又保护了个人隐私。
这意味着什么?
这种边缘优先的模块化方法,让隐私安全成为企业的核心竞争力,高效体验则转化为用户的忠诚度。
如果让小模型在本地处理七到八成的用户请求,只在必要时求助云端,企业的用户留存率能提升两到三成。
未来的竞争,本质上是生态系统的竞争。赢家将能完美平衡好永远在线的本地小模型,与功能强大的云端大模型之间的关系。
融合的机遇与挑战
正在发生什么?
硬件竞赛正在升温。Meta的Ray-Ban眼镜、XREAL的增强现实系统,以及阿里巴巴的夸克AI眼镜,都在将小语言模型作为原生智能直接嵌入设备。
智能手表和扩展现实设备,正在测试由语音和手势驱动的主动式智能助理,但电池续航和佩戴舒适度仍是挑战。
以能效为核心的芯片设计,正在弥合这些差距,让“全天候在线”的智能体验成为可能。
这意味着什么?
明智的战略选择是,在市场格局固化之前,立即着手开发由小语言模型驱动的可穿戴设备,并锁定生态系统合作伙伴。
在企业应用或健康监测等细分领域抢占先机,可以在行业巨头尚未全面发力时,快速积累用户基础。
行动迟缓的企业,将面临入场过晚的风险,届时硬件平台和AI生态早已尘埃落定。

面向未来的战略布局
基于以上洞察,我们的发展路线图十分清晰。
短期:审视现有产品,在当前技术体系中试点小语言模型,用数据评估其带来的效率提升。 中期:投入资源建立专有的小语言模型训练能力,并与硬件厂商进行深度协同设计。 长期:构建一个能让小语言模型在手机、穿戴设备和智能眼镜之间无缝协作的生态系统,抓住未来十年的巨大市场机遇。
终局洞察
小语言模型的崛起,不只是一次技术迭代,它正在从根本上重塑人工智能的开发、部署和商业模式。
它将AI的计算核心,从遥远的云端数据中心,拉回到每个人口袋里的设备中。这彻底改变了AI的经济学。
未来的竞争壁垒,不再是庞大的云端API成本,而是由低延迟、高隐私和极致效率构筑的边缘生态。
这最终会分化出两个截然不同的市场。一方继续用最大的模型追逐技术极限;另一方则专注于将模型与硬件协同设计,用数据提炼出高度专业化的智能体,并构建一个由小模型处理绝大多数请求、大模型作为后援的智能体系。
市场终将奖励那些率先行动的公司。他们将小语言模型融入可穿戴设备和日常硬件,让AI变得无处不在、心有灵犀且毫无摩擦,从而赢得用户的最终信赖。
随着版图不断扩张,决定胜负的关键,在于你是否真正认识到:小语言模型不是被阉割的大模型,它是一个智能与物理世界完全交融的新计算时代的基石。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










