

该论文发表于CVPR 2025,题目为《UNEM: UNrolled Generalized EM for Transductive Few-Shot Learning》。
米兰理工大学的Long Zhou为此文第一作者。
论文链接:
https://openaccess.thecvf.com/content/CVPR2025/html/Zhou_UNEM_UNrolled_Generalized_EM_for_Transductive_Few-Shot_Learning_CVPR_2025_paper.html


论文概要
本文针对当前直推式小样本学习(Transductive Few-Shot Learning)中严重依赖验证集进行网格搜索以确定关键超参数(如类别平衡水平)的现状,提出了一种基于“学习优化”(Learning to Optimize)范式的解决方案。作者将泛化的期望最大化(EM)优化器展开为一个可学习的神经网络架构,通过将每次迭代映射到网络层,从而能够直接从验证数据中高效地学习出一组最优超参数。该方法兼容多种视觉特征分布与预训练模型(包括视觉语言基础模型与纯视觉分类器)。在大量细粒度图像分类任务上的实验表明,所提出的展开式EM算法相比其迭代变体带来了显著性能提升,在纯视觉和视觉-语言基准上的准确率最高分别提升了10%和7.5%。


深度学习显著推动了计算机视觉领域的进步,但在图像分类、目标检测等任务上的成功严重依赖于大量标注数据,且模型在面对预训练未见类别或分布变化时泛化能力受限。为应对这一挑战,小样本学习近年来受到广泛关注。其中,直推式学习方法通过联合推断整个查询集中的样本,利用未标注数据的整体统计特性,性能显著优于独立预测的归纳式方法。然而,现有直推方法通常假设查询集具有完美的类别平衡性,该假设在实际中往往不成立,导致模型在类别不平衡场景中性能显著下降。虽已有研究尝试通过引入超参数(如控制类别平衡水平的参数)以适应更真实的场景,但这些超参数严重依赖于人工网格搜索,其最优值随数据集和预训练模型的不同差异巨大,使得调优过程计算成本高昂。因此,亟需一种能够自动、高效学习这些关键超参数的方法,以推动直推式小样本学习在更广泛场景中的应用。


本研究提出了一种名为的新方法,旨在解决直推式小样本学习中对超参数(特别是控制类别平衡的参数λ和温度参数T)手工调优的依赖问题。其核心思想是将广义期望最大化(GEM)算法展开为一个可学习的神经网络,从而自动、高效地从验证数据中学习最优的超参数配置。其整体框架图如图1所示。该方法主要包含以下几个关键部分:
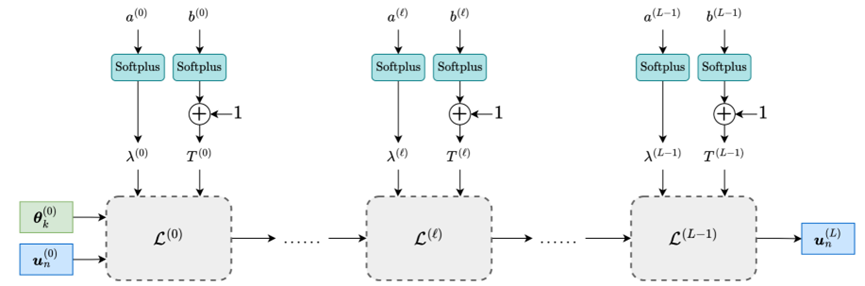 图1 UNEM框架图
图1 UNEM框架图
(1)广义EM算法框架
首先,作者构建了一个统一的概率聚类目标函数。对于一个包含少量标注样本(支持集)和大量未标注样本(查询集)的小样本任务,该模型旨在同时优化两组变量:
软分配向量 (u):表示每个查询样本属于各个类别的概率分布。
特征分布参数 (θ):描述每个类别的特征分布(如高斯分布的均值)。
对于一般的概率聚类问题有:

该目标函数由三部分组成:
对数似然项 :
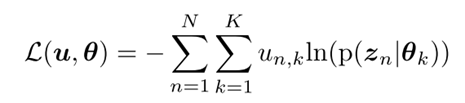
该项鼓励模型更好地拟合数据,倾向于将数据划分为类别平衡的簇。
边际熵项:

引入一个由超参数λ加权的熵正则项,用于抵消上述平衡偏好,从而控制模型对类别平衡或不平衡的倾向性。
熵屏障项:

由一个温度超参数T控制,用于调节软分配的“软硬”程度。
该广义框架是一个数学上的统一,许多现有的直推式方法(如标准EM算法)均可被视为该框架在特定超参数设置下的特例。其结构图如图2所示。

图2 GEM算法结构图
(2) 展开式EM架构
为了解决超参数难以调优的问题,作者采用了 “学习优化”(Learning to Optimize) 的范式,具体策略为:
将GEM算法的每一次迭代映射为神经网络中的一个层。一个完整的、包含L次迭代的优化过程便对应一个L层的神经网络(UNEM)。其迭代规则为:

在每一层中,关键的超参数λ和T不再是固定值,而是作为该层的可学习参数。这使得模型能够根据不同的数据分布,自适应地调整每一层的超参数值,灵活性远超手工调优。为保证λ的非负性,本文将其表示为Softplus函数:
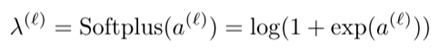
而对于温度参数T,仅仅约束为非负可能会导致梯度消失,因此设置了一个下界确保其值恒不小于1:

(3) 训练方法
整个UNEM网络通过最小化在验证集上的标准交叉熵损失来进行训练:

这使得学习到的超参数能够直接优化模型在未知数据上的分类性能。


为验证所提出UNEM方法的有效性,本文在纯视觉和视觉-语言两种小样本学习设定下进行了广泛的实验,分别命名为UNEM-Gaussian和UNEM-Dirichlet。
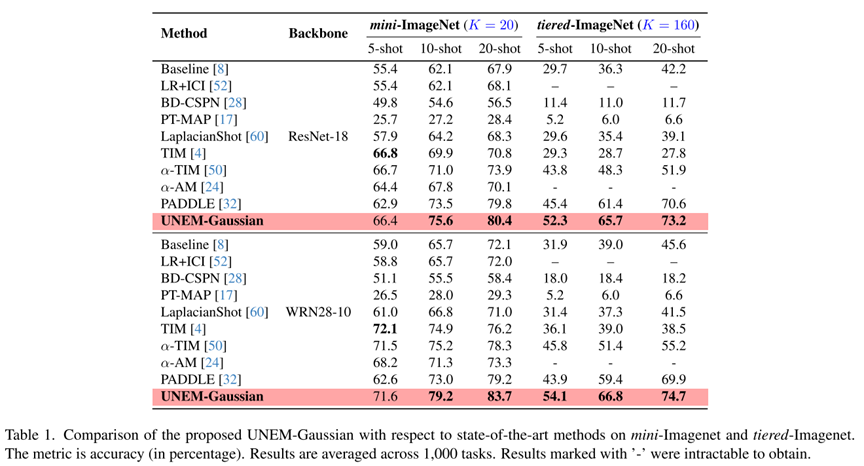
UNEM-Gaussian的实验结果如表1和表2所示:

UNEM-Dirichlet的实验结果如表3所示:
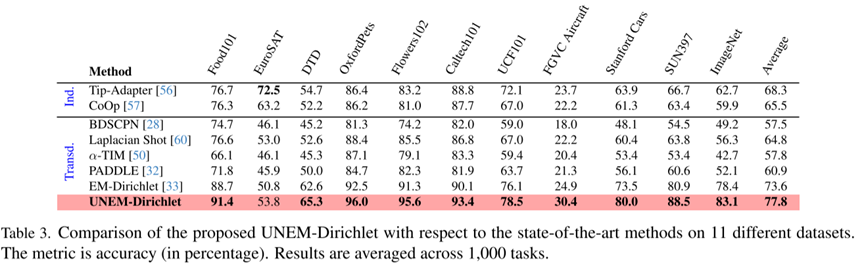
实验表明所提出的展开学习范式在不同模型架构与数据分布上均表现出强大的适应性和有效性,能自动且高效地优化关键超参数,彻底避免了繁琐的手动网格搜索。


结论
本研究将广义EM算法展开为一个可学习的神经网络(UNEM),实现了对直推式小样本学习中关键超参数(如类别平衡与温度系数)的自动优化。实验表明,该方法在纯视觉与视觉-语言模型上均能显著提升性能,为自动化机器学习提供了新思路。
撰稿人:马一鸣
审稿人:李景聪


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci
