

一、前言
对象导航(Object Navigation, ObjectNav)是具身智能(Embodied AI)研究中的一个核心问题。它要求智能体在一个完全未知的环境中,仅凭任务指令(如“找到电视”),自主探索、感知并最终定位目标对象。这一任务极具挑战性,因为它不仅涉及物理空间特征的感知与探索,还要求机器人具备语义理解与常识推理能力。
现有方法大致分为两类:
传统学习范式:依赖强化学习或模仿学习,通过大规模数据集训练策略网络。这类方法虽然在封闭分布内表现良好,但对训练集之外的目标类别或新场景泛化极差。
基于大模型的零样本方法:近期的研究开始利用大型语言模型(LLM)和视觉语言模型(VLM)的常识知识来实现零样本导航,但它们通常只依赖前沿区域附近的对象类别文本作为输入,缺乏对场景结构化上下文的建模,导致推理过程有限且难以解释。

SG-Nav 的提出正是为了解决这一核心瓶颈。其思想是:在导航过程中构建层级化 3D 场景图(对象–组–房间),再通过层级化 Chain-of-Thought 提示调动 VLM 的推理能力,使得 VLM 不再只处理孤立的对象标签,而是能够基于完整的结构化场景上下文进行推理。系统随后利用前沿插值机制将推理结果映射到空间行动层,并通过再感知机制提高鲁棒性。这种设计使得方法在零样本条件下依然能够有效执行导航,并提供可解释的推理路径。
换句话说,SG-Nav 试图用场景图这类显式知识表示,弥补大模型黑箱推理在空间智能上的不足。这一思路不仅在性能上带来提升,更重要的是增强了推理的可解释性。
二、方法设计与模型架构
1. Overview
把大型语言模型(LLM)的强大零样本推理能力用于具身导航(navigation)决策上是近期研究的主流范式。但直接让 LLM 处理此类任务存在两个明显短板——一是 LLM 对场景的视觉信息缺乏直接、精细的理解;二是 LLM 更擅长通用推理而非精确、实时的机器人低层动作预测。因此,要发挥 LLM 的长处并规避其短板,必须对导航任务做精细化建模,将问题转换成适合 LLM 解决的抽象决策形式。

SG-Nav:一个把在线视觉观测结构化为增量式 3D 场景图(scene graph),并以场景图为 prompt 层级化提示驱动 LLM 做高层决策的系统。为了让 LLM 专注于“推理/选择”而不是琐碎的动作细节,作者团队将低层动作预测解耦出来:视觉观测不仅用于构建 3D 场景图,还会被用于生成占用地图(occupancy map)。具体而言,先将深度图转换为世界坐标系下的点云,再投影到 BEV(bird’s-eye view),得到对场景的三元格表示:未探索 / 已探索且可通行 / 已探索且为障碍。
基于该三元表示可以计算出有限数量的边界(frontiers)——即机器人从已探索区域进入未探索区域时必然会经过的边界线。由此我们把巡航的 action 预测拆成两个子任务:
离散边界选择(从候选 frontiers 中选取下一个目标)——交由 LLM 负责,用场景图与语义提示支持其零样本推理;
基于选定边界的低层动作生成(如何沿着局部路径到达该边界)——交给传统的本地策略(Local Policy)模块解决。
这种两层分工让系统既能利用 LLM 强大的语义与策略推理能力,又能依赖确定性强、实时性好的经典控制/规划方法执行具体动作,从而在保持决策泛化性的同时保证执行可靠性。
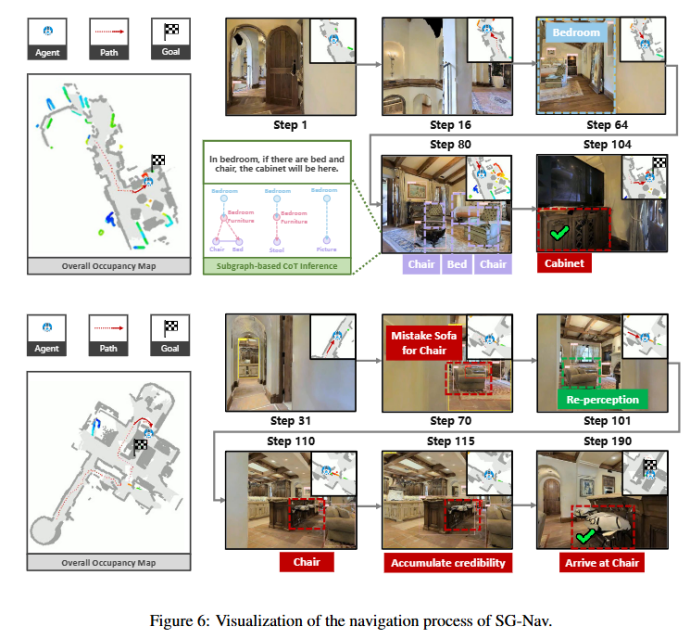
总的来说,SG-Nav 可以视为一个“感知–推理–行动–验证”的闭环,整体框架可分为四个关键模块:
a. 感知(在线 3D 场景图构建):通过视觉几何分割,动态构建对象–组–房间的三层级结构化场景图;
b. 推理(层级化 CoT 提示与子图概率估计):VLM 对局部子图进行层级化常识推理,得到目标概率分布;
c. 行动(前沿插值与行动决策):将推理结果映射为前沿得分,选择最优前沿,结合路径规划执行探索;
d. 验证(再感知机制):多帧验证检测结果,避免因假目标导致的失败。
这一框架兼具结构化知识表示与大模型推理的优势,保证了鲁棒性与可解释性。
2. 在线 3D 场景图构建、更新与剪枝
分层 3D 场景图构建

分层 3D 场景图 通过节点及其间的边来表示三维环境结构。节点分为三类:对象(object)、组(group) 与 房间(room),分别对应细粒度、中粒度与高层次的语义单元。其中,组节点表示一簇相关对象的集合,如“餐桌与周围的椅子”或“电视与电视柜”。
节点之间的边分为两类:
跨层级边:表示从属关系(如“椅子属于客厅”);
同层级边:表示空间或功能关系(如“电视与沙发相对”)。
这种分层设计既能捕捉局部的物体关系,又能表达全局的语义组织结构。
增量式更新
直接在复杂环境中一次性构建完整场景图成本极高。为实现实时在线构建,我们采用跨帧的 增量更新机制:在每个时刻,系统从 RGB-D 观测中注册新的节点,然后将其与上一时刻的场景图融合,得到当前时刻的场景表示。
这样,场景图会随着机器人探索逐步扩展,而不是一次性生成。
边的构建策略
不同层级的边由不同规则建立:
房间—对象边:若对象的实例掩码被房间掩码覆盖,则建立从属关系;
房间—组边:若组内所有对象均属于该房间,则建立连接;
对象—对象边:对于同层级对象,新注册的节点会先与所有已有对象节点密集连接,再通过剪枝筛选有效关系。
需要注意的是,组节点与对象节点之间不直接相连,因为组是基于对象节点聚合得到的。
边的高效推理与剪枝
密集连接会带来高昂的计算开销。假设新注册节点数为 ,已有节点数为 ,则组合后边数为 。若逐条边调用 LLM 推断关系,复杂度为 。为此,我们提出了一种新的 prompt 设计,使 LLM 能够一次性输出所有节点对的关系,将复杂度降至 。具体格式与理论推导可参考原文。
剪枝分两步进行:
1. 短距离关系:若 RGB-D 图像中同时包含两个对象,则判定为短距离边。我们将 RGB 图像输入到视觉语言模型(如 LLaVA [3]),验证该关系是否真实存在,若不存在则剪去。
2. 长距离关系:若对象不同时出现于图像中,则判定为长距离边。我们提出两个保留标准:连接两对象的连线无遮挡,且与房间墙壁平行;两对象属于同一房间节点。只有同时满足这两个条件的边才会被保留。
通过这一系列步骤,我们能够在保证关系准确性的同时大幅降低冗余边,使最终的 3D 场景图既高效又语义丰富。
3. 层级化 Chain-of-Thought 提示与子图概率估计
将场景图划分为若干子图,每个子图由一个对象节点及其所有父节点和其他直接连接的对象节点组成。
在推理过程中,系统对每个子图执行分层提示:
i. 粗略回忆:目标对象常见的场所;
ii. 局部验证:该子图是否合理包含目标;
iii. 层级分析:对象–组–房间的综合推理;
iv. 输出概率:给出该子图附近存在目标的概率 Psub及自然语言理由。
这种层级化 CoT 提示使得 VLM 的推理可解释且稳健。
4. 前沿插值与行动决策
探索过程中的已知空间与未知空间的边界称为前沿(frontier),SG-Nav 将子图的目标概率分布映射为前沿得分:

其中
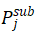
表示目标在子图 j 出现的概率,Dij表示前沿 i 到子图 j 的距离。靠近高概率子图的前沿会被赋予更高得分。
系统最终选择得分最高的前沿,并通过 Fast Marching Method 进行路径规划。这种方法实现了从“推理结果”到“具体空间行动”的映射,并能生成解释性文本说明“为何选择该路径”。
5. 再感知机制
传统的目标巡航框架没有考虑感知错误。一旦机器人检测到错误的目标物体,它将不再探索或感知环境,而是直接巡航到该物体(例如将挂画中的电视识别为真实电视)。
为了解决这个问题,我们增强了现有的目标巡航框架,增加了基于图的重感知机制。当机器人检测到一个目标物体时,它将靠近该物体,从多个角度观察,并累积可信度分数。对于从这一刻起的第次RGB-D观测,我们通过以下公式计算可信度:

其中, Ck是目标物体的置信度分数, Dj是第个子图的中心对象节点与该物体之间的距离。我们提出的重新感知机制的成功条件为:

其中, Nmax是预定义的最大步数。如果成功,机器人将巡航到该目标物体,不再进行进一步的探索或感知。否则,机器人将放弃该物体并继续探索。
三、实验
论文在 Matterport3D,HM3D和RoboTHOR上开展实验,取得了最先进的零样本性能,采用以下指标:
SR(成功率):是否成功找到目标;
SPL(路径效率):路径长度与最优路径的比值;
SoftSPL:容忍部分偏差的路径效率。
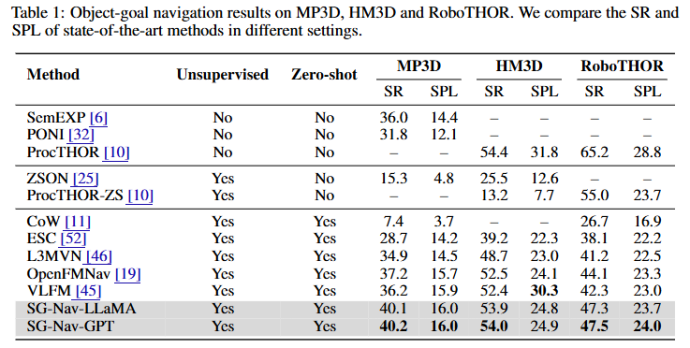
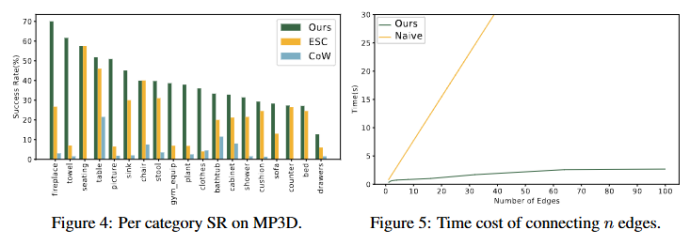
结果显示 SG-Nav 在零样本目标下显著优于基线方法。又进一步开展消融实验:
去掉房间与组节点 → 高层语境缺失,推理大幅下降;
去掉层级化 CoT → 概率估计不稳定;
去掉再感知 → 假阳性率大幅上升。

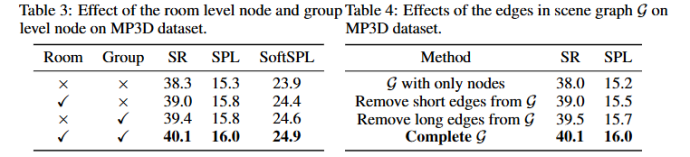
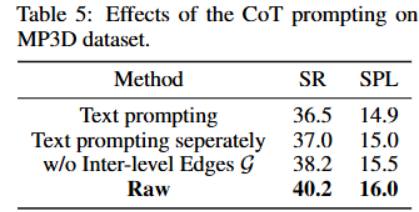
这些实验表明 SG-Nav 的每个模块都是不可或缺的。
四、SG-Nav与空间智能(个人观点总结并非完全准确)
SG-Nav 的关键创新在于:
层级化场景图建模:显式引入对象–组–房间的三层级表示;
结构化 CoT 提示:把场景图转写为自然语言描述,激发 VLM 的常识推理能力;
前沿插值机制:将概率推理结果映射为空间行动;
再感知机制:提升目标检测的鲁棒性。
这使得系统不仅在性能上优于基线,更重要的是提供了可解释的推理链条。
“在我看来,没有空间智能,通用人工智能就不完整。” 这是“AI教母”李飞飞在最新访谈中对AGI的判断。她讲到,从进入人工智能领域开始,她就确定了她终身奋斗的梦想:让智能体能够讲述世界的故事——而这,离不开空间智能。
从个人理解的角度看,SG-Nav 已经朝“空间智能”迈出了一步:它让机器人不只是通过 VLM 黑箱去推理动作,而是显式地利用空间结构化知识来指导探索。但仍存在局限,例如对 detector 依赖较大、缺乏显式的物理一致性建模。若未来能在场景图中引入物理可达性、几何约束与主动信息增益机制,或许能更进一步,向真正的“空间智能”靠拢。
