本文论文选自 Hugging Face 八月论文,解读由 🔥Intern-S1、Qwen3 等 AI 生成可能有误。
(1) Intern-S1: A Scientific Multimodal Foundation Model

论文简介:
由上海人工智能实验室提出的Intern-S1是一款面向科学领域的多模态基础模型,该工作通过创新的混合专家架构、科学数据增强策略及强化学习框架,在通用推理与科学专业任务中均展现出卓越性能。Intern-S1采用280亿激活参数、2410亿总参数的混合专家(MoE)架构,依托2.5万亿token科学领域数据进行持续预训练,并在InternBootCamp环境中通过混合奖励(MoR)框架实现千余任务的在线强化学习。其核心创新包括:1)动态分词器针对科学数据(如分子式、蛋白质序列)设计差异化分词策略,压缩率较传统方法提升70%;2)多模态编码器集成视觉、时序信号处理模块,支持高分辨率图像与长时序数据输入;3)混合奖励框架通过统一化反馈机制协同优化逻辑推理、学术问题解决与对话能力,样本效率较基线提升10倍。实验表明,Intern-S1在MMLU-Pro、MathVista等通用基准上超越主流开源模型,在ChemBench、MatBench等科学专项任务中性能优于闭源模型如OpenAI o3,尤其在分子合成规划、晶体热力学预测等专业场景实现突破。该模型的开源为科学智能研究提供了兼具广度与深度的基础工具,其训练范式为低资源领域模型优化提供了可扩展范例。
Hugging Face 投票数:242
论文链接:
https://hf.co/papers/2508.15763
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15763
(2) InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency

论文简介:
由上海人工智能实验室等机构提出了InternVL3.5,该工作通过创新的级联强化学习框架、视觉分辨率路由技术和解耦式视觉-语言部署策略,在保持开源模型开放性的同时,显著提升了多模态大模型的推理能力、应用通用性及部署效率。InternVL3.5系列包含从1B到241B参数量的多种模型规模,其中最大模型InternVL3.5-241B-A28B在35项多模态任务评估中达到74.1的综合得分,与闭源模型GPT-5(74.0)相当,且在MMMU(多模态推理)和MathVista(数学视觉推理)等核心任务中分别取得77.7和82.7的优异表现,领先现有开源模型。
核心创新方面,级联强化学习(Cascade RL)通过离线预训练(MPO算法)与在线优化(GSPO算法)的双阶段策略,使模型推理能力提升16%,其中8B参数模型在MMMU的得分从62.7跃升至73.4。视觉分辨率路由(ViR)技术动态调整图像token数量,在保持99%性能的前提下将视觉计算量降低50%,结合Decoupled Vision-Language Deployment(DvD)策略实现视觉与语言模块的异步并行计算,推理速度提升4.05倍。模型在文本理解、图表解析、视频推理等任务中均表现突出,例如在MME-RealWorld(真实场景理解)任务中,241B模型以74.6的分数大幅领先GPT-4o(57.4)。此外,该模型还支持GUI交互、具身智能等新型应用场景,在ScreenSpot(屏幕交互)任务中达到92.9的准确率。这些突破性进展为开源多模态模型追赶闭源模型提供了重要技术路径。
Hugging Face 投票数:170
论文链接:
https://hf.co/papers/2508.18265
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18265
(3) WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent

论文简介:
由阿里巴巴达摩院提出了WebWatcher,该工作构建了首个具备深度视觉-语言推理能力的网页智能体。针对现有研究代理多局限文本模态的问题,团队创新性地设计了多模态轨迹生成框架,通过结合高质量合成数据训练与强化学习优化,使模型在复杂视觉问答任务中展现出超越专有系统的推理能力。研究核心贡献包括:1)构建了包含17个子领域的BrowseComp-VL基准,采用实体模糊化设计提升推理难度;2)开发了自动化轨迹生成系统,通过LLM驱动的"思考-行动-观察"循环生成多工具协同的推理路径;3)提出基于GRPO的策略优化方法,通过组内相对优势计算实现稳定策略更新。实验显示,WebWatcher-32B在HLE考试中取得18.2%的平均正确率,较GPT-4o基线提升38%,在LiveVQA和MMSearch等视觉搜索基准上分别达到58.7%和55.3%的准确率。特别在需要跨模态推理的KenKen数独案例中,模型通过OCR识别、网页检索和代码执行的协同,成功破解需要多步骤数学推导的难题。该研究标志着智能体从文本研究向多模态深度推理的重要突破,为构建具备真实世界问题解决能力的AI系统提供了新范式。
Hugging Face 投票数:121
论文链接:
https://hf.co/papers/2508.05748
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05748
(4) Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning

论文简介:
由复旦大学、上海人工智能实验室、腾讯混元等机构提出了Pref-GRPO,该工作揭示了现有文本到图像生成强化学习方法中"奖励黑客"现象的本质原因是"虚假优势"问题,并提出首个基于成对偏好奖励的GRPO优化方法,通过将奖励最大化目标转化为偏好拟合来实现更稳定的生成训练。同时构建了包含600个提示词、覆盖5大主题20个子主题的UniGenBench基准,支持10个主维度27个子维度的细粒度评估,利用多模态大模型实现自动化评估流程。实验表明Pref-GRPO在语义一致性指标上较基线提升5.84%,文本和逻辑推理维度分别提升12.69%和12.04%,有效缓解了奖励分数虚高但质量下降的矛盾。UniGenBench的细粒度评估显示:闭源模型在逻辑推理(48.18%)和文本渲染(89.08%)表现突出,开源模型在动作(69.77%)和布局(77.61%)维度接近闭源水平,但在语法和复杂逻辑任务上仍有显著差距。该研究为文本到图像生成的优化范式和评估体系提供了新的技术路径与标准框架。
Hugging Face 投票数:85
论文链接:
https://hf.co/papers/2508.20751
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20751
(5) Self-Rewarding Vision-Language Model via Reasoning Decomposition

论文简介:
由腾讯AI Lab、马里兰大学等机构提出了Vision-SR1,该工作通过推理分解实现视觉语言模型的自我奖励,有效缓解视觉幻觉和语言捷径问题。现有VLMs常因依赖最终答案匹配而缺乏中间视觉监督,导致模型过度依赖文本先验。Vision-SR1创新性地将推理过程分解为视觉感知和语言推理两阶段:首先引导模型生成自包含的视觉描述,随后通过二次推理验证该描述是否足以独立支撑答案。通过强化学习框架,模型利用自身生成的视觉感知作为文本代理,自适应地生成视觉奖励信号,与最终答案奖励共同优化模型。实验表明,该方法在MMMU、MathVerse等多领域基准测试中显著提升视觉推理能力,平均指标提升3.7%,同时将语言捷径率降低40%。通过完全摒弃外部标注依赖,Vision-SR1建立了视觉感知与语言推理的动态平衡机制,为可扩展的多模态对齐提供了新范式。
Hugging Face 投票数:77
论文链接:
https://hf.co/papers/2508.19652
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19652
(6) Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory

论文简介:
由ByteDance、浙大和上海交大等机构提出的M3-Agent,构建了一个具备长期记忆的多模态智能体框架。该框架通过实时处理视频和音频流,生成包含情景记忆(具体事件)和语义记忆(通用知识)的实体中心化长期记忆网络,实现跨模态的持续知识积累。其核心创新在于:1)采用面部识别和语音识别工具构建稳定的人物身份表示,确保跨视频片段的身份一致性;2)设计强化学习驱动的多轮推理机制,通过迭代检索记忆库中的相关片段完成复杂指令;3)开发包含1,276个问题的M3-Bench-robot机器人视角数据集,以及涵盖929个视频的M3-Bench-web数据集,重点考察人物理解、跨模态推理等能力。
实验对比了Socratic模型、在线视频理解方法等基线,M3-Agent在M3-Bench-robot、M3-Bench-web和VideoMME-long基准测试中分别取得6.7%、7.7%和5.3%的准确率提升。消融实验表明:语义记忆缺失会导致准确率下降17.1%-19.2%,强化学习训练带来10.0%-9.3%的性能增益。案例分析显示,该框架能有效关联人物身份、推理人物性格(如判断角色是否富有想象力),但在空间推理和细节记忆方面仍存在挑战。这项工作为多模态智能体的长期记忆构建提供了新范式,推动智能体向更接近人类的持续学习能力发展。
Hugging Face 投票数:53
论文链接:
https://hf.co/papers/2508.09736
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09736
(7) LongVie: Multimodal-Guided Controllable Ultra-Long Video Generation

论文简介:
由复旦大学、南洋理工大学等机构提出的LongVie,针对可控超长视频生成任务,通过多模态引导和退化感知训练策略,解决了现有方法在生成一分钟以上视频时面临的时间不一致和视觉质量退化问题。该工作创新性地提出统一噪声初始化策略,通过共享跨片段的噪声输入维持生成一致性;采用全局控制信号归一化确保全视频范围的场景对齐;引入密集(深度图)与稀疏(关键点)控制信号的多模态融合框架,并设计特征级与数据级的退化训练机制平衡模态贡献。为验证方法有效性,团队构建了包含100个真实场景与游戏画面的LongVGenBench基准数据集,每个视频时长均超过一分钟。实验显示,LongVie在时间一致性、视觉质量等7项指标上全面超越CogVideoX、StreamingT2V等基线模型,用户研究得分提升40%以上。该框架还支持视频编辑、运动迁移、三维网格驱动等下游任务,在影视制作和内容创作领域具有重要应用价值。
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2508.03694
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.03694
(8) Visual-CoG: Stage-Aware Reinforcement Learning with Chain of Guidance for Text-to-Image Generation

论文简介:
由阿里巴巴集团提出了Visual-CoG,该工作针对当前文本到图像生成模型在处理多属性和模糊提示时的局限性,创新性地设计了阶段感知的强化学习框架。研究团队通过构建包含语义推理、过程细化和结果评估三个阶段的视觉引导链(Visual-CoG),在生成全流程中引入即时奖励机制,有效解决了传统方法仅依赖最终结果反馈导致的优化偏差问题。核心突破在于:1)语义推理阶段通过对比原提示与推理提示的生成差异计算奖励,提升复杂语义理解能力;2)过程细化阶段采用教师模型指导的掩码重建任务评估中间结果;3)结果评估阶段结合规则引擎与美学模型实现多维质量判断。为验证推理能力,团队特别构建了包含非常规位置、组合、颜色及推理任务的VisCogBench基准,实验显示该方法在GenEval、T2I-CompBench和VisCogBench上分别取得15%、5%和19%的性能提升,尤其在计数、空间关系等多属性任务中表现突出。该研究为生成模型的阶段性优化提供了新范式,相关资源即将开源。
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2508.18032
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18032
(9) Enhancing Vision-Language Model Training with Reinforcement Learning in Synthetic Worlds for Real-World Success
论文简介:
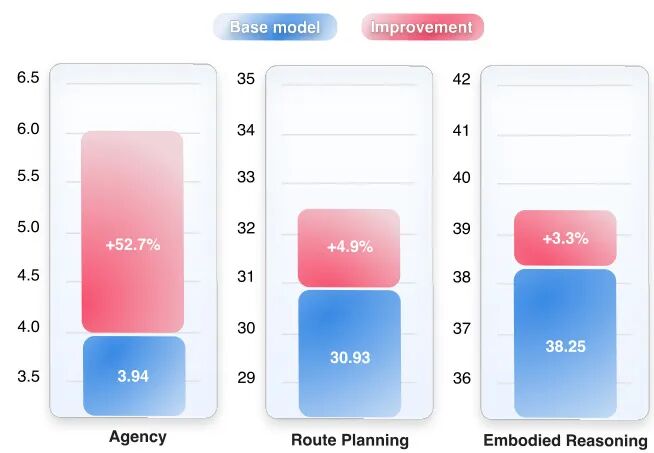
由 T-Tech 等机构提出了 Vision-Language Decoupled Actor-Critic (VL-DAC),该工作提出一种轻量级无超参数强化学习算法,通过将策略损失与值函数损失解耦,实现视觉语言模型在合成环境中的高效训练并有效迁移到真实任务。VL-DAC 在 token 级别应用 PPO 更新策略网络,同时在环境步骤级别学习值函数,通过停止梯度回传避免交叉信号干扰,显著提升训练稳定性。该方法在 MiniWorld、ALFWorld 等低成本模拟器中训练单一模型,即可在 BALROG(+50%)、VSI-Bench(+5%)和 VisualWebBench(+2%)等真实场景基准测试中取得显著提升,且不损害通用图像理解能力。实验表明,VL-DAC 比 RL4VLM 更稳定,比 LOOP 更适合长时序任务,其 token/step 分离设计消除了传统方法对超参数调优、重放缓冲区或密集奖励的依赖。研究证实通过多样化模拟器训练和算法简化,可实现从合成环境到真实任务(包括具身控制、空间规划和网页导航)的有效技能迁移,为视觉语言模型的强化学习训练提供了可扩展的实用方案。
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2508.04280
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04280
(10) Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies

论文简介:
由香港大学、上海人工智能实验室、上海交通大学、华为云等机构提出了Discrete Diffusion VLA,该工作首次将离散扩散模型引入视觉-语言-动作(VLA)策略的动作解码,通过统一的单transformer架构实现视觉、语言与动作的联合建模。该方法将连续动作离散化为固定长度的动作块,并采用离散扩散范式进行迭代解码,保留了扩散模型渐进式精炼的优势,同时与视觉语言模型(VLM)的离散token接口天然兼容。其核心贡献包括:1)提出首个基于离散扩散的VLA动作解码框架,通过交叉熵损失与VLM主干网络统一训练,保留预训练的视觉语言先验知识;2)设计自适应解码策略,按置信度优先解码简单动作元素并二次重掩码修正不确定预测,实现并行解码与错误修正;3)在LIBERO、SimplerEnv-Fractal和SimplerEnv-Bridge三个机器人任务中取得SOTA表现,Franka Panda机械臂在LIBERO上平均成功率96.3%,Google Robot在SimplerEnv-Fractal视觉匹配率达71.2%,WidowX机械臂在SimplerEnv-Bridge整体成功率49.3%,显著优于自回归和连续扩散基线方法。该方法突破了传统自回归解码的左到右瓶颈,通过固定步数的并行精炼将函数评估次数减少4.7倍,为大规模VLA模型扩展提供了新路径。
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2508.20072
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.20072
(11) MIDAS: Multimodal Interactive Digital-human Synthesis via Real-time Autoregressive Video Generation

论文简介:
由快手科技、浙江大学和清华大学等机构提出了MIDAS(Multimodal Interactive Digitalhuman Synthesis),该工作构建了一种基于自回归模型与扩散渲染的实时多模态数字人合成框架。针对现有方法在低延迟交互、多模态控制和长序列生成上的局限,研究团队设计了三大核心创新:首先通过多模态条件投影器将音频、姿态、文本等异构信号编码为统一指令令牌,引导自回归模型生成时空一致的潜在表示;其次采用因果潜在预测与轻量扩散头结合的架构,以单帧预测策略实现流式生成,在保证质量的同时将推理延迟降至毫秒级;此外开发了64倍压缩比的深度压缩自编码器(DC-AE),显著降低长序列生成的计算负担。为支撑模型训练,团队构建了包含2万小时对话的多场景数据集,并引入可控噪声注入机制缓解训练与推理的暴露偏差问题。实验部分通过双工对话、跨语言唱歌合成和交互式世界模型三项任务验证了框架的有效性:数字人能实现自然的对话轮转与唇形同步,支持中英日等多语言高保真生成,并在《我的世界》场景中展现出稳定的视觉记忆与环境交互能力。该工作在保持身份一致性的同时,实现了多模态条件下的实时响应与开放域生成,为交互式数字人技术提供了可扩展的解决方案。
Hugging Face 投票数:27
论文链接:
https://hf.co/papers/2508.19320
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19320
(12) MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Hugging Face 投票数:26
论文链接:
https://hf.co/papers/2508.18264
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18264
(13) T2I-ReasonBench: Benchmarking Reasoning-Informed Text-to-Image Generation

论文简介:
由香港大学和香港中文大学等机构提出了T2I-ReasonBench,该工作构建了一个新型基准测试框架,旨在系统评估文本到图像生成模型的推理能力。研究团队针对现有模型在隐含语义理解上的不足,设计了包含800个提示词的测试集,覆盖成语解读、图文设计、实体推理和科学推理四大维度,要求模型在生成图像前完成多步骤逻辑推导。通过大语言模型生成定制化评估问题,再由多模态模型进行双阶段评分,该框架可量化推理准确率和图像质量。实验对比了14种主流模型,包括扩散模型、自回归模型和闭源商用模型,发现开源模型普遍存在显著推理缺陷,而GPT-Image-1等闭源模型虽表现更优但仍存在提升空间。研究揭示了当前文本到图像生成技术在知识整合与逻辑推理上的核心瓶颈,为构建具备深度语义理解能力的下一代生成模型提供了基准参考和改进方向。
Hugging Face 投票数:26
论文链接:
https://hf.co/papers/2508.17472
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17472
(14) villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
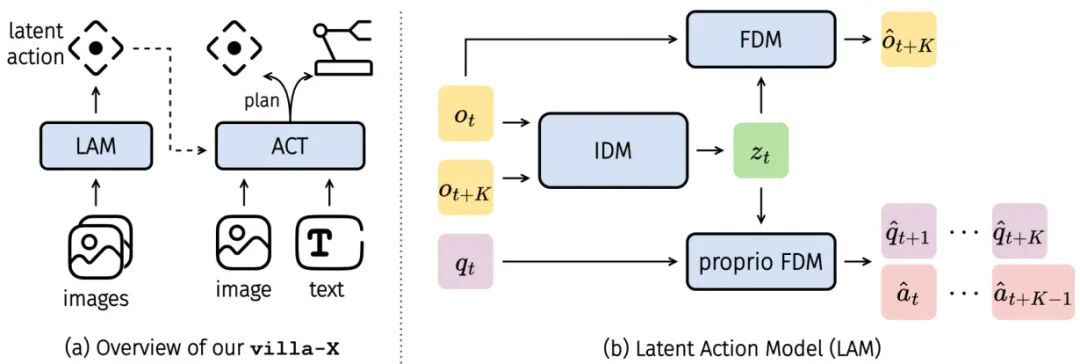
论文简介:
由微软、清华大学、武汉大学等机构提出了villa-X,该工作提出了一种新型视觉-语言-潜在动作(ViLLA)框架,通过改进潜在动作建模和整合方式显著提升了视觉-语言-动作(VLA)模型的泛化能力。核心创新包括:1)在潜在动作模型(LAM)中引入本体前向动力学模块(FDM),通过预测未来机器人状态和动作,使潜在动作与物理动态对齐,增强其对机器人行为的表征能力;2)设计联合扩散过程建模潜在动作专家和机器人动作专家,通过注意力机制实现潜在动作到机器人动作的显式条件生成,有效传递高层语义信息。实验表明,改进后的LAM在LIBERO数据集上通过探针任务验证了潜在动作与机器人动作的强关联性,且在SIMPLER模拟环境和Realman/Xarm真实机器人平台上均取得最优性能。在SIMPLER的Google机器人和WidowX机器人任务中,villa-X平均成功率分别达到59.6%和62.5%,显著优于RT-1-X、Octo-base等基线方法;在LIBERO多任务基准测试中,其平均成功率90.1%也超越Diffusion Policy、OpenVLA等模型。该框架通过潜在动作作为中层桥梁,实现了视觉-语言指令到机器人动作的有效规划,在夹持器操作和灵巧手控制等真实场景中展现出优异的跨形态泛化能力。
Hugging Face 投票数:23
论文链接:
https://hf.co/papers/2507.23682
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23682
(15) MM-BrowseComp: A Comprehensive Benchmark for Multimodal Browsing Agents
论文简介:
由字节跳动、南京大学等机构提出了MM-BrowseComp,该工作构建了一个包含224个挑战性问题的基准测试,专门评估代理的多模态检索和推理能力。该基准要求代理在搜索和推理过程中处理嵌入在网页文本、图像或视频中的关键信息,仅依赖文本的方法在此任务上表现不足。研究团队为每个问题提供验证清单,用于分析多模态依赖关系和推理路径,实现对代理行为的细粒度评估。实验表明,即使当前最先进的模型(如OpenAI o3)在此基准上的准确率也仅为29.02%,凸显了现有模型在多模态能力上的局限性。研究发现,当前开源代理主要依赖图像字幕工具处理视觉内容,导致信息丢失和幻觉,而OpenAI o3通过原生多模态能力直接分析图像内容,展现出更强的推理能力。此外,反思型代理(如Agent-R1)通过避免过度依赖子代理输出,在鲁棒性上表现更优。研究强调,强大的推理能力与完整的工具集需协同作用,单一优势无法保障性能。错误分析显示,视觉理解错误(如幻觉)和工具执行失败是主要瓶颈,且模型在需要广泛搜索的任务上性能显著下降,揭示了上下文窗口限制和多模态处理成本高等根本挑战。该工作通过细粒度评估框架和高难度问题设计,为多模态代理的未来研究指明了方向。
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.13186
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13186
(16) Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer

论文简介:
由香港科技大学、国际数字经济学研究院、清华大学、智谱AI等机构提出了ColorCtrl,该工作提出了一种无需训练的文本引导颜色编辑方法,通过解耦多模态扩散Transformer(MM-DiT)中的结构与颜色信息,实现对物体反照率、光源颜色和环境光照的精准编辑,同时保持几何结构、材质属性和光物质交互的物理一致性。ColorCtrl通过定向操控注意力图和值令牌,仅修改文本提示指定的区域而不影响无关区域,并支持词级控制颜色属性强度。实验表明,该方法在SD3和FLUX.1-dev等MM-DiT模型上显著优于现有训练-free方法,在编辑质量与一致性指标上均达到SOTA水平。值得注意的是,ColorCtrl在保持非编辑区域一致性方面甚至超越了FLUX.1 Kontext Max和GPT-4o等商业模型,其生成结果在色彩和谐度与物理合理性上表现更优。该方法还展现出强大的跨模型泛化能力,可无缝迁移至视频生成模型CogVideoX及指令编辑模型Step1X-Edit,在时序一致性与材质保真度上优势更为显著。通过引入区域颜色保持模块和属性重加权机制,ColorCtrl在无需人工调参的情况下实现了从粗粒度到细粒度的全尺度颜色控制,为生成式AI在影视级后期处理和自动化批处理场景的应用提供了新的技术路径。
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.09131
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09131
(17) UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation

论文简介:
由首尔国立大学、FuriosaAI等机构提出了UNCAGE,该工作针对Masked Generative Transformers(MGTs)在文本到图像生成中属性绑定不准确的问题,提出了一种无需训练的对比注意力引导解码策略。研究发现MGTs在组合式文本到图像生成任务中存在对象属性错位、文本-图像对齐度低的问题,这与其并行解码机制和注意力图的局限性密切相关。UNCAGE通过构建正负对象对的注意力对比机制,在解码初期优先解码能清晰表征独立对象的token,从而在不增加模型训练成本的前提下显著提升生成质量。具体而言,方法通过计算每个空间位置的对比注意力分数(正对最小注意力与负对最大注意力的差值),动态调整解码顺序,使关键对象特征在早期生成阶段得到强化。实验表明,该方法在Attend-and-Excite和SSD等基准数据集上,CLIP文本-图像相似度、GPT评估等指标均超越现有方法,在保持0.13%额外计算开销的情况下,用户研究偏好度提升近50%。与扩散模型的梯度优化方法相比,UNCAGE在计算效率和对MGTs的适配性上具有显著优势,为生成式Transformer的解码优化提供了新的技术路径。
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.05399
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05399
(18) MathReal: We Keep It Real! A Real Scene Benchmark for Evaluating Math Reasoning in Multimodal Large Language Models
论文简介:
由百度、新加坡南洋理工大学等机构提出了MathReal,该工作构建了首个面向K-12数学教育场景的真实场景基准数据集,包含2000道手持设备拍摄的数学题图像,系统覆盖图像质量退化、视角变化、手写干扰等14种现实场景挑战。研究发现当前多模态大语言模型在真实场景中表现显著下降,闭源模型Doubao-1.5-thinking-vision-pro在测试中仅取得53.9%准确率,而开源模型普遍低于30%。通过严格评估揭示模型在多步推理稳定性上的缺陷,分析显示视觉感知错误(占40-50%)和推理错误(占30%以上)是主要瓶颈,且图像噪声导致的OCR错误会大幅降低后续推理性能。该研究揭示了现有模型在真实教育场景应用中的关键缺陷,为开发更具鲁棒性的多模态推理模型提供了基准和优化方向。
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2508.06009
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.06009
(19) InstructVLA: Vision-Language-Action Instruction Tuning from Understanding to Manipulation

论文简介:
由上海人工智能实验室、中国科学技术大学和浙江大学等机构提出了InstructVLA,该工作提出了一种端到端的视觉-语言-动作(VLA)模型,通过保留大规模视觉语言模型(VLM)的灵活推理能力,同时实现领先的操作性能。核心贡献包括:1)提出VLA-IT训练范式,通过混合专家适配框架联合优化文本推理和动作生成,同时使用65万样本的VLA-IT数据集;2)设计多模态数据和评估流程,支持VLA模型的指令泛化能力评估;3)在机器人操作任务、多模态基准和真实世界部署中实现SOTA性能。实验表明,InstructVLA在SimplerEnv任务上比SpatialVLA提升30.5%,在新提出的SimplerEnv-Instruct零样本基准上,超越微调后的OpenVLA和GPT-4o辅助的动作专家模型,分别提升92%和29%。此外,模型在多模态任务中表现优异,并通过推理时的文本生成增强操作性能,展现了将人类-机器人交互与高效策略学习相结合的潜力。
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2507.17520
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.17520
(20) A Glimpse to Compress: Dynamic Visual Token Pruning for Large Vision-Language Models

论文简介:
由南开大学、上海人工智能实验室等机构提出了GlimpsePrune,该工作针对大视觉语言模型(LVLMs)在高分辨率输入下的计算瓶颈问题,提出了一种动态视觉token剪枝框架。现有方法采用固定压缩比率,难以适应不同场景的复杂度,易误删关键视觉信息。GlimpsePrune受人类认知启发,通过插入可学习的“glimpse token”在解码器前向传播阶段提取视觉token重要性得分,并利用轻量级预测器动态剪枝无关token。该方法在Qwen2.5-VL-7B模型上实现92.6%的平均剪枝率,同时保持基线模型在自由形式VQA任务中的完整性能。进一步通过强化学习微调的GlimpsePrune+版本,在维持高剪枝率的同时将性能提升至基线模型的110%。实验表明,该方法在12个VQA数据集上均表现优异,尤其在小目标场景(如DocVQA)中动态调整至3.6%-3.8%的极低保留率时,性能仅下降0.2%。该框架通过单次深度KV缓存剪枝,将解码阶段峰值显存占用降低至基线的72.8%,并支持6000token长度的高效强化学习微调,为构建高效大视觉语言模型提供了新范式。
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2508.01548
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01548
(21) Can Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.04017
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.04017
(22) Adapting Vision-Language Models Without Labels: A Comprehensive Survey

论文简介:
由 Hao Dong 等机构提出了 Adapting Vision-Language Models Without Labels,该工作系统梳理了无监督视觉-语言模型(VLM)适应领域的研究进展,提出基于无标签视觉数据可用性的四维分类体系。研究将现有方法划分为数据空迁移(Data-Free Transfer)、无监督域迁移(Unsupervised Domain Transfer)、片段测试时适应(Episodic Test-Time Adaptation)和在线测试时适应(Online Test-Time Adaptation)四大范式,每个范式对应不同的数据假设和方法挑战。
在数据空迁移场景中,研究聚焦于仅依赖文本类别名称的适应方法,总结出文本增强(Text Augmentation)、图像利用(Image Utilization)和网络修改(Network Modification)三大策略,其中利用大语言模型生成描述性文本和基于检索/生成的视觉信号引入是主要技术路线。无监督域迁移方法则充分利用目标域无标签数据,通过自训练(Self-Training)、熵优化(Entropy Optimization)和外部资源利用(External Resource Utilization)等策略实现跨域对齐,典型方法包括基于伪标签的Prompt学习和多模态知识蒸馏。
测试时适应方面,研究区分了片段式和在线式两种场景。前者针对独立测试批次,采用熵最小化(如TPT)、反馈信号(如Diffusion-TTA)和分布对齐(如PromptAlign)等策略;后者侧重连续数据流处理,发展出伪标签优化(如DART)、记忆机制(如TDA)和分布建模(如OGA)等动态适应方法。论文还系统整理了在图像分类、语义分割、视觉推理等领域的基准数据集,指出理论分析、开放世界适应、对抗鲁棒性等八大未来方向,特别强调医疗影像等垂直领域的应用潜力。
该分类体系为无监督VLM适应提供了清晰的研究框架,揭示了不同场景下的方法演进脉络,对推动跨模态学习在真实场景落地具有指导意义。
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.05547
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05547
(23) HumanSense: From Multimodal Perception to Empathetic Context-Aware Responses through Reasoning MLLMs

论文简介:
由Zheng Qin等研究团队提出了HumanSense,该工作构建了一个用于评估多模态大语言模型(MLLMs)在人类中心场景下感知与交互能力的基准框架。研究团队发现当前主流MLLM在理解复杂人类意图和生成共情回应方面存在显著不足,尤其在多模态上下文推理和多轮交互策略规划等高级任务中表现薄弱。HumanSense基准包含15项渐进式任务,覆盖从基础感知(如动作识别、情感识别)到复杂推理(如关系识别、心理对话策略)的完整能力评估体系,通过3882个基于真实场景的问答对进行测试。实验表明,融合视觉、听觉和文本的多模态输入可显著提升模型表现,Omni模型在高阶任务中展现出明显优势。研究进一步提出多阶段强化学习方法,通过分阶段训练视觉推理、听觉推理和跨模态推理能力,使模型在基准测试中平均得分提升14.7%。此外,团队发现成功推理过程存在共性思维模式,通过设计包含特征提取-情绪识别-语境分析的提示模板,使非推理模型在零样本场景下性能提升9.2%。该工作揭示了多模态推理在实现类人交互中的关键作用,为提升AI系统的共情能力和上下文感知提供了新的优化路径。
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.10576
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10576
(24) MCIF: Multimodal Crosslingual Instruction-Following Benchmark from Scientific Talks

论文简介:
由Fondazione Bruno Kessler、Karlsruhe Institute of Technology和Translated等机构提出了MCIF(Multimodal Crosslingual Instruction Following),该工作构建了首个基于科学演讲的多语言多模态指令跟随基准数据集。MCIF覆盖文本、语音、视频三种模态及英/德/意/中四种语言,支持短文本与长文本输入,包含13项跨模态跨语言任务(如语音识别、视频问答、多语言翻译等),旨在全面评估多模态大语言模型(MLLMs)在复杂场景下的指令理解与执行能力。数据集基于ACL 2023科学演讲构建,包含21个完整演讲视频(2小时时长)及79个扩展样本(10小时时长),所有文本、语音、视频内容均经过专业人工转写、翻译和标注,确保数据质量与多语言一致性。研究团队设计了MCIF_fix(固定指令)和MCIF_mix(多样化指令)两个版本,通过21个主流模型(包括LLMs、SpeechLLMs、VideoLLMs和MLLMs)的实验表明:当前模型在长文本处理、跨语言信息抽取及指令鲁棒性方面仍存在显著局限,例如Ola模型在长语音识别任务中表现突出(WER显著低于其他模型),但多数模型在混合指令测试中性能下降超过20%。MCIF的发布为推动多模态多语言通用人工智能的发展提供了标准化评估框架,所有数据已通过CC-BY 4.0协议开源。
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2507.19634
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.19634
(25) SEAM: Semantically Equivalent Across Modalities Benchmark for Vision-Language Models
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2508.18179
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18179
(26) MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment

论文简介:
由 Sharif University of Technology 等机构提出了 MEENA (PersianMMMU),该工作构建了首个面向波斯语视觉语言模型(VLMs)的多模态多语言教育考试评估数据集。MEENA 包含约 7,500 个波斯语和 3,000 个英语问题,覆盖推理、数学、物理、图表、艺术与文学等学科,涵盖从小学到高中各教育阶段。数据集提供难度分级、详细答案、陷阱选项标识等丰富元数据,并通过原生波斯语内容保留文化特征,同时采用双语结构支持跨语言模型评估。研究团队设计了零样本、少样本、视觉描述、错误图像和无图像等五种实验场景,对 GPT-4o、Gemini-2.0 等模型进行系统测试,发现知识型任务准确率显著高于推理型任务(波斯语差距达 10-19%),Gemini-2.0 在检测图像不匹配方面表现最优(波斯语检测率超 GPT-4o Mini 400 例),而 GPT-4o 系列在图像存在性判断上更稳定。实验还揭示模型在化学和数学高难度问题中准确率随复杂度提升显著下降,凸显多模态模型在复杂推理和领域知识获取上的现存挑战。该数据集的建立为非英语语种多模态模型评估提供了重要基准,推动跨文化多模态人工智能研究发展。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.17290
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17290
(27) Do What? Teaching Vision-Language-Action Models to Reject the Impossible

论文简介:
由加州大学伯克利分校等机构提出了Instruct-Verify-and-Act(IVA)框架,该工作首次探索了视觉-语言-动作(VLA)模型在机器人领域中处理虚假前提指令的能力。研究者针对现有VLA模型无法识别用户指令中引用的不存在对象或不可行条件的问题,构建了包含正例与虚假前提指令的半合成数据集,通过指令微调训练出能够检测不可行指令、生成语言澄清并提供替代方案的VLA模型。IVA框架在保留视觉编码器和语言编码器的前提下,采用LoRA适配器对自回归解码器进行端到端微调,实现了在检测阶段识别虚假前提指令(In-Domain场景检测准确率100%,Out-of-Domain场景97.78%),在执行阶段通过自然语言反馈修正指令(如"未检测到安全箱,是否指代罐子?"),并在真实前提任务中保持与基线模型相当的执行成功率(42.67% vs 38.67%)。实验在9个RLBench任务中验证,IVA在虚假前提场景的成功率较基线提升50.78%,同时将虚假前提检测准确率提升97.56%,证明了该方法在保持常规任务性能的同时,显著增强了机器人应对不可行指令的能力。该研究为语言感知型机器人在现实复杂环境中的安全交互提供了新思路,但目前仍受限于仿真数据的多样性和真实场景的部署验证。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.16292
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16292
(28) Personalized Safety Alignment for Text-to-Image Diffusion Models

论文简介:
由 Yu Lei 等研究者提出了 Personalized Safety Alignment (PSA) 框架,该工作针对当前文本到图像扩散模型统一安全机制无法满足用户个性化需求的问题,创新性地通过用户安全配置文件实现生成内容的动态安全对齐。研究者构建了包含1000个虚拟用户配置文件的 Sage 数据集,涵盖810个有害概念和10个敏感类别,利用LLM生成用户对安全内容的偏好标签,并设计交叉注意力适配器将用户嵌入向量注入扩散模型的U-Net架构。PSA 通过个性化扩散DPO损失函数优化模型,在生成过程中动态调整安全边界,实验显示其在SD v1.5和SDXL架构上均显著优于SLD、SafetyDPO等基线方法,在I2P和UD等数据集上将有害内容生成概率(IP)降低至0.05-0.12区间,同时保持34.3的CLIPScore语义对齐度。特别在用户偏好对齐评估中,PSA 相较基线模型获得86.2%的胜率提升,并通过5级安全强度调节实现视觉质量与内容过滤的灵活权衡。该研究开创了生成模型个性化安全对齐的新范式,为构建用户中心化的内容生成系统提供了重要技术路径。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.01151
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01151
(29) LAMIC: Layout-Aware Multi-Image Composition via Scalability of Multimodal Diffusion Transformer

论文简介:
由中科大、Onestory Team和华东师范大学等机构提出了LAMIC,该工作首次将单参考扩散模型扩展到多参考场景的零样本布局感知多图像合成框架。LAMIC基于多模态扩散Transformer(MMDiT)架构,通过Group Isolation Attention(GIA)和Region-Modulated Attention(RMA)两种即插即用注意力机制实现核心突破:GIA通过限制视觉-文本-空间三元组内的局部注意力增强实体解耦,RMA则通过延迟区域融合和跨实体交互指令注入提升布局可控性。为全面评估模型能力,研究团队引入了Inclusion Ratio(IN-R)、Fill Ratio(FI-R)和Background Similarity(BG-S)三项新指标,分别衡量布局控制精度和背景一致性。实验表明,LAMIC在2/3/4参考图像设置下均取得最优表现,尤其在身份保持(ID-S)、背景一致性(BG-S)、布局控制(IN-R)和综合指标(AVG)上全面领先现有方法。值得注意的是,该框架无需任何训练或微调即可实现多参考图像合成,展现出强大的零样本泛化能力。在复杂场景下(如四参考图像),LAMIC的DPG指标与UNO持平,但ID-S和BG-S分别领先8.41和6.46分,凸显其在身份保真和背景合成上的优势。未来研究将聚焦于优化注意力设计以平衡区域边界平滑性与实体解耦效果,并探索提示词与参考图像的早期绑定机制以增强跨实体交互能力。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.00477
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00477
(30) CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification

论文简介:
由哈尔滨工业大学深圳校区等机构提出了CogVLA,该工作提出了一种认知对齐的视觉-语言-动作框架,通过指令驱动的路由与稀疏化策略,在提升模型效率的同时增强跨模态语义一致性。CogVLA借鉴人类多模态协调机制,构建了"视觉注意系统(VAS)-辅助运动区(SMA)-前运动皮层(PMC)"的三阶段渐进架构:首先通过EFA-Routing模块将指令信息注入视觉编码器,动态聚合双流视觉token形成任务感知的潜在表示;接着LFP-Routing模块在语言模型中引入动作意图,修剪指令无关的视觉token实现token级稀疏化;最后CAtten模块通过因果视觉-语言注意力与双向动作并行解码,确保压缩感知输入下的动作序列逻辑一致性与时间连贯性。在LIBERO基准测试中,CogVLA以97.4%的成功率刷新纪录,真实机器人任务成功率提升至70.0%,同时训练成本降低2.5倍,推理延迟减少2.8倍。该框架通过协同优化的路由模块与耦合注意力机制,在保持高任务性能的同时显著降低计算开销,为构建高效具身智能系统提供了新范式。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.21046
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.21046
(31) Multimodal Referring Segmentation: A Survey

论文简介:
由 Ding 等机构提出了《Multimodal Referring Segmentation: A Survey》,该工作系统梳理了跨图像、视频和3D场景的多模态指代表达分割任务体系。论文提出统一的任务分类框架,涵盖经典指代表达分割(RES)、视频分割(RVOS)、音频-视觉分割(AVS)及新兴的多模态音频-视觉分割(OmniAVS)等场景,创新性地引入通用元架构设计,总结了特征提取、跨模态交互、时序建模等核心模块的技术演进。研究揭示了大模型(如SAM、CLIP)和视觉基础模型对领域的推动作用,highlight了GRES(广义分割)、推理分割等前沿方向。通过对RefCOCO、ScanRefer等27个基准数据集的全面分析,指出当前方法在多目标定位、弱监督学习及跨模态对齐方面的挑战。论文还系统梳理了两阶段与单阶段方法的演进路径,揭示了Transformer架构、对比学习和提示学习对性能提升的关键作用,为构建具备开放世界理解能力的通用分割模型提供了方法论指导。
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.00265
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00265
(32) AgroBench: Vision-Language Model Benchmark in Agriculture

论文简介:
由大阪大学、京都大学、东京工业大学等机构提出了AgroBench,该工作构建了一个覆盖203种作物、682种疾病、108种杂草和134种害虫的农业视觉语言模型基准测试集,包含7个农业工程核心任务(疾病/害虫/杂草识别、作物管理、疾病管理、机械使用问答、传统农法评估),所有标注均由农业专家完成。AgroBench通过多任务评估揭示了当前VLM模型在杂草识别(多数开源模型接近随机)和细粒度疾病识别上的局限性,分析显示51.9%的错误源于专业知识缺失,32.7%源于感知偏差。实验对比12种主流VLM模型发现,闭源模型GPT-4o在整体任务中表现最佳(73.45%),但所有模型在杂草识别任务中准确率均低于55%,凸显农业领域专业视觉知识的训练缺口。该数据集通过真实农场场景图像和专家标注,为农业多模态模型的评估与优化提供了标准化基准。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2507.20519
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.20519
(33) Controlling Multimodal LLMs via Reward-guided Decoding

论文简介:
由Mila、Meta FAIR等机构提出了Controlling Multimodal LLMs via Reward-guided Decoding,该工作提出了一种多模态奖励引导解码(MRGD)方法,通过构建针对视觉定位的双奖励模型(物体精度与召回率),首次实现了多模态大语言模型(MLLMs)在推理阶段的动态可控性。该方法通过线性组合两个奖励模型的权重(w∈[0,1]),使用户能够实时调整输出的物体精度与召回率的权衡,并通过控制搜索宽度(k)和评估频率(T)平衡计算成本与视觉定位质量。实验表明,MRGD在COCO和AMBER基准上将物体幻觉率降低50%以上,同时保持或提升现有方法的性能,且在不同MLLM架构(如LLaVA-1.5、Llama-3.2-Vision)上均有效。该方法无需微调模型,仅需训练轻量级奖励模型(如基于PaliGemma的物体幻觉奖励模型),即可通过搜索策略优化输出,相比贪婪解码在COCO上将实例级幻觉率从15.05%降至4.53%,且计算效率比传统拒绝采样提升6倍以上。研究还揭示了MLLM中精度与召回率的固有权衡,并证明通过调整w值可灵活适配不同数据集特性(如COCO需w=0.25,AMBER需w=1.0)。该方法为多模态模型的可控生成提供了新范式。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.11616
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.11616
(34) VisCodex: Unified Multimodal Code Generation via Merging Vision and Coding Models

论文简介:
由微软、北京大学和南方科技大学等机构提出了VisCodex,该工作通过合并视觉和编码模型提出了一种统一的多模态代码生成框架。VisCodex利用任务向量合并技术,将先进视觉语言模型与专用代码语言模型参数进行线性融合,在保留视觉理解能力的同时注入强大的代码生成能力。研究团队构建了包含59.8万样本的多模态编码数据集MCD,涵盖网页设计、图表生成、StackOverflow问答和算法题等多元场景,并开发了专门评估视觉编程能力的InfiBench-V基准测试。实验显示,VisCodex-8B在多模态代码生成任务上超越了GPT-4o-mini等专有模型,而33B参数版本的平均得分达到72.3,与GPT-4o的73.3相当。该方法通过选择性参数合并策略,在不改变视觉编码器和跨模态投影模块的前提下,仅微调语言模型主干即可实现视觉-代码能力的高效融合,为多模态代码生成领域树立了新的开源模型标杆。研究团队已公开模型代码、数据集和基准测试,为后续研究提供了重要基础设施。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.09945
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09945
(35) Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents

论文简介:
由 UNC Chapel Hill 和 Lambda 等机构提出了 Bifrost-1,该工作通过引入与多模态大语言模型(MLLM)原生对齐的 patch-level CLIP 图像嵌入作为潜在变量,实现了 MLLM 与扩散模型的高效整合。核心创新在于利用 MLLM 自身视觉编码器生成的空间对齐图像嵌入,通过轻量级 ControlNet 适配器注入扩散模型,同时为 MLLM 增加视觉生成分支以预测 patch-level 图像嵌入,从而在保持原始多模态推理能力的前提下实现高保真可控图像生成。实验表明,该方法在图像重建、文本到图像生成等任务上达到或超越现有方法性能,同时训练计算量显著降低。通过解耦训练策略和原生 CLIP 潜在空间对齐,Bifrost-1 在 ImageNet 和多模态基准测试中展现出优异的视觉生成质量与理解能力平衡,为统一多模态生成与理解模型提供了高效解决方案。
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.05954
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.05954
(36) ViExam: Are Vision Language Models Better than Humans on Vietnamese Multimodal Exam Questions?

论文简介:
由KAIST等机构提出了ViExam,该工作通过构建包含2548道越南语多模态考试题的基准测试集,首次系统评估了视觉语言模型(VLMs)在低资源语言教育场景中的推理能力。研究发现:(1)当前最先进VLMs(如o3)在7个学术领域(数理化生地、驾照、智商测试)的平均准确率为57.74%,低于人类考生平均分66.54%;(2)具备推理能力的o3模型以74.07%的准确率超越人类平均表现,但仍显著低于人类最优表现(99.6%);(3)模型在地理(72%)和物理(44%)领域表现差异显著,显示学科特性影响推理难度;(4)跨语言提示(英文指令+越南语内容)对开源模型提升2.9%但使闭源模型下降1.05%,揭示语言内容错位问题;(5)人类专家协作(OCR修正+图像描述优化)可使模型表现提升5.71个百分点,验证人机协同潜力。该研究揭示了VLMs在低资源语言多模态推理中的核心挑战,为跨语言教育AI开发提供了关键洞见。
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.13680
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13680
(37) Describe What You See with Multimodal Large Language Models to Enhance Video Recommendations

论文简介:
由Spotify等机构提出了基于多模态大语言模型(MLLM)的视频推荐增强框架,该工作通过零微调方式将MLLM生成的自然语言描述注入推荐系统,有效解决了传统方法依赖低级特征导致语义缺失的问题。研究团队利用Qwen-VL等开放权重模型对视频帧和音频进行联合分析,生成包含意图、风格和文化背景的高阶语义描述(如"超级英雄模仿剧,包含闹剧式打斗和管弦乐突起"),并将其与先进文本编码器结合输入至协同过滤、内容推荐及生成式模型。在模拟TikTok风格视频交互的MicroLens-100K数据集上,该方法在五种代表性推荐模型中均超越传统视频、音频及元数据特征,其中HR@10指标相对提升最高达60%。实验表明,融合音视频的多模态描述能显著提升推荐质量,尤其对30秒以上视频效果更优。该研究不仅首次系统验证了开放权重MLLM在视频推荐中的应用潜力,还通过零微调设计降低了大规模模型适配的计算成本,同时开源提示模板及生成数据以推动领域发展。研究结果揭示了MLLM作为知识提取器在理解用户偏好深层动因(如幽默感、文化共鸣)方面的独特优势,为构建更精准的意图感知型推荐系统提供了新路径。
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.09789
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.09789
(38) HyCodePolicy: Hybrid Language Controllers for Multimodal Monitoring and Decision in Embodied Agents

论文简介:
由上海人工智能实验室、香港大学、清华大学等机构提出了HyCodePolicy,该工作提出了一种混合语言控制框架HyCodePolicy,通过闭环整合代码生成、几何感知、多模态监控和目标修复机制,显著提升了具身智能体在语言指令下的操作鲁棒性。该框架首先将自然语言指令分解为分层子目标,并基于物体几何特征生成初始程序;在模拟环境中执行时,通过视觉语言模型(VLM)监控关键检查点,结合程序执行日志与视觉反馈定位失败原因并进行代码修复。核心创新在于构建了符号日志与视觉诊断的混合反馈机制,使系统能够通过几何原语实现物理可执行的策略生成,同时通过自适应监测策略优化计算资源分配。实验表明,该方法在RoboTwin平台上的任务成功率从47.4%提升至63.9%,在Bi2Code接口下进一步提升至71.3%,且收敛迭代次数从2.42降至1.76。通过将程序视为动态假设进行持续验证与修正,HyCodePolicy实现了最小人工干预下的自我修正程序合成,为复杂环境中的自主决策提供了可扩展的多模态推理方案。
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2508.02629
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02629
(39) MAESTRO: Masked AutoEncoders for Multimodal, Multitemporal, and Multispectral Earth Observation Data
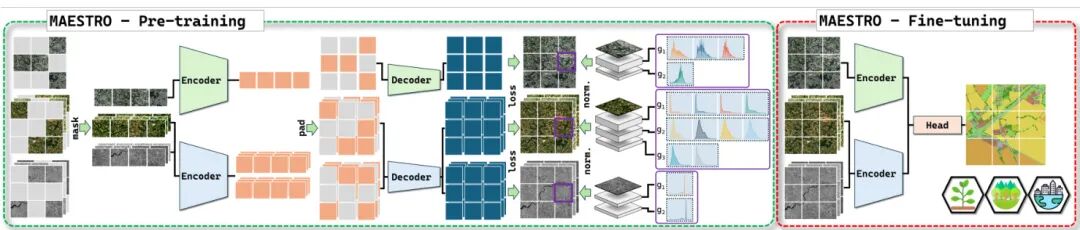
论文简介:
由IGN和巴黎文理研究大学等机构提出的MAESTRO,该工作针对多模态、多时相和多光谱地球观测数据特性,改进了掩码自编码器(MAE)框架。核心贡献包括:1)提出基于时间步和相似模态的早期融合、不同模态间晚期融合的混合策略,平衡模态特异性和跨模态协同;2)创新性地采用patch-group-wise归一化,通过光谱波段分组实现有效的重建目标归一化,在保持计算效率的同时注入光谱先验;3)在TreeSatAI-TS和PASTIS-HD数据集上分别取得2.7%和2.5%的mIoU提升,展现对时序动态任务的强适应性,同时在其他数据集保持竞争力。实验表明,MAESTRO在多时相依赖任务中显著优于现有方法,其多模态融合策略揭示了跨模态协同的局限性,为遥感自监督学习提供了重要设计启示。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.10894
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.10894
(40) A Coarse-to-Fine Approach to Multi-Modality 3D Occupancy Grounding

论文简介:
由浙江大学等机构提出了Talk2Occ基准和GroundingOcc模型,该工作首次将体素级占位预测引入3D视觉定位任务,解决了传统边界框无法精确描述不规则物体形状的问题。研究团队基于nuScenes数据集构建了Talk2Occ数据集,通过融合Talk2Car的自然语言描述与Occ3D的体素标注,实现了15类障碍物的精准空间定位。GroundingOcc模型采用多模态编码器提取图像、点云和文本特征,创新性地引入2D定位模块和深度估计模块,通过几何监督优化体素预测。实验表明,该方法在Talk2Occ数据集上Acc@0.25指标达到32.68%,较基线模型提升18.13%,在复杂场景下对挖掘机等非规则障碍物的定位精度显著提升。研究提出的几何监督损失和多模态融合策略,为自动驾驶系统的精细化空间理解提供了新范式,相关代码和数据集已开源。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.01197
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01197
(41) Collaborative Multi-Modal Coding for High-Quality 3D Generation

论文简介:
由新加坡南洋理工大学、上海人工智能实验室等机构提出了Collaborative Multi-Modal Coding for High-Quality 3D Generation,该工作提出了TriMM模型,首个基于多模态数据(RGB、RGBD、点云)的前馈式3D生成模型。核心贡献包括:1)协同多模态编码技术,通过模态特异性编码器和共享解码器,将多模态数据映射到统一三平面(triplane)潜在空间,保留RGB的纹理细节和点云/深度图的几何优势;2)引入2D图像空间(RGB/深度/掩码损失)与3D几何空间(SDF损失)的混合监督,提升多模态编码的鲁棒性;3)基于多模态编码构建生成框架,通过重建损失引导模型规避模态缺陷(如RGB几何模糊、点云纹理稀疏),增强3D生成质量;4)实验表明,TriMM在Objaverse、GSO等数据集上,仅用8万训练数据即可超越使用50万数据的SOTA方法,在纹理(PSNR)和几何(CD/F-Score)指标上均领先,且支持将RGBD等多模态数据扩展为3D triplane,为解决3D数据稀缺提供新范式。
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.15228
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15228
(42) Platonic Representations for Poverty Mapping: Unified Vision-Language Codes or Agent-Induced Novelty?
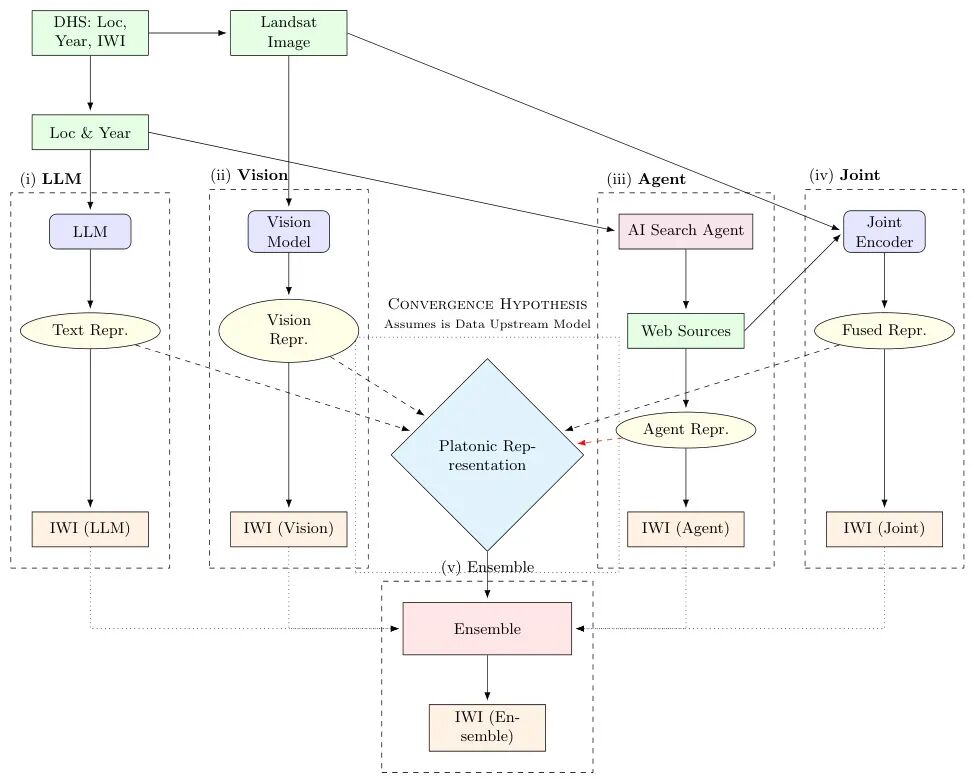
论文简介:
由UT Austin、Fraunhofer Center和Chalmers & Linköping University等机构提出了Platonic Representations for Poverty Mapping,该工作通过融合卫星影像和语言模型生成的文本数据,构建了预测非洲家庭财富水平的多模态框架。研究利用Demographic and Health Survey(DHS)数据,将高分辨率Landsat影像与大语言模型(LLM)生成的地理位置描述、AI代理检索的互联网文本相结合,开发了包含视觉模型、LLM预测、AI代理检索、联合编码器和集成模型的五种预测管道。
核心贡献包括:第一,实验表明融合视觉和语言模态可显著提升财富预测性能(R²=0.77 vs. 0.63),其中LLM内部知识(人工神经记忆)比AI代理检索的动态文本更有效,且在跨国家/时间的泛化任务中表现更稳健。第二,通过分析模态间表征收敛性,发现视觉与语言嵌入在对齐后中位余弦相似度达0.60,部分支持柏拉图表征假设(共享物质福祉潜在表征),但AI代理数据带来的增量收益有限,仅在特定场景下体现微弱的新颖性。第三,研究团队发布了包含6万个DHS簇的多模态数据集,每个样本关联卫星影像、LLM生成描述及AI代理检索文本。
实验采用随机分割、跨国家和跨时间三种评估策略,发现国家特异性特征对预测影响显著(跨国家测试R²下降达30%),而时间特异性影响较小。分析显示LLM仅需地理位置和年份即可生成有效文本描述,其性能接近集成模型的95%,在资源受限场景下更具实用性。研究同时指出数据采样偏差(如偏远地区覆盖不足)和代理检索文本潜在因果偏差等局限,未来工作可结合因果推理优化多模态社会经济分析框架。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.01109
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01109
(43) Multi-Agent Game Generation and Evaluation via Audio-Visual Recordings

论文简介:
由Samsung SAIL Montréal等机构提出了AVR-Eval和AVR-Agent,该工作通过音频-视觉记录(AVR)实现多媒体内容的自动化评估与多智能体生成。研究团队针对当前大语言模型(LLMs)在生成复杂交互式多媒体内容(如视频游戏)时面临的两大挑战——缺乏有效评估指标和难以利用高质量资产及反馈——提出了创新解决方案。
核心贡献包括:1)AVR-Eval评估指标,通过多模态模型对比两个内容的AVR记录,并由文本模型审查结果,实现对内容质量的自动化相对评估;2)AVR-Agent多智能体系统,结合资产库、代码生成、AVR反馈和控制台日志,通过迭代优化生成JavaScript游戏与动画;3)实验发现当前模型虽能通过多轮迭代提升内容质量,但未能有效利用人类提供的高质量资产和多模态反馈,揭示了机器与人类创作方式的根本差异。
实验表明,AVR-Agent生成的内容在79.2%的案例中优于单次生成结果,且选择最佳初始候选方案的效果优于单纯增加迭代次数。但引入资产和反馈后,仅55.5%和33.3%的案例表现出提升,凸显现有模型在资产理解和多模态反馈利用上的局限性。研究还发现Qwen3-Coder-480B和Kimi-K2-1T在代码生成任务中表现最优,而当前最先进多模态模型仍无法直接参与代码生成。
该工作为自动化游戏设计提供了新思路,但强调需要更强的多模态编码能力才能充分发挥资产与反馈的价值。研究团队开源了代码并构建了包含5个游戏和5个动画的基准测试集,为后续研究提供了基础框架。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.00632
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.00632
(44) Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval

论文简介:
由韩国高丽大学、Meta GenAI和KAIST等机构提出了BLiM框架,该工作针对多模态大语言模型(MLLM)在文本-视频检索中存在候选先验偏差的问题,提出双向似然估计方法与候选先验归一化模块(CPN)。研究发现,传统MLLM检索模型因过度依赖候选文本的先验概率(如高频短语或长文本),导致检索结果偏离实际语义相关性。BLiM通过同时建模视频到文本(P(t|v))和文本到视频(P(v|t))的双向生成过程,在四个主流基准数据集(DiDeMo、ActivityNet、LSMDC、MSRVTT)上平均R@1指标提升6.4,显著缓解了偏差问题。CPN模块通过训练-free的分数校准策略,进一步消除候选先验对似然估计的影响,在零样本和微调场景下均表现优异。实验表明,CPN在视觉问答、视频字幕生成等多模态任务中同样有效,通过减少对文本先验的依赖,提升模型对视觉内容的理解能力。该方法在保持计算效率的同时,为MLLM在跨模态检索中的应用提供了新的优化方向。
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2507.23284
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23284
(45) I2CR: Intra- and Inter-modal Collaborative Reflections for Multimodal Entity Linking

论文简介:
由华东理工大学、华南理工大学及美团等机构提出了I2CR框架,该工作针对多模态实体链接任务中图像信息滥用和单次视觉特征提取的局限性,创新性地构建了基于大语言模型的模内与模间协同反思机制。通过优先利用文本信息进行实体匹配,在模内一致性验证和模间对齐评估的基础上,动态引入多轮次多视角的视觉线索反馈,有效解决了图像数据噪声干扰和视觉特征提取不充分的问题。实验表明,该框架在WikiMEL、WikiDiverse和RichMEL三个基准数据集上分别取得92.2%、91.6%和86.8%的Top-1准确率,较当前最优方法提升3.2%、5.1%和1.6%。核心创新在于:提出文本优先的分阶段验证机制,通过语义一致性评估和跨模态对齐检查动态触发视觉信息介入;构建多模型协同的视觉线索迭代生成模块,从OCR、图像描述、密集描述和图像标签等不同维度提取补充信息;实现文本与视觉模态的解耦处理,在避免信息过载的同时提升推理准确性。该方法在保持高效推理的同时显著提升多模态实体链接的准确性,为多模态信息融合提供了新的技术范式。
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.02243
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02243
(46) Social-MAE: A Transformer-Based Multimodal Autoencoder for Face and Voice

论文简介:
由比利时蒙斯大学和美国南加州大学等机构提出了Social-MAE,该工作基于CAV-MAE架构改进并应用于社交场景,通过在大规模社交数据集VoxCeleb2上进行自监督预训练,实现了多模态情感识别和社交行为分析的突破性进展。研究团队针对原始CAV-MAE模型进行三方面创新:将视觉输入从单帧扩展为多帧序列以提升时序建模能力;采用对比学习与掩码重建联合训练策略增强跨模态关联;通过25轮epoch的自监督预训练优化模型参数。在CREMA-D情感识别数据集上,Social-MAE取得0.837的多模态F1分数,超越现有UAVM、AuxFormer等方法;在笑声检测任务中达到0.776的F1值,较监督学习基线提升显著;在人格特质预测任务中平均准确率达90.3%,验证了领域自适应预训练的有效性。实验结果表明,该模型在动态面部表情重建中能准确还原关键区域特征,尤其在眼睛和唇部细节处理上表现突出。研究证明了基于大规模社交数据的自监督预训练能够显著提升多模态模型对人类社交行为的理解能力,为情感计算和人机交互领域提供了新的技术范式。相关代码和模型参数已开源,为后续研究提供了重要基础。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17502
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17502
(47) CM^3: Calibrating Multimodal Recommendation

论文简介:
由南洋理工大学等机构提出了CM³,该工作针对多模态推荐系统中对比学习的对齐性(alignment)与均匀性(uniformity)优化失衡问题,提出通过多模态特征校准的均匀性损失函数和球面贝塞尔融合方法。研究发现,现有模型过度优化项间均匀性而牺牲用户-项对齐性,导致表征空间分布失衡。CM³通过计算项间多模态相似性得分,动态调整均匀性损失对不同相似度项的排斥力度,使得相似项在超球面空间中保持近邻关系,同时增强不相似项的分离强度。理论分析揭示了校准损失与传统均匀性损失的数学关联,并证明相似性得分对优化方向的调节作用。此外,创新性设计的球面贝塞尔融合方法通过迭代插值多模态特征,确保融合后的向量保持超球面特性,有效整合视觉、文本等异构信息。实验在Amazon和MicroLens等五个真实数据集上验证,CM³在NDCG@20指标上较SOTA方法平均提升8.56%-11.95%,在冷启动场景下优势更显著。特别地,结合多模态大语言模型(MLLM)提取的特征后,NDCG@20进一步提升5.4%,验证了校准优化策略对多模态推荐性能的显著增强效果。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.01226
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.01226
(48) The Cow of Rembrandt - Analyzing Artistic Prompt Interpretation in Text-to-Image Models

论文简介:
由米兰大学等机构提出了《The Cow of Rembrandt - Analyzing Artistic Prompt Interpretation in Text-to-Image Models》,该工作通过交叉注意力热图分析文本到图像扩散模型在生成艺术作品时对内容与风格概念的内部表征机制。研究发现,模型在无显式监督的情况下,对不同艺术提示词表现出差异化的分离特性,内容词主要影响主体对象区域,风格词则更多作用于背景纹理,揭示了生成模型对艺术概念的隐式解耦能力。
研究团队通过构建包含16,000个提示词的实验集(涵盖COCO 80类物体与WikiArt 50种艺术风格),利用Stable Diffusion XL模型生成图像并提取跨注意力热图。通过阈值分割生成二值掩码,计算内容-风格词对的IoU值(Δ=0.64),显著低于基线指标(p<0.001),证实两者空间分布的分离性。实验表明动物类内容(如长颈鹿Δ=0.43)与写实风格(如新现实主义Δ=0.39)分离度最高,而人物内容(Δ=0.03)与抽象风格(如抽象表现主义Δ=0.11)分离度最低。特别发现伦勃朗风格(Δ=-0.07)会将人物服饰纳入风格影响区域,印证了训练数据中艺术家创作特征的内化效应。
该研究通过量化分析揭示了扩散模型在艺术生成中"内容-风格"表征的动态特性,为理解生成模型的创作逻辑提供了可解释性工具。代码与可视化工具已开源,支持通过注意力热图探索提示词对图像生成的细粒度影响。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2507.23313
PaperScope.ai 解读:
https://paperscope.ai/hf/2507.23313
(49) RotBench: Evaluating Multimodal Large Language Models on Identifying Image Rotation

论文简介:
由UNC Chapel Hill的研究团队提出了RotBench,该工作通过构建包含350张手动筛选图像的基准测试集,系统评估了多模态大语言模型(MLLMs)在识别图像旋转方向上的能力。研究发现,尽管GPT-5、o3和Gemini-2.5-Pro等前沿模型能够准确识别未旋转(0°)和倒置(180°)的图像(准确率接近100%),但在区分90°和270°旋转时存在显著缺陷——所有模型均难以稳定区分这两个方向,混淆矩阵分析显示二者频繁被相互误判。提供辅助信息(如字幕、深度图、场景图等)或链式推理提示仅带来微小且不一致的性能提升,甚至可能因信息冗余导致准确率下降。通过同时展示图像的多角度旋转版本,推理模型(如o3和Gemini-2.5-Pro)的性能得到提升,而投票机制则帮助较弱模型实现跨方向的一致性改进。值得注意的是,微调虽显著提升180°旋转的识别能力(如Qwen-2.5-VL-7B-Instruct从5%升至80%),但对90°和270°的识别呈现周期性波动,暗示视觉编码器存在潜在表征瓶颈。研究进一步通过二分类实验揭示模型对顺时针与逆时针旋转的感知偏差,并通过归一化投票策略验证了多视角推理的有效性。这些结果共同表明,当前MLLMs在空间旋转推理能力上与人类存在显著差距,为改进模型的旋转感知和空间理解提供了关键方向。
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.13968
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13968
(50) MedBLINK: Probing Basic Perception in Multimodal Language Models for Medicine

论文简介:
由华盛顿大学、麻省理工学院和首尔国立大学等机构提出了MedBLINK,该工作设计了一个专门针对多模态语言模型(MLMs)医学感知能力的基准测试。研究发现,尽管当前MLMs在临床决策支持和诊断推理领域展现出潜力,但医生对AI工具的采用仍高度谨慎——模型若在图像方向判断、CT增强扫描识别等基础感知任务中出错,将直接削弱临床信任。MedBLINK包含8项临床相关任务,覆盖X光、CT、内窥镜、组织病理学和超声五种成像模式,以及牙科、胸腔、皮肤等九个解剖区域,总计1429道多选题和1605张专家验证图像。通过评估19个最先进模型(包括通用模型GPT-4o、Claude 3.5 Sonnet和医学专用模型Med-Flamingo、LLaVA-Med等),研究揭示当前模型普遍存在视觉基础薄弱问题:人类专家平均准确率达96.4%,而最佳模型Claude 3.5 Sonnet仅实现65%的准确率,医学专用模型表现甚至低于通用模型(平均43.69-47.47% vs 55.1-64.99%)。实验表明,模型在对比增强检测、特征计数等任务中频繁失败,且参数规模提升带来的性能增益有限。值得注意的是,ResNet-50等小型CNN模型在相同任务中可达98.5%以上准确率,证明任务本身难度可控,当前MLMs的缺陷源于视觉理解而非任务复杂度。研究强调,模型必须先掌握医生"一瞥即知"的感知能力(如解剖定位、深度估计),才能建立临床可信度,MedBLINK为此提供了关键评估框架。
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.02951
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.02951
(51) Refining Contrastive Learning and Homography Relations for Multi-Modal Recommendation

论文简介:
由悉尼科技大学等机构提出了REARM框架,该工作针对多模态推荐系统的数据稀疏性问题,通过改进对比学习和同构关系挖掘提升推荐效果。研究发现现有方法存在两方面缺陷:简单多模态对比导致模态共享特征噪声干扰和模态特有信息丢失,以及用户兴趣与项目共现关系未被充分挖掘。REARM框架创新性地采用元网络和正交约束策略优化对比学习,前者通过定制化变换矩阵过滤模态共享特征中的噪声,后者通过正交损失保留模态特有信息中的推荐相关特征。同时构建用户兴趣图和项目共现图,结合已有用户共现图和项目语义图进行图神经网络学习,实现用户-项目交互的多视角关系建模。在三个真实数据集上的实验表明,REARM在Recall和NDCG指标上全面超越SOTA基线模型,可视化分析证实其有效区分模态共享与特有特征的能力。该研究为多模态推荐系统提供了对比学习优化和异构关系建模的新范式。
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.13745
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.13745