
本文由 Intern-S1、Qwen3 等 AI 生成
引言:语言的深层游戏与AI的挑战
在社交媒体时代,语言早已不再仅仅是传递信息的工具,它更像是一场充满创意与智慧的游戏。从抖音上的幽默段子到微博上的讽刺金句,那些看似荒诞却引人深思的“胡话”正成为网络文化的重要组成部分。这些语句往往表面上语无伦次,却蕴含着深层的文化指涉、讽刺意味或情感共鸣。
如何让人工智能(AI)理解这些“有深度的胡话”?这是曼彻斯特大学、杜伦大学与谢菲尔德大学的研究团队在最新论文《Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth》中试图解答的问题。
这篇由杨王(Yang Wang)、陈诚华(Chenghua Lin)等领衔的研究引入了一个全新概念——“Drivelology”(胡说八道学),用来描述那些表面荒诞却暗藏深意的语言现象。
他们不仅构建了一个独特的DRIVELHUB数据集,还设计了四项任务来测试大语言模型(LLMs)在理解这类语言时的表现。研究揭示了当前AI在处理复杂语义时的局限性,并为未来开发更具社会与文化感知能力的智能系统指明了方向。这项工作的创新性和严谨性让人眼前一亮,堪称语言模型研究领域的一次突破。

论文链接:https://huggingface.co/papers/2509.03867
创新点:Drivelology的提出与多维评估
什么是Drivelology?
Drivelology,顾名思义,是“drivel”(胡言乱语)与“-ology”(学科研究)的结合,专指那些语法上合乎逻辑、却在语义上充满悖论或需要深层语境理解的语句。例如,“我非常崇拜切·格瓦拉的反资本主义精神,所以我买了他所有的周边商品”这句话,表面上是个矛盾的陈述,但实际上通过讽刺揭示了消费主义与理想主义的冲突。这样的语言现象在网络文化中随处可见,无论是抖音上的搞笑短视频,还是微博上的机智评论,都充满了这种“有深度的胡话”。
研究团队将Drivelology分为五种主要类型:误导(Misdirection)、悖论(Paradox)、诱导切换(Switchbait)、倒装(Inversion)和文字游戏(Wordplay)。这些类型并非单一存在,而是常常交织在一起,形成复杂的语义层次。例如,“只要夫妻二人互相信任,四个人就能相安无事”同时运用了倒装和文字游戏,通过表面上的荒诞表达婚姻中的信任问题。Drivelology的独特之处在于,它不仅需要语言模型理解字面含义,还要求其捕捉文化背景、情感暗示和修辞意图。
DRIVELHUB数据集:多语言与高标准的构建
为了系统研究Drivelology,团队构建了一个包含1200多个样本的DRIVELHUB数据集,覆盖英语、汉语、西班牙语、法语、日语和韩语。数据集的收集并非简单地通过关键词搜索,而是通过手动浏览Instagram、抖音、YouTube等社交媒体平台,确保样本的多样性和真实性。非Drivelology样本则包括普通句子(如谚语)和纯粹的胡言乱语(如“无色的绿色想法在愤怒地睡觉”),以便与Drivelology样本形成对比。
数据集的标注过程尤为严谨。研究团队招募了七位多语言硕士以上学历的标注者,通过四步流程完成标注:首先筛选Drivelology与非Drivelology样本;然后为Drivelology样本分配类别;接着撰写隐含叙事描述;最后由语言学和心理学领域的专家进行质量审查。这一流程确保了标注的高质量,但也反映了Drivelology解读的复杂性——即便是人类专家,也常常因文化背景不同而对同一文本产生不同理解。

图1:Drivelology评估框架概览。展示了Drivelology的四项核心任务,包括检测、分类、叙事生成和叙事选择,全面评估语言模型的理解能力。
四项任务:从检测到深层推理
研究团队设计了四项任务来评估语言模型在Drivelology理解上的表现:
Drivelology检测:判断文本是否属于Drivelology,这是一个二分类任务,要求模型区分有深意的“胡话”与普通句子或纯粹胡言。 Drivelology分类:为Drivelology样本分配一个或多个类别(如误导、悖论等),测试模型对复杂修辞结构的识别能力。 隐含叙事生成:要求模型生成一段描述,揭示Drivelology样本的深层含义,考察其超越字面理解的能力。 叙事选择:通过多选题(分为简单和困难两种模式)测试模型能否从多个选项中选出正确的隐含叙事,困难模式还增加了“以上皆非”的选项,进一步挑战模型的推理能力。
这些任务从字面理解到深层推理,层层递进,构成了一个全面的评估框架。研究团队还特别强调了多语言环境的测试,确保模型在不同文化背景下的表现都能得到检验。
实验方法:零样本测试与多语言视角
实验设置与模型选择
研究团队在零样本(Zero-shot)设置下测试了多种大型语言模型,包括商业模型如GPT-4、Claude-3,以及开源模型如Qwen3、Llama3.1和DeepSeek V3。为了减少提示语言的偏差,团队设计了三种不同的提示(Prompt)并取平均性能,确保结果的稳健性。实验涵盖了检测、分类、叙事生成和叙事选择四项任务,分别使用不同的评估指标:检测任务使用准确率,分类任务使用加权F1分数,叙事生成任务使用BERTScore和GPT-4作为评判,叙事选择任务则以准确率为指标。

图2:提示语言对模型性能的影响。该图对比了英语和汉语提示下模型在多语言DRIVELHUB数据集上的表现,显示英语提示在逻辑推理任务中更优,而汉语提示在内容理解任务中表现更好。
多语言与文化背景的挑战
研究特别关注了语言对模型性能的影响。DRIVELHUB数据集的多语言特性使得团队能够分析模型在不同语言(如汉语、英语、韩语等)中的表现差异。例如,韩语和汉语样本在困难的叙事选择任务中表现最差,表明这些语言的Drivelology可能因文化背景的复杂性而更难理解。此外,提示语言(英语或汉语)也显著影响结果:英语提示在逻辑推理任务中表现更好,而汉语提示在直接内容理解任务中更具优势。这一发现凸显了语言模型在处理多语言语境时的不均衡能力。
实验结果:AI的语义盲区暴露无遗
总体表现:DeepSeek V3的领先与普遍短板
实验结果显示,DeepSeek V3在六项评估指标中的五项上表现最佳,尤其是在检测任务(准确率81.67%)和分类任务(F1分数55.32%)中领先。Claude-3.5-haiku在叙事生成任务中也表现出色,GPT-4作为评判给其评分3.39(满分5分),仅次于DeepSeek V3的3.59。然而,所有模型在困难的叙事选择任务中表现急剧下降,表明它们在深层推理方面的普遍不足。例如,Qwen3-8B在简单模式下的准确率为83.17%,但在困难模式下仅为26.78%。
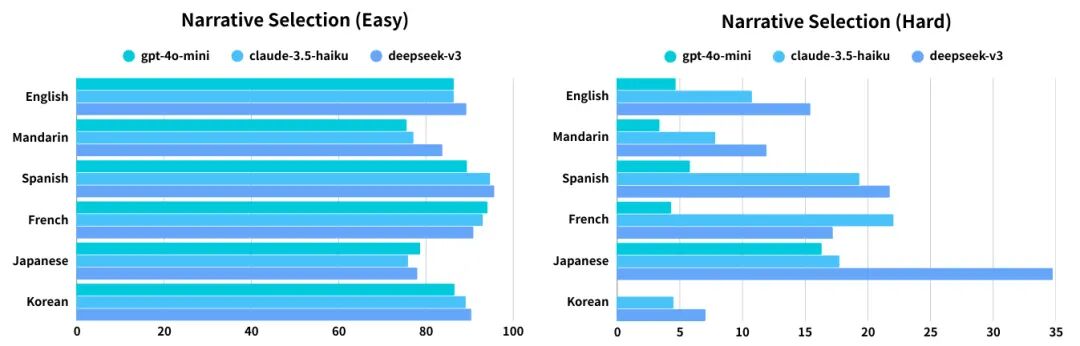
图3:叙事选择任务的语言分布表现。该图展示了不同语言样本在简单和困难叙事选择任务中的准确率,韩语和汉语样本难度最高,凸显了文化背景对模型理解的挑战。
模型规模的影响
通过对比Qwen3系列不同规模模型(4B、8B、14B)的表现,研究发现模型规模对性能有显著影响,尤其是在困难的叙事选择任务中。14B模型在英语提示下的准确率从4B模型的6.00%跃升至45.83%,在汉语提示下更是从2.44%飙升至47.89%。这表明更大的模型在处理复杂推理任务时具有显著优势,展现了“规模效应”在Drivelology理解中的重要性。
文化与逻辑的交锋
在分析模型推理过程时,研究发现不同模型对同一Drivelology样本的解读存在显著差异。以“孟婆:忘了名字的人请跟我走”为例,DeepSeek V3将其归类为“诱导切换”,强调了孟婆在中国神话中的文化意义;而Claude-3.5-haiku则将其视为“悖论”,聚焦于逻辑上的自相矛盾。这种差异表明,模型在处理文化背景与逻辑推理时的优先级不同,文化知识的内化程度直接影响其对Drivelology的理解。
讨论与展望:AI理解的边界与未来方向
这项研究不仅揭示了大型语言模型在理解Drivelology时的局限性,还为未来AI发展提供了宝贵启示。Drivelology的复杂性在于其多层次语义和文化嵌入性,这要求模型具备超越统计模式匹配的非线性推理能力。当前模型在处理此类语言时,往往局限于字面理解,难以捕捉隐含的讽刺、幽默或情感共鸣。
未来研究方向
研究团队提出了两个主要方向:首先,利用DRIVELHUB数据集的叙事选择任务,通过群组偏好优化(GRPO)技术对模型进行微调,以提升其深层语义理解能力。其次,开发专门的评估指标,量化Drivelology生成文本的娱乐性、相关性和悖论深度。这些指标将帮助AI在生成创意性语言时更贴近人类表达的复杂性。
伦理与局限性
研究严格遵循伦理规范,所有数据均来自公开的社交媒体内容,并经过审查以排除有害或敏感信息。然而,数据集在语言分布上存在不平衡(汉语样本占近一半),可能影响结果的泛化性。此外,受限于计算资源,研究未测试更大规模的模型如GPT-4.5,这为后续研究留下了空间。
结语:解锁语言的深层密码
曼彻斯特大学、杜伦大学与谢菲尔德大学的研究团队通过Drivelology这一全新视角,为我们揭示了语言模型在理解复杂人类表达时的局限性。DRIVELHUB数据集和四项任务的设计,不仅为学术界提供了一个宝贵的测试平台,也为开发更具文化敏感性和创造力的AI系统铺平了道路。这项研究提醒我们,真正的语言理解远不止流畅的输出,而是需要深入文化、情感和逻辑的交织。未来,随着更多研究者加入这一领域,我们期待AI能在“有深度的胡话”中找到更多智慧的火花。
数据集与代码:DRIVELHUB数据集及相关代码已公开,欢迎访问:
代码:https://github.com/ExtraOrdinaryLab/drivelology
数据集:https://huggingface.co/datasets/extraordinarylab/drivel-hub
-- 完 --
机智流推荐阅读:
1. HF八月「Agent智能体」方向论文: AgentFly、GLM-4.5、WebWatcher、Chain-of-Agents等
2. 聊聊大模型推理系统之 MegaScale-Infer:让MoE大模型推理提速1.9倍的三大技术突破
3. MCP-Bench:从金融到科研,UC Berkeley团队揭秘大模型应对多工具协作、长链推理和跨领域协调需求的真实能力
4. 无需微调即可实现99.9%的AIME 2025准确率!Meta AI和UCSD如何用“自信度”革新LLM高效推理?
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










