“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注!

一、被忽视的致命问题:训练中期OOD波动
数据增强是单源域泛化的常用手段,通过生成模拟数据扩展源域分布。但论文作者发现一个关键痛点:基于增强的方法在训练过程中会出现严重的目标域性能波动(训练中期OOD波动),这给实际部署中的模型选择带来巨大困扰。
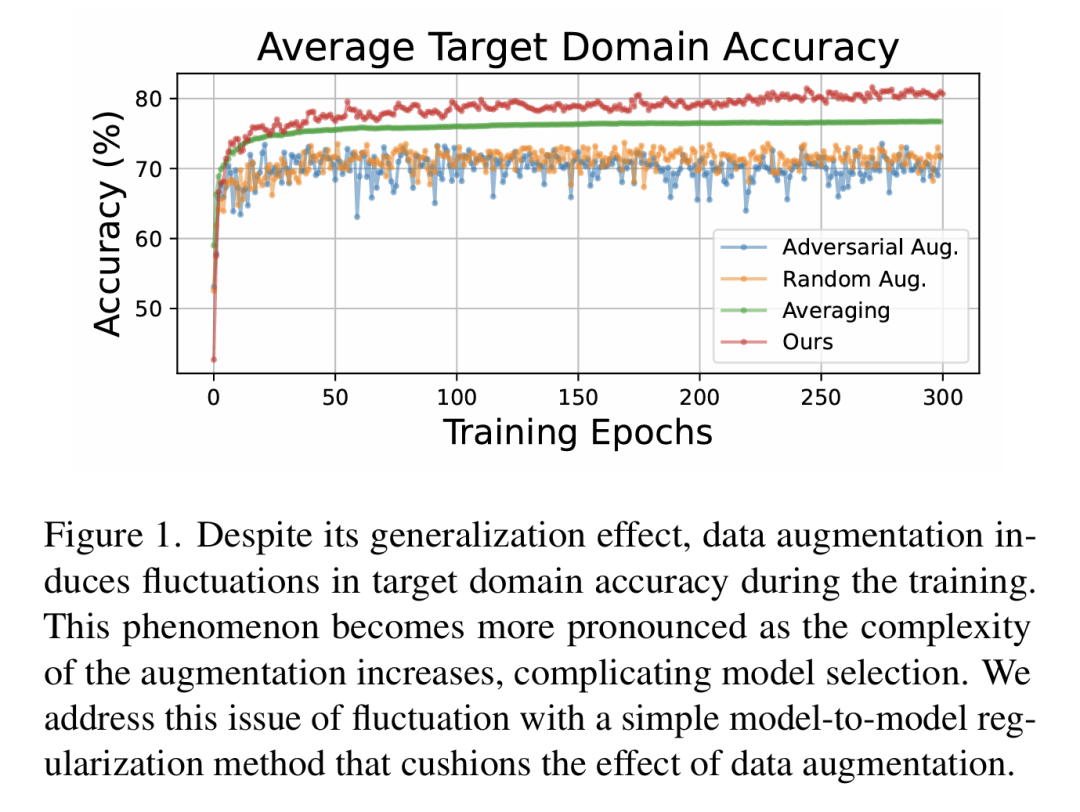
深入研究发现,波动源于特征扭曲:模型在学习多样化增强样本时,无法有效积累知识,导致先前学到的特征被新样本严重干扰。作者通过实验证实:
增强策略越复杂(如对抗增强),波动越剧烈 源域与目标域差异越大(如MNIST到SVHN),波动越明显 增强样本与原始样本的差异甚至超过源域与目标域的天然差异

这种波动不仅影响模型选择,更会显著削弱最终泛化能力。现有方法要么忽视这个问题,要么在抑制波动时牺牲性能,陷入两难境地。
二、PEER框架:双模型协作破解困局
针对上述问题,作者提出PEER(带熵正则化的参数空间集成)框架,通过两个模型的精妙协作实现知识积累与波动抑制的双赢。
核心设计:双模型交互机制
PEER包含两个同架构模型:
任务模型(F):冻结状态,负责积累知识并指导学习 代理模型(P):可训练,在任务模型指导下学习增强数据

关键创新点解析
互信息正则化
通过共享投影头映射特征,最大化任务模型(处理原始样本)与代理模型(处理增强样本)的特征互信息:
这确保代理模型学习到与任务模型兼容的特征,避免过度偏离。
周期性参数平均
每k个epoch,任务模型通过平均代理模型的历史参数更新自身:
这种参数空间集成让任务模型逐步吸收不同增强策略的知识,类似"集百家之长"。
动态增强策略
同步更新增强函数G,使模型接触更丰富的分布变化,同时通过参数平均保持学习稳定性。
三、实验验证:全面刷新SOTA性能
在四大基准测试中,PEER展现出碾压性优势,证明了其在不同场景下的鲁棒性。
标准基准测试结果
在PACS和Digits数据集上,PEER不仅平均准确率超越所有基线方法,更在多个目标域实现当前最优:
Digits数据集:比随机增强(RandAug)提升7.08% PACS数据集:比同类方法高出2.30%

挑战性数据集突破
在更难的Office-Home和VLCS上,传统增强方法甚至会降低性能,而PEER结合随机增强实现:
Office-Home:10.62%的显著提升 VLCS:6.66%的性能飞跃

波动抑制效果
通过计算目标域准确率方差,PEER在所有数据集上均显著降低OOD波动,解决了模型选择难题:
四、深度解析:PEER为何有效?
特征对齐机制
通过中心核对齐(CKA)分析发现,PEER使任务模型与代理模型的特征表示高度相似(亮色表示高相似性),证明参数平均有效保留了各阶段知识。

模型连通性提升
PEER正则化让代理模型不同训练阶段的参数空间更连通,插值时性能不降反升,验证了参数平均的有效性。
与传统方法对比
相比静态教师模型正则化,PEER的动态任务模型能更好适应新增强样本;相比无正则化的参数集成,PEER通过特征对齐避免了集成失效问题。
五、总结与展望
PEER框架以简洁而深刻的设计,解决了单源域泛化中困扰已久的训练波动问题。其核心价值在于:
首次系统揭示增强导致的特征扭曲与OOD波动的关联 创新双模型协作机制,实现知识积累与波动抑制的平衡 仅需简单随机增强即可超越复杂增强策略的性能
这一方法不仅为单源域泛化提供了新范式,更为解决更广泛的分布外泛化问题提供了重要启示。未来,PEER的思想有望扩展到半监督学习、持续学习等领域,推动更多视觉任务的泛化能力突破。
 本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!











