摘要
Abstract
EO-1模型正式亮相!这是面向通用机器人控制的开放统一具身基础模型,凭借3B参数规模的开源模型和创新的统一架构,在多个具身推理和机器人控制基准中超越现有开源模型,展现出强大的开放世界泛化能力。
项目地址:
https://eo-robotics.ai/eo-1
人类在开放世界中无缝执行多模态推理和物理交互的能力是通用具身智能系统的核心目标。EO Robotics 试图通过统一的具身基础模型 EO-Series 为自动机器人配备类似人类的无缝多模态推理和物理行为能力。
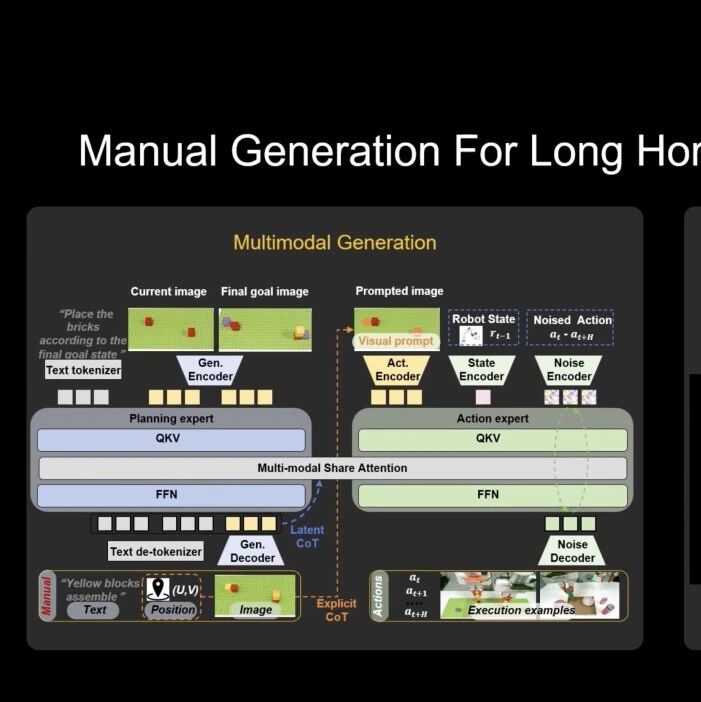
今天我们介绍 EO-1 模型,这是一个由 3B 参数组成的开源统一具身基础模型,在精心策划的交错具身数据集 EO-Data1.5M 上进行训练。EO-1 模型采用单一统一的纯解码器 Transformer,将离散自回归解码与连续流匹配去噪集成在一起,进行多模态具身推理和机器人控制,通过交错的视觉-文本-动作预训练,实现单一模型的无缝感知、规划、推理和行动。
EO-1 模型在多个具身推理和机器人控制基准中超越了现有的开源模型,包括 ERQA、LIBERO、SimplerEnv 和自建的 EO-Bench。同时,广泛的真实机器人评估表明,其在开放世界泛化中的推理能力和灵巧的控制能力大大增强。

EO-1 在具身推理和机器人控制基准方面超越了现有的开源模型。

EO-1 可以在各种机器人平台上执行各种真实世界的作任务。
专注于长视线灵巧
我们研究了 EO-1 模型专注于需要多阶段成功执行才能完成的长期灵巧任务的能力。选择四项需要复杂的多步骤决策和精细作的任务:
1) 制作早餐三明治,2) 烤牛肉牛排,3) 折叠家居服,以及 4) 分类杂货。
EO-1 在需要多模态理解和精细作的各种任务上表现出稳定而强大的长视野灵活性,展示了其处理复杂现实世界环境的能力。
新兴的开放世界具身泛化
具身基础模型的主要挑战是推广到现实场景,在这些场景中,自然语言指令必须基于精确、可执行的作。为了评估这种能力,我们使用不同的任务指令、不断变化的物体位置、动态光条件和看不见的背景进行泛化评估。我们观察到 EO-1 表现出稳定的指令遵循和开放世界的泛化能力。
通过统一推理增强泛化
为了评估一个单独交错的视觉-文本-行动策略是否能够在真实环境中将高级推理与低级控制无缝集成,我们设计了两个推理控制任务:视觉重排、井字游戏。这些任务需要在现实世界动态下进行联合感知、空间推理、多步骤规划和双手作。
EO-1 将高级具身推理与低级机器人控制无缝集成,实现需要上下文感知推理指导行动的推理控制任务的平稳、正确执行。
可访问的多模态训练数据
EO-1 在多种模态的各种数据集上进行训练,包括文本、图像、视频和机器人控制数据,以通过统一的多模态界面执行具身推理和灵巧控制。预训练数据语料库分为三大类:网络多模态数据、机器人控制数据和交错具身数据。
交错具身数据 EO-Data1.5M 数据集是一个自我策划的、海量的、高质量的多模态具身推理数据集,通过可扩展的数据构建管道进行交错具身推理和机器人控制。
数据包括 1)物理环境理解的物理常识,2)专注于复杂纵任务的任务规划和空间关系理解的任务推理和空间理解 QA 数据,以及 3)将时间/空间推理数据与机器人控制数据连接起来的交错作数据,用于学习具身交互中的多模态因果关系。



往期文章
全球首篇自动驾驶VLA模型综述重磅发布!麦吉尔&清华&小米团队解析VLA自驾模型的前世今生
字节跳动Seed实验室发布ByteDexter灵巧手:解锁人类级灵巧操作
具身专栏(三)| 具身智能中VLA、VLN、VA中常见训练(training)方法
具身专栏(二)| 具身智能中VLA、VLN分类与发展线梳理
具身专栏(一)| VLA、VA、VLN概述
π0.5:突破视觉语言模型边界,首个实现开放世界泛化的VLA诞生!
斯坦福&英伟达最新论文:CoT-VLA模型凭"视觉思维链"实现复杂任务精准操控
RoboTwin2.0全面开源!多模态大模型驱动的双臂操作Benchmark ,支持代码生成!
开源!Maniskill仿真器上LeRobot的sim2real的RL训练代码开源(附教程)
迈向机器人领域ImageNet,大牛PieterAbbeel领衔北大、通院、斯坦福发布RoboVerse大一统仿真平台
CVPR 北大、清华最新突破:机器人操作新范式,3.3万次仿真模拟构建最大灵巧手数据集
人形机器人四级分类:你的人形机器人到Level 4了吗?(附L1-L4技术全景图)建议收藏!
斯坦福最新论文:使用人类动作的视频数据,摆脱对机器人硬件的需求
爆发在即!养老机器人如何守护2.2亿老人?产业链+政策一览,建议收藏!