
点击蓝字 关注我们

欢迎各位专家学者在公众号平台报道最新研究工作,荐稿请联系小编Robert(微信ID:BrainX007); 或将稿件发送至lgl010@vip.163.com。
近期,浙江大学机械工程学院Zhang Xiangliang教授团队在Knowledge-Based Systems (KBS,Q1/1区) 在线发表题为MTSL-TimesNet: A multi-task self-supervised learning model based onTimesNet for EEG emotion recognition的研究成果。昆明理工大学Li Yongqi为第一作者,浙江大学Zhang Xiangliang为通讯作者。

成果简介
近年来,基于脑电图(EEG)的情绪识别任务引起了广泛的兴趣。目前的方法主要依靠单任务学习来提取潜在特征并构建通用模型,这可能导致模型的过拟合和泛化性较弱。为了解决该问题,本文提出了一种多任务自监督情感识别方法(MTSL-ERM)。该方法首先从原始 EEG 数据中消除基线信号,并将处理后的信号映射到大脑电极图上。将处理后的数据输入到 MTSL-TimesNet 中,这是一种基于 TimesNet 架构的新型深度学习模型。该模型通过空间拼图和对比学习任务实现跨任务知识共享和多任务优化。具体来说,空间拼图任务旨在捕获不同大脑区域的空间模式,而对比学习任务引入了一种时频增强方法,并生成实例级硬负样本来保留时间序列中的关键时间关系,从而增强模型的判别能力。该模型通过增强相似样本和重构时间序列的相似性,更好地正则化特征学习,提高了其学习数据固有模式的能力。DEAP 和 DREAMER 数据集的结果表明 MTSL-ERM 优于当前方法。DEAP 数据集上受试者相关实验中唤醒和效价的分类准确率分别为 96.30% 和 95.92%。同时,在 DREAMER 数据集上,准确率分别为 90.76 % 和 90.866%。
主要贡献
本文提出一种新的EEG情感识别(MTSL-ERM)方法,该方法利用多任务自监督深度学习模型。与传统的使用处理数据特征的情绪识别方法不同,该方法利用原始脑电图信号作为输入,并将其映射到二维脑电极网格上,然后将其输入到模型中。
引入了多任务自监督学习模型(MTSL-TimesNet),该模型通过跨不同学习任务共享特征提取器从多个维度中提取特征,从而提高无监督模型的 EEG 情感识别性能和泛化能力。
在DEAP和DREAMER数据集上进行了广泛的实验。基于无监督方法的实验结果表明,在两个数据集上,MTSL-ERM 对唤醒和效价的分类准确率均高于现有方法。
方法
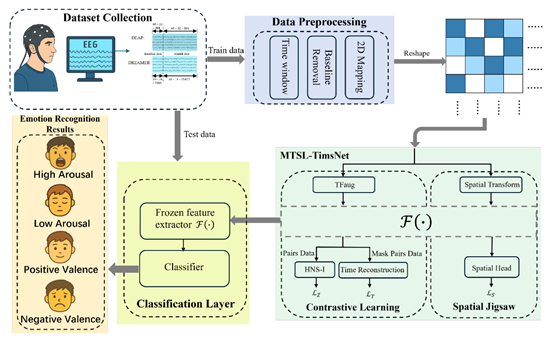
图1:基于多任务自监督学习的脑电情感识别方法的网络结构。
在技术研究的发展中,现有的方法主要面临以下关键挑战:
(1) EEG信号是典型的一维时间序列,在特征表示上存在固有的局限性。
(2) 不同个体间EEG信号存在显著差异。
(3)由于脑电信号固有的不稳定性和不可预测性,获取准确的标签和处理特征变得具有挑战性,标签噪声的问题进一步使这一过程复杂化。
(4)当前的EEG情绪检测方法没有充分利用情绪的不同特征,因为它们只关注单个特征,如时域或频域特征,而EEG电极点之间的空间关系被忽略了。

图2:MTSL-TimesNet 模型的整体架构。
本研究提出了基于多任务自监督学习(MTSL-Timesnet)的 TimesNet 网络。
(1) 为了解决第一个问题,开发了一种基于TimesNet的动态特征提取网络。通过利用时间序列周期性,将一维数据分解为周期内部和周期之间的时间变化,将其转换为二维表示。然后应用 2D 建模来捕获每个周期和跨周期的时间特征变化。
(2)为了解决第二个问题,本研究在 MTSL-Timesnet 的特征提取层中设置了不同大小的多尺度卷积核,并动态提取不同长度的特征。这种方法能够全面提取EEG信号特征,有助于消除不同受试者EEG数据的差异。
(3)为了解决第三个问题,原始信号直接用于特征提取,从而消除了特征处理的需要,完全保留了原始脑电信号中固有的时间特征,增强了模型的灵活性。此外,自监督预训练任务用于自动学习潜在特征,而不需要语义标签,克服了获取情感标签和标签噪声的挑战。

图3:(a) 对比学习任务概述,(b) 数据增强方法(TFaug). (c) 硬负样本生成技术 (HNS-I)

图4:Timesnet层的结构。
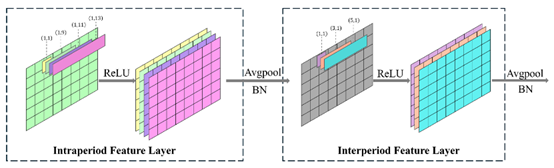
图5:使用动态卷积进行特征提取层的结构。
(4)为了解决第四个问题并提高模型的泛化能力,并考虑多任务学习中的任务相关性,本研究开发了两个自监督的预训练任务:基于图的空间拼图任务和对比学习任务。空间拼图任务侧重于信号的空间结构,而对比学习任务侧重于信号的时频动态变化。虽然这两个任务有不同的目标,但它们是互补的,有助于模型更全面地理解脑电信号的时空特征。在多任务学习中,当任务高度相关时,它们可以共享部分模型参数,从而提高模型的学习效率和泛化能力,因为情感识别需要同时考虑脑电信号的空间结构和动态特征。因此,通过共享特征提取器,这两个任务可以帮助模型学习更多集成的信息。空间拼图任务涉及重新排列脑电信号的加扰空间块,促进模型捕获信号空间特征的能力,从而提高情感识别的准确性。在对比学习任务中,使用基于频率混合的方法 (TFaug) 生成数据增强样本,并使用硬负样本生成技术 (HNS-I) 创建实例级硬负样本,帮助模型学习更高质量的频域信息。此外,采用随机掩蔽方法的时间重建模块来捕获脑电信号的时间特征。对比学习任务进一步规范化特征空间。这两个自监督的预训练任务允许模型同时捕获时空和时频特征,从多个维度中提取深层特征以进行更全面的情感识别。
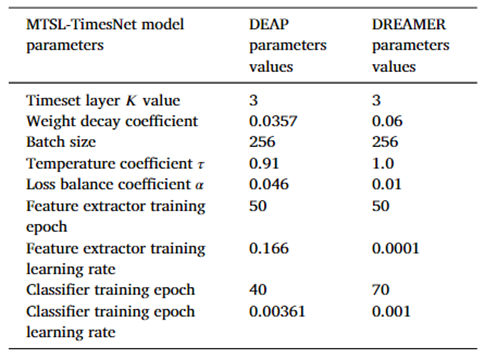
表1:参数设置。
数据库

图6:(a)DEAP数据集中构建的2D基体中的EEG电极位置,(b)从dreamer数据集中构建的2D基体中的EEG电极位置。

图7:(A)DEAP数据集中划分后的大脑区域位置排列,(B)DREAMER数据集中划分后的大脑区域位置排列。
表2:DEAP和DREAMER数据集的每个大脑区域对应的大脑电极。

表3:DEAP 和 DREAMER 数据集的结构。

结果
表4:不同方法在DEAP和DREAMER上的平均识别精度(平均值±标准差)
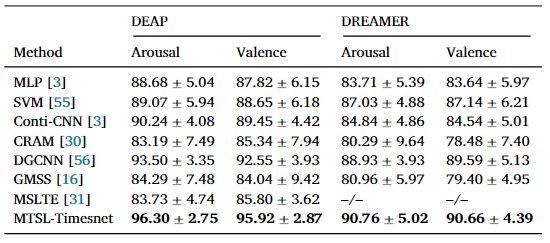

图8:DEAP数据库上不同方法对唤醒分类任务每个受试者的平均准确率(%)。

图9:DEAP数据库上不同方法对价分类任务每个受试者的平均准确率(%)。

图10:DREAMER 数据库上不同方法对唤醒分类任务每个受试者的平均准确率 (%)

图11:DREAMER 数据库上不同方法在效价分类任务上的每个主题的平均准确率 (%)
表5:与DEAP数据集上最先进的模型的比较。

表6:与 DREAMER 数据集上最先进的模型的比较。

表7:与 DEAP 和 DREAMER 数据集上不同方法的 P 值进行比较。

表8:DEAP数据集上的被试独立实验结果(%)(平均精度)。


图12:(a)和(b)分别为DEAP数据集上唤醒和效价维度的混淆矩阵,(c)和(d)分别为DREAMER数据集上唤醒和效价维度的混淆矩阵。
表9:DREAMER 数据集上的被试独立实验结果 (%)(平均精度)。

表10:DEAP数据集上不同方法的训练时间、测试时间和模型参数。


图13:DEAP数据集上不同信噪比(SNR)的数据的平均准确率(%)。

图14:t-SNE 图可视化原始 EEG 情感数据以及 MTSL-TimesNet 提取的判别特征。(a) 和 (c) 分别是唤醒维度学习前后的可视化; (b) 和 (d) 分别是价维度学习前后的可视化。
表14:受试者相关分类性能的消融分析(平均值±方差.) 在 DEAP 和 DREAMER 数据集上跨越各种模型。

研究结论
本研究设计了多任务自监督时间网络模型(MTSL-TimesNet)来提取用于EEG情绪识别的一般特征表示,提高分类精度。该模型以原始信号为输入,保持信号特征的完整性,基于多任务学习理论和自监督学习理论。它集成了多个自我监督任务,并通过这些任务获得的知识被共享以全面提取数据特征表示,从而提高模型的泛化能力、情感噪声标签的鲁棒性和从EEG信号中识别情绪的能力。所提出的深度学习模型通过空间拼图任务从EEG情感数据中提取空间特征。为了更好地提取脑电信号的时间和频率特征,对比学习任务采用一种同时利用时域和频域的数据增强方法TFaug,以及生成实例级负样本的HNS-I方法。随后,通过最大化样本相似度,进一步对特征空间进行归一化,时间重构辅助模型学习数据中的内在模式和长期的时间相关性。最终,MTSL-ERM方法在DEAP和DREAMER数据集上进行验证。在DEAP数据集上的受试者非独立测试中,唤醒和效价的平均分类准确率分别为96.30%和95.92%,而在受试者独立测试中,准确率分别为77.00%和72.38%。在 DREAMER 数据集上的被试相关测试中,唤醒和效价的平均分类准确率分别为90.76%和90.66%,而在与被试独立测试中,准确率分别为60.40% 和63.65%。实验结果表明,相对于基线方法,MTSL-ERM 实现了最先进的性能,并验证了其有效性。
免责声明:原创仅代表原创编译,水平有限,仅供学术交流,如有侵权,请联系删除,文献解读如有疏漏之处,我们深表歉意。



公众号丨智能传感与脑机接口