VLA能够利用多模态数据,近年来已逐渐成为机器人学习领域的重要方法。但现有VLA模型主要针对短程任务,在长程多步骤机器人操作任务中表现不佳,机器人往往在前几个步骤就出现错误累积,导致整个任务失败。
在长程机器人操作任务中,现有技术大概为三类:
端到端统一模型,能够在短程任务中高效学习,但面对长程复杂任务却无能为力,尤其在技能链处理上表现不佳;
任务分解方法,通过将复杂任务拆分为多个子任务,每个子任务由一个局部策略处理。这类方法降低了任务的复杂度,但由于子任务之间缺乏协调,常导致状态漂移和误差累积;
输入适配地模块化方法,分别处理运动规划与执行,虽能一定程度上缓解了技能链问题,但与 VLA模型统一、数据驱动的学习范式冲突,难以扩展。
为此,西湖大学王东林教授团队联合浙江大学、西安交通大学等提出首个专为长程机器人操作任务设计的端到端VLA模型Long-VLA。该模型引入阶段感知的输入掩码,将子任务划分为“移动阶段”和“交互阶段” ,并在不同阶段动态调整视觉模态输入,使模型能够在移动时关注全局空间线索,在交互时聚焦局部精细感知。通过这种方式,Long-VLA能够在保持统一架构和端到端学习优势的同时,有效解决了技能链问题。

在L-CALVIN基准上进行评估,Long-VLA在仿真和真实机器人任务中均优于最先进方法,且在多样化长时程任务中表现出显著优势。与Long-VLA相关的论文成果已收录于CoRL 2025顶会。

论文标题:《Long-VLA: Unleashing Long-Horizon Capability of Vision Language Action Model for Robot Manipulation》
论文链接:https://arxiv.org/abs/2508.19958
项目主页:
https://long-vla.github.io/
收录情况:CoRL 2025
1
方法
1.1 训练范式
Long-VLA将每个子任务精细分解为移动阶段和交互阶段两个阶段。为此,数据集被重新标注,形成新的L-CALVIN数据集,每条轨迹均带有明确的阶段切分点。
在移动阶段,主要涉及及空间定位与全局导航,此时第三人称视角提供更全面的环境信息,末端执行器相机视角的信息量极少,信息价值有限。
在交互阶段,机器人需要执行精确操作,末端执行器视角能提供更细致的操作细节,减轻视觉分布偏移。
为了在不同任务阶段动态调整视觉输入,提出一种输入级自适应策略,可根据当前任务阶段动态调整视觉输入。为实现跨阶段视觉输入的动态调整,采用掩码策略而非直接移除整个模态。通过此掩码策略,模型可在注意力计算中选择性关注相关标记,且不改变输入结构,从而在适应不同任务阶段的同时保持模态一致性。

在动作生成任务中,采用条件扩散模型生成动作序列。基于构建的阶段化数据集,模型通过得分匹配损失函数(Score Matching Loss)进行训练,该函数联合监督移动阶段和交互阶段的生成过程:

为确保视觉目标与语言指令在语义上一致,采用InfoNCE损失 Lgoal,总训练损失定义为:

1.2 模型架构
Long-VLA的策略  在当前观测
在当前观测  、与
、与 关联的检测输入
关联的检测输入 以及Latent目标 g 的条件下预测动作
以及Latent目标 g 的条件下预测动作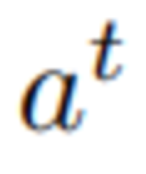 。
。
观测编码器:观测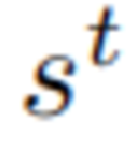 包含末端执行器相机视角和静态相机视角 ,二者分别通过ResNet-18编码为
包含末端执行器相机视角和静态相机视角 ,二者分别通过ResNet-18编码为 和
和 。
。
目标编码器:为实现对无标注交互数据的高效利用,采用策略:当无语言指令时,将未来观测 作为视觉目标;当语言标注可用时,将其作为目标。两类目标均通过冻结的CLIP模型的文本和图像编码器进行编码,分别得到
作为视觉目标;当语言标注可用时,将其作为目标。两类目标均通过冻结的CLIP模型的文本和图像编码器进行编码,分别得到 和
和  。
。
检测信息融合:为实现动态场景中精准的物体导航与交互,引入了额外检测信息。具体来说,在CALVIN数据集的子集上通过LoRA微调Grounding DINO,以实现可靠的细粒度物体定位。模型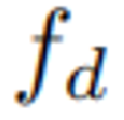 基于语言查询从第三视角图像预测像素级边界框,这些边界框通过可训练的位置编码器投影到Latent空间,得到检测特征
基于语言查询从第三视角图像预测像素级边界框,这些边界框通过可训练的位置编码器投影到Latent空间,得到检测特征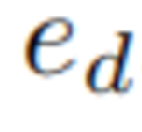 。随后,通过FiLM策略调制静态相机特征,得到增强后的检测表征
。随后,通过FiLM策略调制静态相机特征,得到增强后的检测表征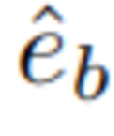 。
。
多模态编码器:模型中的多模态编码器基于GPT-2的Transformer架构。输入  定义为
定义为 即拼接所有模态特征并编码为Latent感知token
即拼接所有模态特征并编码为Latent感知token  。
。
动作解码器:采用条件扩散模型生成动作 ,通过高斯噪声逐步去噪实现反向过程:
,通过高斯噪声逐步去噪实现反向过程:
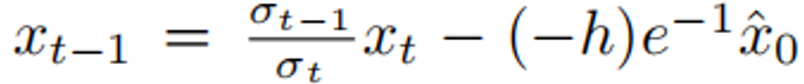
经扩散模型解码后,输出通过两层带GELU激活函数的多层感知器(MLP)映射为动作向量。
2
实验
实验围绕以下三个核心问题展开:
Long-VLA如何增强基础策略?
Long-VLA与当前最先进(SOTA)方法相比如何?
Long-VLA的关键设计组件有哪些?
2.1 实验设置
仿真与真实环境实验:选择CALVIN作为仿真平台,该平台专注于长程任务研究。基于CALVIN的数据协议,进一步提出了L-CALVIN新基准,将任务序列从5步扩展至10步。此外,设计了两类真实世界任务:(1)将积木按顺序放入碗中,序列长度为8;(2)复杂的厨房清洁任务,序列长度为4。前者侧重于长程依赖关系,后者侧重于复杂动作执行,从而全面评估模型执行长程任务的能力。

2.2 仿真场景测试
将Long-VLA和基线模型MDT,在L-CALVIN基准上进行测试,实验结果如图4所示。

实验结果表明,Long-VLA在D→D和ABCD→D任务上均显著超越基线模型。随着任务时间跨度增加,性能增益更为明显,在D→D任务的第9步和第10步,增幅分别为100%和81%。上述结果是在已见过的环境测试的,为评估模型的泛化能力,研究人员进一步在真实环境中未出现过的新设定下进行了测试。
2.3 真机测试
整理任务
为评估模型在长程任务中的基本能力,将物体整理任务作为测试场景。该任务相对简单,仅包含若干个积木块和一个碗,视觉冗余信息极少,能有效检验模型执行长程任务的基础能力。实验结果如图5所示。

实验结果表明,基线模型在第7个步骤后成功率降为零,而Long-VLA在所有8个步骤仍保持25%~45%的成功率。Long-VLA模型和基线模型相比,其优势随任务步骤增长而直线上升,体现出在长程任务中的鲁棒性。
清洁任务
清洁任务包含更多样的动作(如按压、抓取和放置)和更多干扰信息,这对长程的任务能力也更具挑战性、更具代表性。实验结果如图6所示。Long-VLA模型在所有时间跨度上均显著优于基线。特别是,在清洁任务中,性能提升幅度甚至超过整理任务中的相应值,表明Long-VLA在处理视觉干扰和复杂环境时优势显著,这归功于所提出的长程自适应范式。

2.4 当前最优方法(SOTA)对比
Long-VLA在D→D”任务中,连续完成任务序列数最高为4.75,显著优于其他SOTA方法(GR-1:2.96;RoboVLMs:2.88),平均任务链长度相对次优方法提升60%以上,体现出很强的泛化能力。

在真实机器人实验中,Long-VLA在泛化任务优于目前最先进的方法π0。

3
总结
本论文提出了一个专为长程机器人操作任务设计的端到端VLA模型Long-VLA。该模型通过阶段感知输入掩码策略,有效解决了技能链接这一核心难题,将每个子任务精细分解为移动阶段和交互阶段两个阶段。
在L-CALVIN基准与真机实验中,该方法突破了现有VLA模型的在长程操作任务泛化的瓶颈,实现了执行复杂任务的鲁棒性,在长程任务中显著优于π0。
END
智猩猩矩阵号各专所长,点击名片关注