编辑:张倩
只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。

图源:https://x.com/rohanpaul_ai/status/1966820906916815156
键值缓存(KV cache)已经成为大模型快速运行的核心技术,它就像一个「记忆库」,能够保存之前计算过的结果并重复使用,这样就不用每次都重新计算同样的内容。
但是,这个记忆库有个问题:输入的文本越长,需要的存储空间就越大,而且模型处理长文本时会变得非常慢。
为了应对这些挑战,现有的 KV cache 压缩方法主要依赖基于规则的启发式方法。当前的方法可以归类为三种范式:
跨所有层的固定位置信息保留
基于注意力权重的均匀层级分配淘汰机制
具有预定义深度衰减的金字塔策略
虽然这些方法在降低内存占用方面有效,但它们未能考虑两个关键问题:
transformer 层在信息处理中的不同功能角色
缓存与任务性能之间的动态关系
仅依赖基于规则的 KV cache 预算分层分配,可能导致任务相关信息无法被最优地保留。
针对这些限制,来自中国科学院大学、中国科学院自动化研究所的 Bohan Yu 和苏黎世联邦理工学院的 Yekun Chai 受到(Chai 等,2022)的启发,采用进化算法直接基于任务性能搜索最优的 KV cache 分配。

论文标题:EvolKV: Evolutionary KV Cache Compression for LLM Inference
论文链接:https://arxiv.org/pdf/2509.08315
他们引入了 EvolKV,这是一个进化框架,能够自适应地在 transformer 层之间分配 KV cache 预算,如图 1 所示。它将每层 KV cache 预算制定为优化变量,将其分为组,并采用进化算法迭代搜索能够直接最大化下游任务适应度得分的组别配置。通过将任务驱动优化与层特定缓存剪枝相结合,EvolKV 实现了与不同层的不同贡献相匹配的细粒度、性能感知分配。
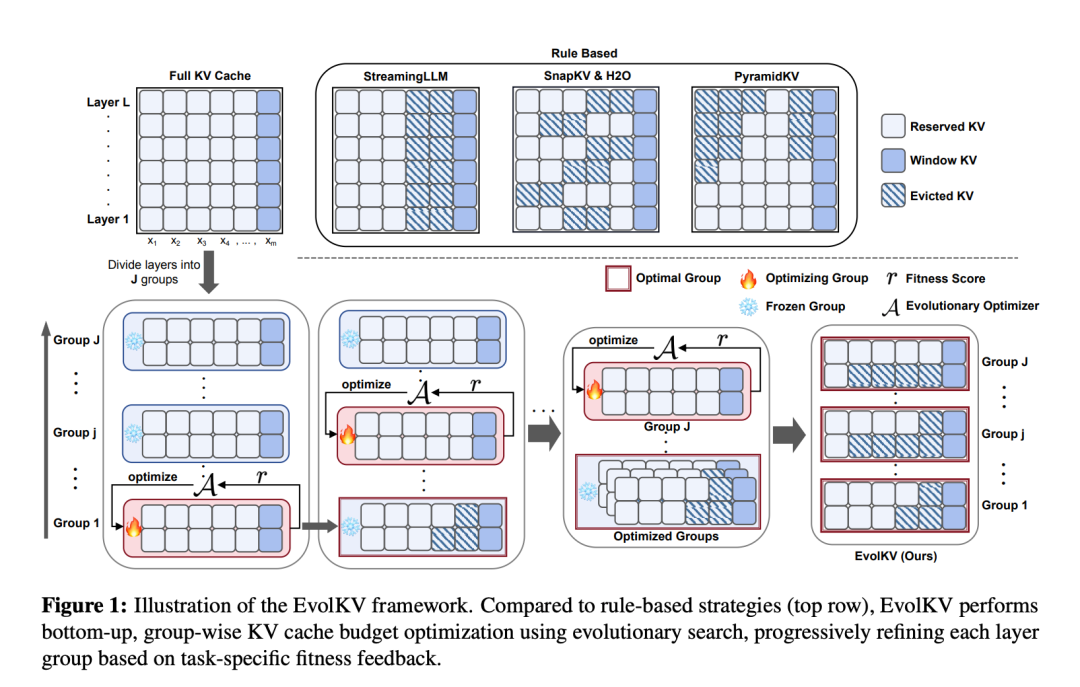
与刚性启发式方法相比,EvolKV 为以下游任务目标为导向的逐层 KV cache 预算分配提供了一个灵活而有效的机制。首先,它将层 / 组级缓存预算制定为可学习参数,其中,作者将层分组为优化单元以实现高效搜索。然后,它们使用黑盒进化优化方法直接最大化下游任务的性能。
通过这种方式,他们的方法能够实现任务感知的细粒度缓存分配,自动适应每个组或层的功能贡献。具体而言,它能够适应多样化的评估标准,如准确率和 F1 分数,并在没有预定义假设的情况下发现非均匀分布(即偏离启发式固定长度或金字塔模式的模式)。
作者在 Mistral 7B-Instruct 和 Llama-3-8B-Instruct 上进行了全面实验,在四个不同的基准测试(十一项任务)上评估 EvolKV,涵盖长上下文检索、长上下文推理和数学任务。结果表明,任务优化的 KV cache 分配产生了一致的改进:
在 Needle-in-a-Haystack 基准测试中,EvolKV 比最佳基线提高了多达 13%
在 RULER 基准测试中,EvolKV 比最强基线提升了多达 3.6%
在 LongBench 评估中,它在广泛的目标 KV cache 预算范围内(从 128 到 2048)始终优于所有基线方法,并且在仅使用完整模型 1.5% 的 KV cache 预算的情况下,其性能显著超过了完整模型。
对于 GSM8K,在 128 KV cache 预算下,EvolKV 比最强基线在准确率上提高了多达 7 个百分点,保持了完整模型性能的 95.7%,而最强基线在 512 KV cache 预算下仅保持了 84.5%。
EvolKV 详解
EvolKV 是一个动态的、任务驱动的进化框架,通过利用下游任务的性能反馈来自适应地为每一层分配 KV cache 预算。图 2a 展示了 EvolKV 与其他方法之间预算分配的比较。

进化压缩的优化目标
进化算法的工作原理是产生候选解决方案并评估它们的适应度,然后根据适应度反馈不断改进搜索策略,逐步引导整个群体朝着更好的解决方案发展。在本文中,EvolKV 将下游任务的性能反馈当作适应度分数,并利用进化算法来指导每一层的 KV cache 压缩。
具体来说,在一个有 L 个 transformer 层的语言模型中,作者用 k_i ∈ N 来表示第 i 层的 KV cache 预算,其中∀i ∈ {1, . . . , L}。给定进化算法为下游任务 f (・) 产生的一组候选压缩方案 ,他们的目标是找到最优方案 S*,这个方案既要最大化任务性能,又要尽量接近目标平均 KV cache 预算 c:
,他们的目标是找到最优方案 S*,这个方案既要最大化任务性能,又要尽量接近目标平均 KV cache 预算 c:

其中 f (S) 是使用压缩方案 S ∈  时获得的下游任务性能,超参数 λ > 0 用来平衡原始性能和缓存效率。由于下游性能指标种类繁多且数值范围不同(比如准确率、F1 分数、ROUGE 分数),作者采用了一个直接与任务性能进行权衡的缓存效率项,以确保可比性。
时获得的下游任务性能,超参数 λ > 0 用来平衡原始性能和缓存效率。由于下游性能指标种类繁多且数值范围不同(比如准确率、F1 分数、ROUGE 分数),作者采用了一个直接与任务性能进行权衡的缓存效率项,以确保可比性。
缓存效率项 CACHESCORE (S, c) ∈ [0, 1] 的工作机制是:如果某个方案的平均每层缓存预算
 超过了目标预算 c,就给它较低的分数;对于那些保持在目标范围内的方案,则应用平滑折扣:
超过了目标预算 c,就给它较低的分数;对于那些保持在目标范围内的方案,则应用平滑折扣:

其中 γ ∈ (0, 1] 是平滑因子。因此,这个目标函数偏好那些提供强大任务性能且将平均 KV cache 预算保持在接近或低于期望预算的压缩方案。
KV Cache 预算的分组
为了提高优化效率,作者引入了组大小参数 n_g,将 KV cache 预算 K = {k_1, k_2, . . . , k_L} 划分为 J = ⌈L/n_g⌉个组,记为 G = {g_1, g_2, . . . , g_J}。每个组 g_j 包含连续的缓存预算子集,定义为 g_j =  ∀_j ∈ {1, 2, . . . , J}。
∀_j ∈ {1, 2, . . . , J}。
为简化起见,作者假设层总数 L 能被组大小 n_g 整除,即 L = J・n_g。在这种表述下,候选压缩方案 在组级别应用,记为
在组级别应用,记为 。基于下游任务性能为每个组选择的最优方案记为
。基于下游任务性能为每个组选择的最优方案记为 。这种分组表述显著减少了搜索空间,并在进化搜索过程中促进了更稳定的优化动态。
。这种分组表述显著减少了搜索空间,并在进化搜索过程中促进了更稳定的优化动态。
进化压缩的迭代过程
本文中的 KV cache 预算优化以分组方式进行,如算法 1 所示,从底层到顶层依次进行。在优化每个组时,先前优化组的 KV cache 预算被固定为各自的最优方案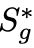 ,而其余组保持其初始值。如果候选方案 S_g 获得比当前最佳方案更高的适应度分数 r,则相应地更新当前组的 KV cache 预算。这个过程反复进行,直到所有组都被优化。
,而其余组保持其初始值。如果候选方案 S_g 获得比当前最佳方案更高的适应度分数 r,则相应地更新当前组的 KV cache 预算。这个过程反复进行,直到所有组都被优化。

KV 缓存预算补全
为了确保评估的公平性,作者对总大小偏离目标的 KV cache 预算优化结果进行补全。具体而言,他们首先计算实际总 KV cache 预算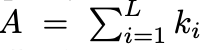 与目标总预算 T = c・L 之间的差异,记为∆_cache = T − A。然后根据各层在 A 中的原始占比,将这个差异按比例重新分配到各层。补全后的 KV cache 预算为 B = {b_1, b_2, . . . , b_L},其中
与目标总预算 T = c・L 之间的差异,记为∆_cache = T − A。然后根据各层在 A 中的原始占比,将这个差异按比例重新分配到各层。补全后的 KV cache 预算为 B = {b_1, b_2, . . . , b_L},其中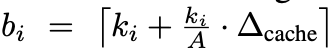 ,i ∈ {1, 2, . . . , L}。
,i ∈ {1, 2, . . . , L}。
实验结果
在 LongBench 上的结果
表 1 报告了在 Mistral-7B-Instruct 上使用 16 个 LongBench 子数据集的评估结果,所有训练样本已被移除。在所有评估的 KV cache 预算中,EvolKV 始终获得最高的平均性能,优于所有基于规则的基线方法。此外,在包括 MultiFieldQA-en、2WikiMultihopQA、MuSiQue、TriviaQA 和 PassageRetrieval-en 在内的几个子数据集上,EvolKV 不仅与未压缩的完整模型保持竞争力,甚至在某些 KV cache 预算下超越了完整模型。
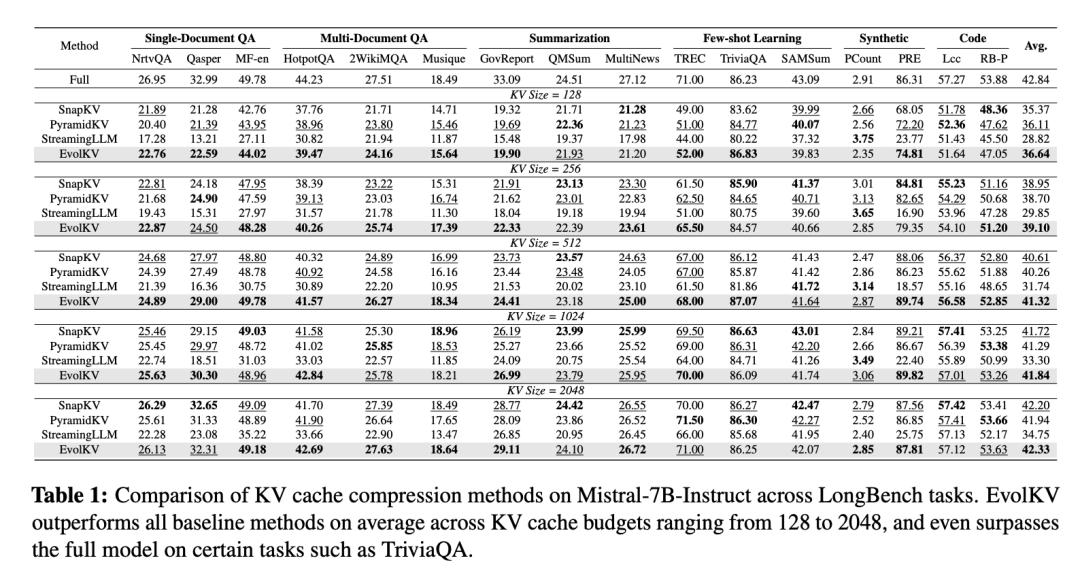
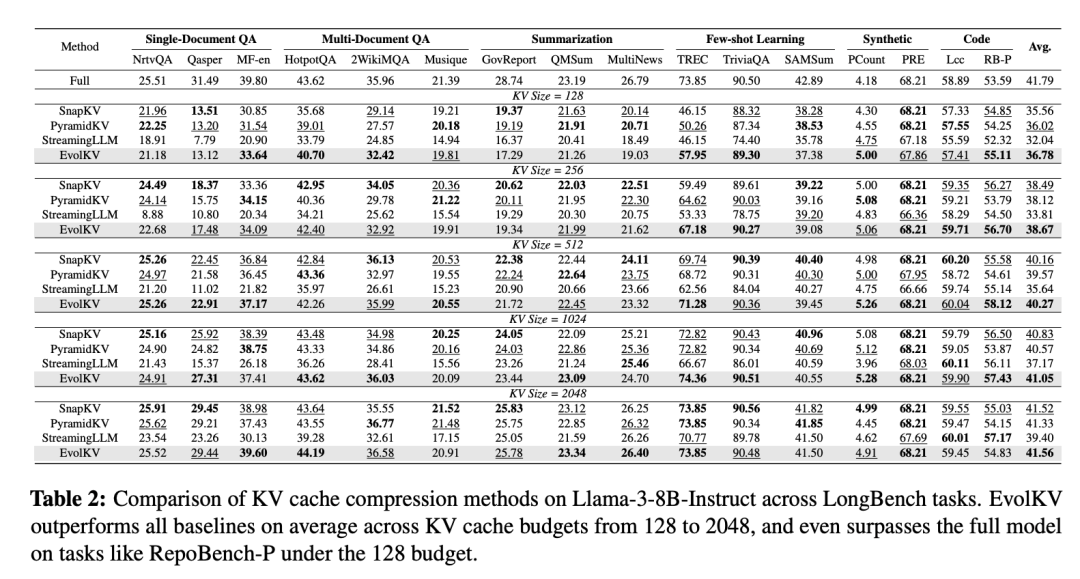
表 2 展示了 Llama-3-8B-Instruct 上的类似结果,同样排除了训练样本。EvolKV 在所有 KV cache 预算下都表现出了优异的性能。值得注意的是,在缓存预算为 128 时,EvolKV 在 TREC 子集上比最强基线高出 7.69 个百分点,突出了其对多样化下游任务的强适应性。
在 GSM8K 上的结果
图 3b 展示了 EvolKV 为 Llama-3-8B-Instruct 优化的 KV cache 预算分配。表 3 报告了 Llama-3-8B-Instruct 和 Mistral-7B-Instruct 两个模型对应的测试集准确率。在所有配置中,EvolKV 在两个模型上都始终优于基线方法。具体而言,在 Llama-3-8B-Instruct 上,它相比最强竞争对手取得了显著改进,在 KV 缓存预算为 128、256 和 512 时,准确率分别至少提升了 7.28、2.05 和 7.58 个百分点。值得注意的是,EvolKV 使用减少的缓存预算(c = 512)就达到了完整模型性能的 95.7%,显著优于所有基线方法,其中最佳基线结果仅达到 84.5%。


在 NIAH 和 RULER 上的结果
作者在 NIAH 上评估了 EvolKV 以及所有基线模型的长上下文检索能力。图 7 展示了这部分评估的结果:与基线方法相比,EvolKV 在 Llama3-8B-Instruct 上取得了超过 4 个百分点的改进,在 Mistral-7B-Instruct 上取得了超过 13 个百分点的显著提升。这些结果表明,EvolKV 有效地探索并利用了模型在长上下文检索中的潜在层级 KV cache 分配。

作者在 RULER 基准测试上进一步评估了 NIAH 中优化的 KV 缓存分配。如表 4 所示,EvolKV 在平均得分上始终优于所有基线方法,在 Mistral-7B-Instruct 上提升了多达 0.99 分,在 Llama-3-8B-Instruct 上提升了 3.6 分。这些结果进一步证明了 EvolKV 强大的泛化能力、长上下文检索和推理能力,因为优化的 KV 预算可以有效地迁移到其他基准评估中,这表明 EvolKV 揭示了潜在的层级分配策略。

更多细节请参见原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










