
上周五晚上11点,正准备下班,突然收到运维同事的紧急电话:"老哥,生产环境的实时数仓又挂了,这已经是这个月第三次了!"
我赶紧远程登录查看,果然又是老朋友——数据倾斜。看着监控面板上那条孤零零的红线,我陷入了沉思。
这些年来,我见过太多技术团队在数据倾斜面前束手无策,不是因为他们技术不行,而是因为他们掉进了认知陷阱。
今天就来聊聊数据倾斜背后那些被忽视的认知误区,以及我这些年踩坑总结出来的一些思考。

第一个认知陷阱:把数据倾斜当成纯技术问题
大部分人遇到数据倾斜,第一反应就是调参数、换算法、加机器。我之前也是这么想的,直到有一次被现实狠狠打脸。
那是在一家电商公司,我们的用户行为分析任务经常因为数据倾斜失败。团队花了两个月时间,试了各种技术方案:增加Reducer数量、调整内存配置、换Spark引擎,甚至重写了整套ETL逻辑。
结果呢?问题依然存在。
直到有一天,业务同事无意中提到:"最近我们在做用户分层运营,有个超级用户一天能产生几十万条行为记录。"
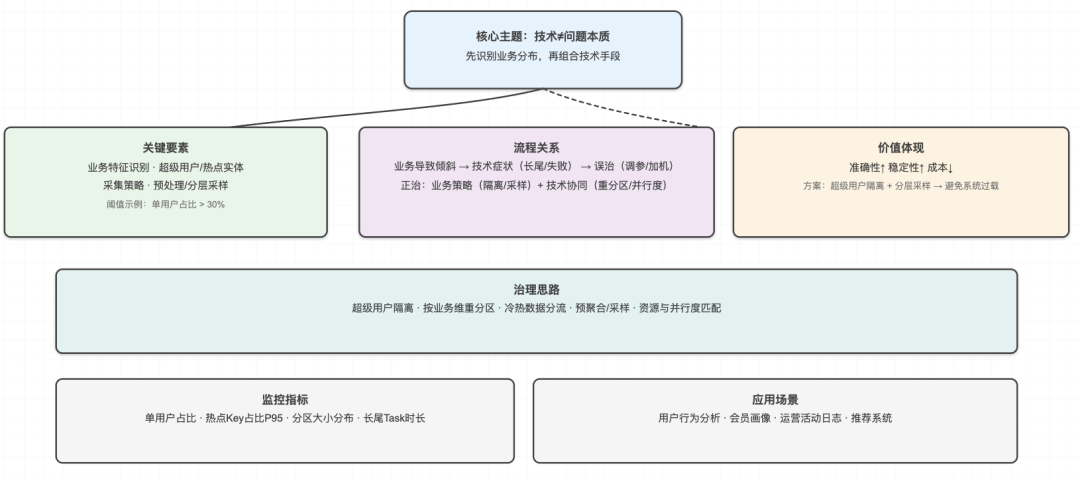
这句话点醒了我。我们一直在技术层面找解决方案,却忽略了一个根本问题:数据倾斜往往反映的是业务特征,而不是技术缺陷。
那个超级用户的行为数据占了总量的30%,这不是系统bug,而是业务现实。我们真正需要解决的,不是如何让系统处理这种倾斜,而是如何在业务逻辑中合理应对这种分布不均。
后来我们调整了策略:对超级用户的数据进行预处理和分层采样,既保证了分析的准确性,又避免了系统的过载。这个方案不仅解决了技术问题,还为业务团队提供了更精准的用户画像。
这件事让我明白:数据倾斜的根源往往在业务层面,技术只是表象。
如果你只盯着技术指标,很可能会陷入"头痛医头,脚痛医脚"的困境。
真正的高手,会从业务角度思考数据分布的合理性。
他们会问:这种倾斜是否反映了真实的业务场景?我们是否需要调整数据采集策略?业务逻辑是否需要优化?
第二个认知陷阱:过度依赖经验和直觉
"这个Key看起来数据量很大,肯定是它导致的倾斜。"
"上次遇到类似问题,就是因为Join顺序不对。"
"我觉得应该是内存不够,加点资源试试。"
这些话是不是很熟悉?我在技术群里经常看到这样的讨论。大家都在凭经验判断,却很少有人真正去量化分析问题。
我记得有一次,一个朋友找我帮忙排查数据倾斜问题。他信誓旦旦地说:"肯定是用户ID这个字段的问题,我看日志里这个字段的数据量特别大。"
我没有直接相信他的判断,而是写了一段简单的统计代码:
SELECT
user_id,
COUNT(*) as record_count,
COUNT(*) * 100.0 / SUM(COUNT(*)) OVER() as percentage
FROM user_behavior_log
WHERE dt = '2024-01-15'
GROUP BY user_id
ORDER BY record_count DESC
LIMIT 100;
结果让他大吃一惊:用户ID的分布确实不均匀,但最大的用户也只占总量的2.3%,远没有达到引起严重倾斜的程度。
真正的问题出在时间字段上。由于业务活动的影响,某个小时的数据量是平时的50倍,这才是导致倾斜的真正原因。
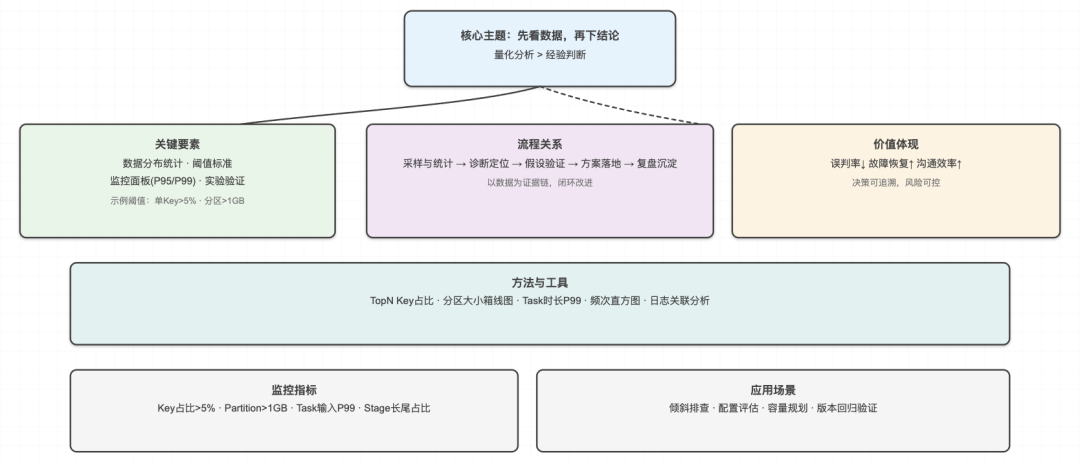
这个案例给我很大启发:数据不会说谎,但人的直觉会。在大数据领域,量化分析比经验判断更可靠。
现在我处理数据倾斜问题,都会遵循一个原则:先看数据,再下结论。
具体来说:
1. 用统计分析替代主观判断。不管多有经验,都要用数据说话。
2. 建立量化的判断标准。比如单个Key占比超过5%才算严重倾斜,单个分区数据量超过1GB才需要优化。
3. 记录和复盘每次处理过程。把解决方案和效果数据化,避免重复踩坑。
我发现,那些真正厉害的数据工程师,都有一个共同特点:他们不相信直觉,只相信数据。他们会花时间去分析数据分布,会用工具去监控系统状态,会用实验去验证假设。
第三个认知陷阱:把解决数据倾斜当成一次性工作
很多团队解决了一次数据倾斜问题后,就以为万事大吉了。这是最危险的认知误区。
我之前在一家金融科技公司,负责风控数据平台的建设。刚开始系统运行得很稳定,大家都很满意。但随着业务的快速发展,数据倾斜问题开始频繁出现。
起初我们还是用老办法:发现问题,分析原因,调整参数,问题解决。
但很快我们发现,这种"救火式"的处理方式根本跟不上业务变化的速度。
转折点出现在一次深度复盘中。我们分析了过去半年的所有数据倾斜事件,发现了一个规律:90%的倾斜问题都是由业务变化引起的。
1. 新的营销活动会带来用户行为模式的改变;
2. 新的产品功能会产生新的数据热点;
3. 业务规模的扩张会放大原本不明显的倾斜问题。
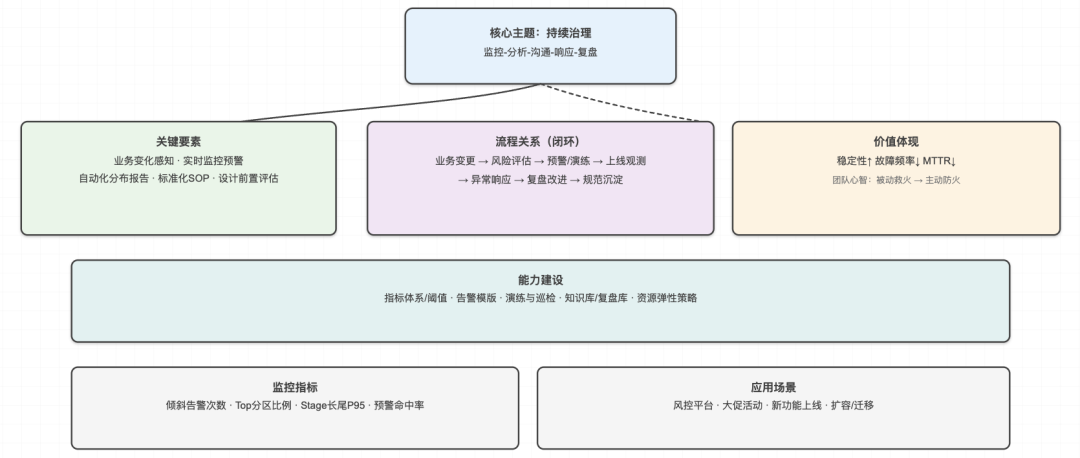
这让我意识到:数据倾斜不是一个静态的技术问题,而是一个动态的业务问题。解决它需要的不是一次性的技术方案,而是持续的监控和优化机制。
后来我们建立了一套完整的数据倾斜预防体系:
1. 实时监控系统,能够在倾斜发生前就发出预警;
2. 自动化的数据分布分析,定期生成数据健康报告;
3. 与业务团队的定期沟通机制,提前了解可能影响数据分布的业务变化;
4. 标准化的应急响应流程,确保问题发生时能够快速定位和解决。
更重要的是,我们开始把数据倾斜治理纳入到系统设计的全生命周期中。
在需求分析阶段,我们会评估新功能对数据分布的影响;在架构设计阶段,我们会考虑如何应对可能的倾斜场景;在上线后,我们会持续监控和优化。
这种转变带来的效果是显著的:系统的稳定性大幅提升,数据倾斜导致的故障从每月3-4次降低到每季度1次以下。
更重要的是,团队不再被动地"救火",而是主动地"防火"。
结语
经过这些年的实践,我发现解决数据倾斜问题的关键,不在于掌握多少技术技巧,而在于建立正确的思维模式。
真正的高手,会把数据倾斜看作一个系统性问题。他们不会孤立地看待技术指标,而是会从业务、技术、运营三个维度综合考虑。
在业务维度,他们会深入理解数据的业务含义,识别出哪些倾斜是合理的业务特征,哪些是需要优化的系统问题。
在技术维度,他们不仅会使用各种技术手段解决当前问题,更会设计可扩展的架构来应对未来的变化。
在运营维度,他们会建立完善的监控和响应机制,确保问题能够被及时发现和处理。
最重要的是,他们会把数据倾斜治理当作一个持续改进的过程,而不是一次性的任务。数据倾斜,本质上是数据世界中"不平衡"的一种表现。而在这个快速变化的时代,学会与不平衡共舞,或许才是我们真正需要掌握的核心能力。

🔗 扫描下方二维码  备注【DA】加入【大数据AI智能圈】学习交流👇
备注【DA】加入【大数据AI智能圈】学习交流👇


点击下方蓝字关注智能圈