机器之心编辑部
让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。观众看到的不再只是嘴在动,而是整个人在表演。这种表现不仅限于几个片段,而是能够稳定地延续到分钟级长视频中,在整段时间里保持动作自然、镜头流畅。
近日,快手可灵团队把这一构想带到了现实。全新数字人功能已在可灵平台开启公测,目前逐步放量中。技术报告 Kling-Avatar 与项目主页也已同步发布。报告系统解析了可灵数字人背后的技术路径,阐明如何让一个只能跟着声音对口型的模型,进化为能够按照用户意图进行生动表达的解决方案。

可灵数字人产品界面。网址:https://app.klingai.com/cn/ai-human/image/new


论文地址:https://arxiv.org/abs/2509.09595
项目主页:https://klingavatar.github.io/
首先看一些效果:
实现这些惊艳效果的背后,是快手可灵团队精心设计的一套多模态大语言模型赋能的两阶段生成框架。
多模态理解,让指令变成可执行的故事线
借助多模态大语言模型在生成与理解一体化上的能力,Kling-Avatar 设计了一个多模态导演模块(MLLM Director),把三类输入组织成一条清晰的故事线: 从音频中提取语音内容与情感轨迹;从图像中识别人像特征与场景元素;将用户的文字提示融入动作方式、镜头语言、情绪变化等要素。导演模块产出的结构化剧情描述,通过文本跨注意力层注入到视频扩散模型中,生成一段全局一致的蓝图视频,明确整段内容的节奏、风格与关键表达节点。

Kling-Avatar 方案框架。由多模态大语言模型 (MLLMs) 赋能的 MLLM Director 首先将多模态指令解释为全局语义和连贯的故事线,基于该全局规划生成一个蓝图视频,然后从蓝图视频中提取首尾帧作为条件控制,并行生成子段视频。
两阶段级联生成的长视频生成框架
蓝图视频生成后,系统在视频流中根据身份一致性、动作多样性、避免遮挡、表情清晰等条件,自动挑选若干高质量关键帧。每相邻两帧作为首尾帧条件,用于生成一个子段落。所有子段落根据各自的首尾帧并行合成,最后拼接得到完整视频。为避免首尾帧处画面与实际音频节拍的错位,方法还引入音频对齐插帧策略,保证口型与声学节奏的帧级同步。
此外,团队还精心设计了一系列训练和推理策略,保证视频生成过程中音频与口型的对齐和身份一致性:
口型对齐:将音频切分成与帧片段对齐的子段,通过滑窗方式注入音频特征;自动检测嘴部区域加权去噪损失;通过对视频帧做手动扩展,增强画面中人脸占比较小情况下的对齐效果,进一步提升口型对齐任务在远景场景下的适应能力。
文本可控性:冻结文本跨注意力层参数,避免基座视频生成模型在专门数据上过拟合而弱化文本控制。
身份一致性:在推理阶段对参考图像构造 “退化负样本”,作为负向 CFG,抑制纹理拉花、饱和度漂移等身份漂移模式。
训练与测评数据管线
为了获得多样高质量的训练数据,团队从演讲、对话、歌唱等高质量语料库中收集数千小时视频,并训练多种专家模型用于从嘴部清晰度、镜头切换、音画同步与美学质量等多个维度检测数据的可靠性。对专家模型筛选出的视频,再进行一遍人工复核,得到数百小时高质量训练数据集。
为了验证方法的有效性,团队制作了一个包含 375 个 “参考图–音频–文本提示” 的测评基准,该测评基准包含了丰富的输入样例,图片涵盖真人 / AI 生成图像、不同人种、以及开放情境中的非真人数据;音频涵盖中 / 英 / 日 / 韩等多种语言,包含不同语速和情感的台词;文本提示包含多种多样的镜头、人物动作、表达情绪控制。该测评基准为现有方法提供了极具挑战性的测试场景,能够充分评估数字人像视频生成方法在多模态指令跟随方面的能力,将在未来开源。
实验结果对比
在定量验证方面,团队精心设计了一套基于用户偏好的 GSB(Good/Same/Bad)测评体系。对每个样本,由三名评测者将 Kling-Avatar 与对比方法逐一比较,给出 “更好”(G),“一样”(S),“更差”(B) 的判断。最终汇报 (G+S)/(B+S) 作为指标,用以衡量 “更好或不差” 的占比。同时在四个维度给出分项结果:总体效果、口型同步、画面质量、指令响应、身份一致。对比方法选择最先进的 OmniHuman-1、HeyGen 等产品。
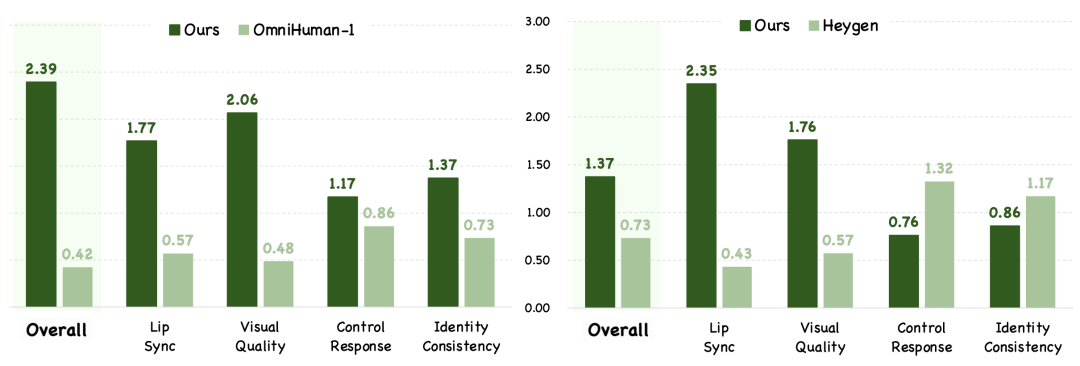

在构建的测评基准上与 OmniHuman-1 和 HeyGen 的 GSB 可视化对比。Kling-Avatar 在绝大多数维度上取得领先。

在全部 Benchmark 和各个子测评集的 GSB 指标对比。Kling-Avatar 全面超过 OmniHuman-1,并在绝大部分指标上超过 HeyGen。
在多种场景的对比测试中,Kling-Avatar 所生成的唇形不仅在时序和形态上与音频高度一致,面部表情也随着语音的起伏变化而更显自然。即使在发音难度较高的音节(如 “truth”,其标准发音为 [truːθ],[u:] 要求双唇前突、口型小而紧)或高频语音中的短暂静音段落,Kling-Avatar 均能够准确还原相应的口型状态。

在 “情绪、动作、镜头” 三类控制上,Kling-Avatar 能够更准确地体现文本提示中的意图,在歌唱、演讲等复杂场景下的动作与镜头调度更加贴合语义。下图展示了 Kling-Avatar 生成的一些视频示例,其中包含了人物的情绪控制如 “兴奋”,镜头控制如 “镜头缓慢上移”,生成结果均有良好的响应。

Kling-Avatar 的另一大优势是长时视频生成。因为采用两阶段生成 + 级联并行生成的框架,因此在首先获得蓝图视频后,可以从蓝图视频中选择任意多数量的首尾帧,并行生成每个子段视频,最后再完整拼接在一起,总生成时间理论上与一段生成时间相当,因此可以快速稳定的生成长视频。下图展示了 1 分钟长视频生成的例子,生成结果在动态性,身份一致性保持,口型等各方面都获得了令人满意的结果。

总结
从 “对口型” 迈向 “会表演”,快手可灵团队探索出一条全新的数字人生成范式,实现了在分钟级长视频中生动细腻、情绪饱满、身份一致的影视级演绎。Kling-Avatar 现已集成到可灵平台,欢迎移步可灵平台体验新版数字人应用,看看你的声音和想法如何被一镜到底地演绎出来。
近年来,快手可灵团队持续深耕多模态指令控制与理解的数字人视频生成解决方案。除了 Kling-Avatar,团队前不久还提出实时多模态交互控制的数字人生成框架 MIDAS,二者分别在 “表达深度” 与 “响应速度” 上实现了重要突破。未来,团队将持续推进高分辨率、精细动作控制、复杂多轮指令理解等方向的前沿探索,致力于让数字人的每一次表达,都拥有真实而动人的灵魂。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










