
本文由 Intern-S1、Qwen3 等 AI 生成, 由机智流编辑部校对
你是否想过,当多个不同精度的大语言模型(LLM)共享同一块 GPU 时,内存效率为何总是“打架”?量化模型明明更省显存,但实际部署中却常因KV 缓存碎片化和资源分配不均导致性能下降。如何让 FP8、INT4 等轻量模型与 FP16 大模型和谐共处,最大化吞吐并保障延迟承诺(SLO)?
近日,三星 SDS 云研究团队提出全新推理服务框架 FineServe,直面混合精度 LLM 服务中的两大核心挑战——KV 内存管理碎片化与跨模型调度低效。实验表明,FineServe 在真实负载下实现了高达 2.2 倍的 SLO 达标率提升 和 1.8 倍的 Token 生成吞吐增长,为高密度、低成本的 LLM 集群部署提供了新范式。

核心看点
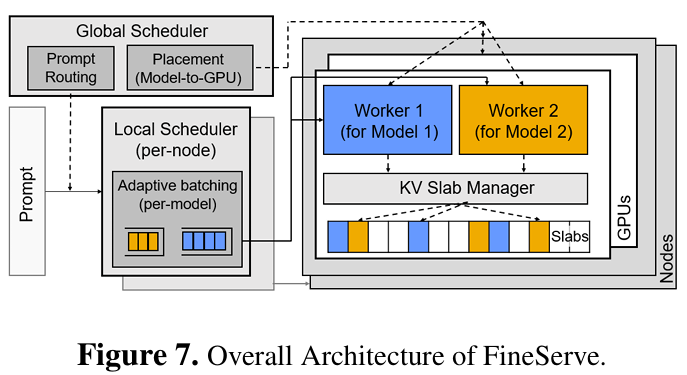
FineServe 的核心在于两项协同设计:一是KV Slab,一种感知量化精度的自适应 KV 缓存管理机制,通过预分配统一大小的“内存板”(slab),灵活适配不同精度模型的 KV 块需求,有效消除内外部内存碎片;二是两级调度器,全局调度器基于边际内存效率(MME)将模型智能分配至 GPU,本地调度器则实时预测延迟,动态调整批处理大小以保障 SLO。这两项技术共同解决了传统静态分区或虚拟内存映射方案在高并发场景下的性能瓶颈。
该框架已在 vLLM 引擎上实现,并在多达 16 块 NVIDIA H100 GPU 的集群中验证,适用于当前主流的 AWQ、FP8、QoQ 等多种后训练量化(PTQ)方案,为多租户、多模型的云推理平台提供了高效且可扩展的解决方案。
研究背景
随着大语言模型规模持续扩大,显存墙(Memory Wall)已成为制约推理性能的关键瓶颈。为此,后训练量化(Post-Training Quantization, PTQ)技术被广泛采用,通过将权重、激活甚至 KV 缓存从 FP16 压缩至 INT8、INT4 甚至 FP8,显著降低显存占用与带宽压力。然而,这也带来了新的系统级挑战。
传统服务框架如 vLLM 采用PagedAttention机制,为每个模型独立维护固定大小的 KV 块池。当多个量化程度不同的模型共存于同一 GPU 时,这种静态分区策略极易造成资源浪费——空闲模型的 KV 内存无法被其他高负载模型使用。而若采用共享内存池,则因不同模型的 KV 块大小不一,引发严重的外部碎片(external fragmentation)或内部碎片(internal fragmentation)。此外,现有调度策略往往忽视了不同精度模型在单位显存下所能生成的 Token 数量差异,导致资源分配不均衡。
FineServe 正是在此背景下应运而生,旨在构建一个真正面向混合精度环境的高效 LLM 服务系统。

核心贡献
创新方法:KV Slab 消除内存碎片
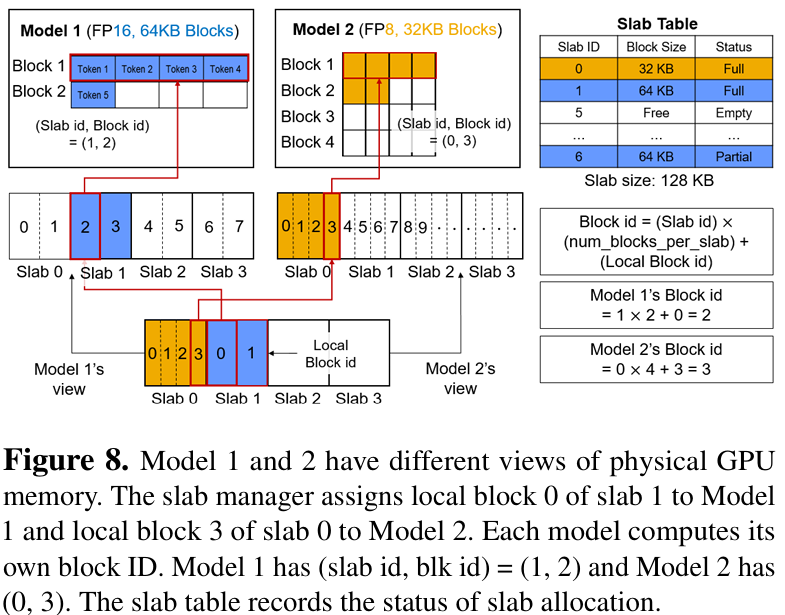
FineServe 提出了KV Slab机制,灵感来源于操作系统中的 slab 分配器。其核心思想是:在每块 GPU 上预分配一个大型共享 KV 张量,并将其划分为多个固定大小的“板”(slab)。每个 slab 可根据请求的 KV 块大小,动态格式化为若干逻辑块。例如,一个 256KB 的 slab 可被格式化为 8 个 32KB 的 FP16 KV 块,或 16 个 16KB 的 FP8 KV 块。
这一设计巧妙地解决了碎片问题:固定物理 slab 大小避免了外部碎片,而按需格式化的逻辑块则减少了内部碎片。更重要的是,所有内存映射均通过视图(view)完成,无需频繁调用 CUDA 虚拟内存管理(VMM)API,从而规避了高昂的上下文切换开销。实验显示,在高请求率下,KV Slab 相比基于 VMM 的 kvcached 库,**TTFT(首 Token 延迟)降低最高达 40%**。
理论突破:基于边际内存效率的调度准则
FineServe 引入了边际内存效率(Marginal Memory Efficiency, MME, μ)作为调度核心指标,定义为“每增加一单位 KV 内存所能额外生成的 Token 数”。量化模型(如 FP8、QoQ)因 KV 精度更低,在相同显存下能缓存更多 Token,故其 μ 值更高。
全局调度器利用 μ 值指导模型放置:在为每个模型预留基础显存(权重+平均激活/缓存)后,将剩余“竞争性”显存分配给能最高效利用它的模型组合。其评分函数score(G|M) ≈ (1/|G'|) × Σ μ_m × K_rem综合考量了组内平均效率与模型数量,确保高 μ 模型优先获得资源,同时避免单一模型垄断。
实证成果:显著提升 SLO 与吞吐

在 ShareGPT 数据集上的测试表明,FineServe 在多种场景下均大幅超越基线:
在请求率 8 倍放大、SLO 缩放因子为 20 的严苛条件下,SLO 达标率比 Prism★ 提升 2.2 倍,比静态分区方案(Static★)提升 1.2 倍。 Token 生成吞吐达到约 2300 tokens/s,较 Prism★ 提升 1.8 倍,较 Static★ 提升 1.5 倍。 大规模扩展测试中,即使 GPU 数量翻倍,Prism★ 仍无法追平 FineServe 的 SLO 表现,暗示 FineServe 可节省至少 50%的 GPU 资源以达成同等服务质量。
这些结果证明,FineServe 不仅能应对高负载波动,还能在多节点环境中保持稳定高效的性能。
行业意义
FineServe 的出现,标志着 LLM 服务系统从“粗放式共享”向“精细化运营”的重要转变。它不仅为混合精度推理这一主流技术路线提供了关键的系统支撑,更揭示了未来高效 AI 基础设施的核心逻辑——资源分配必须与模型的实际效益挂钩。
该框架的设计理念与我国推动“算力资源集约化”和“绿色低碳计算”的政策导向高度契合。通过最大化显存利用率和吞吐效率,FineServe 有助于降低大模型服务的能耗与成本,加速 AI 普惠化进程。
可以预见,类似 FineServe 的精细化调度与内存管理技术,将在未来的多模态模型编排、边缘端轻量化部署以及自动驾驶的实时感知系统中发挥关键作用,推动整个 AI 产业向更高效率、更强韧性的方向变革。
论文链接:FineServe: Precision-Aware KV Slab and Two-Level Scheduling for Heterogeneous Precision LLM Serving[1]
FineServe: Precision-Aware KV Slab and Two-Level Scheduling for Heterogeneous Precision LLM Serving: https://arxiv.org/abs/2509.06261
-- 完 --
机智流推荐阅读:
1. 万字长文解答为何LLM同问不同答?OpenAI前CTO团队最新研究让大模型结果可复现
2. VLA-Adapter:北邮等团队以0.5B参数实现机器人智能新高度,还无需预训练
3. 理解和生成让任务真的能相互受益吗,还是仅仅共存?北大&百度UAE框架,统一视觉理解与生成,实现多模态模型新突破
4. 聊聊大模型推理系统之Q-Infer技术突破:GPU-CPU协同推理提速3倍背后的三大创新
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群