一、大模型中的Transformer与混合专家(MoE)
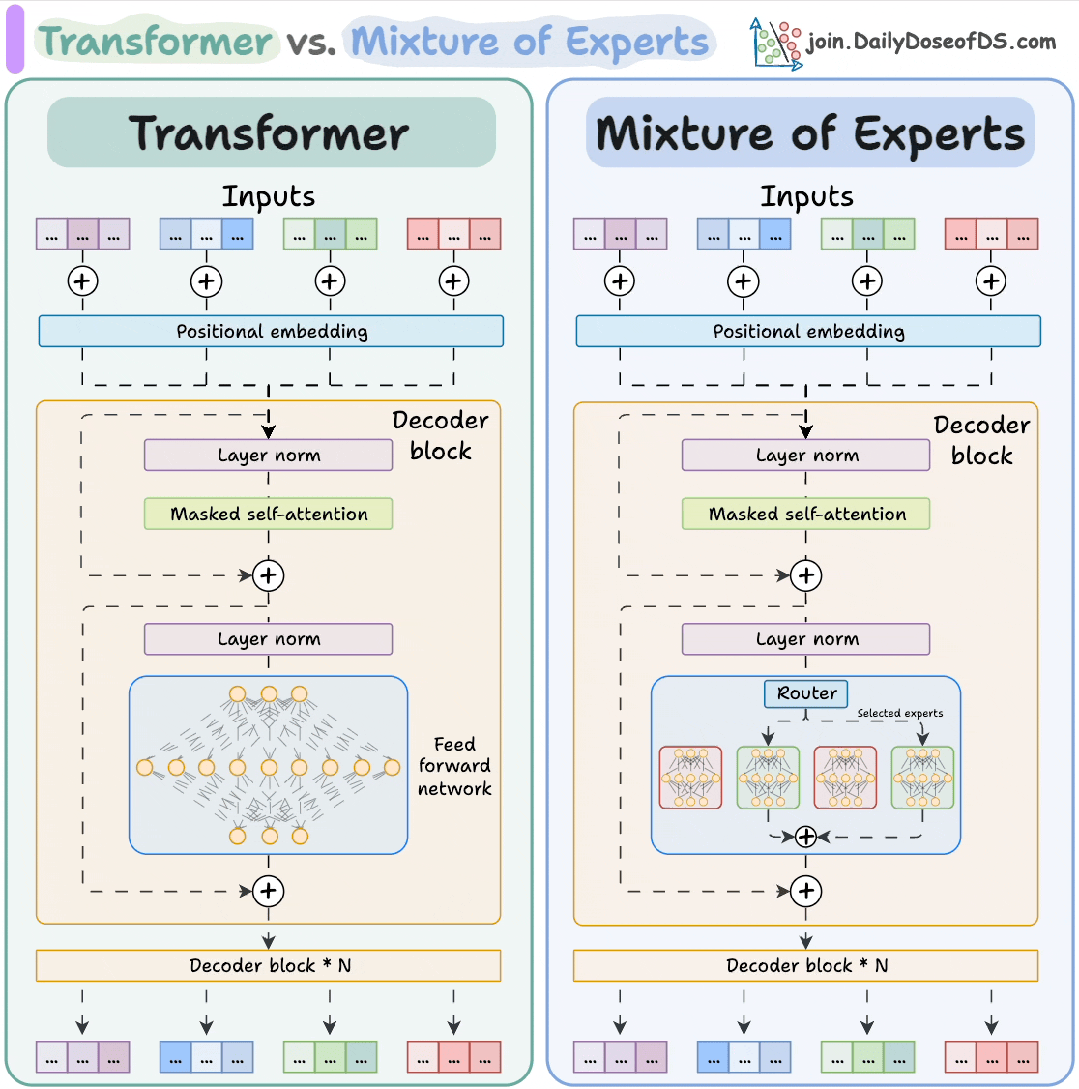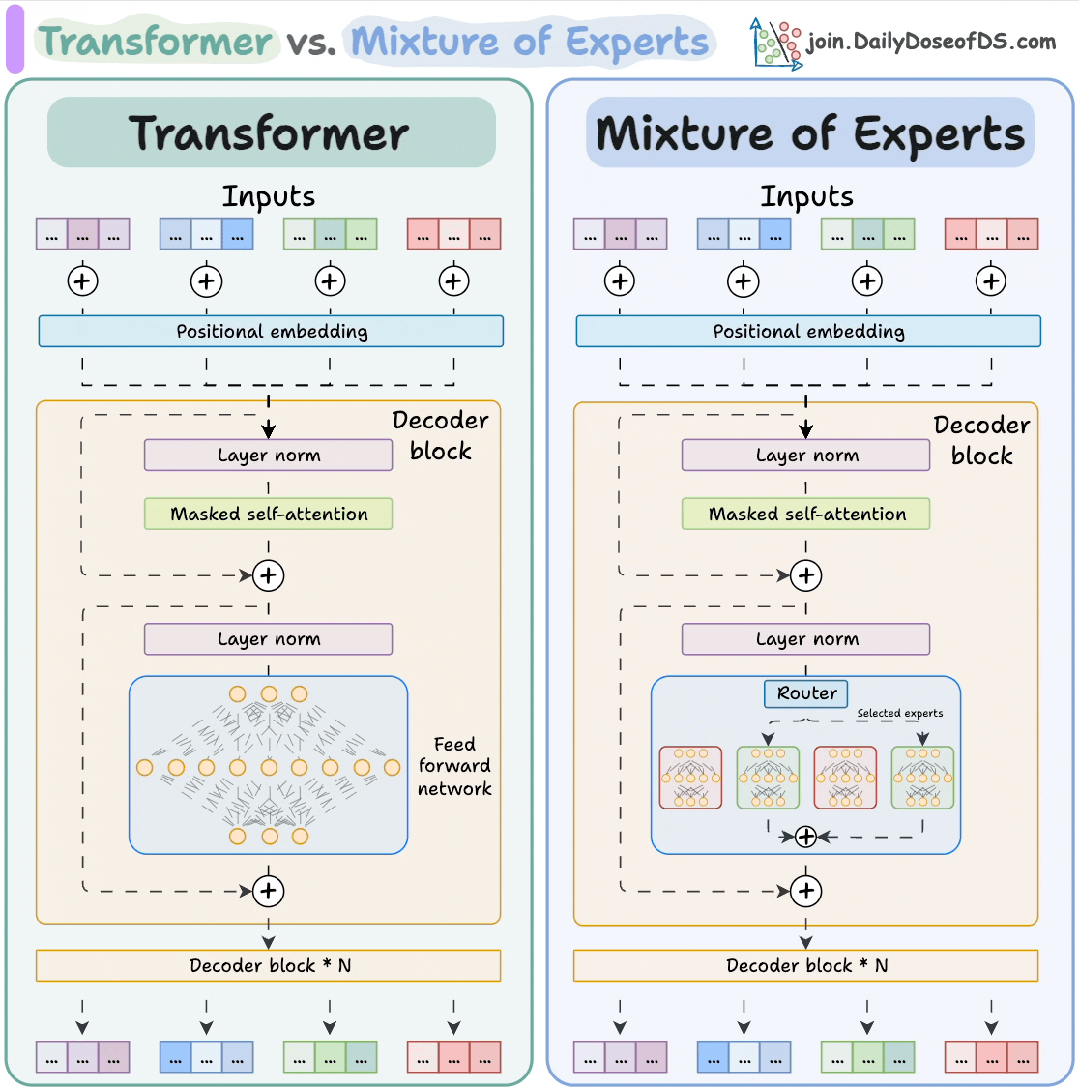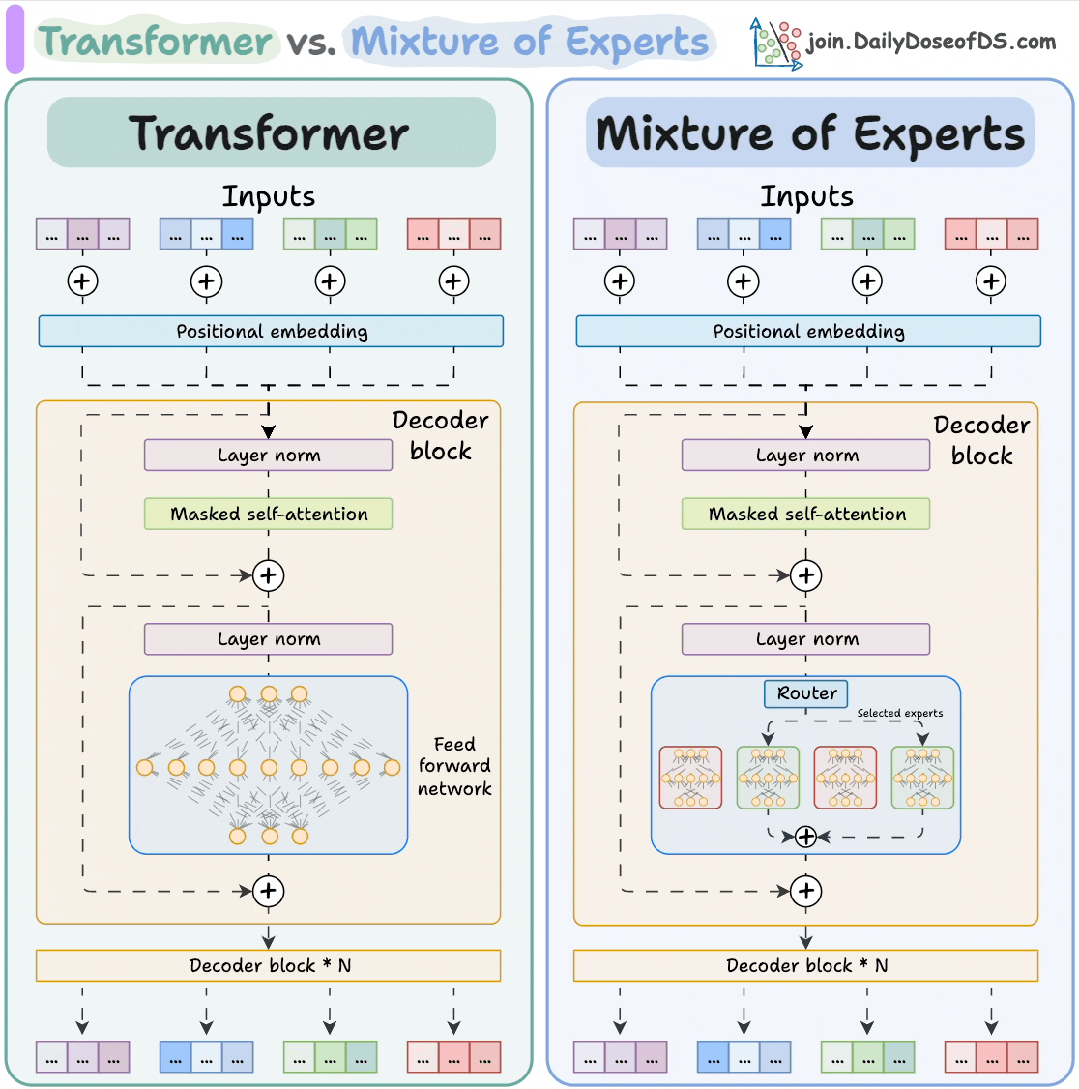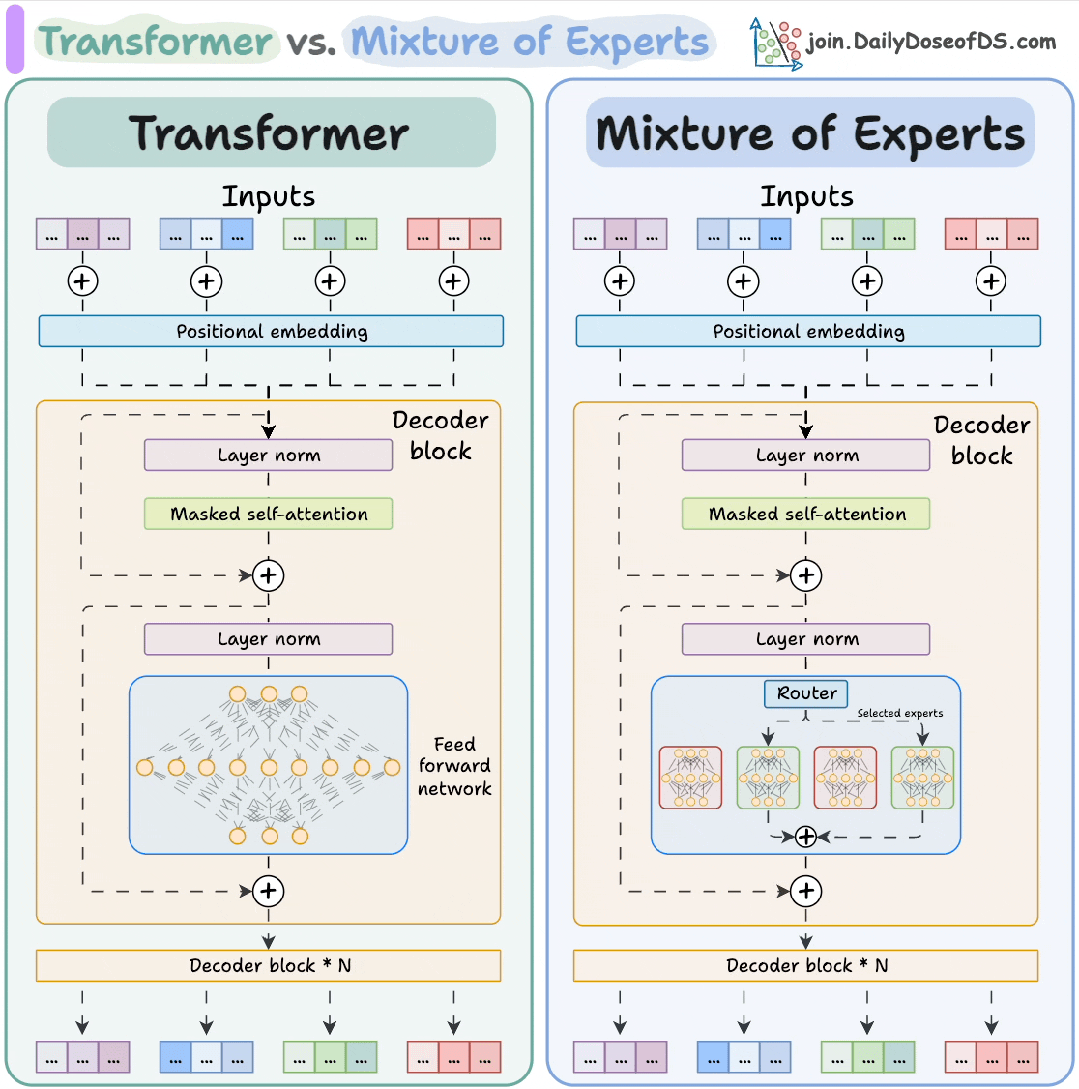
1. Transformer
核心结构:基于自注意力机制(Self-Attention),并行处理序列数据,解决长距离依赖问题。
关键组件:多头注意力(Multi-Head Attention)、前馈网络(FFN)、层归一化(LayerNorm)和残差连接。
优势:高效并行训练,适合大规模预训练(如GPT、BERT)。
2. 混合专家(MoE)
核心思想:将模型拆分为多个专家子网络(如FFN),每层动态激活部分专家(通过门控机制),显著扩展模型规模而不增加计算量。
典型应用:Google的Switch Transformer、Meta的FairSeq-MoE。
优势:计算高效(稀疏激活),支持万亿参数级模型。
3. 结合方式
MoE常作为Transformer中FFN的替代,例如MoE层替换FFN,实现模型容量与计算效率的平衡。
Transformer提供基础架构,MoE通过稀疏化计算扩展模型规模,二者结合推动大模型发展(如GPT-4、Mixtral)。
二、5种大模型微调技术

1. LoRA(Low-Rank Adaptation)
核心思想:冻结预训练模型权重,插入低秩矩阵(,秩)微调,减少参数量。
优势:显存占用低,适配多任务。
2. LoRA-FA(LoRA with Frozen-A)
改进点:固定LoRA的矩阵(随机初始化不更新),仅训练矩阵,进一步减少计算开销。
适用场景:资源极度受限时保持性能。
3. VeRA(Vector-based Random Adaptation)
核心思想:所有LoRA层共享同一对随机初始化低秩矩阵,仅学习层特定的缩放向量(逐层调整幅度)。
优势:参数效率极高(如千倍减少),适合边缘设备。
4. Delta-LoRA
改进点:在LoRA基础上,将预训练权重的增量()也纳入低秩约束,即微调。
优势:平衡参数更新与原始权重保护。
5. LoRA+
核心思想:对LoRA的矩阵AA和BB采用不对称学习率(如
 ),缓解梯度失衡问题。
),缓解梯度失衡问题。
效果:提升收敛速度与微调稳定性。
LoRA | 中 | 低 | 基础低秩适配 |
LoRA-FA | 高 | 极低 | 冻结AA矩阵 |
VeRA | 极高 | 极低 | 共享矩阵+缩放向量 |
Delta-LoRA | 中 | 中 | 低秩增量+权重更新 |
LoRA+ | 中 | 低 | 非对称学习率优化 |
应用场景:LoRA通用性强;VeRA适合超轻量化;Delta-LoRA和LoRA+侧重性能优化。
三、传统RAG与Agentic RAG对比

1. 传统RAG
核心流程
检索(Retrieval):从固定知识库中检索与输入相关的文档片段(如BM25/向量检索)。
生成(Generation):将检索结果拼接为上下文,输入大模型生成回答。
特点
静态处理:检索与生成分离,无反馈循环。
局限性:
检索结果质量直接限制生成效果;
无法动态优化检索策略;
多跳推理能力弱(需人工设计分步查询)。
2. Agentic RAG
核心思想
将RAG流程赋予自主决策能力,通过智能体(Agent)动态管理检索与生成。
关键改进:
动态检索:
基于生成内容的反馈调整检索策略(如改写查询、多轮检索);
支持复杂查询的多跳推理(自动分解子问题并迭代检索)。
任务感知:
根据任务类型(问答、摘要等)选择检索工具或生成策略;
可调用外部API或工具补充知识(如计算、实时数据)。
自我验证:
对生成结果进行事实性检查(如二次检索验证)、逻辑一致性评估。
对比总结
检索方式 | 单次、静态 | 多轮、动态优化 |
推理能力 | 单跳,依赖人工设计 | 多跳,自主分解任务 |
上下文管理 | 固定拼接 | 动态筛选与精炼 |
错误处理 | 无自检机制 | 结果验证与修正 |
适用场景 | 简单问答、文档摘要 | 复杂推理、实时交互、工具调用 |
演进本质:Agentic RAG将RAG从“管道流程”升级为“自主决策系统”,更贴近人类问题解决模式。
四、5 种经典的智能体设计模式

1. Reflection Pattern(反思模式)
核心思想:智能体通过自我评估与迭代修正优化输出。
流程:生成结果 → 分析错误/不足 → 调整策略重新生成。
2. Tool Use Pattern(工具使用模式)
核心思想:智能体调用外部工具(如API、计算器、搜索引擎)扩展能力边界。动态选择工具并解析工具返回结果。
3. ReAct Pattern(推理+行动模式)
核心思想:结合推理(Reasoning)与行动(Action)的交互式决策。
流程:
Reason:分析当前状态(如“需要查询天气”);
Act:执行动作(如调用天气API);
循环直至解决问题。
4. Planning Pattern(规划模式)
核心思想:智能体预先制定分步计划再执行,而非即时反应。长期目标分解为子任务,动态调整计划。
5. Multi-agent Pattern(多智能体模式)
核心思想:多个智能体通过协作/竞争完成复杂任务。角色分工(如管理者、执行者)、通信机制(如投票、辩论)。
五、5大文本分块策略

1. Fixed-size Chunking(固定分块)
核心思想:按固定长度(如 256 tokens)分割文本,可重叠(滑动窗口)。
优点:简单高效,适合常规 NLP 任务(如向量检索)。
缺点:可能切断语义连贯性(如句子中途截断)。
场景:BERT 等模型的输入预处理、基础 RAG 系统。
2. Semantic Chunking(语义分块)
核心思想:基于文本语义边界分块(如段落、话题转折点)。
实现:
规则:按标点(句号、段落符)分割;
模型:用嵌入相似度检测语义边界(如 Sentence-BERT)。
优点:保留语义完整性。
缺点:计算成本较高。
场景:精细化问答、摘要生成。
3. Recursive Chunking(递归分块)
核心思想:分层分割文本(如先按段落→再按句子)。
优点:平衡长度与语义,适配多级处理需求。
缺点:需设计分层规则。
场景:长文档处理(论文、法律文本)。
4. Document Structure-based Chunking(基于文档结构的分块)
核心思想:利用文档固有结构(标题、章节、表格)分块。
实现:解析 Markdown/HTML/PDF 的标签结构。
优点:精准匹配人类阅读逻辑。
缺点:依赖文档格式规范性。
场景:技术手册、结构化报告解析。
5. LLM-based Chunking(基于大模型的分块)
核心思想:用 LLM(如 GPT-4)动态决定分块策略。
方法:
直接生成分块边界;
指导规则引擎优化(如“将这段话按时间线拆分”)。
优点:灵活适配复杂需求。
缺点:成本高、延迟大。
场景:高价值文本处理(如医疗记录、跨语言内容)。
对比总结
策略 | 核心逻辑 | 优势 | 局限性 |
Fixed-size | 固定长度切割 | 高效、通用 | 语义断裂风险 |
Semantic | 语义边界检测 | 保留上下文 | 计算复杂度高 |
Recursive | 多级递归分割 | 灵活适配长文本 | 规则设计复杂 |
Structure-based | 文档标签解析 | 精准匹配结构 | 依赖格式标准化 |
LLM-based | 大模型动态决策 | 智能适应场景 | 成本高、速度慢 |
六、智能体系统的5个等级

等级 | 核心能力 | 关键特征 | 典型场景 |
Basic Responder | 单轮响应 | 无记忆,固定规则生成 | 简单问答、自动回复 |
Router Pattern | 任务分类与分发 | 意图识别+预定义路由 | 多技能助手(如小爱同学) |
Tool Calling | 调用外部工具 | 动态API调用+结果解析 | 实时计算、数据查询 |
Multi-agent | 多智能体协作/竞争 | 角色分工+通信协议 | 仿真系统、复杂任务分解 |
Autonomous | 长期目标驱动+自我优化 | 规划+反思+环境适应 | 自动驾驶、AutoGPT |

传统RAG(Retrieval-Augmented Generation)和HyDE(Hypothetical Document Embeddings)都是检索增强生成(RAG)技术的变体,但它们在检索策略和性能优化上有显著差异。以下是两者的对比:
1. 核心流程对比
检索方式 | 直接对用户查询(Query)进行向量检索 | 先让LLM生成假设答案(Hypothetical Answer),再检索相似文档 |
匹配逻辑 | Query-to-Document 相似度匹配 | Answer-to-Document 相似度匹配 |
生成阶段 | 直接使用检索到的文档生成答案 | 结合假设答案+检索文档生成最终答案 |
关键区别:
传统RAG依赖查询与文档的语义匹配,但用户问题(如“什么是ML?”)可能与答案(如“机器学习是一种方法”)表述不同,导致检索失败。
HyDE通过生成假设答案(如“ML是让计算机学习数据的方法”),使嵌入更接近真实答案的语义,从而提高检索精度。
2. 性能对比
指标 | 传统RAG | HyDE |
检索精度 | 较低(依赖查询表述) | 显著提升(如ARAGOG实验显示优于基线) |
答案质量 | 可能因检索失败而错误 | 更准确(利用假设答案引导检索) |
计算成本 | 低(仅需一次检索) | 较高(需LLM生成假设答案) |
实验数据:
OpenAI测试显示,传统RAG准确率仅45%,HyDE可提升至65%。
ARAGOG研究表明,HyDE与LLM重排序结合后,检索精度显著优于朴素RAG。
3. 适用场景
场景 | 传统RAG | HyDE |
简单问答 | 适用(如事实型问题) | 适用,但可能过度复杂 |
复杂查询 | 易失败(表述差异大) | 更优(如多跳推理) |
实时性要求 | 更高效 | 延迟较高(需生成步骤) |
4. 优缺点总结
技术 | 优点 | 缺点 |
传统RAG | 简单、计算成本低 | 检索精度受查询表述限制 |
HyDE | 检索精度高、适配复杂语义 | 延迟高、依赖LLM生成质量 |
八、RAG vs Graph RAG
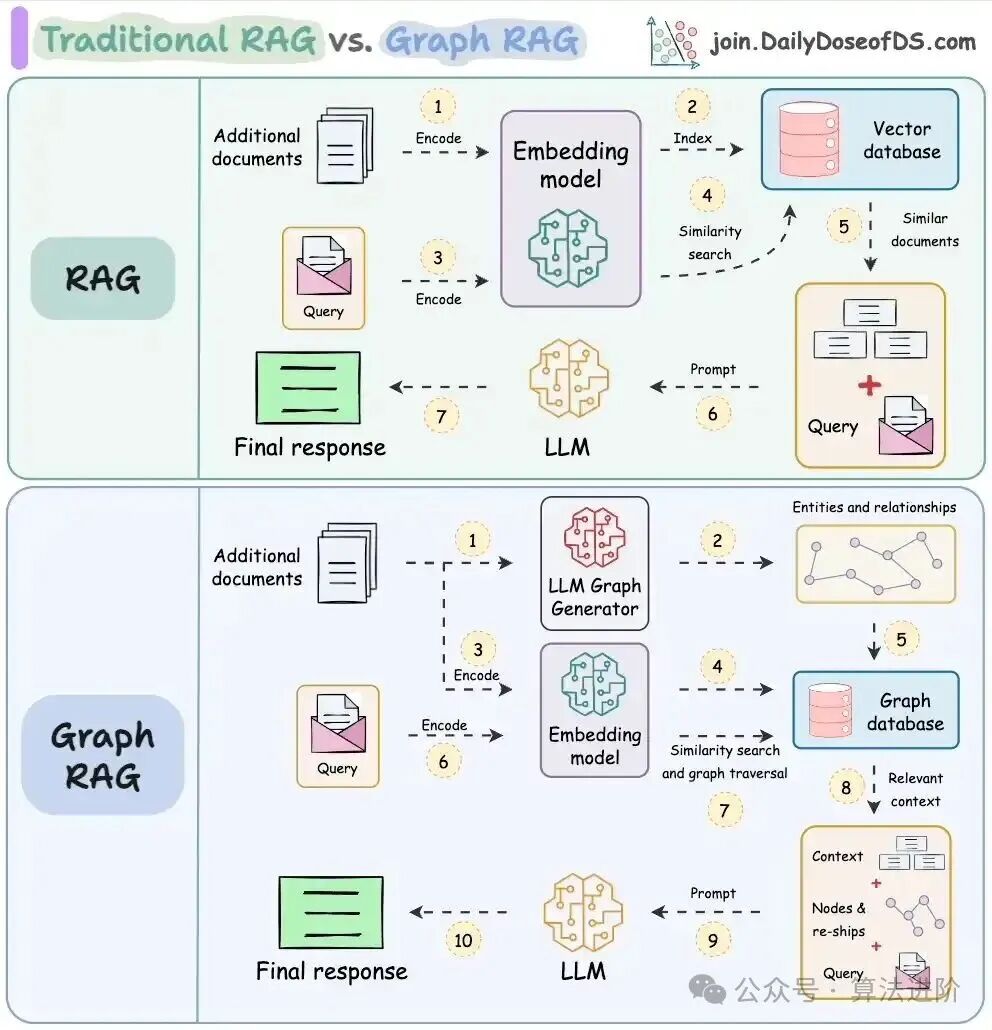
维度 | RAG(检索增强生成) | Graph RAG(图增强检索生成) |
知识结构 | 基于扁平文本(向量检索) | 基于知识图谱(图结构检索) |
检索方式 | 语义相似度匹配(如BM25/Embedding) | 图遍历(如节点关系推理、路径查询) |
优势 | 简单高效,适合事实型问答 | 擅长多跳推理、关系推理 |
缺点 | 难以处理复杂逻辑关系 | 依赖高质量知识图谱,构建成本高 |
适用场景 | 问答、文档摘要 | 复杂推理(如因果分析、事件链推导) |
核心区别:
RAG 直接检索文本片段,适合短平快问答;
Graph RAG 利用知识图谱的结构化关系,更适合需要逻辑推理的任务(如“某药物的副作用机制是什么?”)。
九、KV caching

KV Cache是Transformer推理时的关键优化技术,通过缓存注意力层计算过的键值矩阵(Key-Value),避免对历史token的重复计算,将生成过程的计算复杂度从二次方O(n²)降至线性(O(n)),显著提升大模型生成速度(3-5倍加速)。它以显存占用为代价(需存储每层的KV矩阵),成为所有主流推理框架(如vLLM、TGI)的核心优化手段,支撑了长文本生成和实时交互的高效实现。









