
题目:Think in Games: Learning to Reason in Games via Reinforcement Learning with Large Language Models
论文地址:https://arxiv.org/pdf/2508.21365

创新点
首次将“游戏思维”作为研究重点,强调在游戏场景中对玩家行为和决策的深层次理解,这与以往单纯从技术角度研究游戏 AI 或从心理学角度研究玩家行为的研究视角有所不同,为理解游戏中的复杂行为提供了新的切入点。
创造性地设计了“游戏思维”模块,该模块能够根据游戏的上下文和玩家的意图动态生成策略,这与传统的基于固定规则或简单学习算法的策略生成方法相比,更加灵活和智能,能够更好地适应复杂多变的游戏环境。
方法
本文主要研究方法是将强化学习与大型语言模型相结合,构建了一个能够学习游戏推理的模型框架。首先,设计了一个“游戏思维”模块,该模块能够根据游戏的上下文和玩家的意图动态生成策略。然后,通过强化学习对生成的策略进行评估和优化,以提高模型在游戏场景中的决策性能。在训练过程中,模型会在多个不同的游戏环境中进行训练,并引入“游戏思维”模块的动态调整机制,使模型能够学习到不同游戏场景下的通用决策策略,从而提高模型的泛化能力。
Think-In Games(TiG)框架中基于游戏状态的GRPO训练过程示意图详解

本图展示了Think-In Games(TiG)框架下使用Group Relative Policy Optimization(GRPO)算法进行训练的核心流程,直观呈现了大型语言模型如何通过与游戏环境的交互来学习战略决策并生成可解释的推理过程。在该框架中,给定一个当前的游戏状态,模型被要求预测合适的宏观行动(如“推上路兵线”或“争夺暴君”),同时在思考过程中详细阐述选择该行动的理由,这一过程模拟了人类玩家在复杂对局中的决策逻辑。模型的输出包含两个部分:一是放入
TiG框架在动作预测任务中的性能表现与错误案例分布分析

本图由两部分组成,左侧展示了不同训练方法和模型规模在动作预测任务上的准确率对比,右侧则呈现了各类模型在错误案例中的分布情况,共同揭示了Think-In Games(TiG)框架的有效性、优势来源以及潜在的改进方向。左侧的性能图表清晰地表明,采用多阶段训练策略,特别是先进行监督微调(SFT)再结合GRPO强化学习的方法,能够显著提升模型在复杂游戏决策任务中的表现。右侧的错误分布图则深入剖析了不同模型在执行任务时出错的类型构成,涵盖了如“行动不完整”、“逻辑跳跃”、“信息误读”等多种错误类别,分析显示经过TiG训练的模型不仅总体错误率更低,而且在关键错误类型上的比例也明显下降,例如在需要深度情境理解的“战略误判”类错误上表现更优,这表明该框架确实帮助模型建立了对游戏机制更深刻、更内在的理解,而非简单的模式匹配。
不同模型在强化学习训练过程中奖励得分与响应长度的动态变化趋势
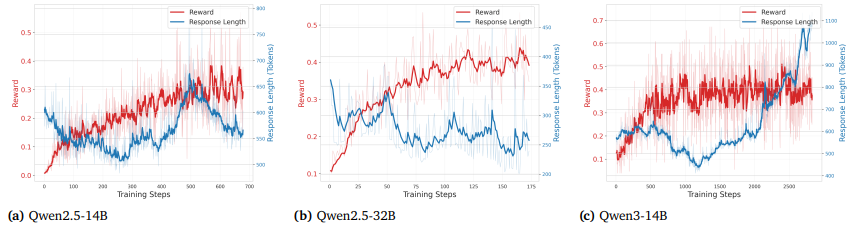
本图展示了Qwen2.5-14B、Qwen2.5-32B和Qwen3-14B三种不同规模的模型在使用GRPO算法进行在线强化学习训练时,其生成响应的长度(response length)和获得的奖励(rewards)随着训练步数推进所呈现出的动态演变过程,揭示了模型在学习策略决策过程中“思考深度”与“决策质量”之间的复杂关系。对于前两个模型Qwen2.5-14B和Qwen2.5-32B,它们的响应长度在训练初期迅速下降,这可能反映了模型在早期阶段通过强化学习快速剔除了冗余或无效的表达,学会了更简洁地组织语言;随后响应长度又逐渐回升并趋于稳定,与此同时奖励分数持续上升,表明模型在掌握了基本的高效表达后,开始重新引入更多必要的推理细节,以支持更复杂的决策逻辑,最终在简洁性与推理充分性之间找到了平衡点。
实验

本表展示了Think-In Games(TiG)框架在多个标准基准测试上的表现,全面评估了经过SFT和GRPO训练后的模型在通用语言理解与推理能力方面的保留和演化情况。该表格对比了不同规模的基础模型(如Qwen2.5-14B、Qwen-3-14B、Qwen2.5-32B)在经过多阶段训练(SFT+GRPO)前后在数学解题(ape_210k)、学科考试(SchoolChinese)、常识推理(MMLU)、中文知识(Ceval)、角色扮演(CharacterEval)、逻辑推理(BBH)以及指令遵循(IfEval)等多个维度的性能变化,其核心目的在于验证TiG方法是否在提升模型特定领域(如游戏策略决策)能力的同时,会损害其原有的通用语言智能。实验结果表明,经过针对游戏环境优化的强化学习训练后,所有模型在绝大多数基准任务上的表现均保持稳定,甚至在部分任务上略有提升。综上所述,本表有力地证明了TiG框架的成功不仅体现在专业领域的性能突破,更在于它实现了“专精”与“通识”的平衡——即在赋予语言模型强大交互式决策能力的同时,完整保留了其作为通用大模型所具备的广泛知识和复杂推理素质,从而支持了该方法在现实场景中安全、可靠且可泛化的应用潜力。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码
