NeurIPS 2025放榜了!大模型之心Tech着手汇总了中稿的相关工作,目前涉及视觉感知推理、大模型训练、具身智能、强化学习、视频理解、代码生成等等方向,大模型相关的论文汇总会第一时间同步至大模型之心Tech知识星球!

视觉感知推理
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
paper: https://arxiv.org/pdf/2509.15096 code:https://github.com/VCIP-RGBD/DFormer 单位:南开@程明明

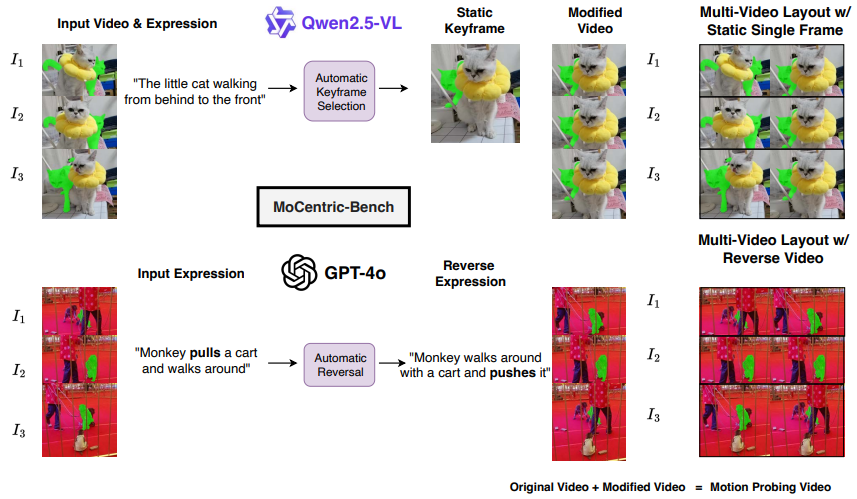
PixFoundation 2.0: Do Video Multi-Modal LLMs Use Motion in Visual Grounding?
paper: https://arxiv.org/pdf/2509.02807 code: https://github.com/MSiam/PixFoundation-2.0.git.

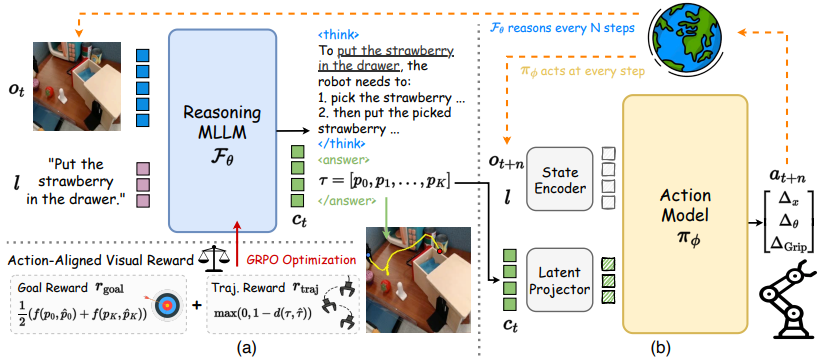
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
paper: https://arxiv.org/pdf/2507.16815 code: https://jasper0314-huang.github.io/thinkact-vla/ 单位:英伟达、台湾大学
DeepTraverse: A Depth-First Search Inspired Network for Algorithmic Visual Understanding
paper: https://arxiv.org/pdf/2506.10084

Are Vision Language Models Ready for Clinical Diagnosis? A 3D Medical Benchmark for Tumor-centric Visual Question Answering
paper: https://arxiv.org/pdf/2505.18915 code: https://github.com/Schuture/DeepTumorVQA.

视频理解
PixFoundation 2.0: Do Video Multi-Modal LLMs Use Motion in Visual Grounding?
paper: https://arxiv.org/pdf/2509.02807 code: https://github.com/MSiam/PixFoundation-2.0.git.
图像/视频生成与编辑
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
paper: https://arxiv.org/pdf/2509.15188 code:https://github.com/ybseo-ac/Conv
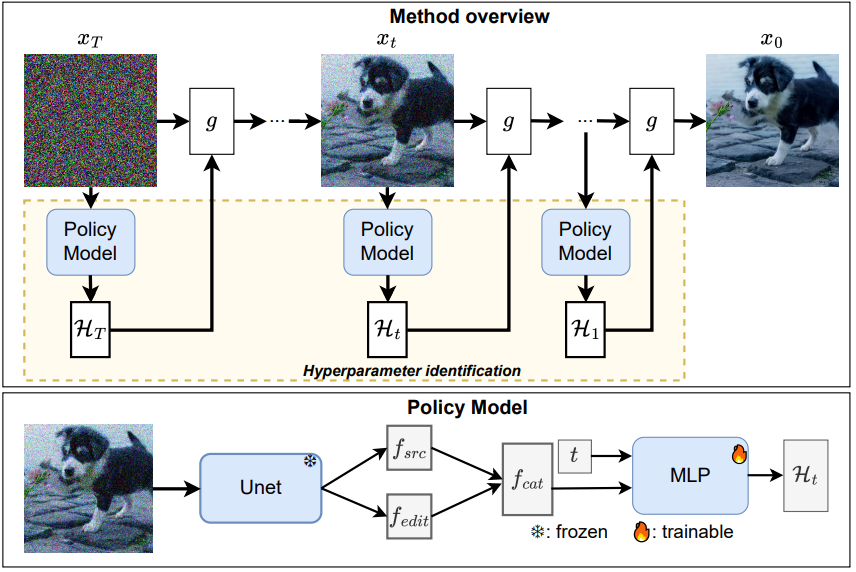
AutoEdit: Automatic Hyperparameter Tuning for Image Editing
paper: https://arxiv.org/pdf/2509.15031
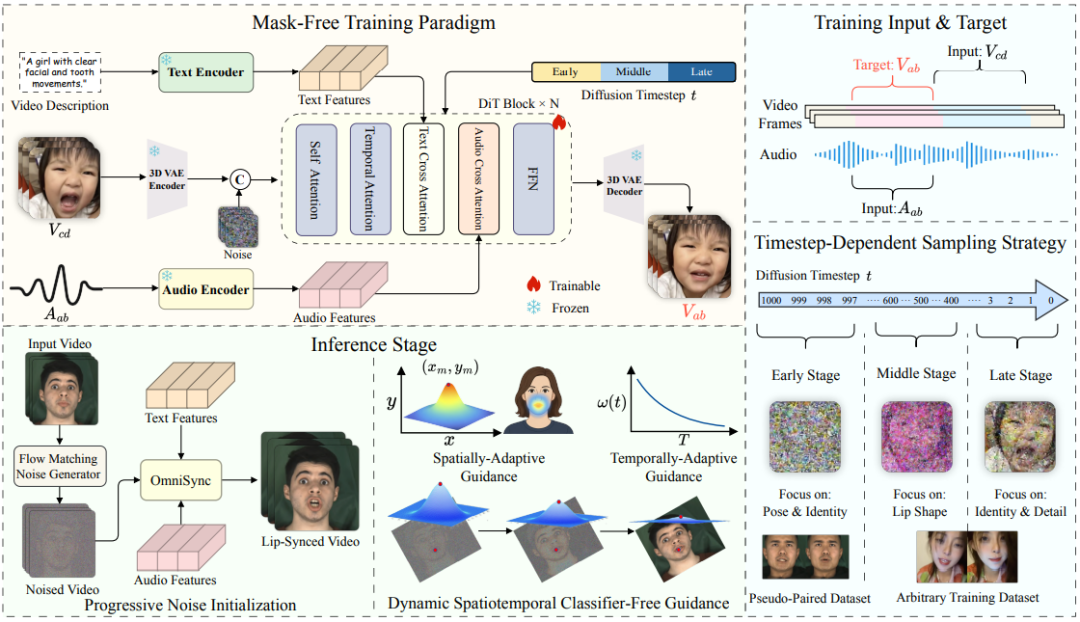
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
paper: https://arxiv.org/pdf/2505.21448 code:https://ziqiaopeng.github.io/OmniSync/
数据集/评估
Are Vision Language Models Ready for Clinical Diagnosis? A 3D Medical Benchmark for Tumor-centric Visual Question Answering
paper: https://arxiv.org/pdf/2505.18915 code: https://github.com/Schuture/DeepTumorVQA.
3D视觉
Are Vision Language Models Ready for Clinical Diagnosis? A 3D Medical Benchmark for Tumor-centric Visual Question Answering
paper: https://arxiv.org/pdf/2505.18915 code: https://github.com/Schuture/DeepTumorVQA.
大模型训练
Scaling Offline RL via Efficient and Expressive Shortcut Models
paper: https://arxiv.org/pdf/2505.22866 单位:康奈尔大学
强化学习/偏好优化
LLM world models are mental: Output layer evidence of brittle world model use in LLM mechanical reasoning
paper: https://arxiv.org/pdf/2507.15521
Scaling Offline RL via Efficient and Expressive Shortcut Models
paper: https://arxiv.org/pdf/2505.22866
大模型微调
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
paper: https://arxiv.org/pdf/2509.15188
Adaptive LoRA Experts Allocation and Selection for Federated Fine-Tuning
paper: https://arxiv.org/pdf/2509.15087

Differentially Private Federated Low Rank Adaptation Beyond Fixed-Matrix
paper: https://arxiv.org/pdf/2507.09990

具身智能
Self-Improving Embodied Foundation Models
paper: https://arxiv.org/pdf/2509.15155 code: https://self-improving-efms.github.io 单位:DeepMind

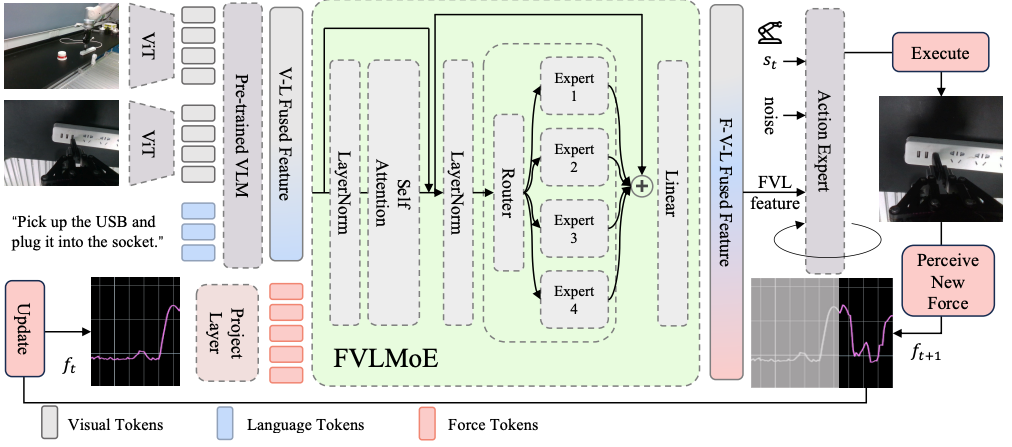
ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
paper: https://arxiv.org/pdf/2505.22159 code: https://sites.google.com/view/forcevla2025 单位:复旦、上交等
持续学习/模型幻觉
Improving Multimodal Large Language Models Using Continual Learning
paper: https://arxiv.org/pdf/2410.19925 code: https://shikhar-srivastava.github.io/cl-for-improving-mllms
人体
Real-Time Intuitive AI Drawing System for Collaboration: Enhancing Human Creativity through Formal and Contextual Intent Integration
paper: https://arxiv.org/pdf/2508.19254
大模型安全
Safely Learning Controlled Stochastic Dynamics
paper: https://arxiv.org/pdf/2506.02754
可解释性
Concept-Level Explainability for Auditing & Steering LLM Responses
paper: https://arxiv.org/pdf/2505.07610
文档理解
STEM-POM: Evaluating Language Models Math-Symbol Reasoning in Document Parsing
paper: https://arxiv.org/pdf/2411.00387 code: https://github.com/jiaruzouu/STEM-PoM.
医学
Are Vision Language Models Ready for Clinical Diagnosis? A 3D Medical Benchmark for Tumor-centric Visual Question Answering
paper: https://arxiv.org/pdf/2505.18915 code: https://github.com/Schuture/DeepTumorVQA.
Agent
AgentMisalignment: Measuring the Propensity for Misaligned Behaviour in LLM-Based Agents
paper: https://arxiv.org/pdf/2506.04018
混合专家模型
Adaptive LoRA Experts Allocation and Selection for Federated Fine-Tuning
paper: https://arxiv.org/pdf/2509.15087

ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
paper: https://arxiv.org/pdf/2505.22159 code: https://sites.google.com/view/forcevla2025.
代码生成
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
paper: https://arxiv.org/pdf/2509.15188
SBSC: Step-By-Step Coding for Improving Mathematical Olympiad Performance
paper: https://arxiv.org/pdf/2502.16666
大模型推理优化
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
paper: https://arxiv.org/pdf/2507.16815 code: https://jasper0314-huang.github.io/thinkact-vla/
LLM world models are mental: Output layer evidence of brittle world model use in LLM mechanical reasoning
paper: https://arxiv.org/pdf/2507.15521
STEM-POM: Evaluating Language Models Math-Symbol Reasoning in Document Parsing
paper: https://arxiv.org/pdf/2411.00387 code: https://github.com/jiaruzouu/STEM-PoM.
扩散模型
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
paper: https://arxiv.org/pdf/2509.15188
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
paper: https://arxiv.org/pdf/2505.21448
其他领域
Out-of-distribution generalisation is hard: evidence from ARC-like tasks
paper: https://arxiv.org/pdf/2505.09716
Fair Summarization: Bridging Quality and Diversity in Extractive Summaries
paper: https://arxiv.org/pdf/2411.07521











