

该论文发表于 The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025(CCF A类),题目为《Bridging Gait Recognition and Large Language Models Sequence Modeling》。
北京师范大学的ShaoPeng Yang为论文的第一作者,北京师范大学的侯赛辉副教授为本文通讯作者。
论文链接:
https://ieeexplore.ieee.org/document/11094335



论文概要
当前基于序列的步态识别方法在建模时序依赖方面取得了进展,但它们通常依赖复杂的网络结构设计,且容易受限于特定数据集,难以充分捕捉长时序和全局的动态特征。此外,步态序列是连续的非语言信号,与自然语言模型的输入形式存在差异,直接利用大语言模型(LLMs)进行建模存在挑战。
为了解决这些问题,本文提出了一种新的步态识别方法GaitLLM,核心在于通过两个关键模块实现步态序列与LLMs的有效结合。步态到语言模块(G2L)将步态特征转换为“步态句子”,利用空间与时间双重Tokenizer去除冗余并提取关键动作片段,使步态数据能够以语法形式输入LLMs;语言到步态模块(L2G)则将LLMs处理后的高层语义特征映射回步态特征空间,并与原始步态特征融合,实现身份判别特征的增强。通过冻结预训练步态编码器和LLMs,仅需训练少量参数即可完成适配。GaitLLM在SUSTech1K、CCPG、Gait3D和GREW四个主流步态数据集上均取得了优于现有方法的性能,验证了将语言模型引入步态识别的有效性与潜力。


步态识别作为一种重要的生物特征识别技术,能够通过人体独特的行走模式实现远距离的身份识别,相较于人脸和虹膜等静态生物特征,步态在衣物变化、光照和视角变化等条件下具有更强的鲁棒性,因此在安防和监控等 领域具有广泛的应用价值。
近年来,序列建模方法在步态识别中取得了显著进展,研究者们通过引入多尺度时间卷积、自注意力机制和时序变换器等方式,增强了对动态动作序列的建模能力。然而,这些方法往往依赖复杂的网络结构设计,并且高度依赖特定数据集,限制了模型的泛化能力。同时,步态序列作为一种连续的动态信号,难以直接与大语言模型的离散化输入形式对齐,因此如何充分利用大语言模型在序列建模方面的优势来提升步态识别性能,成为亟需解决的研究问题。


本文提出了一种新的步态识别方法GaitLLM,它利用大语言模型(LLM)的强大序列建模能力来增强步态识别性能。整体框架包括 步态到语言模块(G2L)、语言到步态模块(L2G)和步态识别头部,其中预训练的步态编码器与LLM 参数冻结,仅需训练少量适配模块即可完成步态特征与语言特征空间的映射。网络整体结构如图1所示。

图1 GaitLLM整体框架 (a) G2L-L2G总体结构 (b) 空间Tokenizer (c) 时间Tokenizer
(1)步态到语言模块(G2L)
G2L模块的目标是将步态特征转化为“步态句子”,使其能够输入LLM进行序列建模。该模块主要包含两个部分:空间Tokenizer 与 时间Tokenizer。
空间Tokenizer:作用是压缩局部空间特征并减少冗余。输入为步态编码器提取的特征图,将其划分为patch,并通过Transformer Block和绝对位置编码得到优化后的空间token t’:

其中 t 为可学习初试token,Pos 表示位置编码。
时间Tokenizer:用于去除时序冗余并提取关键动作片段。它包括 峰值Token检测器(PTF) 和 动作片段组装器(MCA)。PTF通过与全局token的相似度检测序列中最具判别性的关键帧:

MCA则利用交叉注意力机制将冗余token的信息压缩到保留token中,最终形成精简的“步态句子”。
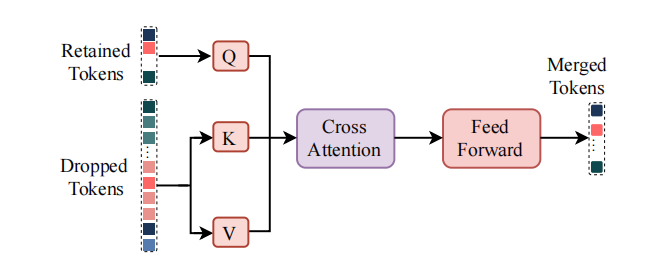
图2 时间Tokenizer的结构,包括峰值Token检测器(PTF)与动作片段组装器(MCA)
(2)语言到步态模块(L2G)
LLM在接收到“步态句子”后,会建模复杂的时序依赖关系并输出高层语义特征。为了使这些特征能够用于步态识别,需要通过L2G模块将其映射回步态特征空间。
L2G投影器:利用全连接层将LLM输出的语义特征重新映射到与步态编码器相匹配的特征维度。
表示聚合器(RA):通过全局最大池化操作,将序列token聚合为判别性强的步态特征表示:

该步骤保证了LLM提取的全局时序依赖能够转化为身份判别特征。
(3)步态识别头部
L2G模块输出的特征与步态编码器原始特征进行融合,沿着水平维度拼接后输入至步态识别头部(全连接层),以获得最终的步态嵌入表示:
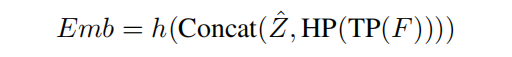
其中 F 为步态编码器的输出,TP 表示时序池化,HP 表示水平池化,h(·) 为分类头部。
(4)训练策略
GaitLLM采用两阶段训练:
阶段一:使用OpenGait框架预训练步态编码器(如DeepGaitV2或GaitBase)。
阶段二:冻结步态编码器与LLM,仅训练G2L、L2G和识别头部,优化目标为三元组损失和交叉熵损失:



作者主要在Gait3D、GREW、CCPG 和SUSTech1K 四个主流步态识别数据集上对所提出的GaitLLM进行了全面评估。如表2、表3和表4所示,GaitLLM在多个测试条件下均取得了优于现有方法的结果。在 Gait3D 数据集上,基于10层DeepGaitV2-P3D的基线模型Rank-1准确率为67.4%,而GaitLLM提升至74.1%,mAP达到60.1%,均显著优于基线。在 GREW 数据集上,GaitLLM的Rank-1准确率为71.2%,比基线提升2.2%,进一步验证了其在真实场景下的泛化能力。
表1 在 Gait3D 和 GREW 数据集上的性能比较

表2 在 CCPG 数据集不同条件下的性能比较

表3 在 SUSTech1K 数据集不同属性条件下的评估结果
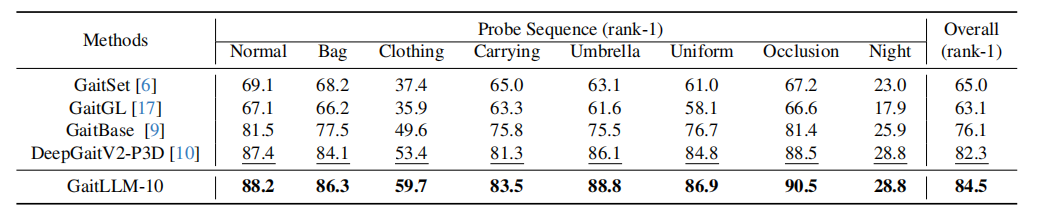
在 CCPG 数据集的衣物变化场景中,GaitLLM-10在四种测试协议(CL、UP、DN、BG)下均取得最佳结果,平均Rank-1准确率达到85.4%,超过了基线的83.3%。在 SUSTech1K 数据集的多种复杂场景下,GaitLLM-10也展现出显著优势,总体Rank-1准确率达到84.5%,在衣物变化、背包和打伞场景下分别提升了6.3%、2.2%和2.7%。
此外,通过消融实验进一步分析了所有模块的有效性。空间Tokenizer与时间Tokenizer在G2L模块中缺一不可,而在聚合策略对比中,全局最大池化(GMP)明显优于全局平均池化(GAP)和Last Token方法。
表4 G2L-Tokenizer 在 Gait3D 和 SUSTech1K 数据集上的消融实验

表5 在 Gait3D 数据集上不同特征聚合方法的比较

在图2的t-SNE可视化结果中也可以直观地看到,GaitLLM-10能够有效减小类内差异,提高类间可分性,验证了模型在表征学习方面的优势。

图2 消融实验结果对比 (a) 不同Tokenizer组合 (b) 不同聚合策略 (c) t-SNE可视化对比基线与GaitLLM-10


结论
本文提出了GaitLLM,一种利用大语言模型(LLMs)强大序列建模能力的步态识别方法。通过设计步态到语言模块(G2L)和语言到步态模块(L2G),GaitLLM能够将连续的步态序列转化为“步态句子”,并借助LLMs建模复杂的时序依赖,再映射回步态特征空间以增强身份判别能力。实验结果表明,GaitLLM在Gait3D、GREW、CCPG和SUSTech1K等多个主流数据集上均取得了优于现有方法的性能,尤其在衣物变化和复杂环境条件下展现出显著优势。该方法为步态识别引入了新的视角,展示了语言模型在时序视觉任务中的潜力,并为未来结合大语言模型与步态识别的研究提供了新的方向。
撰稿人:徐昱涛
审稿人:周成菊


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci











