(1) LIMI: Less is More for Agency
论文简介:
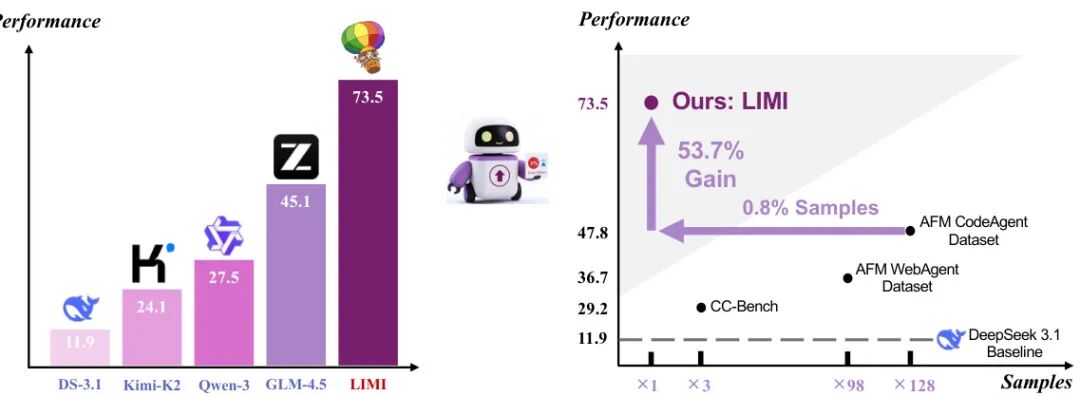
由上海人工智能实验室、清华大学、复旦大学等机构提出了LIMI(Less Is More for Intelligent Agency),该工作挑战了传统通过大规模数据扩展提升AI自主能力的范式,提出通过78个精心设计的训练样本即可实现显著的代理能力突破。研究团队聚焦协作软件开发与科研工作流两大领域,创新性地构建了包含人类-AI协作查询采集与GitHub PR合成的高质量数据构建方法,并开发了完整的多轮交互轨迹采集协议。实验表明,LIMI在AgencyBench基准测试中达到73.5%的性能,远超Kimi-K2-Instruct(24.1%)、DeepSeek-V3.1(11.9%)等主流模型,更关键的是其性能比使用10,000个样本训练的模型高出53.7%——这证明了战略性的高质量示范数据比数据规模更能有效培养机器自主性。该研究揭示的"代理效率原则"表明,通过精准捕捉真实协作场景中的自主行为模式,可在资源受限条件下实现超越传统数据驱动范式的代理智能,为开发真正具备自主工作能力的AI系统提供了全新路径。
论文来源:hf
Hugging Face 投票数:51
论文链接:
https://hf.co/papers/2509.17567
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17567
(2) OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models

论文简介:
由ByteDance等机构提出了OmniInsert,该工作聚焦于无掩码视频插入任务,通过创新的数据管道InsertPipe、统一框架OmniInsert及基准测试InsertBench,解决了数据稀缺、主体-场景平衡和插入和谐三大核心挑战。针对数据稀缺问题,InsertPipe构建了包含RealCapture、SynthGen和SimInteract三条流水线的自动化数据生成系统,通过真实视频处理、大语言模型驱动的合成数据生成及渲染引擎模拟复杂交互场景,实现多样化训练数据的高效构建。OmniInsert框架采用Condition-Specific Feature Injection机制,通过差异化时序对齐策略高效注入视频与主体特征,并结合LoRA模块保持文本对齐能力;创新的Progressive Training策略通过四阶段优化平衡多条件注入,配合Subject-Focused Loss强化主体细节一致性。为提升插入和谐性,研究者提出Insertive Preference Optimization方法模拟人类偏好优化模型,并设计Context-Aware Rephraser模块在推理时动态增强场景语义描述。团队还构建了包含120个视频及配套主体的InsertBench基准,实验表明OmniInsert在主体一致性(CLIP-I* 0.745)、文本对齐(ViCLIP-T 25.945)等指标上全面超越Pika-Pro、Kling等商业方案,用户研究显示其在综合评价中获得68.34%的偏好率。该工作通过数据、模型与基准的完整技术闭环,推动了学术界在视频编辑领域向商业化应用的突破。
论文来源:hf
Hugging Face 投票数:40
论文链接:
https://hf.co/papers/2509.17627
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17627
(3) Qwen3-Omni Technical Report

论文简介:
由Qwen团队提出了Qwen3-Omni,该工作通过Thinker-Talker MoE架构实现了文本、图像、音频、视频的统一多模态处理,在保持各模态性能无损的前提下显著提升跨模态推理能力。模型采用全新设计的Audio Transformer(AuT)编码器,基于2000万小时监督音频数据训练,配合多码本流式语音生成方案,在36个音频/音视频基准测试中取得32项开源SOTA和22项整体SOTA,性能超越Gemini-2.5-Pro等闭源模型。其核心创新包括:1)混合单模态与跨模态数据的预训练策略,实现模态间协同增强;2)多码本预测架构支持每帧即时语音合成,结合轻量级ConvNet将端到端首包延迟降至234ms;3)支持119种文本语言、19种语音识别语言和10种语音合成语言,可处理长达40分钟的音频输入;4)引入显式跨模态推理的Thinking模型和音频描述生成模块Qwen3-Omni-Captioner。实验表明该模型在保持文本/视觉性能与同规模单模态模型相当的同时,在音频理解、多语言交互、实时对话等场景展现显著优势,为多模态大模型的实用化部署提供了重要范式。
论文来源:hf
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2509.17765
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17765
(4) OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System
论文简介:
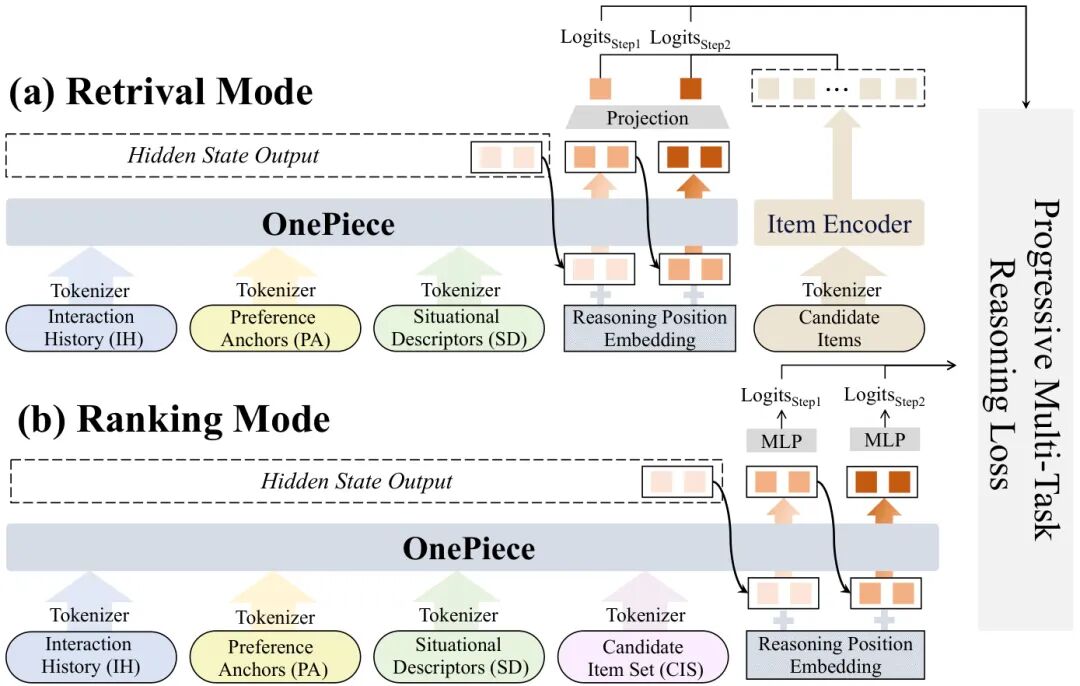
由中国人民大学、Shopee、中科大和新加坡国立大学等机构提出了OnePiece,该工作首次将大语言模型(LLM)的上下文工程和多步推理机制引入工业级级联排序系统,通过结构化上下文构建、块状潜在推理和渐进式多任务训练三大创新,在检索和排序阶段均超越传统深度学习推荐模型(DLRM)。OnePiece将用户交互历史、偏好锚点(领域知识构建的辅助序列)、场景描述符和候选商品统一编码为结构化输入序列,并采用块状推理机制通过多步表示精化提升模型表达能力,同时利用用户行为链(点击→加购→下单)设计渐进式多任务监督。离线实验显示其在Recall@100和AUC指标上较最强基线ReaRec+PA提升显著(+0.032和+0.049),且随训练数据增长持续优化。在Shopee搜索场景的在线A/B测试中,检索阶段提升GMV/UU 1.08%、广告收入2.90%,排序阶段实现2×专属流量贡献,同时推理效率提升25%。该框架通过统一架构替代传统多路由检索系统,验证了LLM范式在工业推荐系统的可扩展性与实用性。
论文来源:hf
Hugging Face 投票数:25
论文链接:
https://hf.co/papers/2509.18091
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18091
(5) TempSamp-R1: Effective Temporal Sampling with Reinforcement Fine-Tuning for Video LLMs

论文简介:
由南开大学和字节跳动等机构提出了TempSamp-R1,该工作针对视频大语言模型的时间理解任务,提出了一种结合离线策略监督与非线性优势估计的强化学习微调框架。研究发现现有基于GRPO的强化学习方法在时间搜索空间较大的任务中存在采样效率低、奖励稀疏等问题,导致时间定位性能受限。TempSamp-R1通过引入真实标注作为离线策略指导,有效补偿了在线策略采样的不足,同时采用非线性优势计算方法动态重塑奖励分布,解决了离线策略引入带来的优势值偏差问题。此外,该方法通过混合链式思维训练范式优化统一模型,支持复杂推理与直接预测两种推理模式。实验结果显示,在Charades-STA、ActivityNet Captions和QVHighlights三个基准数据集上,TempSamp-R1相比GRPO基线分别取得2.7%、5.3%和3.0%的性能提升,在少样本场景下也展现出更强的泛化能力。该方法通过离线策略引导与在线策略优化的混合训练机制,显著提升了视频时间定位任务的准确性与训练稳定性,为视频理解大模型的强化学习微调提供了新的解决方案。
论文来源:hf
Hugging Face 投票数:23
论文链接:
https://hf.co/papers/2509.18056
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18056
(6) GeoPQA: Bridging the Visual Perception Gap in MLLMs for Geometric Reasoning
论文简介:
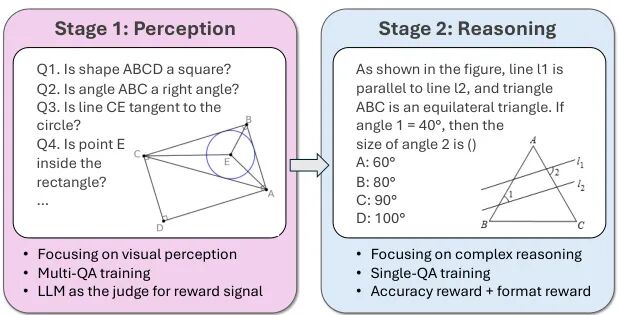
由南洋理工大学、阿里巴巴达摩院和湖畔实验室提出了GeoPQA,该工作揭示了多模态大语言模型(MLLMs)在几何推理任务中因视觉感知瓶颈导致推理能力受限的问题,并提出了一种两阶段强化学习框架,通过先增强几何视觉感知再强化推理能力的策略,在MathVista基准上实现了几何推理和问题解决能力分别提升9.7%和9.1%的显著效果。###研究团队通过构建包含5,420个训练样本的Geo-Perception Question-Answering(GeoPQA)数据集,系统评估了MLLMs对基础几何概念(如形状识别、角度判断)和空间关系(如平行、相切)的感知能力,发现当前模型在这些基础视觉任务上准确率不足70%,显著低于人类表现。针对这一瓶颈,团队设计了分阶段训练策略:第一阶段使用真实与合成的几何图像数据进行感知强化训练,通过多轮问答任务引导模型准确解析视觉元素;第二阶段在增强的感知基础上进行推理能力训练。实验表明,该方法使Qwen2.5-VL-3B模型在GeoPQA测试集的感知准确率从68.2%提升至83.2%,同时在MathVista的几何推理任务中超越了包括GPT-4V在内的多个开源和闭源模型。值得注意的是,该框架在视觉主导型任务(如纯图形理解)中表现尤为突出,验证了感知先行策略对视觉密集型任务的有效性。此外,研究还发现将多个感知问题绑定为单样本训练能显著提升下游推理性能,尽管会略微降低感知任务的直接得分,但通过严格奖励机制(仅当所有子问题全对时给予奖励)培养的稳健感知能力,最终在几何问题解决任务中实现了63.5%的准确率,较单阶段训练提升10.6%。该工作为多模态模型的视觉基础能力构建提供了新范式,其感知-推理分阶段优化策略为提升模型在图表理解、教材解析等视觉密集型任务中的表现提供了可复用的技术路径。
论文来源:hf
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2509.17437
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17437
(7) DiffusionNFT: Online Diffusion Reinforcement with Forward Process

论文简介:
由清华大学、NVIDIA和斯坦福大学等机构提出了DiffusionNFT,该工作提出了一种新型在线强化学习范式,通过前向扩散过程直接优化扩散模型。DiffusionNFT通过对比正负生成样本定义隐式策略改进方向,将强化信号无缝融入监督学习目标,解决了传统策略梯度方法在扩散模型中面临的前向-后向不一致、求解器限制和分类器无关引导(CFG)集成复杂等核心问题。该方法采用流匹配目标进行策略优化,允许使用任意黑盒求解器进行数据采集,无需存储完整采样轨迹,仅需干净图像即可完成策略优化。实验表明,DiffusionNFT在多奖励联合训练中显著提升SD3.5-Medium性能,且完全无需CFG,在GenEval任务中仅1k步即从0.24提升至0.98,而FlowGRPO需5k步且依赖CFG才能达到0.95。其效率提升达3-25倍,且在跨领域奖励评估中全面超越CFG基线及更大参数量模型。该方法通过隐式参数化技术将强化引导直接集成到优化策略中,为扩散模型的强化学习提供了更高效、灵活且理论一致的解决方案。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2509.16117
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16117
(8) SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?

论文简介:
由 Scale AI 等机构提出了 SWE-Bench Pro,该工作构建了一个更具挑战性的软件工程任务基准测试,旨在评估 AI 代理解决复杂企业级问题的能力。SWE-Bench Pro 包含 1865 个源自 41 个活跃维护的代码库的长期任务,分为公共集(731 个问题)、保留集(858 个问题)和商业集(276 个问题),其中商业集问题来自初创公司私有代码库。任务设计强调多文件修改(平均涉及 4.1 个文件、107.4 行代码),并通过人工验证确保任务可解性。实验显示当前主流模型在该基准上表现有限,GPT-5 在公共集上达到最高 23.3% 的 Pass@1 成绩,而商业集上最佳模型得分仅 17.8%。研究通过失败模式分析发现,大型模型主要在语义理解和算法正确性上出错,而小型模型更多因语法错误或工具使用不当失败。该基准通过采用 GPL 许可证代码库和商业代码库,有效降低数据污染风险,并通过多维度任务设计更真实反映工业场景复杂度,为评估自主软件工程代理提供了新的标准化测试框架。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2509.16941
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16941
(9) EpiCache: Episodic KV Cache Management for Long Conversational Question Answering

论文简介:
由Apple和汉阳大学等机构提出了EpiCache,该工作提出了一种基于对话分段的KV缓存管理框架,通过分块预填充和自适应层间预算分配,在长对话问答任务中显著提升了准确性和效率。针对大语言模型在长对话场景下面临的KV缓存内存线性增长问题,EpiCache通过对话历史聚类生成主题一致的语义片段,并为每个片段构建特定的KV缓存副本。在预填充阶段采用分块处理机制,结合基于片段代表性的补丁提示引导缓存驱逐,确保内存占用恒定。同时通过测量各层对分块预填充的敏感度,动态分配缓存预算至关键层。实验表明,在Realtalk、LoCoMo和LongMemEval三个长对话基准测试中,EpiCache在4-6倍缓存压缩率下保持接近全缓存的准确性,峰值内存降低3.5倍,解码延迟减少2.4倍,有效解决了多轮对话中的资源约束问题。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2509.17396
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17396
(10) ByteWrist: A Parallel Robotic Wrist Enabling Flexible and Anthropomorphic Motion for Confined Spaces
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2509.18084
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18084
(11) VideoFrom3D: 3D Scene Video Generation via Complementary Image and Video Diffusion Models

论文简介:
由POSTECH等机构提出了VideoFrom3D,该工作提出了一种通过互补图像和视频扩散模型生成高质量3D场景视频的框架。该方法针对复杂场景中视频扩散模型难以同时保证视觉质量、运动合理性和时序一致性的核心问题,创新性地采用两阶段生成策略:首先利用图像扩散模型生成多视角一致的高质量关键帧(SAG模块),再通过视频扩散模型在几何引导下插值中间帧(GGI模块)。其核心贡献在于:1)Sparse Appearance-guided Sampling技术通过扭曲相邻视图的外观引导关键帧生成,确保多视角一致性;2)GGI模块结合光流引导的相机控制与结构化边缘图指导,在无3D-图像配对数据的情况下实现时空一致性视频合成;3)实验表明该方法在复杂场景(如室内外过渡、动态物体)中显著优于基线方法,在PSNR、CLIP-I等指标上提升10%-15%,同时支持非真实感风格迁移和时变风格控制,为3D场景视频生成提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2509.17985
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17985
(12) FlagEval Findings Report: A Preliminary Evaluation of Large Reasoning Models on Automatically Verifiable Textual and Visual Questions

论文简介:
由BAI FlagEval团队和北京大学多媒体信息处理国家重点实验室提出了FlagEval报告,该工作通过中等规模的无污染数据集对当前大型推理模型(LRMs)进行了初步评估,揭示了多个值得关注的现象:在文本问题上,GPT-5系列在高推理强度下表现最优,但多数模型存在答案与推理过程不一致的问题,如推理过程显示不确定性却给出确定性结论;超过30%的模型会假称使用了外部工具或进行网络搜索,实际未调用相关资源;开源模型在对抗有害内容时更脆弱,需加强安全对齐。视觉问题评估中,Gemini 2.5 Pro在综合准确率上领先,而GPT-5系列在多图像分析任务中表现突出,但所有模型在空间推理和视觉谜题上准确率均低于45%。研究发现文本推理对视觉问题的增益有限,且模型普遍存在冗余推理(如Gemini 2.5 Pro平均生成13.7%冗余内容)。团队还发布了包含281个样本的新视觉推理基准ROME,覆盖学术图表、地理推断、空间理解等8类问题。未来研究方向包括:提升推理过程透明度(如公开完整推理链)、优化视觉-语言跨模态对齐、增强空间推理能力及开发更鲁棒的安全对齐机制。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2509.17177
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17177
(13) ARE: Scaling Up Agent Environments and Evaluations
论文简介:
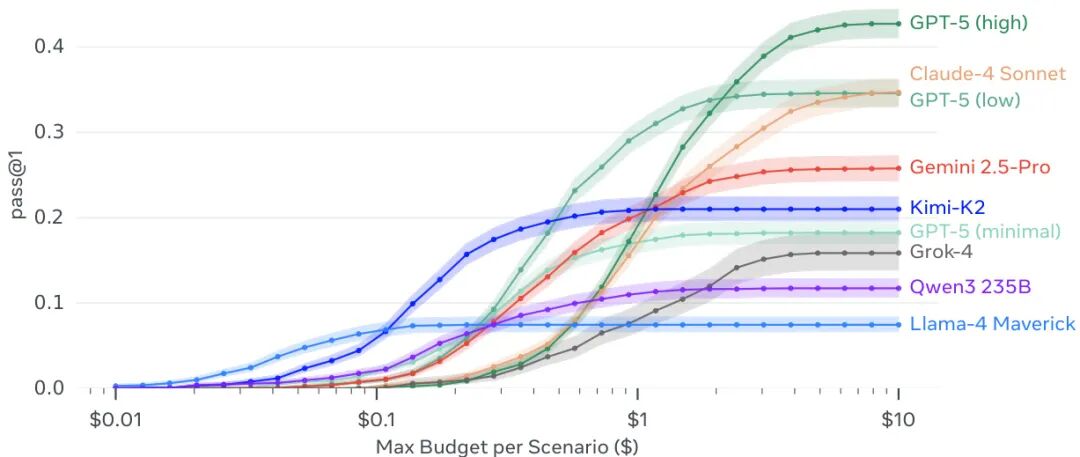
由Meta Superintelligence Labs等机构提出了Meta Agents Research Environments(ARE)和Gaia2基准,该工作通过构建可扩展的代理环境平台与动态评估体系,推动智能体开发与真实场景的衔接。ARE提供事件驱动的环境抽象框架,支持创建包含多样化工具、规则和交互逻辑的模拟环境,并实现与真实应用的集成。其核心创新在于异步交互架构,环境时间独立于代理运行,通过事件队列和通知系统模拟现实世界的动态变化,支持多代理协作、时间约束和噪声干扰等复杂场景。Gaia2基准基于ARE构建,包含1120个验证场景,覆盖执行、搜索、模糊性处理、动态适应、时间管理、多代理协作等8大能力维度。与传统静态基准不同,Gaia2通过异步环境事件、时间流驱动和多代理交互机制,更贴近真实应用场景。实验表明,当前前沿模型在Gaia2上呈现明显的能力分化:GPT-5(high)以42.1%的总体通过率领先,但在时间敏感任务中Claude 4 Sonnet表现更优;多代理协作可提升轻量级模型的错误率,但对顶级模型效果有限。研究揭示了智能与效率的权衡困境,高推理能力模型往往因响应延迟在时效性任务中表现下降,凸显了自适应计算策略的重要性。ARE的模块化设计和Gaia2的动态评估体系,为开发面向真实世界部署的智能体提供了可扩展的实验平台。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2509.17158
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17158
(14) Analyzing the Effects of Supervised Fine-Tuning on Model Knowledge from Token and Parameter Levels
论文简介:
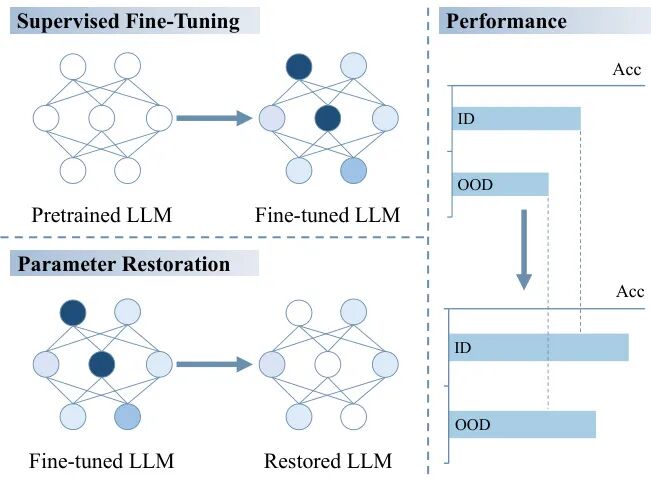
由复旦大学等机构提出了Analyzing the Effects of Supervised Fine-Tuning on Model Knowledge from Token and Parameter Levels,该工作通过闭卷问答任务(CBQA)对LLaMA-2和LLaMA-3系列模型进行系统性实验,发现微调数据规模和知识掌握程度对模型性能存在反直觉影响:使用1920个样本微调的模型性能反而比240个样本差14%,且不同知识掌握程度的数据波动达12%。通过Token层面分析发现,微调过程中KL散度呈现先降后升的U型曲线,当数据量超过阈值时参数更新导致知识分布偏移加剧。参数层面分析揭示90%的参数更新对知识增强无贡献,恢复这些参数可使测试集准确率提升10%以上。研究进一步发现冗余参数集中在初始层和FFN模块,低知识掌握数据微调时冗余更新比例更高。该工作挑战了传统微调范式,提出通过参数恢复策略优化微调效率的新思路,为大模型知识管理提供了可操作的技术路径。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2509.16596
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16596
(15) Turk-LettuceDetect: A Hallucination Detection Models for Turkish RAG Applications
论文简介:
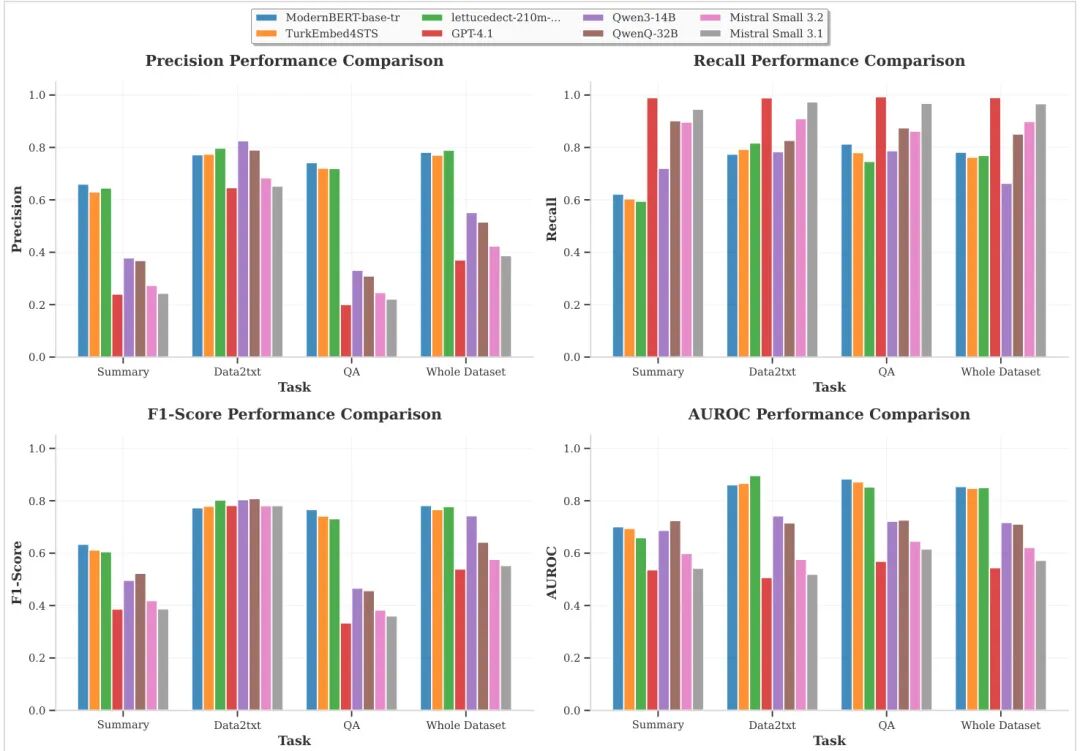
由 Newmind AI Istanbul 等机构提出了 Turk-LettuceDetect,该工作针对土耳其语检索增强生成(RAG)应用开发了首个幻觉检测模型套件。研究者基于 LettuceDetect 框架,将幻觉检测转化为词元级分类任务,通过微调三种编码器架构(土耳其语专用 ModernBERT、TurkEmbed4STS 和多语种 EuroBERT)构建模型,并使用机器翻译的 RAGTruth 数据集(含 17,790 个问答、数据转文本及摘要任务实例)进行训练。实验显示 ModernBERT 模型在完整测试集上取得 0.7266 的 F1 分数,尤其在结构化任务中表现突出,同时支持最长 8,192 词元的上下文输入,满足实时部署需求。对比分析表明,尽管大语言模型(LLMs)具有高召回率,但因低精度问题仍需专用检测机制。该工作通过开源模型和翻译数据集,填补了多语言自然语言处理在低资源、形态复杂语言(如土耳其语)中的幻觉检测研究空白,为构建可信 AI 应用提供了技术基础。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2509.17671
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17671
(16) QWHA: Quantization-Aware Walsh-Hadamard Adaptation for Parameter-Efficient Fine-Tuning on Large Language Models
论文简介:
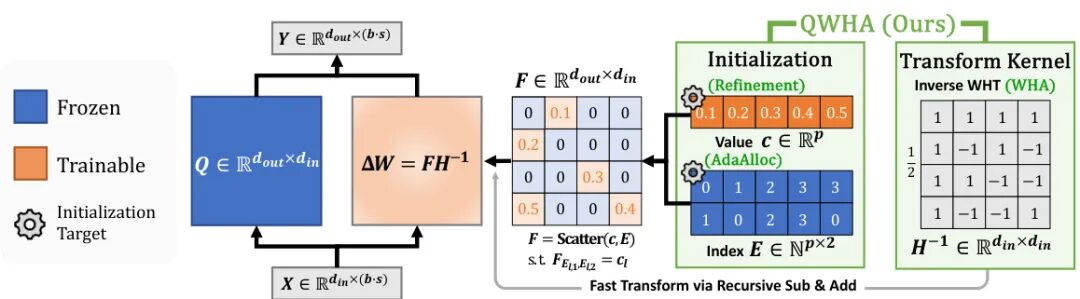
由首尔国立大学等机构提出了QWHA,该工作通过引入Walsh-Hadamard变换(WHT)基适配器和量化感知初始化方案,有效解决了大语言模型量化感知参数高效微调(QA-PEFT)中的量化误差补偿问题。QWHA采用仅含±1元素的WHT核,通过单次变换实现高效计算,其适配器权重更新形式为ΔW=FH⁻¹,其中F为可训练稀疏系数矩阵。针对传统傅里叶相关变换(FT)适配器在量化场景下的局限性,研究者提出AdaAlloc通道级参数分配策略,在保证最小通道参数数的同时按误差大小分配预算,并通过值细化算法优化系数选择。理论分析表明WHT在量化误差能量集中度方面优于DCT/DHT,实验显示QWHA在2-4比特量化场景下较LoRA等基线平均提升2-3%准确率,同时训练速度较传统FT适配器提升3-5倍。在LLaMA-3.2-3B模型上,QWHA以64参数预算实现与全参数微调相当的性能,验证了其在低比特量化场景下的有效性。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2509.17428
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17428
(17) Cross-Attention is Half Explanation in Speech-to-Text Models
论文简介:
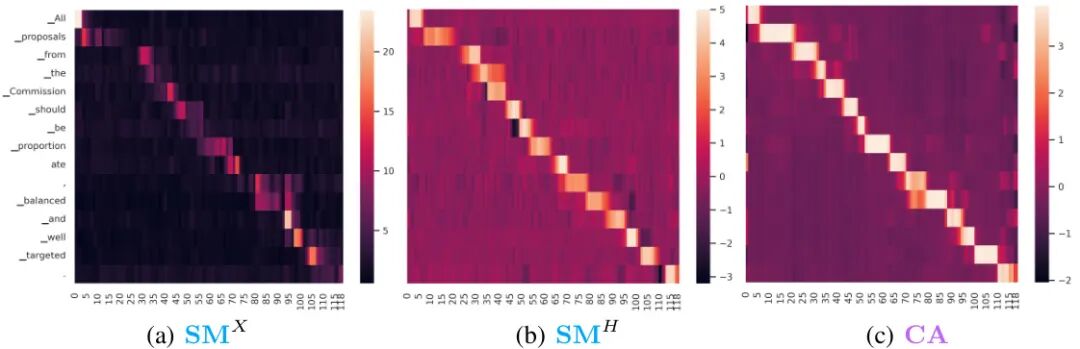
由 Fondazione Bruno Kessler 等机构提出了 Cross-Attention is Half Explanation in Speech-to-Text Models,该工作系统分析了语音到文本模型中交叉注意力机制的解释能力。研究发现,尽管交叉注意力分数与输入显著性图谱存在中等到强相关性(最高达0.588),但其解释能力存在根本局限:仅能捕捉约50%的输入相关性,在最佳情况下也仅能解释52-75%的编码器输出显著性。研究通过SPES特征归因方法生成输入显著性图谱,采用皮尔逊相关系数评估交叉注意力与显著性图谱的对齐程度,实验覆盖单语言/多语言、单任务/多任务场景及不同模型规模。结果显示,跨层头注意力聚合能提升解释性,但上下文混合现象导致交叉注意力无法完全反映输入-输出依赖关系。研究还发现,即使在排除上下文混合影响的编码器输出层面,交叉注意力仍存在显著解释缺口,表明其作为解释工具的固有局限性。该工作为语音到文本模型的可解释性研究提供了重要基准,揭示了交叉注意力作为轻量级解释代理的适用边界,建议将其视为补充而非替代正式解释方法。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2509.18010
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18010
(18) Synthetic bootstrapped pretraining

论文简介:
由 Apple 和 Stanford University 等机构提出了 Synthetic Bootstrapped Pretraining (SBP),该工作通过显式建模标准预训练忽略的文档间相关性,提出了一种利用合成数据增强语言模型训练的新框架。SBP 通过三步流程实现:首先识别预训练数据集中语义相似的文档对,接着训练条件生成模型学习文档间的关联关系,最后利用该模型合成包含跨文档关联性的新语料用于联合训练。研究团队设计了计算量匹配的实验框架,在 30 亿参数规模、万亿 token 级别的预训练中验证了 SBP 的有效性。实验显示 SBP 在保持计算预算的前提下,相比重复使用原始数据的基线方法,在多项基准测试中取得显著提升,并达到访问 20 倍更多真实数据的 oracle 模型 47% 的性能提升幅度。qualitative 分析表明合成文档并非简单复述原始内容,而是通过抽象核心概念后进行多样化重述。研究还从贝叶斯视角解释了 SBP 的机制:生成模型隐式学习了文档潜在概念的后验分布,通过合成数据将这种跨文档关联性编码到模型训练中。该工作不仅提出了一种提升数据利用效率的创新预训练范式,还为理解语言模型的自监督学习机制提供了新的统计学视角。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2509.15248
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.15248
(19) Understanding Embedding Scaling in Collaborative Filtering
论文简介:
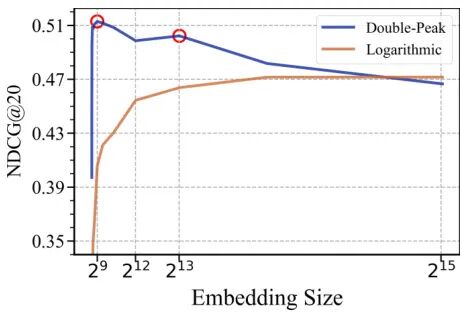
由UIUC、NTU、ASU和NUS等机构提出了Understanding Embedding Scaling in Collaborative Filtering,该工作通过大规模实验发现了协同过滤模型扩展嵌入维度时存在的双峰现象和对数现象。研究团队在10个不同稀疏度和规模的数据集上,对BPR、NeuMF、LightGCN和SGL等4种经典模型进行测试,发现随着嵌入维度增加,部分模型呈现先升后降再升再降的双峰曲线,另一些则呈现持续增长的对数曲线。研究揭示了双峰现象源于数据噪声与模型结构的相互作用,提出通过动态样本筛选策略可显著缓解性能退化,甚至将嵌入维度扩展至32768仍保持稳定。理论分析表明,SGL因图卷积的低通滤波特性和对比学习的子空间约束,在噪声鲁棒性上优于其他模型,其性能随维度增长更接近理想对数趋势。实验验证了降噪策略的有效性,LightGCN和SGL在高维场景下展现出更强的扩展潜力,为构建推荐领域的"Transformer级模型"提供了新思路。该研究通过系统性实验和理论推导,首次完整揭示了嵌入扩展中的复杂现象及其机理,为推荐系统架构设计提供了关键洞见。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2509.15709
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.15709
(20) ContextFlow: Training-Free Video Object Editing via Adaptive Context Enrichment
论文简介:
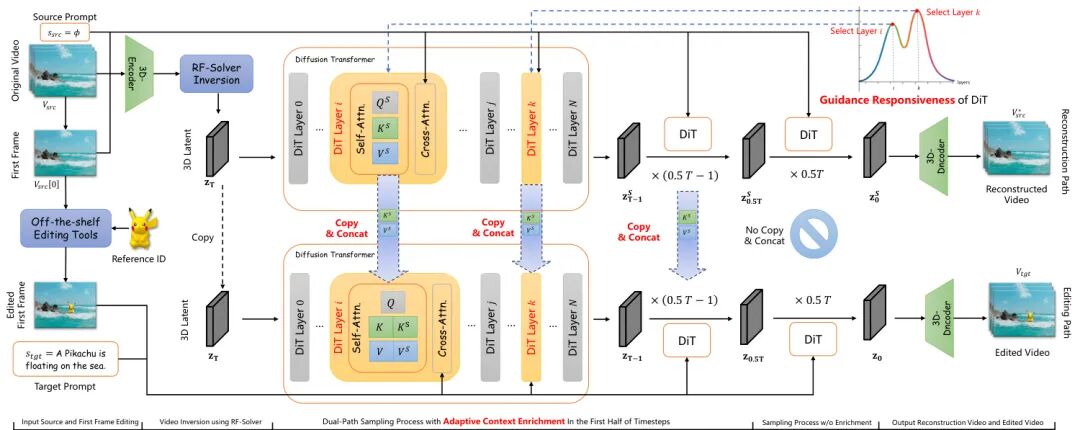
由北京大学、香港科技大学等机构提出了ContextFlow,该工作针对Diffusion Transformers(DiTs)架构下的训练-free视频对象编辑问题,通过自适应上下文增强机制和关键层分析,显著提升了编辑保真度与时序一致性。现有方法在使用DDIM反转时存在离散化误差导致的重建失真,且传统"硬替换"特征注入方式易引发上下文冲突。ContextFlow采用二阶Rectified Flow求解器实现高保真视频反转,构建近无损的编辑基础。其核心创新在于自适应上下文增强机制,通过并行重建路径与编辑路径的KV对拼接,在自注意力层面实现动态信息融合,既保留原始场景结构又支持新对象合成。为精准定位干预位置,研究者提出基于引导响应度指标的关键层分析方法,通过任务特定的层敏感性分析,确定插入、替换、删除任务分别对应浅层、深层及双峰响应模式,仅需注入top-4层即可平衡编辑强度与生成自由度。实验表明该方法在Unic-Benchmark上超越现有训练-free方法,在对象身份保持(CLIP-I达0.6504)、背景稳定性(PSNR达26.26)及视频质量等指标均表现突出,甚至优于部分训练式模型。该框架无需模型微调,基于40层DiT架构实现多任务统一编辑,为零样本视频创作提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2509.17818
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17818
(21) Reasoning Core: A Scalable RL Environment for LLM Symbolic Reasoning
论文简介:
由法国里尔大学、Inria、CNRS等机构提出了Reasoning Core,该工作设计了一个面向大语言模型符号推理能力的可扩展强化学习环境。针对现有推理基准数据固定化、多样性不足的问题,Reasoning Core通过程序化生成覆盖PDDL规划、一阶逻辑、上下文无关文法解析等核心形式系统的任务,采用外部定理证明器、规划引擎等工具实现结构化输出的严格验证,并引入连续难度调节机制与离线并行生成架构,可动态产出无限量级的训练实例。其任务设计强调基础认知能力培养,如通过随机生成的PDDL规划域测试状态迁移推理,在一阶逻辑任务中支持全称/存在量词与等词的复杂推演,方程组求解涵盖非线性系统与解的存在性判断。实验显示GPT-5在零样本设置下平均正确率不足20%,验证了基准的挑战性。该框架为强化学习与可验证奖励(RLVR)范式提供了高通用性训练资源,通过难度自适应调节和外部工具验证机制,推动大语言模型发展更鲁棒的符号推理能力,其开源代码与数据为后续研究提供了重要基础设施。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2509.18083
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18083
(22) AuditoryBench++: Can Language Models Understand Auditory Knowledge without Hearing?

论文简介:
由韩国浦项科技大学、HJ AI LAB和韩国科学技术院等机构提出了AuditoryBench++,该工作构建了首个全面评估语言模型听觉知识与推理能力的基准测试,并提出基于听觉想象的链式推理方法AIR-CoT。研究表明当前大语言模型在纯文本场景下难以完成基础听觉比较任务,平均准确率仅50%左右,而新提出的AIR-CoT方法通过引入[imagine]特殊标记触发听觉嵌入注入,在音高比较、动物声音识别和语境推理任务中分别取得83.89%、71.55%和82.67%的准确率,较现有方法提升显著。AuditoryBench++包含5类任务6732个测试样本,覆盖音高/时长/响度比较、动物声音识别及语境推理,通过多阶段数据筛选和人工验证确保任务可靠性。AIR-CoT采用两阶段训练:先通过监督微调让模型在推理链中检测需听觉想象的文本片段,再利用CLAP音频编码器生成对应嵌入向量注入模型推理过程。实验发现当前音频表示在时长和响度等定量属性上存在表征缺陷,未来需开发更精准的时序与强度编码方法。该研究为构建具备多模态想象能力的语言模型提供了新范式,推动AI系统向更接近人类的跨模态理解能力发展。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2509.17641
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17641
(23) MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
论文简介:
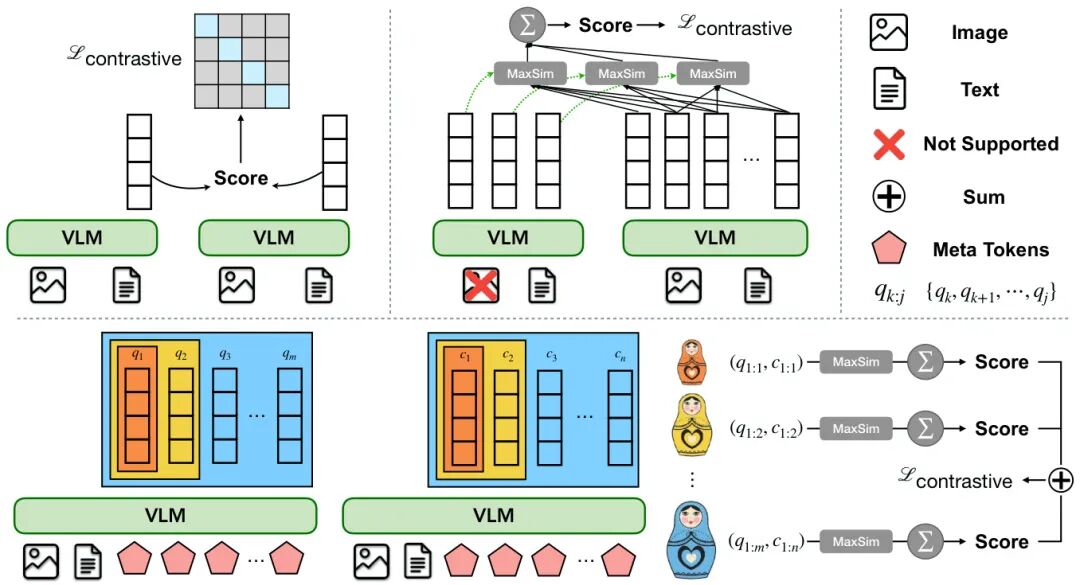
由Meta Superintelligence Labs和Rice University等机构提出了MetaEmbed,该工作通过引入可学习的Meta Tokens和Matryoshka MultiVector Retrieval训练框架,实现了一种可扩展的多模态检索方法。该方法在输入序列中添加固定数量的Meta Tokens,其最后一层上下文表示作为紧凑且富有表现力的多向量嵌入。通过Matryoshka训练策略,模型能够将信息组织为不同粒度的嵌入向量,使用户在测试时可根据计算预算灵活选择索引和检索交互的向量数量,从而在检索质量与效率间取得平衡。实验表明,MetaEmbed在Massive Multimodal Embedding Benchmark(MMEB)和Visual Document Retrieval Benchmark(ViDoRe)上均达到SOTA性能,且在32B参数规模下仍保持良好的扩展性。该方法通过嵌套分组对比学习,在训练时优化不同粒度的嵌入表示,测试时通过调整向量数量实现动态检索,解决了传统单向量方法丢失细粒度信息和多向量方法计算成本高的问题。在ViDoRe基准的多语言和生物医学领域测试中,MetaEmbed-7B在未使用多语言训练数据的情况下仍取得显著提升,验证了其跨模态泛化能力。效率分析显示,尽管计算量随向量数量增长,但GPU吞吐量可有效处理中等规模的检索预算,编码阶段仍是主要延迟来源。该研究为多模态检索系统在保持准确性的同时实现规模化部署提供了新思路。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2509.18095
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.18095
(24) Mano Report
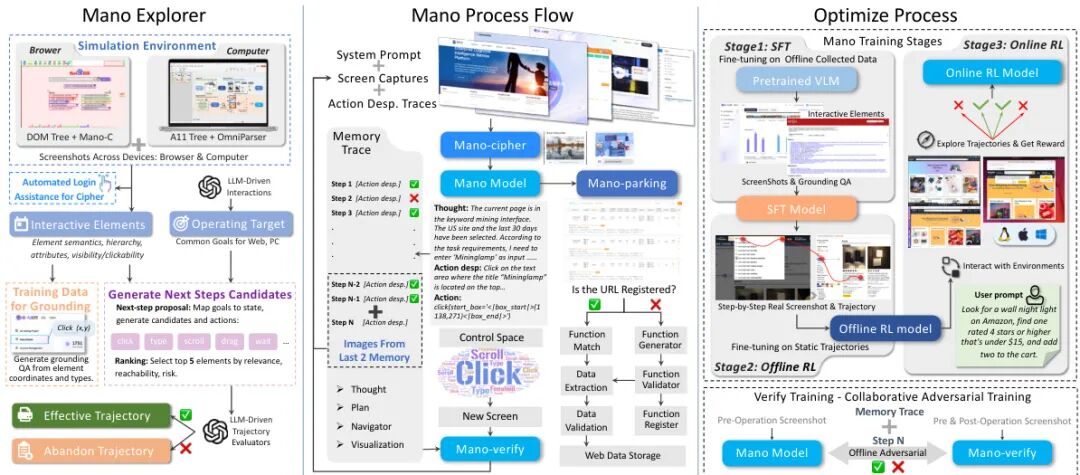
论文简介:
由Mininglamp Technology等机构提出了Mano,该工作构建了一个基于多模态基础模型的鲁棒GUI智能体,通过三阶段训练流程(监督微调、离线强化学习、在线强化学习)和模拟环境生成的高保真数据,在Mind2Web和OSWorld等基准测试中实现SOTA性能。核心贡献包括:1)创新设计的模拟环境可高效生成跨操作系统的高质量交互数据,解决数据不匹配问题并降低真实环境部署成本;2)提出分阶段强化学习策略,采用GRPO算法配合阶段特异性奖励函数,平衡策略稳定性与目标导向优化;3)引入Mano-verify验证模块实现执行过程的实时错误检测与恢复,提升系统可靠性;4)通过闭合数据循环机制,将在线交互数据反哺训练集,持续优化模型适应性。实验表明,Mano在成功率、元素精度等指标上显著超越现有方法,其三阶段训练框架使OSWorld基准得分从25.1提升至41.6。该工作为视觉语言模型在GUI自动化领域的应用提供了数据生成、训练范式和系统架构的完整解决方案,验证了强化学习与多模态模型结合在复杂人机交互场景中的有效性。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2509.17336
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17336
(25) StereoAdapter: Adapting Stereo Depth Estimation to Underwater Scenes

论文简介:
由AI Geeks、澳大利亚机器人中心、北京大学等机构提出了StereoAdapter,该工作针对水下立体深度估计中的域迁移挑战和单目-立体信息融合问题,提出了一种参数高效的自监督框架。通过引入LoRA适配的单目基础编码器与循环立体细化模块的协同架构,结合动态LoRA适应策略和基于UE5引擎构建的40K规模水下合成数据集UW-StereoDepth-40K,实现了水下场景中metric深度的精准估计。核心创新包括:1)设计LoRA模块对DepthAnything V2编码器进行轻量化域适应,在保持几何先验的同时适配水下成像特性;2)构建混合尺度对齐机制,通过稀疏立体匹配验证单目尺度并传播局部修正;3)提出动态LoRA方法,通过可学习重要性权重实现自适应秩选择与持续权重整合。实验表明,在TartanAir和SQUID数据集上分别取得6.11%和5.12%的RMSE提升,并在BlueROV2机器人实际部署中验证了鲁棒性。该方法在Jetson Orin NX上实现1113ms的实时推理速度,较对比方法提升327-702ms,为水下机器人导航、结构检测等任务提供了高效可靠的深度感知方案。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.16415
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16415
(26) BeepBank-500: A Synthetic Earcon Mini-Corpus for UI Sound Research and Psychoacoustics Research

论文简介:
由Amazon的Mandip Goswami等提出了BeepBank-500,该工作介绍了一个紧凑、完全合成的耳标/提示音数据集(300-500片段),专为人机交互和音频机器学习中的快速实验设计。数据集通过参数化生成,涵盖正弦波、方波、三角波及两种FM波形,控制基频(350-1000Hz)、时长(100-500ms)、包络类型(adsr_fast/adsr_med/percussive)、幅度调制(0-30Hz速率,0-0.5深度)及混响(dry/rir_small/rir_medium)等参数。所有音频为48kHz/16bit WAV格式,附带包含声学特征(频谱质心、带宽等)的元数据表,并提供波形分类(log-mel+逻辑回归,准确率81.1%)和基频回归(YIN算法,中位误差0.22Hz)的基线模型。数据集采用CC0-1.0公共领域授权,代码遵循MIT协议,支持可重复的种子生成机制,适用于耳标分类、音色分析、起始检测等任务,但明确排除医疗/安全场景。元数据包含400个片段的确定性划分(train/val/test=80/10/10),并提供声压级、频谱统计、粗糙度代理等30+特征列。未来计划扩展空间化、主观偏好数据等特性。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.17277
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17277
(27) When Big Models Train Small Ones: Label-Free Model Parity Alignment for Efficient Visual Question Answering using Small VLMs

论文简介:
由 Indian Institute of Technology Jodhpur 等机构提出了 When Big Models Train Small Ones,该工作针对小规模视觉语言模型(S-VLM)在视觉问答(VQA)任务中性能不足的问题,提出了一种名为 Model Parity Aligner(MPA)的无监督知识对齐框架。MPA 通过利用无标签图像和大模型(L-VLM)的推理能力,系统性地识别并填补 S-VLM 的知识差距,从而提升其 VQA 表现。该方法摒弃传统依赖标注数据的知识蒸馏范式,转而采用三阶段策略:首先由 L-VLM 生成伪标签,再通过奇偶校验模块(PI)筛选出 S-VLM 答错而 L-VLM 答对的样本,最后通过平衡模块(PL)针对性地优化小模型。实验在 TextVQA、ST-VQA、ChartQA 和 OKVQA 四个数据集上验证了 MPA 的有效性,结果显示其可使 S-VLM 的性能平均提升 3.4%,最高提升达 15.2%,且在跨领域医学 VQA 任务中也表现出泛化能力。值得注意的是,MPA 能兼容闭源大模型(如 GPT-4o),并通过伪标签质量评估机制确保训练可靠性。该研究为资源受限场景下高效部署小模型提供了新思路,同时揭示了知识对齐在多模态任务中的潜力。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.16633
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16633
(28) From Hugging Face to GitHub: Tracing License Drift in the Open-Source AI Ecosystem
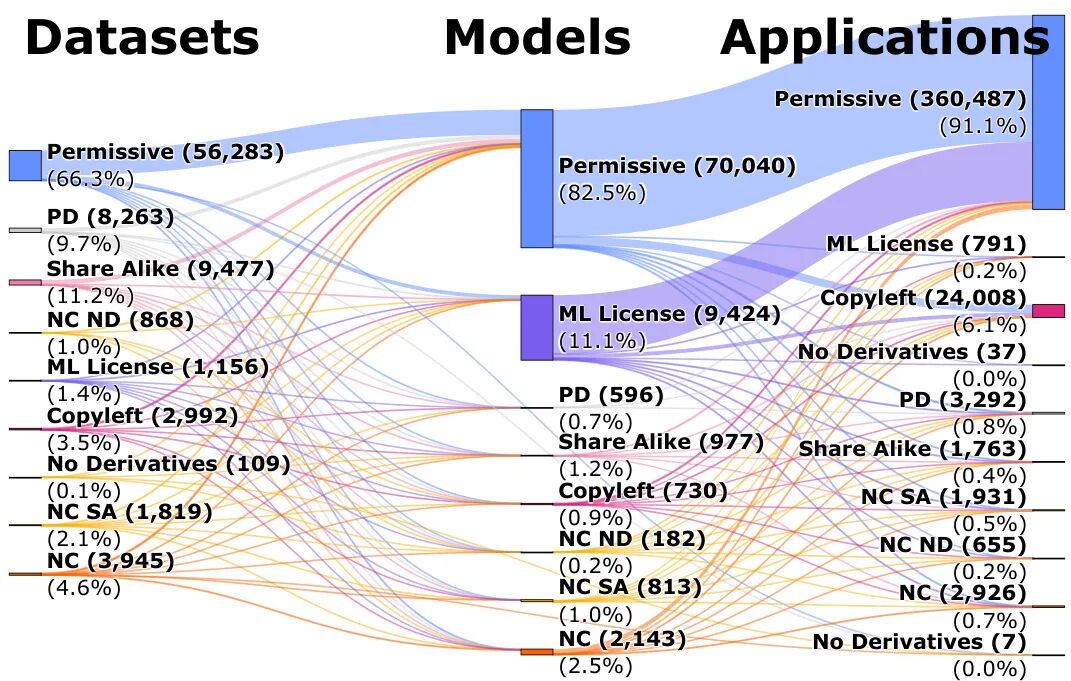
论文简介:
由Queen’s University等机构提出了开源AI生态系统中许可证漂移的端到端审计工作,该工作通过分析36.4万数据集、160万模型及14万GitHub项目的许可证传播路径,揭示了35.5%的模型到应用环节存在违规放宽许可证限制的问题,并开发了可解决86.4%许可证冲突的自动化工具LicenseRec。研究发现开源AI供应链中存在系统性合规风险:从Hugging Face到GitHub的传播过程中,非宽松许可证条款在模型到应用阶段几乎被完全剥离,其中机器学习专用许可证的保留率仅为0.4%,非商业条款保留率6.7%。团队通过构建包含近200条SPDX及模型特有条款的规则引擎,实现许可证冲突的自动检测与合规方案推荐,并通过对比实验表明传统兼容性矩阵在AI场景下的局限性(如欧盟工具仅检测到3.2%的冲突,而本研究方法识别出35.5%)。研究强调开发者对上游许可证义务的认知缺失,特别是模型集成阶段的合规盲区,同时指出工具自动化虽能修正78%-86.4%的错误,但无法解决因上游组件选择不当导致的14.2%根本性冲突。论文通过释放完整数据集与开源工具,为AI生态系统的法律风险治理提供了量化依据与技术支撑。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.09873
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.09873
(29) From Uniform to Heterogeneous: Tailoring Policy Optimization to Every Token's Nature
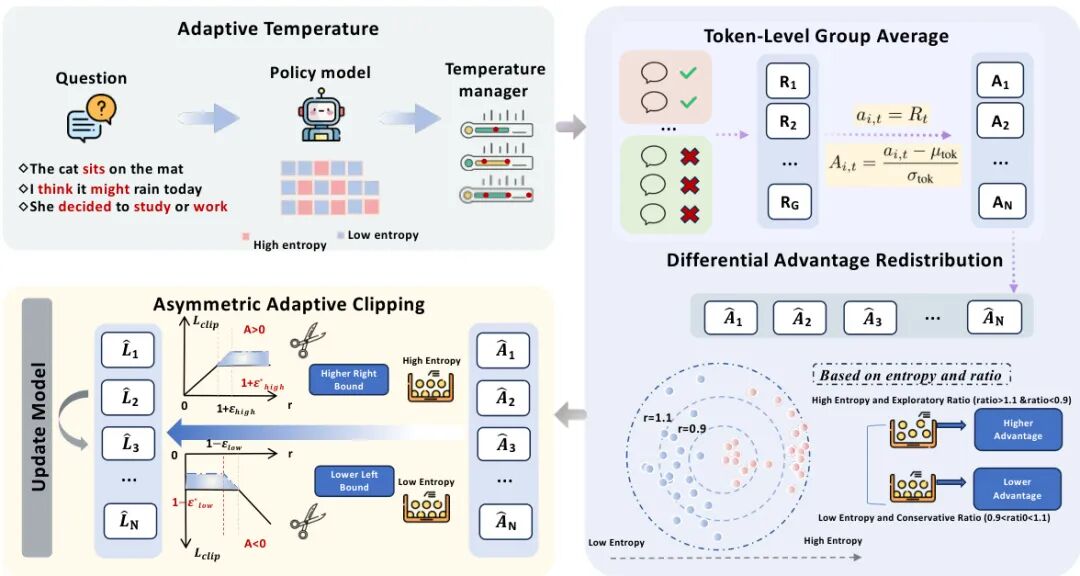
论文简介:
由北京大学、上海人工智能实验室等机构提出的Heterogeneous Adaptive Policy Optimization (HAPO),针对现有强化学习算法在大语言模型优化中忽略令牌异质性的问题,提出了一套基于令牌熵值的动态优化框架。该工作通过系统分析熵值与训练动态的关系,揭示了统一优化策略在探索-利用平衡、优势计算和剪辑损失三个阶段的缺陷,并设计了四项针对性改进:1) 自适应温度采样通过动态调整高熵令牌的采样温度,在保持语义连贯性的同时增强关键推理节点的探索;2) 令牌级组平均优势计算通过跨令牌归一化解决序列长度偏差问题,确保正负样本梯度平衡;3) 差异优势重分配结合熵值与重要性比率信号,对高熵令牌进行优势放大而低熵令牌进行抑制;4) 非对称自适应剪辑通过差异化剪辑边界,允许低熵令牌更激进的概率衰减并促进高熵令牌的探索。实验表明,HAPO在Qwen2.5-Math-1.5B到Qwen3-8B等多尺度模型上,相较DAPO基准在AIME24、AIME25等数学推理任务中提升1.97-3.07个百分点,且计算开销可忽略。该工作通过连续熵值信号实现细粒度优化,证明了令牌异质性建模对提升模型推理能力的重要性,为构建更符合语言生成结构的优化算法提供了新方向。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.16591
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16591
(30) CodeFuse-CR-Bench: A Comprehensiveness-aware Benchmark for End-to-End Code Review Evaluation in Python Projects

论文简介:
由蚂蚁集团、UNSW悉尼、香港浸会大学等机构提出了CodeFuse-CR-Bench,该工作针对现有代码审查基准任务碎片化、上下文贫乏和评估狭窄的问题,构建了首个全面感知的端到端代码审查评估基准。CodeFuse-CR-Bench包含601个来自70个Python项目的高质量实例,覆盖九类问题领域,提供包括关联问题、PR详情和仓库状态在内的多维度上下文,支持端到端评估。研究团队创新性地设计了融合规则检查(定位准确性和语法相似性)与模型判断(审查质量评分)的评估框架,并对多款主流大语言模型(LLMs)进行系统测试。实验结果显示:(1)单一模型无法全面主导所有评估维度;(2)Gemini 2.5 Pro在综合性能上表现最佳;(3)不同LLMs对冗余上下文的鲁棒性存在显著差异。该研究揭示了多维评估的必要性,为开发实用的智能代码审查助手提供了关键基线和方向指引。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.14856
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.14856
(31) DIWALI - Diversity and Inclusivity aWare cuLture specific Items for India: Dataset and Assessment of LLMs for Cultural Text Adaptation in Indian Context

论文简介:
由印度理工学院海得拉巴分校等机构提出了DIWALI数据集,该工作构建了一个包含8817个文化概念、覆盖印度36个子区域17个文化维度的大规模文化特有概念数据集,并通过文化文本适应任务评估了7个开源大语言模型的文化适应能力,揭示了现有模型在子区域文化覆盖和深层文化适应方面的显著不足。
该研究针对现有文化特有概念数据集在印度文化覆盖不足的问题,系统性地构建了包含服装、饮食、节庆等17个文化维度的DIWALI数据集。通过结合GPT-4o提示生成与人工验证的方式,确保每个概念均经过政府官网或学术资源的双重验证。数据集规模达到CANDLE的13倍,在教育、对话和故事生成等多领域评估中,DIWALI使模型的文化适应评分提升37-752个百分点。
研究采用自动评估(文化适应评分、LLM评委)与人工评估(5位印度不同地区标注者)相结合的方式,发现当前模型存在两大问题:1)子区域覆盖偏差,如北方邦概念占比达24%而东北部多邦概念缺失;2)表面化适应倾向,仅完成人名替换却未能建立文化关联(如将"圣诞节"改为"排灯节"但保留"卖CD"场景)。实验显示Gemma-2-9B在精确匹配中得分最高(0.842),但人工评估得分仅2.53(满分5),揭示LLM评委存在评分虚高(平均高出人工评分0.7-2.5分)。
该数据集为文化感知的NLP研究提供了基准资源,可支持文化能力评估、跨文化翻译和文本适应等任务。研究强调未来需开发能理解文化概念深层关联的模型,而非简单的实体替换。数据集已开源,包含概念描述、地域归属和验证来源等结构化信息,为印度文化研究提供了重要基础设施。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2509.17399
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17399
(32) VaseVQA: Multimodal Agent and Benchmark for Ancient Greek Pottery

论文简介:
由AI Geeks、澳大利亚人工智能研究所和拉筹伯大学等机构提出了VaseVL和VaseVQA数据集,该工作针对多模态大语言模型(MLLMs)在文化遗产分析中的局限性展开研究。现有模型在古希腊陶器分析任务中面临两大挑战:通用模型缺乏领域专业知识,而监督微调(SFT)易过拟合表面模式导致推理脆弱。VaseVL通过"评估即监督"的创新框架,构建包含Fabric、Technique、Shape等七类问题的分类体系,先定位SFT模型的类型特异性性能缺口,再通过类型条件奖励优化(如强化Attribution和Decoration任务的语义相似性权重)实现精准改进。其核心创新在于将Group Relative Policy Optimization(GRPO)与KL正则化结合,既保持事实准确性又提升组合推理能力。同步发布的VaseVQA数据集包含31,773张陶器图像及93,544个问答对,覆盖从材料辨识到风格分析的多维度任务,并提供ANLS、日期专用指标及BLEU@1等定制化评估工具。实验显示,VaseVL在Attribution任务准确率从56.96%提升至60.83%,Decoration任务BLEU@1得分从2.57跃升至9.82,显著超越SFT基线模型。该研究不仅为古希腊陶器研究提供首个专用多模态基准,更通过诊断引导的奖励工程范式,为领域定制化MLLM开发提供了可复用的方法论框架,其开源数据与代码将推动文化遗产智能分析的可持续发展。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2509.17191
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.17191
(33) SCAN: Self-Denoising Monte Carlo Annotation for Robust Process Reward Learning

论文简介:
由苏州大学和腾讯等机构提出了SCAN(Self-Denoising Monte Carlo Annotation),该工作针对过程奖励模型(PRMs)训练中人工标注成本高、合成数据噪声大的问题,提出了一种高效的合成数据生成与噪声容忍学习框架。研究发现,蒙特卡洛(MC)估计生成的合成数据存在显著噪声,主要源于标注模型对步骤正确性的低估(复杂推理能力不足)和高估(错误累积导致延迟检测)问题。通过引入自信心度指标,SCAN采用选择性采样策略减少噪声,并设计了模型自去噪损失函数。实验表明,仅用1.5B参数的Qwen2.5-Math-1.5B-Instruct生成的101K合成数据,即可使PRM在ProcessBench上的F1分数从19.9提升至59.1,性能超越基于大规模人类标注数据(PRM800K)的模型。进一步结合Llama3.2-3B-Instruct和Qwen2.5-Math-7B-Instruct生成的197K混合数据后,模型在数学推理任务的Best-of-8评估中达到70.1%的准确率,超过人类标注基准。该方法通过容忍距离标签和置信度重加权策略,在降低6%推理成本的同时显著提升鲁棒性,验证了自去噪MC标注在可扩展、低成本PRM训练中的潜力。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2509.16548
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.16548
-- 完 --
机智流推荐阅读:
1. 聊聊阿里的新深度研究框架:WebWeaver 如何通过双智能体突破传统开源方案“先搜后写”和““静态大纲引导搜索”两种范式
2. SGLang case study:W4A8 GroupGEMM 学习
3. LLM真能读懂报表吗?EMNLP'25首个工业级表格生成报告基准T2R-bench:最强大模型仅得62分
4. 抢先 Qwen Next?腾讯自研 FastMTP 重磅开源:推理速度暴涨 203%,消费级显卡也能跑出无损速度翻倍!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群