近年来,视觉-语言-动作模型已成为实现通用具身智能的一条充满前景的路径。然而,当前解释和引导VLA模型的方法远不及传统机器人技术。机器人技术基于明确的运动学、动力学和控制模型;而VLA模型作为一个“黑箱”神经网络,其解释和引导面临巨大挑战。这种挑战,会导致难以很好地将其部署在真实机器人,因为鲁棒性和可解释性至关重要。
受大语言模型“机制可解释性”最新进展的启发,加州大学伯克利分校提出首个通过内部表征来解释和引导VLA模型的框架。具体而言,该团队把Transformer前馈层内的激活向量投影到词嵌入基底,发现了一系列稀疏且语义清晰的方向,如“速度语义方向”和“方向语义方向”。这些方向与最终动作选择存在因果关联。借助这些方向,该团队进一步提出一种通用、无需微调、无需奖励、无需环境交互的激活干预方法,能够在推理阶段实时调制模型行为。
在两个开源VLA模型π0和OpenVLA上进行评估,借助本论文提出的方法,VLA模型在仿真平台 LIBERO与真实UR5机械臂上均实现了零样本行为控制。证明了具身VLA的“可解释性”可以被系统性地抽取并用于机器人控制,为机器人基础模型的“透明、可引导”新范式奠定了理论与实证基础。

论文标题:《Mechanistic Interpretability for Steering Vision-Language-Action Models》
论文链接:
https://arxiv.org/pdf/2509.00328
收录情况:CoRL 2025
1
解读VLA模型
深度神经网络会层层递进地做出预测:前一层的特征为下一层的计算与表征提供支撑。依照“线性表征假说”,中间层常把不同概念编码为潜空间中的方向。例如,如果一个模型表示了"快"的概念,并且能在其潜在空间中识别出相应的方向,那就能理解模型何时以及如何使用这个概念来产生最终输出。
在多数大模型里,语义方向往往与单个神经元对齐;这一事实已被用来解释视觉和语言模型。近来,稀疏自编码器(SAE)因能挖掘更多方向而受到广泛的关注,但SAE需要海量数据,且结果因所用数据集的不同而产生差异。因此在开源数据稀缺的机器人领域中成为了关键瓶颈。因此,本论文专注于“单神经元特征”。
1.1 VLA训练如何影响VLM在预训练期间学习到的知识?
在VLA训练期间,使用例如Open X-Embodiment之类的数据集,对预训练的VLM进行微调,以模仿在任务描述和图像或状态观测条件下的专家机器人轨迹的控制动作。像RT-2、OPENVLA和π0-FAST等这些VLA,处理动作最常用的策略是指定一小部分很少使用的VLM tokens作为"动作tokens",将其解码为控制输出。VLA训练期间模型的最终输出完全是动作tokens,这就提出了一个问题:VLA是否仍然使用类自然语言的表征来选择适当的控制动作?如果是,语言和动作在训练好的模型中是如何交互的?该团队选择的可解释性技术这些问题有了一些认识:
1)尽管VLA最终输出只剩无语义的动作tokens,但VLA训练并未破坏前馈神经网络(FFN)内部的概念组织,因此VLA Value向量保留了语义含义。
2)VLA模型并非“前几层思考任务、后几层思考控制”,而是从最早计算开始便持续推理并细化动作预测。因此动作tokens遍布各层。

1.2 任务特定微调如何影响VLA
VLA预训练后,通常还需针对具体机器人与任务微调。为探究Value向量在此过程中的变化,比较了π0-FAST 与它在 DROID 数据集微调后的检查点,结果如图3a和3b。

根据结果发现:动作tokens存在非常显著差异,微调后模型对动作tokens的分布变得更集中、更专业化,而预训练模型分布相对平坦。总体而言,这些结果表明微调的主要效果是重新调整模型,使其更容易产生微调任务中使用的动作tokens而忽略其他tokens,对语义tokens的影响则较为有限。
2
引导VLA模型
该团队提出一种可解释的激活层引导方法,如图1所示。这种方法在推理阶段实时修改VLA的基础VLM 中Transformer模块FFN子模块的选定神经元,无需微调、无需环境奖励信号,即可引导机器人行为。

2.1 仿真实验
在LIBERO-Long基准测试的十个长程操作任务套件中评估该团队提出的VLA引导方法,任务可视化如图4所示。

2.2 机器人实验
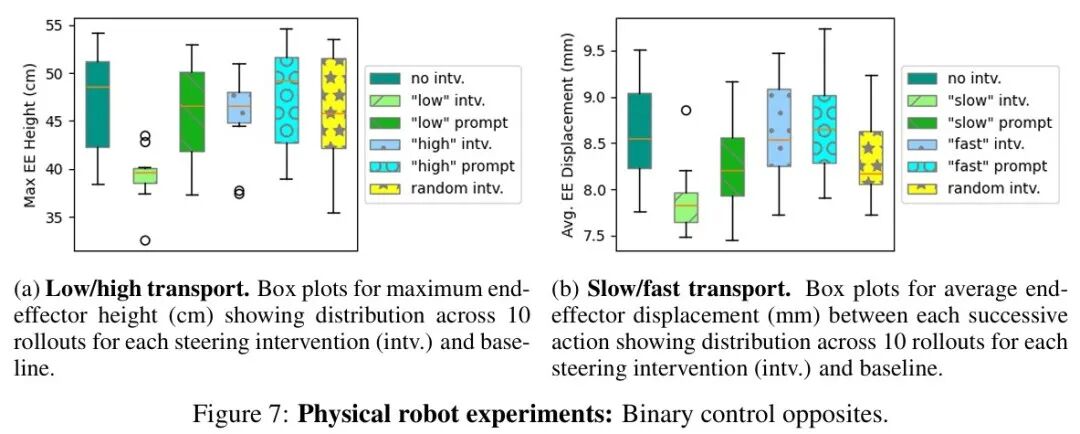
该团队使用了3B参数的π0-FAST VLA在真实机器人上评估了所提出的VLA引导方法。具体来说,在两个UR5机械臂的拾取放置任务中测试模型引导二元对立控制(慢 vs. 快 和 低 vs. 高)的能力。使用运行在NVIDIA A4500 GPU上的π0-FAST的JAX实现。
微调。与DROID等使用标准化机器人平台并包含微调π0-FAST检查点的基准测试不同,该团队的机器人配置未出现在π0-FAST原始训练集中,零样本几乎无法完成任务。为获得可比结果,使用LoRA在从机器人收集的小型数据集上进行了微调。
机器人任务。该团队在两个任务上评估引导。第一个任务是高、低运输,机器人拾取一个玩具企鹅并将其放入篮子中,包含75个片段,其中运输过程中抬起企鹅的高度存在未标记的变化。
第二个任务是快、慢运输,机器人拾取一个玩具海豹并将其放在指定的盘子上,包含120个片段,其中机器人运动速度存在变化。两个任务的可视化如图6a和6b所示。

机器人实验结果。实验结果如下图所示。结果表明,引导干预能够影响π0-FAST的动作。在高、低运输任务中,低干预产生了总体最低的轨迹。快、慢运输任务中的慢干预导致了总体最慢的运动。
但高和快与无干预的基线相似。这可能是因为模型本身认为基线轨迹已经是是快的和高的,表明选择有语义意义的向量可以更有效地引导模型朝向期望行为。此外,该团队还发现引导干预比仅仅在提示中添加目标描述词效果更好。
3
总结
本论文中,加州大学伯克利分校提出首个通过内部表征来解释和引导VLA模型的框架。通过把Transformer前馈层内的激活向量投影到词嵌入基底,发现了一系列稀疏且语义清晰的方向。借助这些方向,进一步提出一种通用、无需微调、无需奖励、无需环境交互的激活干预方法,能够在推理阶段实时调制模型行为。
实验表明,所提出的方法能够跨模型和任务泛化,影响仿真和真实世界中机器人的行为,包括长程LIBERO任务以及在UR5机器人上实现的二元对立控制。
在机器人领域,该方法提供了一种简单的、可解释的工具,用于部署后的机器人行为的控制。它无需重新训练,可在现有策略上运行,并支持快速测试和调整。实验表明,该方法能够调节机器人行为,例如末端执行器的速度或高度,这种方式比使用提示词更为有效。
END
智猩猩矩阵号各专所长,点击名片关注