机器人领域的“快慢双系统”设计思路,正受到越来越多企业的重视。美国著名心理学家Daniel Kahneman将人类解决问题的两种思维模式描述为“系统1”(“System 1”)和“系统2”(“System 2”)。这种理论框架通常源于人类认知的“双过程理论”,系统1是直觉、本能且自动的;系统2则是深思熟虑和有意识的。两者协同形成一种高效决策机制,旨在让机器人既能快速响应环境变化,又能进行深思熟虑的复杂决策。快慢系统解耦,使得可以独立升级慢系统的AI算法,而无需改动底层稳定的控制框架,降低了系统开发的复杂性。
试想一下你的手不小心碰到一个很烫的杯子,快系统(反射系统)会让你的手会“嗖”地一下缩回来,几乎不经过大脑思考,只为了完成躲避这个动作。慢系统(认知系统)会在你缩回手之后,开始思考:“啊,好烫!这个杯子是谁的?我得擦一下洒出来的水。下次要小心点。”这意味着快系统的信号往往只在脊髓层面就完成了处理,保证了你的安全。而慢系统主要在大脑皮层进行逻辑分析、记忆检索和规划,速度慢,但决策更智能、更全面。

机器人采用快慢双系统,有望解决通用性和实用性的平衡问题,让模型既具备通用性特征,实现快速的视觉运动策略,并且经过端到端的训练快速通信从而交互响应。以机器人抓取积木这类机器人展商时常演示的场景为例,假设任务是指令一个机械臂“抓取桌子上的红色积木”,慢系统会进感知、规划、指令下发等决策工作,快系统实时计算每个关节需要输出的扭矩,驱动机械臂平滑、准确地沿着轨迹运动。在执行过程中,如果突然有人碰了一下机械臂,快系统会立即检测到异常,并触发反射,要么紧急停止,要么轻微调整力矩以抵消干扰,然后继续执行任务。如果干扰很大,比如积木被拿走了,快系统可能会上报一个“任务失败”的信号给慢系统,慢系统则会重新开始“感知-规划”的循环。
本文简述了全球10家企业“快慢双系统”的情况,发现尽管各家的命名和实现技术路径略有不同,但所有这些架构都共享一个最根本的共性与设计灵感:借鉴人类认知的“双系统理论”(System 1/System 2)。所有架构都旨在解决机器人领域的一个核心矛盾:高频、精准、安全、高速的底层控制与复杂、抽象、需要推理的高层任务规划难以在单一系统中完美兼顾。快慢分离是应对这一挑战的必然选择,这将原本的长链条端到端模型VLA模型拆开,分成VLM和动作执行两个模型,相当于把机器人的动作规划和动作执行分开,从而实现功能解耦,以及达成“真异步”并行,实现长时序任务的流畅执行,避免机器人因“思考”而“卡顿”。
整体来看,智平方GOVLA和星海图G0等都强调对机器人全身(移动底盘+躯干+双臂)的端到端控制,适用于开放环境下的复杂任务。而Figure AI Helix和PI、星动纪元的早期演示更侧重于上半身的精细操作。但PI的架构特别强调慢系统生成“可解读的中间指令”(类似自言自语),注重决策过程的透明化,便于调试和信任,其他家更多是端到端的内部特征传递。
在数据策略与训练方法上,魔法原子、擎朗以及节卡、微亿智造等,都非常强调在真实场景中采集的海量数据,以减少仿真到现实的GAP。而PI等则大量采用合成数据来高效训练模型的泛化能力。同时,节卡、微亿智造这类企业的路径更偏向基于专家示教的轻量模仿学习,追求在工业场景下的快速迁移、可靠部署,而许多研究机构则探索强化学习等让机器人自主摸索优化的方法。
总而言之,机器人快慢双系统架构或许已成为实现高级别机器人智能的主流范式。然而,在具体实现上,正呈现出百花齐放的局面:有的从通用大模型出发,追求终极的泛化能力;有的深耕特定场景,追求极致的可靠性与效率;有的则致力于软硬件协同创新,打造一体化的最优解。这些不同的技术路径最终将在真实世界的应用中得到检验和融合。
以下是具体的快慢系统介绍。
(1)Figure AI:Helix
2025年2月20日,Figure发布自研通用视觉-语言-动作(VLA)大模型Helix。Helix采用双系统架构,系统1(S1-快思考)+系统2(S2-慢思考)是第一个能够高频率、连续地控制机器人整个上半身的VLA模型,包括手腕、躯干、头部,甚至独立的每根手指,两个系统在机器人内置的双低功耗GPU上异步并行运行。S2作为后台进程持续更新任务意图,S1作为实时进程以200Hz的频率执行闭环控制,标志着端到端的视觉-语言-动作模型在高自由度人形机器人上的成功落地。
其中,S1系统是一个8000万参数的Transformer模型,依赖一个完全卷积的多尺度视觉骨干网络进行视觉处理。该网络完全在模拟环境中进行预训练初始化。来自S2的潜在向量被投影到S1的标记空间中,并与S1视觉骨干网络提取的视觉特征沿序列维度连接,提供任务条件。最后,S1以200Hz的频率输出完整的上半身人形控制,包括期望的手腕姿态、手指屈曲和外展控制,以及躯干和头部方向目标。
S2系统是一个70亿参数的预训练VLM模型,用于处理单目机器人图像和机器人状态信息(包括手腕姿态和手指位置),并将它们投影到视觉语言嵌入空间中。结合指定期望行为的自然语言指令,S2将所有语义任务相关信息提炼为一个连续的潜在向量,以7-9 Hz的频率传递给S1,为机器人的行为决策提供高层次的指导。

(2)PI:Hi Robot
2025年2月27日,PI团队发布他们的快慢系统方案:分层交互式机器人学习系统(hierarchical interactive robot learning system,简称Hi Robot),该系统是PI“π系列”模型中的重要一环,其本质是搭载了“高级决策大脑”的π₀模型,其同样并非来自单个系统,而是源于“慢思考”与“快思考”的紧密协作。后续的π₀.5模型进一步发展了这一思想,它采用协同训练技术,将来自多种机器人、网络数据源的知识融合到单一模型中,让这个模型既能进行高层语义规划,也能输出底层动作,在全新的家庭环境中执行像整理整个厨房这样的长时序任务。
Hi Robot系统能在机器人接收到指令输入后,不仅进行抽象的“思考”(高层推理),还能指导具体的“行动”(低层任务执行),其中上层的VLM会理解这个复杂指令的全局意图,接着将任务分解成一系列清晰的子步骤,并生成相应的中间指令,同时将这些简单的中间指令传递给下层的快系统,下层的VLA(视觉-语言-动作模型,如π₀)直接控制机器人的机械臂和夹爪,完成抓取、移动等精准的物理动作。
该框架可以使机器人处理比以往的端到端指令跟随系统更复杂的提示,并且能在任务执行期间整合反馈(feedback),同时先前的VLA工作和合成数据生成(synthetic data generation)方案组合是主要创新点。因为慢系统背后的VLM技术,得益于海量网络数据的训练,就像人类从书本、网络、影视剧中汲取知识,Hi Robot也因此拥有了更丰富的知识储备,能够更好地理解指令,做出更明智的判断,展现出更强的学习迁移能力。其还在星尘智能等机器人(单臂、双臂和双臂移动机器人)进行了评估,展示了处理清洁凌乱的桌子、制作三明治和杂货店购物等任务的能力。比API-based的VLM(直接调用API)和无分层架构(flat)的VLA policy效果更好。

(3)智平方:GOVLA
2025年4月17日,智平方推出自主研发的GOVLA大模型,该模型采用双系统架构,由空间交互基础模型、慢系统和快系统三部分组成。慢系统基于大规模参数的视觉语言模型(VLM),负责高层次语义理解、上下文推理及任务相关视觉观察和语言指令的解析,输出中间Latent特征作为系统的条件输入。快系统聚焦实时生成可执行动作,依赖慢系统周期性更新的高层推理结果,结合最新观察动态调整动作,类似“直觉与反应”机制。
其工作流程可以概括为“规划与执行的解耦与协作”,当机器人接收到复杂指令后,慢系统首先被激活,它综合空间交互基础模型提供的360度环境感知信息,理解全局意图,并将宏大的任务拆解为一系列可执行的子步骤,这些简单的子步骤指令被传递给快系统,使其将这些抽象指令直接转化为机器人的关节运动指令,控制其全身自由度,完成行走、抓取、操作等一系列流畅的物理动作。在整个过程中,快系统负责底层的平衡和稳定控制,同时将执行状态实时反馈给慢系统。慢系统则能根据这些反馈进行动态重规划,调整任务策略或生成求助信息,从而实现闭环控制。
传统VLA模型通常只能控制机械臂在固定桌面完成简单操作,GOVLA通过快慢系统分工,首次实现了对机器人全身协同控制和移动轨迹的端到端输出,使其能从桌面走向开放环境,同时智平方将DeepSeek语言大模型的技术融入慢系统,显著提升了GOVLA在理解和分析多步骤、开放式任务方面的推理能力,从而具备更强的零样本任务泛化能力。该架构成功打破了机器人“操控效率”与“推理能力”难以兼得的困局,快系统保障了对物理世界的即时响应能力,而慢系统则赋予了处理长程、复杂任务的深度思考能力。

(4)星海图:G0
2025年8月11日,星海图推出端到端双系统全身智能VLA模型G0,助力具身智能突破,该模型构建全球首个开放场景高质量真机数据集,涵盖500小时时长、150个任务、50个场景,附带语言注释,同时创新快慢双系统架构,System-2负责语言交互与任务规划,后台持续分析环境、更新规划,System-1在前台以高频持续执行最新指令,实现实时运动控制,从而构建了一个规划与执行分离、高低频异步协同的智能架构。该架构旨在解决机器人在复杂开放世界中处理长时序任务时,对环境深度理解和全身动作实时控制的双重挑战。
G0模型卓越能力的背后,是星海图在高质量数据和创新性训练策略上的深厚积累,这种在真实非结构化环境中采集的数据,极大地减少了模型部署时的“现实差距”(real-to-real gap),为模型提供了至关重要的泛化能力基础,G0模型的训练并非一蹴而就,而是采用了渐进式的课程学习,其三阶段训练策略能让模型基于获得通用的视觉与语言理解先验知识,在单本体精调的过程中,让模型深度适配特定机器人的动力学特性,最终仅需不到100条特定任务的演示数据,即可让模型快速掌握如整理床铺等复杂新技能,展现了强大的迁移学习能力,最终成功地将深层的语义推理与高频的全身运动控制融为一体,显著提升了机器人在开放环境中的任务泛化能力、执行流畅度和长程规划智能。

(5)擎朗:KOM2.0
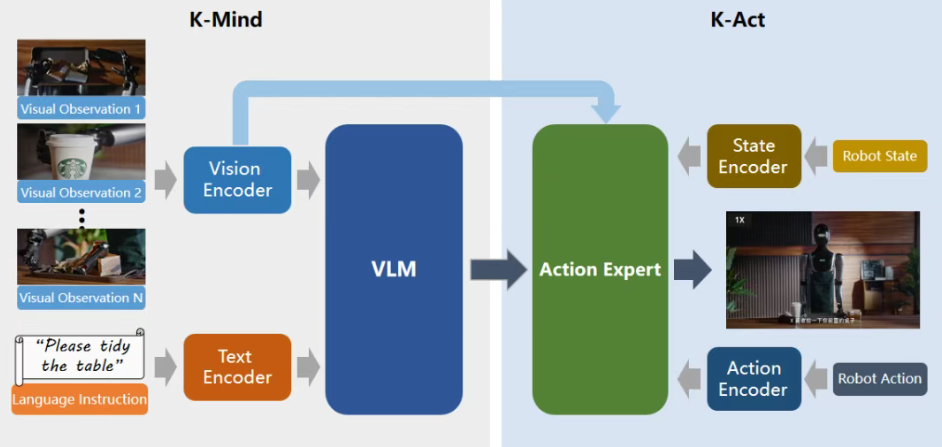
近期,随着今年具身人形XMAN系列的发布,擎朗智能正式升级并发布全球首个针对服务行业的VLA模型:KOM2.0(KEENON Operator Model2.0)。擎朗KOM2.0模型采用了快-慢双系统架构,慢系统(K-Mind)基于VLM多模态大模型,通过擎朗构建的岗位服务场景数据集K-Infinity(KEENON Infinity Dataset)实现对服务场景的环境感知、任务理解与规划,快系统(K-Act)采用Action Expert(动作专家模型),利用大量真机数据进行训练,用于精细的动作生成。擎朗KOM2.0模型,已成为新一代擎朗机器人更具通用性的底座模型。
值得注意的是,在KOM模型之上,擎朗开创性地提出并实践“岗位化”理念,倾力打造了岗位化垂域模型KEENON ProS,该模型是面向具体服务岗位的深度专业化垂直领域模型,可有效提升通用具身大模型在特定垂直领域中的适用性和效率,使得擎朗具身服务机器人掌握餐饮、酒店、商超等场景中具体岗位的技能,实现“岗位化”的快速落地。
擎朗KOM模型的卓越性能根植于公司积累的数亿级场景数据资产,这些数据来源于在真实服务场景中运行的擎朗机器人在此基础上结合部分真机数据,擎朗构建了服务场景数据集K-Infinity(KEENON Infinity Dataset),该数据集具备极强的真实性、多样性和业务相关性,为模型鲁棒性与泛化能力提供坚实基础。
(6)星动纪元:ERA-42
星动纪元的快慢系统架构主要体现在其端到端原生机器人大模型ERA-42中,采用高层次规划与低层次控制的双系统架构,强化了执行层面的能力。两个系统通过latent变量进行通信连接,满足了规划与控制的协同,实现了高频执行与深度思考能力的无缝融合。星动纪元的创新之处在于,它并非让“快”与“慢”两个系统轮流工作,而是通过端到端的架构让它们并行协同运作,类似慢思考的世界模型使用70亿参数的Instructblip视觉语言模型,负责理解任务和生成动作序列,会对任务进行“预演”,生成未来几秒的动作预测,这使得使用4000万参数的Transformer模型,类似快思考高频执行系统在动作开始时,就已经有了一个优化的参考轨迹。当遇到突发干扰时,高频执行系统会优先进行快速局部调整,同时世界模型会快速重新预测后续动作序列,确保任务能在干扰后继续顺利执行,这赋予了机器人强大的抗干扰能力。
星动纪元的ERA-42技术架构可以理解为一种“模型大脑引领,高性能本体执行”的深度集成模式,它通过端到端VLA模型追求通用智能的上限,同时通过全栈自研的高性能硬件本体确保复杂任务执行的下限,二者通过数据飞轮形成闭环,共同推动机器人向通用具身智能的目标演进。

(7)节卡:JAKA EVO
节卡机器人的快慢脑架构,主要体现在其JAKA EVO工业具身智能平台的设计中。该架构的慢系统能实现快速任务解析与规划,当下达一个指令后,它利用视觉大模型和多模态感知系统“看懂”环境,精准识别工件,接着将复杂的指令分解为一系列有序的子任务,然后规划好的子任务被传递给一个轻量化的决策网络(可视为快慢系统间的桥梁),它负责将每个子任务拆解为具体的、可执行的动作序列。最终,这些动作指令抵达快系统,它通过高性能的伺服驱动模块,以极高的频率和极低的延迟控制机器人各关节电机,完成精准的抓取、移动等操作。
在整个过程中,力觉、视觉等传感器数据会实时反馈。快系统负责毫秒级的微调,而慢系统则能处理更复杂的意外情况,并动态调整全局任务计划,慢系统与快系统通过标准化接口实现毫秒级数据交互,但运算过程是并行的,同时,借助轻量模仿学习机制,JAKA EVO平台在交付后能通过少量示教快速迁移适配新场景,打破了传统机器人需要数周调试的困境,极适合小批量、多品种的柔性生产需求。
目前,基于该架构,节卡能使它能作为“大脑”同时调度机械臂、移动平台(如S³机器人)乃至人形机器人(如K1系列)协同作业,实现如“机器人自主组装机器人”这样的复杂流程,并且通过分层处理,巧妙地平衡工业复杂任务的智能决策需求与高精度实时控制要求。

(8)微亿智造
微亿智造的“快慢思考”通过一个无缝集成的“云、边、端”三层技术架构实现,并通过其内部沉淀的感知、学习、决策、执行四大通用技术模块落地,旨在形成一套可在复杂工业场景中规模化应用的通用技术范式,保证了全栈式技术可以根据具体的应用场景灵活组合。得益于快慢双系统,微亿智造的工业具身智能机器人能在人类帮助下快速理解并执行任务,大幅简化部署流程,显著降低部署成本和时间,真正实现“开箱即用”。
其中“快思考”是一套工业具身智能机器人实时直觉系统,专为即时行动与适应而设计破解了机器人无数据难启动的悖论,其建立在云端的人机协作交互机制与设备端的安全与反射机制上实现。“慢思考”则是微亿智造构建深度智能、实现长期自主能力并积累核心技术资产的战略性系统,基于业内规模最大的由真实工业场景产生的精标数据库而来,该数据库的数据量已超过15TB,包含超过10亿条精标数据点,而且基于端侧、边侧共同为工业具身智能机器人提供高速实时的感知、决策与执行能力能实现持续迭代、生成新模型。

(9)魔法原子:原子万象
魔法原子为其人形机器人设计的“原子万象大模型”核心创新在于其仿生认知的“快慢双脑”协同架构。该架构旨在模拟人类的直觉反应与深度思考模式,以解决机器人在复杂动态环境中实时响应与长周期任务规划难以兼顾的根本挑战。
具体而言,其“快系统”扮演动作专家的角色,基于高效的动作专家模型运行。它专责处理毫秒级的实时控制任务,确保了机器人动作的连贯性、精准性与本质安全。与之协同工作的“慢系统”则如同一个策略规划中心,由参数规模更大的多模态大模型驱动。它的职责是进行深度的环境感知与语义理解,并规划复杂的长期任务序列。双系统的协同并非简单串联,而是通过端到端的向量化特征进行高效闭环。慢系统输出的高层任务规划被转化为特征向量,直接传递给快系统进行解码与执行,从而实现了从认知到动作的无缝衔接。这一设计使得机器人能在“慢系统”持续进行后台规划的同时,“快系统”不间断地执行动作,实现了真正的异步并行处理,大幅提升了任务效率。
该架构的能力源于对真实世界数据的深度依赖。魔法原子通过与追觅科技等战略伙伴合作,在真实工厂、商场等环境中采集了数百万条高价值数据样本用于模型训练。这使得快慢双脑能够深刻理解真实的物理交互规律,而非局限于互联网视频或仿真数据的失真环境,从而具备更强的落地特性。

(10)灵初智能:Psi-R1
2025年4月27日,灵初智能正式推出分层端到端VLA+强化学习算法模型Psi-R1。Psi R1模型采取了“快慢脑”的分层架构,其中快脑S1专注操作,慢脑S2专注推理。Psi R1模型的上层Planner应用自回归的Causal VLM架构,负责场景抽象理解、任务规划决策,经过Action Tokenizer,实现上层视觉—语言—动作三大模态的信息连接和穿透;下层Controller则专注精确控制执行,配合真机强化学习,在大多数灵巧操作任务上表现出人类水平的任意泛化与长程灵巧操作能力。
灵初智能的Psi R1模型的慢脑S2在做环境感知的时候,不只输入了VLM模型中常见的视觉和语言信息,而是连同动作信息(Action Tokenizer)也一同输入。这其中,Action模态的输入内容包含历史动作序列、实时动作反馈、物理交互数据等。而Action Tokenizer模块则强化了多模态融合能力:将动作数据(时序、空间维度)与视觉、语言信息深度融合,构建更完整的物理世界表征,同时快慢脑通过Action Tokenizer隐式连接,端到端训练,协同完成长程任务的灵巧操作。
