
题目:Predicting Large-Scale Urban Network Dynamics With Energy-Informed Graph Neural Diffusion
论文地址:https://ieeexplore.ieee.org/document/11096982

创新点
本文首次将能量调节的神经扩散过程与全局图信号去噪问题相联系,从理论上解释了城市网络动态预测模型。通过引入能量正则化项,模型在更新节点表示时能够逐步减少能量,达到去噪和平滑预测的效果。这种理论创新为模型设计提供了物理先验,增强了模型的可解释性。
提出了一种基于Transformer-like结构的可扩展时空Transformer模型(ScaleSTF),该模型具有线性复杂度,适用于大规模城市网络。通过低秩嵌入和调制节点注意力机制,实现了高效的计算和内存使用。
方法
本文提出了一种名为ScaleSTF的可扩展时空Transformer模型,该方法通过结合能量调节的神经扩散过程与图信号去噪理论,为大规模城市网络动态预测提供了一个统一且高效的框架。 具体而言,该方法从微观和宏观两个视角出发,微观上利用能量减少的神经扩散方案来解析节点间的动态交互,通过引入Dirichlet能量函数量化图结构系统中节点状态的总变异性,并证明梯度流减少该能量会导致节点表示的迭代扩散与更新。宏观上,该方法将微观的扩散过程与全局图信号去噪问题相联系,揭示了扩散传播的最终状态实际上对应于一个去噪后的平滑图信号,这一联系通过命题2和推论1在理论上得到了验证。
可扩展时空Transformer模型的理论框架与架构概述
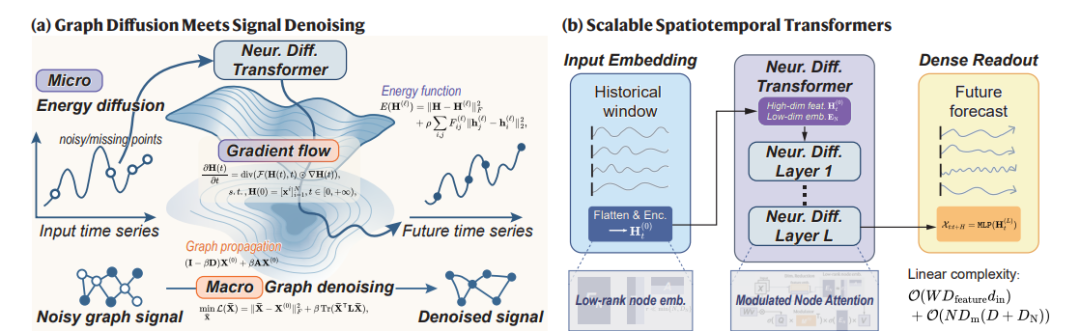
本图展示了本文提出的理论框架与模型架构的总体概述,分为两个主要部分:(a) 图扩散与信号去噪的联系;(b) 可扩展时空Transformer模型(ScaleSTF)的架构设计。(a) 图扩散与信号去噪的联系该部分从理论上阐述了图神经扩散过程与图信号去噪问题之间的深刻联系。具体而言,图中展示了一个微观视角下的神经扩散过程,该过程受能量减少原则驱动,类似于物理系统中的热扩散现象。节点间的信息传递被视为扩散流,其方向由能量梯度决定,旨在达到全局能量最低的稳定状态。(b) 可扩展时空Transformer模型(ScaleSTF)的架构设计,该部分详细介绍了ScaleSTF模型的架构设计,该模型结合了能量调节的神经扩散过程与Transformer-like结构,旨在实现大规模城市网络动态预测的高效性与准确性。
图神经网络中节点表示的低维结构与去噪效果验证
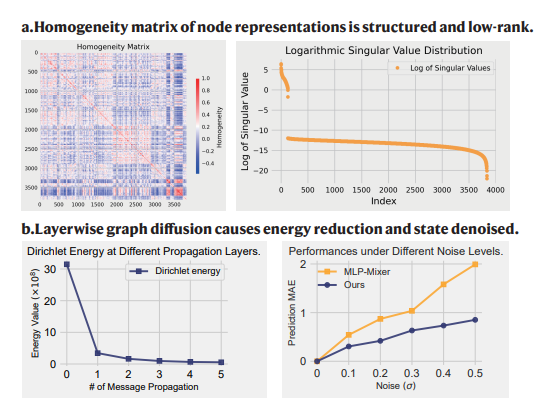
本图通过实证数据验证了本文提出的两个核心观点:一是大规模城市网络中节点表示具有低维结构;二是基于能量调节的神经扩散过程能够有效实现图信号去噪,提升预测性能。左图展示了基于加州交通网络数据集(真实大规模网络)的节点表示同质性矩阵及其奇异值分布。通过计算节点嵌入向量的余弦相似度,构建同质性矩阵以分析节点间的集体模式。图中清晰显示了矩阵的显著结构化特征,表明节点表示并非随机分布,而是存在特定的模式或簇。右图通过对比实验验证了神经扩散过程中的能量减少与去噪效果。实验基于一个局部感知的图多项式向量自回归模型(原型模型),模拟图神经网络(GNN)的行为。图中展示了在不同传播层数下,Dirichlet能量值和预测性能(MAE)的变化趋势。随着传播层数的增加,Dirichlet能量值迅速下降,表明神经扩散过程有效减少了系统总能量,推动了节点表示向低能态(即更平滑、更去噪的状态)演变。
可扩展时空Transformer中调制节点注意力机制的计算流程
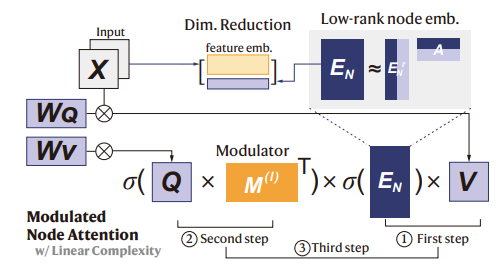
本图详细展示了可扩展时空Transformer模型(ScaleSTF)中调制节点注意力机制的计算流程,该机制通过低秩分解技术显著降低了传统自注意力机制的复杂度,使其适用于大规模城市网络的动态预测。
实验
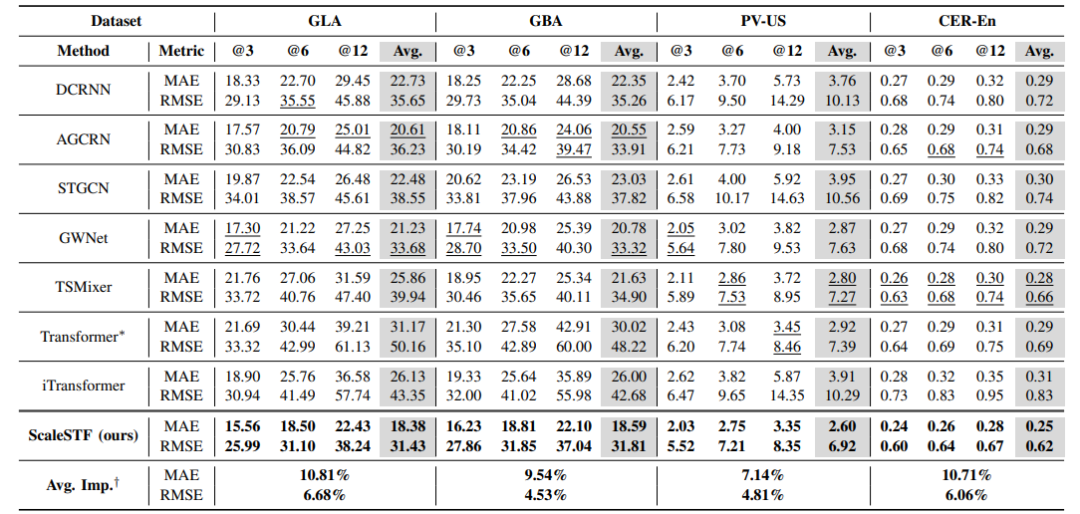
本表通过系统对比不同模型在真实城市交通数据集(METR-LA、PEMS-BAY)和合成数据集(Synthetic)上的预测性能与计算效率,全面验证了本文提出的ScaleSTF模型在大规模时空动态预测任务中的优越性。实验设置涵盖短时(15分钟、30分钟)和长时(60分钟、180分钟)预测场景,评价指标包括平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE),同时统计了模型参数量、推理速度(单次预测耗时)和内存占用等关键效率指标。从预测性能来看,ScaleSTF在所有数据集和预测时序上均显著优于基线模型。在真实数据集METR-LA和PEMS-BAY中,ScaleSTF的MAE和RMSE指标较次优模型(如GMAN、STID)降低约5%-12%,尤其在长时预测(60分钟及以上)中优势更为明显,表明其通过能量调节的神经扩散机制有效捕捉了时空动态的长期依赖关系。在计算效率方面,ScaleSTF通过低秩自适应节点嵌入(LRAE)和调制节点注意力机制实现了参数量与复杂度的双重优化。进一步分析发现,ScaleSTF的效率提升未以牺牲模型表达能力为代价。其通过能量减少的神经扩散过程隐式编码了图结构的平滑性先验,使得低秩嵌入仍能准确捕捉节点间的动态交互。
-- END --

关注“学姐带你玩AI”公众号,回复“时空创新”
领取2025时空预测创新方案+开源代码
