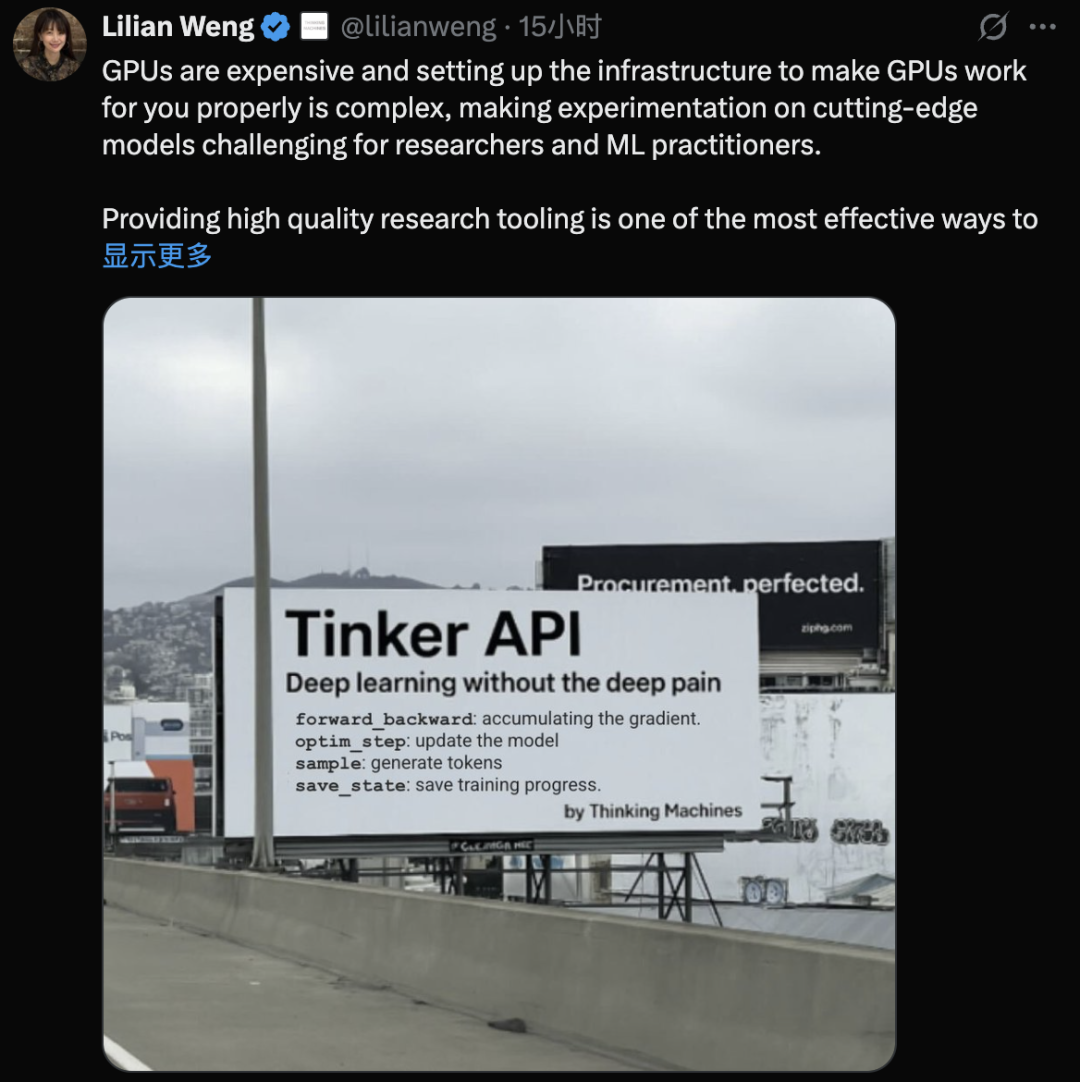
今天,AI圈知名独角兽Thinking Machines终于发布了旗下第一款产品:Tinker,一个用于微调语言模型的灵活API。该公司由前OpenAI首席技术官Mira Murati、前OpenAI联合创始人John Schulman、前OpenAI研究副总裁Barret Zoph以及前OpenAI安全副总裁&北大校友翁荔 (Lilian Weng)等数位高管联合创立。今年7月份,Thinking Machines融资20亿美元创下硅谷种子轮融资之最,成立仅5个月公司估值便飙到120亿美元,此前由于没有任何产品拿出手而被吐槽是“0产品”AI独角兽,Tinker的推出总算是完成了首款产品破壳。该公司联合创始人翁荔发帖表示:“GPU价格昂贵,并且设置基础设施以使GPU正常工作非常复杂,这使得研究人员和ML从业者对尖端模型进行实验具有挑战性。提供高质量的研究工具是提高更广泛社区研究生产力的最有效方法之一,而Tinker API是我们实现这一使命的关键一步。”目前,Tinker已面向研究人员和开发者开放内测。Tinker并非又一个拖放式界面或黑盒调优服务,相反,它提供了一个对开发者用户很友好的API,让研究人员能够精细地控制损失函数、训练循环和数据工作流——所有这些都用标准的Python代码实现。
实际的训练工作负载在Thinking Machines托管的基础架构上运行,从而实现快速分布式执行,而无需担心任何常见的GPU编排问题。
具体而言,Tinker的核心功能主要包括四方面:
1、Python原生原语(如forward_backward和sample)使用户能够构建自定义微调或RL算法。
2、支持小型和大型开放重量模型,包括Qwen-235B-A22B等混合专家架构。
3、与基于LoRA的调整集成,允许多个训练作业共享计算池,从而优化成本效益。
4、一个名为Tinker Cookbook的开源配套库,其中包括后训练方法的实现。

在公开亮相之前,Tinker已在多个研究实验室投入使用。早期采用者包括来自伯克利、普林斯顿、斯坦福和Redwood研究中心的团队,每个团队都将该API应用于独特的模型训练问题:
普林斯顿大学的Goedel团队对LLM进行了微调,使其能够用于形式化定理证明。他们仅使用20%的数据,就利用Tinker和LoRA实现了与Goedel-Prover V2等全参数SFT模型相当的性能。他们的模型在Tinker上训练,在MiniF2F基准测试中达到了88.1%的pass@32精度,在自校正测试中达到了90.4%,超越了规模更大的闭环模型。
斯坦福大学Rotskoff实验室使用Tinker训练化学推理模型。通过在LLaMA 70B基础上进行强化学习,IUPAC到分子式转换的准确率从15%跃升至50%,研究人员表示,这一提升此前若无大型基础设施支持,是无法实现的。
伯克利的SkyRL运行自定义多智能体强化学习循环,涉及异步离线策略训练和多轮工具使用——由于Tinker的灵活性而变得易于处理。
Redwood Research使用Tinker对Qwen3-32B进行强化学习训练,以完成长上下文AI控制任务。研究员Eric Gan表示,如果没有Tinker,他很可能不会开展这个项目,并指出扩展多节点训练一直是一个障碍。
这些示例展示了Tinker的多功能性——它既支持经典的监督微调,也支持跨不同领域的高度实验性的RL管道。
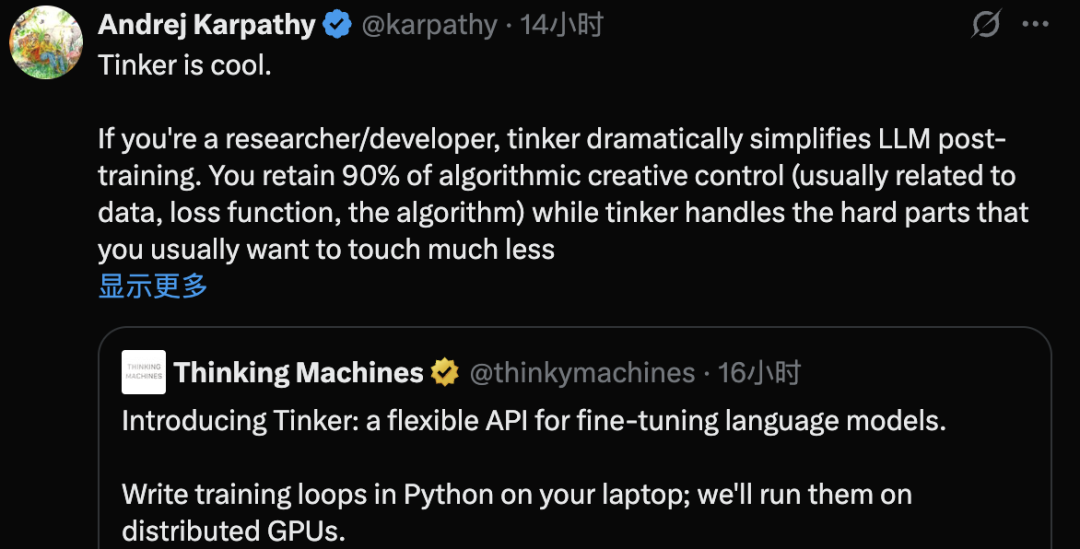
前OpenAI联合创始人、前特斯拉AI负责人Andrej Karpathy(现为AI原生学校Eureka Labs负责人)对Tinker的设计权衡表示赞赏。他表示,Tinker很酷,如果你是研究人员/开发人员,Tinker可以显著简化LLM的后训练流程。开发者可以保留90%的算法创作控制权(通常与数据、损失函数和算法相关),而Tinker则会处理你通常不太常用的复杂部分(底层、LLM 本身的前向/后向、分布式训练),这意味着用户可以以远低于<10%的典型复杂度完成这些工作。伯克利SkyRL计算机科学博士Tyler Griggs表示,过去几周的使用测试留下深刻印象,Tinker大大减轻了LLM的训练负担,非常适合那些专注于算法和数据而非基础设施的研究人员。他认为Tinker的接口有潜力在开源软件(OSS)中更广泛地流行起来,成为训练的标准接口,类似于OpenAI API的推理接口。Philipp Moritz和Robert Nishihara是AnyScale的联合创始人,也是广泛使用的开源AI应用程序扩展框架Ray的创建者,他们强调了将Tinker与分布式计算框架相结合以实现更大规模的机会。开发者们认为,Tinker有望掀起大模型“傻瓜式”微调潮流,几行Python就能把任意规模的模型训成自己的专属模型。在市场分析师看来,Tinker API商业模式本质是finetune as a service,类似的微调模型方式,目前还没有一个通用化的解决方案,而是在私有化定制方案一单一单的做,Tinker有望推动前沿模型微调更加民主化。微调并非新鲜事,如何包装才是。Tinker将繁琐的部分(GPU集群编排、分布式训练稳定性、检查点、故障恢复)抽象出来,同时将底层控制权交给开发者用户。该公司创始人Mira Murati曾在今年初宣布公司的愿景,强调了三大支柱:1、帮助人们根据自己的特定需求调整人工智能系统;2、为强大且安全的人工智能奠定坚实的基础;3、通过公开发布模型、代码和研究来促进开放科学。目前来看,Thinking Machines并非要致力于开发另一款AI模型和生成式应用。它正在构建工业级的训练后即服务,拥有足够的控制权来进行真正的研究,并具备足够的抽象能力以避免对集群进行过度监管。他们押注基础设施层——那些允许他人定制开发模型的工具——现在比囤积基础模型机密更重要。从更宏观的市场角度来看,美国目前在最先进的专有模型方面处于领先地位,中国在广泛发布的开放权重方面处于领先地位。这种不对称创造了一个前所未有战略机遇:如果价值重心从训练最大的基础模型转移到快速安全地调整强大的开放模型,那么最重要的公司就会成为降低大规模定制门槛的公司,Thinking Machines就是最先受益的公司。
即使权重来自其他地方,工具也可以重新平衡影响力,这也重新定义了“开放性”。发布模型权重是一种开放性,发布强大的、研究级的训练后工具是另一种,Tinker瞄准的是后者,其目标并非取代“AI军备竞赛”,而是拓宽入口。