
致力于发展人工智能超级运算的公司Cerebras Systems,继、,2024年WSE-3(Wafer Scale Engine 3 )以及由该款芯片构成的 CS-3 超级计算机系统后,继续加快运营及IPO步伐。

其最新完成的 11 亿美元 G 轮融资,这笔融资不仅为 Cerebras 争取到更多时间拓展客户群体并实现业务多元化,也为其 2024 年 10 月宣布的首次公开募股(IPO)计划增添了筹码。据悉,该公司最初计划通过 IPO 募资 7.5 亿至 10 亿美元,对应估值 70 亿至 80 亿美元。而 G 轮融资后,Cerebras 的估值已达 81 亿美元 —— 这意味着它无需经历 IPO 的繁琐流程,便已实现了预期的融资规模与估值。但这很可能是 IPO 前的最后一轮融资,预计 2026 年将是其登陆资本市场的关键节点。届时,AI 投资或将迎来局部峰值,甚至可能是生成式 AI 泡沫破裂前的最后高点。无论如何,2026 年注定是 AI 热潮突破新高度的年份,也将是叩响华尔街资本大门的最佳时机。
此轮融资由富达投资(管理资产规模近 6 万亿美元的金融巨头)和阿特柔斯管理公司(Atreides Management)领投。后者由曾在互联网泡沫时期执掌富达投资组合长达 20 年的加文・贝克(Gavin Baker)创立,其妻子亦为这家金融巨头的基金经理。值得关注的是,此次融资并非来自中东石油资本,而是波士顿的专业投资机构 —— 这对 Cerebras 而言意义重大。参与 G 轮的还包括 Benchmark Capital、老虎环球基金、Valor Equity Partners 等知名机构。截至目前,该公司累计融资已达 21.6 亿美元,其中包括阿联酋 G42 控股集团注资的 3.35 亿美元受限资金(G42 亦是 Cerebras 当前最大的客户)。
根据 Cerebras 去年向美国证监会提交的 S-1 文件显示,2023 年第三季度至 2024 年第二季度期间,G42 贡献了 1.187 亿美元的销售额,而此前两年半内其他所有客户的采购总额仅为 5580 万美元。尽管过去一年的财务数据尚未披露,但据已知信息,该公司此前持有 4.275 亿美元现金,尽管净亏损仍在扩大,但过往融资应仍留有部分储备资金。
有趣的是,富达与阿特柔斯均持有 AMD 股份 —— 根据公开文件,AMD 是阿特柔斯投资组合中占比最大的标的,紧随其后的是 Pure Storage。该基金管理资产达 36 亿美元,持仓涵盖谷歌、英伟达、亚马逊等科技巨头,同时也投资了 SpaceX、特斯拉等创新企业,以及 Mythic AI、Electric AI 等 AI 初创公司。值得一提的是,阿特柔斯还是今年 2 月马斯克牵头收购 OpenAI(报价 974 亿美元)的财团成员之一,而 Cerebras 很可能已成为其当前最大的单一投资标的。
富达投资的 AI 版图同样庞大,其投资组合包括 OpenAI、Anthropic、CoreWeave、Databricks 等行业领军企业,以及 SpaceX 等前沿科技公司。
富达与阿特柔斯对 AMD 的重仓,似乎暗示着它们在 AI 领域的多元布局策略。这与 Cerebras 的创始团队背景密不可分 ——2012 年,他们将微服务器公司 SeaMicro 以 3.34 亿美元出售给 AMD,此后在 AMD 任职数年。尽管 AMD 于三年后终止了 SeaMicro 的服务器业务,但安德鲁・费尔德曼(Andrew Feldman)等核心成员并未放弃,转而挑战晶圆级芯片技术 —— 这一梦想最早可追溯至 1980 年代,由 IBM System/360 大型机架构师吉恩・阿姆达尔(Gene Amdahl)创立的 Trilogy Systems 曾试图实现。
Trilogy Systems 在 1980 年代初就募集了惊人的 2.3 亿美元(按通胀调整后接近 10 亿美元),创下硅谷融资纪录。但当这家晶圆级计算先驱于 1984 年上市时,其制造工艺良率不足,而其他芯片设计技术正依托摩尔定律实现性价比突破。该公司成为硅谷早期科技乐观主义与快速失败的经典案例。如今,Cerebras 虽致力于将阿姆达尔 45 年前的构想商业化,却极力避免重蹈覆辙(毕竟阿姆达尔后来成功创立了大型机克隆业务,或许 Cerebras 若转型,也可能开发全新 GPU 与 AMD、英伟达正面竞争)。
晶圆技术的维度突破
当其他 XPU 供应商(包括英伟达、AMD 等 GPU 厂商)还在比拼单个计算引擎插座内能集成多少光罩限制芯片(面积约 800 平方毫米)—— 从 1 颗到 2 颗、4 颗,甚至未来十年可能增至 6 至 8 颗时,Cerebras 从创立之初就选择了晶圆级路线。由于 450 毫米晶圆在经济与技术层面均不具可行性,行业目前仍停留在 300 毫米晶圆时代。若 Cerebras 能转向 450 毫米晶圆,其晶圆级引擎(Wafer Scale Engine)的性能可直接提升 2.25 倍,而无需依赖制程工艺迭代。
Cerebras 将直径 300 毫米的圆形晶圆切割为四边形,通过切除四条弦边,在单晶圆上实现 46,225 平方毫米的电路面积。以下是三代晶圆级引擎对这一面积的利用演进:
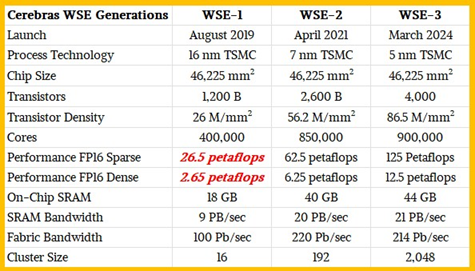
每套系统仅搭载一颗 WSE 芯片,显然也可通过集群部署提升算力。当 WSE-3 发布时,其设计因拓展计算单元、提升性能,同时适度增加片上 SRAM 带宽与容量而备受赞誉。但生成式 AI 革命的爆发彻底改变了需求格局 —— 混合专家模型与推理模型的兴起,大幅推高了内存需求:如今用户不再满足于单次模糊应答,而是需要同时处理数十至数百个模型,以覆盖多样化任务。
这正是 Cerebras 近期在推理测试中频繁使用 2 至 4 套系统的原因 —— 并非算力不足,而是需要更多 SRAM 存储模型权重与参数。但该公司已不再披露具体使用的系统数量,我们推测其核心诉求已转向提升单晶圆 SRAM 容量。此外,通过 3D 堆叠技术垂直扩展 SRAM 或许是必经之路:类似 AMD 在 Epyc CPU 中采用的 V-Cache 顶部堆叠,或在 Instinct GPU 中通过 Infinity Cache 底部扩展。Cerebras 完全可授权这两种技术,为下一代 WSE-4 引擎集成 SRAM—— 如下表 “困难场景” 所示:
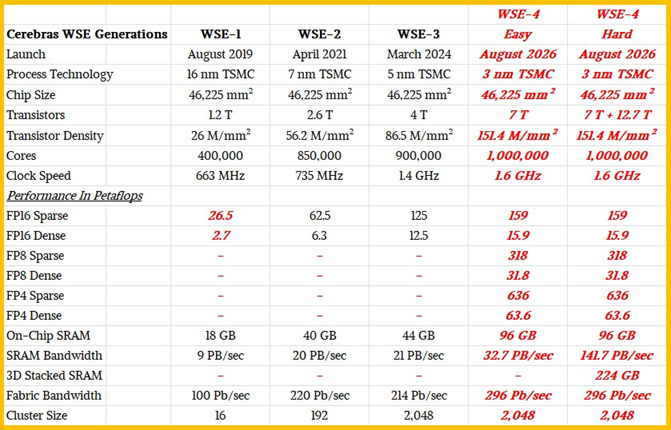
而“简易场景” 下的 WSE-4 则将在芯片上集成更多 SRAM,并为处理单元的 SIMD 引擎添加 FP8 与 FP4 精度计算支持。
本质上,WSE 芯片是大量 SRAM 与嵌入式计算单元的结合体,且内部存在显著冗余设计。从 4 万亿晶体管到 7 万亿晶体管的跃升,主要增量来自缓存扩展 —— 约 2.5 万亿晶体管用于实现 44GB 可用缓存,此外可能还有 10 亿冗余晶体管用于提升良率(部分电路存在缺陷时,可舍弃 20% 以确保 80% 的成品率)。
若 Cerebras 在 WSE-4 中引入类似 V-Cache 与 Infinity Cache 的技术,我们预计其晶体管数量可能增至12.7万亿(是其在2019年推出的第一代1.2万亿晶体管数量的10倍),单晶圆 SRAM 容量或达 320GB。
更激进的“极限场景” 则可能在晶圆外围集成 HBM4 内存 banks,或通过光互连技术构建 Memory-X 堆叠内存系统,作为片上 SRAM 的上层缓存(光互连从芯片顶部引出)。为满足大模型对 KV 缓存的本地化需求,甚至可能需要通过光传输接入高速 NVM-Express 闪存。我们看好 IBM 与微软开发的微流控散热技术 —— 试想晶圆堆叠结构中同时引出水冷管路与光传输通道,将是何等震撼的技术图景。
最后,Cerebras 若想成功上市,必须拿出一份直至 2032 年的技术路线图。英伟达已发布至 2028 年的规划,业界对其硬件演进已有基本预期。Cerebras 需效仿此举 —— 甚至更进一步。路线图可随技术发展动态调整,正如英伟达临时新增的长上下文处理芯片 “Rubin CPX” 所示:技术迭代中总可融入新突破。市场对此完全理解。
推荐:
欢迎加入 EETOP 微信群
报名











