
基于扩散模型(Diffusion Model)的生成方法已显示出用于从离线强化学习 (offline Reinforcement Learning) 数据集建模轨迹的巨大潜力,并且已引入分层扩散(Hierarchical Diffusion)来减轻长期规划任务中的方差累积和计算挑战。然而,现有方法通常假设具有单个预定义时间尺度的固定两层扩散层次结构,这限制了对各种下游任务的适应性并降低了决策的灵活性。
本文介绍一篇研究论文 《Structural Information-based Hierarchical Diffusion for Offline Reinforcement Learning》。该研究提出了一个名为 SIHD 的新型框架,该框架通过分析离线轨迹中内嵌的“结构信息”,自适应地构建一个多尺度的扩散层级,从而在具有稀疏奖励的长时序环境中实现高效、稳定的离线策略学习。
论文标题: Structural Information-based Hierarchical Diffusion for Offline Reinforcement Learning
arxiv地址:https://arxiv.org/abs/2509.21942
代码地址:https://github.com/SELGroup/SIHD
离线强化学习旨在解决一个核心挑战:如何在不与环境进行新交互的情况下,仅利用固定的历史数据集训练出有效的策略。扩散模型通过将策略学习重构为条件轨迹生成任务,有效缓解了分布外(OOD)状态和动作导致的“外推误差”(extrapolation errors)问题 。
为了提升在长时序任务中的效率,分层策略被引入扩散模型,通过将复杂任务分解为由子目标引导的子问题来简化学习过程 。然而,当前主流方法存在两个关键局限:
固定的层级结构:通常假设一个由“子目标层”和“动作层”组成的刚性两层结构,缺乏对不同任务复杂度的适应性。
单一的时间尺度:采用预定义的固定时间步长来分割轨迹,无法捕捉现实世界任务中固有的多尺度时间模式。
这种单一时间尺度划分的固定分层方式阻碍了对不同时间模式和特定任务复杂性的适应性,从而限制了决策性能和灵活性。这提出了离线强化学习中的一个核心开放性挑战:如何系统地分析历史轨迹,以构建一个既可泛化又具有任务感知能力的扩散层级结构?
为应对上述挑战,SIHD 框架从三个方面进行了创新设计:层级构建、条件扩散和正则化探索。
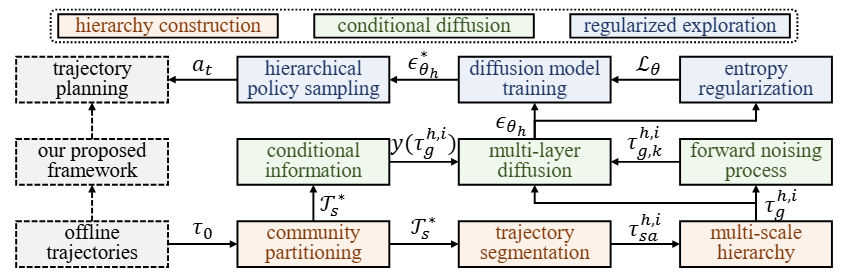
图 1: 所提出的 SIHD 框架包括层次结构构建、条件扩散和正则化探索模块
SIHD 的核心在于其自适应的层级构建机制,它让数据自身的结构来决定层级的划分方式。
(1)构建状态拓扑图:首先,从离线数据集 中提取所有状态元素,并基于特征相似度(如余弦相似度)构建一个 k-近邻状态图 。
(2)挖掘社群结构 (Community Partitioning):接着,应用结构信息原理,通过一个名为 HCSE 的优化算法最小化 K-维结构熵 ,从而获得一个最优的树状编码结构 。这棵“编码树”的每一层都代表了在不同粒度上对状态空间的划分,形成了层次化的“状态社群”。
(3)自适应轨迹分割:基于 定义的社群结构,SIHD 能够为每一条历史轨迹 进行自适应的层级分割。在层级 , 会被分割成多段,确保每个片段内的状态都属于同一个社群。最终,每个片段的末端状态被定义为该层的子目标 。
这一过程使得 SIHD 能够从数据中自动推断出不同任务的动态时间尺度,构建出一个灵活的多尺度扩散层级。
图 2: 通过最小化离线轨迹的结构熵、推导树状结构社区划分、分层分割轨迹以及提取多层子目标序列来构建多尺度分层扩散框架 *
在 SIHD 中,每一层的扩散模型都由其上一层的子目标序列进行引导。与传统方法依赖局部奖励信号不同,SIHD 创造性地使用结构信息增益作为引导信号。
对于层级 的第 个子序列 ,其条件输入 被定义为对应状态社群 的结构信息增益:
此增益项量化了从一个高层级社群(由父节点 $\alpha^{-}$ 表示)过渡到一个更具体的子社群(由节点 $\alpha$ 表示)所获得的“信息量”。这种引导方式不直接依赖于可能稀疏或有噪声的奖励函数,从而使生成过程更加稳定和鲁棒。
为了缓解对有限离线数据集的过分依赖并鼓励有效探索,SIHD 引入了一个 结构熵正则化器。
该正则化项旨在实现两个目标:
(1)促进探索:通过最大化状态分布的香农熵 ,鼓励策略探索数据集中覆盖不足的状态区域。
(2)避免外推误差:通过最小化在每个层级 的社群划分上的结构熵 ,来约束策略不会过度偏离由 编码的行为模式,从而减轻分布偏移带来的风险。
最终的训练目标函数 $\mathcal{L}(\theta_{h})$ 将扩散模型的标准损失与这个正则化项结合起来,尤其是在底层的动作生成模型($h=1$)中,以实现探索与利用的平衡。
研究者在 D4RL 基准测试上对 SIHD 进行了全面的评估,涵盖了标准离线 RL 任务和长时序导航任务。
在 HalfCheetah, Hopper, 和 Walker2D 任务中,SIHD 在不同质量的数据集上均取得了最优的平均回报。
相较于 HDMI 和 HD 等先进的分层基线,SIHD 表现出更强的泛化能力,这得益于其自适应的层级结构和时间尺度。
在中低质量的 "Medium" 和 "Medium-Replay" 数据集上,SIHD 的性能优势尤为突出,平均提升分别达到 3.8% 和 3.9%,验证了结构熵正则化器在缓解数据质量依赖方面的有效性。

表 1: SIHD 与基线方法在 D4RL Gym-MuJoCo 基准任务的 Medium-Expert、Medium 和 Medium-Replay 数据集上的性能比较
在这些奖励稀疏且对长时序规划要求更高的任务中,SIHD 的优势更加显著。
SIHD 在所有导航任务的数据集上均实现了最佳性能,平均奖励在单任务 Maze2D、多任务 Maze2D 和 AntMaze 上分别领先 8.3%, 7.4%, 和 4.4%。
在 AntMaze-Large 数据集上,SIHD 的得分为 89.4,显著高于次优方法 HD 的 83.6。
SIHD 展现了卓越的鲁棒性。在数据质量下降时,基线方法性能最大降幅可达 27.4%,而 SIHD 的降幅被控制在 17.1% 以内,这归功于其正则化的探索机制。
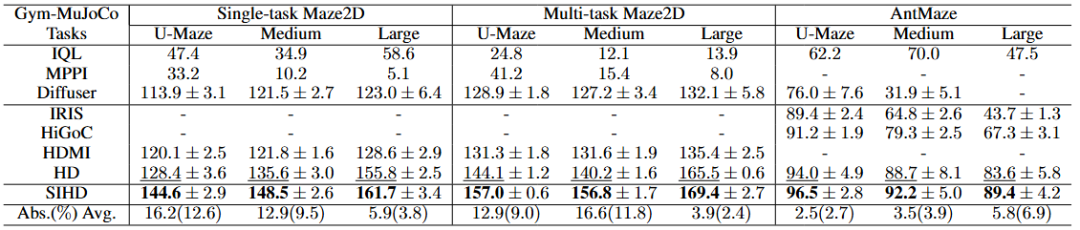
表 2: SIHD 与基线方法在 Maze2D 和 AntMaze 任务的 U-Maze、Medium 和 Large 数据集上的性能比较
消融研究证实了 SIHD 各个组件的必要性,尤其是自适应多尺度层级(SIHD-DH),它的缺失会导致最严重的性能下降,特别是在长时序任务中。

图 3: 在 D4RL 基准中评估的 SIHD 框架内的分层构建、条件扩散和正则化探索的消融研究
本文提出的 SIHD 框架,通过利用离线轨迹中蕴含的结构信息,成功构建了一个自适应的多尺度分层扩散模型。它克服了现有方法在层级结构和时间尺度上的刚性限制,并通过结构信息增益引导和结构熵正则化探索,显著提升了离线策略学习的性能、泛化能力和鲁棒性。
这项工作为分层离线强化学习的研究开辟了新的视角,证明了从数据自身结构出发进行建模的巨大潜力。未来的研究方向包括探索更精细的子目标条件化策略,以及将 SIHD 框架的思想推广到更广泛的扩散式生成模型领域。
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。
10 月 23 - 25 日,QCon 上海站即将召开,95+ 精彩议题已上线!快来锁定参会席位,详情可联系票务经理 18514549229 咨询。

今日荐文

你也「在看」吗?👇










