看今年ICML这类顶会的录用情况,多模态融合+迁移学习这个组合依旧火爆,TPAMI上也有不少相关成果。
而工业界这边,谷歌、微软等巨头的动作,也体现了这个方向明确的商业化路径。总之,这个组合是个挺不错的研究方向,想发论文可以考虑。
目前这方向常见的思路还是参数微调、数据迁移、针对具体问题改进这些。其他的也可以试试边缘设备、生成式迁移这类切入点。
如果想快速找对研究方向,建议直接看我整理的17篇多模态融合+迁移学习的前沿论文,代码已附,可以当做参考,能省不少找资料的时间。
扫码添加小享,回复“迁移多模态”
免费获取全部论文+开源代码

Cross-Modal Dynamic Transfer Learning for Multimodal Emotion Recognition
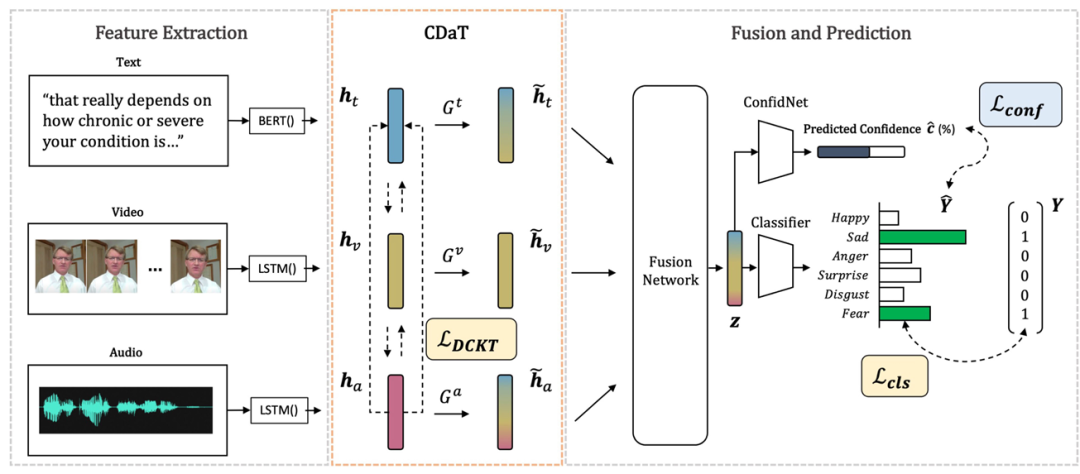
方法:论文提出了一种名为CDaT的方法,用于多模态情绪识别。该方法通过动态过滤低置信度模态,并利用单模态掩蔽和跨模态表示迁移学习来补充高置信度模态,从而解决多模态融合中模态间语义不一致的问题。
创新点:
提出动态跨模态迁移学习方法,动态调整多模态情绪识别中不一致的模态,优化融合效果。 设计辅助网络估计模态置信度,确定低置信度模态并量化知识转移程度,可与任何融合模型结合。 在CMU-MOSEI和IEMOCAP数据集上验证,显著提升多种先进融合模型性能。
A Multimodal Transfer Learning Approach Using PubMedCLIP for Medical Image Classification
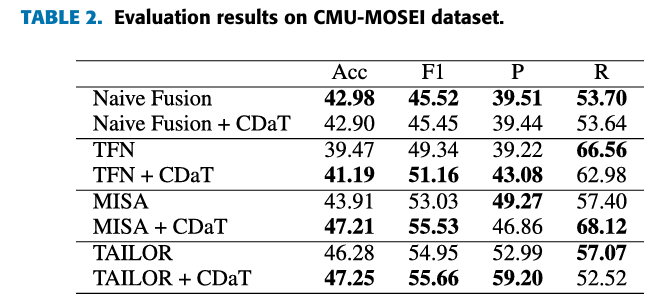
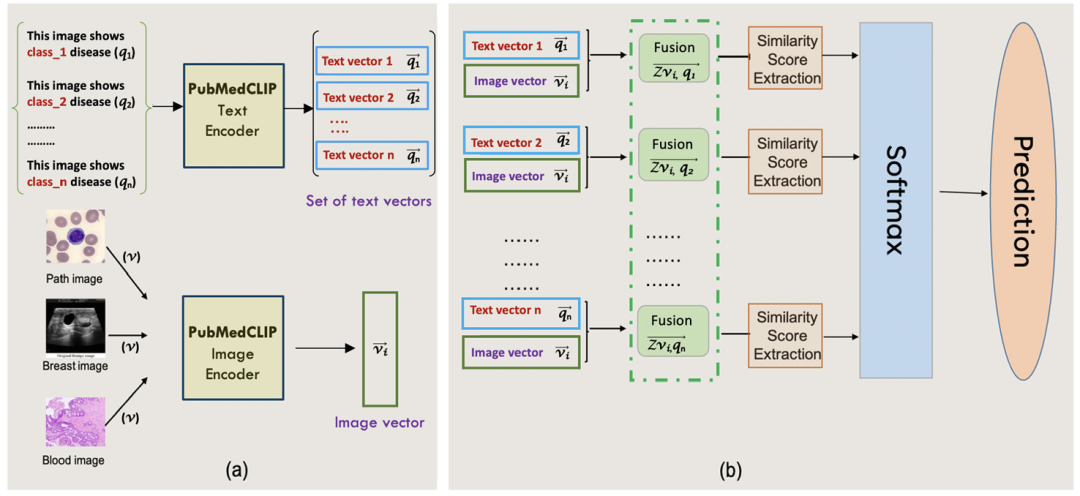
方法:论文提出了一种基于PubMedCLIP的多模态迁移学习方法,用于医学图像分类。该方法通过结合图像和文本提示作为输入,利用PubMedCLIP模型的预训练图像和文本特征表示,并通过多模态特征融合来提高分类性能。
创新点:
利用PubMedCLIP实现多模态迁移学习,结合图像和文本特征提升医学图像分类效果。 设计了多种复杂度的文本提示模板,验证丰富提示可显著提高分类准确率。 在多个医学图像数据集上验证,证明方法在有限训练样本下的鲁棒性和优越性。

扫码添加小享,回复“迁移多模态”
免费获取全部论文+开源代码

MoPE: Mixture of Prompt Experts for Parameter-Efficient and Scalable Multimodal Fusion
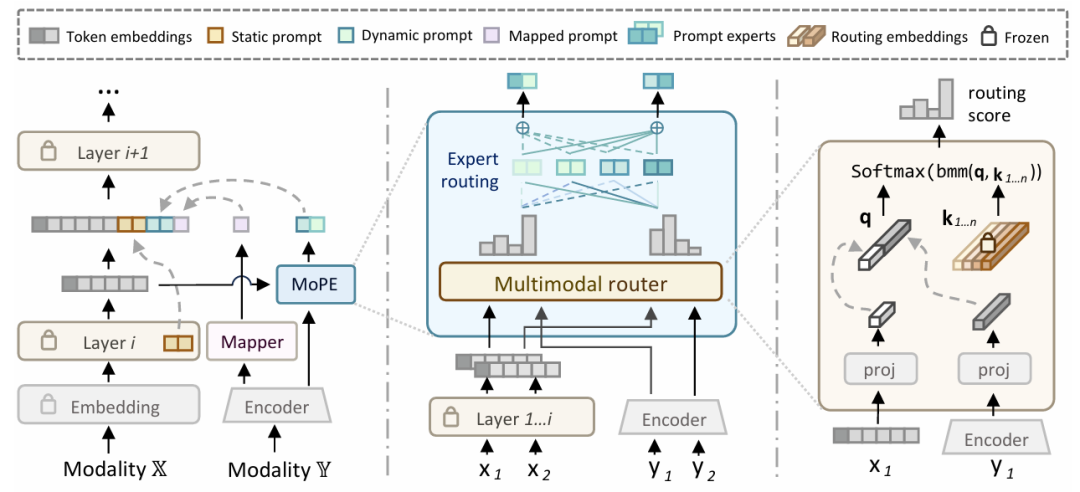
方法:论文提出了一种名为MoPE的方法,用于多模态融合任务。该方法通过将提示分解为静态和动态部分,并利用混合提示专家技术动态生成每个实例的提示,从而提高多模态融合的适应性和可扩展性。
创新点:
提出了一种新的多模态融合方法MoPE,通过将提示分解为静态和动态部分,实现对不同实例的自适应提示学习。 引入MoPE技术,利用多模态配对信息作为先验,动态生成每个实例的提示,提升提示调整的表达能力。 在多个多模态数据集上验证了该方法的性能,结果表明MoPE在参数效率和可扩展性方面优于现有方法。

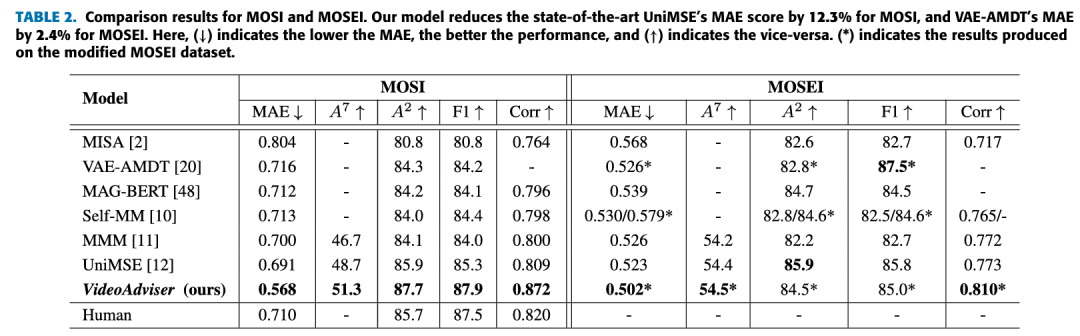
VideoAdviser: Video Knowledge Distillation for Multimodal Transfer Learning
方法:论文提出了一种名为VideoAdviser的多模态迁移学习方法,通过视频知识蒸馏将多模态知识从一个强大的多模态模型(教师)转移到一个特定模态的模型(学生),仅需文本输入即可实现高效推理。

创新点:
提出VideoAdviser方法,通过视频知识蒸馏实现多模态知识从教师模型到学生模型的高效转移。 采用两步蒸馏损失函数,先从分类logits到回归logits,再从教师到学生,优化知识传递。 在视频情感分析和音频-视觉检索任务中,仅用文本输入的学生模型性能显著提升,且推理效率更高。
扫码添加小享,回复“迁移多模态”
免费获取全部论文+开源代码










