

语义归语义,空间归空间:如何实现VLN的完美解耦?
视觉-语言导航(VLN)技术旨在赋予机器“读懂指令、看懂世界、自主行动”的能力。然而,正如人类远行需要可靠的记忆,智能体在复杂的长时序导航中也面临着严峻的“记忆”挑战。
当前主流方法所依赖的显式语义记忆(如文本地图或历史图像序列)已逐渐演变为性能的阿喀琉斯之踵,引发了信息失真、计算冗余与记忆爆炸等一系列问题。
为突破此瓶颈,阿里巴巴高德地图与西安交通大学联合团队从人类认知科学中汲取灵感,重磅推出JanusVLN框架。
该框架颠覆性地提出了双重隐式记忆(Dual Implicit Memory)范式,首次将导航中至关重要的“语义”与“空间”信息进行解耦,并将其编码为两个高效、紧凑且大小恒定的神经记忆表征。
论文标题:JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory forVision-Language Navigation
论文链接:https://arxiv.org/abs/2509.22548
项目主页:https://miv-xjtu.github.io/JanusVLN.github.io/
代码地址:https://github.com/MIV-XJTU/JanusVLN

瓶颈:当前VLN记忆机制的三重困境
长距离、长时序的导航任务对智能体的记忆能力提出了极高要求。然而,当前基于多模态大模型(MLLM)的VLN方法在记忆机制上普遍存在三大核心挑战:
空间信息的“降维打击”
将三维视觉观测转化为离散的文本描述(如“左边有一张桌子”),虽易于LLM理解,却丢失了物体间精确的相对位置、朝向和距离等关键几何信息,导致空间推理能力严重受限。

计算与推理的“雪崩效应”
依赖历史图像序列作为记忆的方法,在每一步决策时都需对不断增长的图像序列进行重复编码和推理。这导致计算成本随导航步数线性攀升,严重影响了模型的实时决策效率。
记忆容量的“无限膨胀”:
无论是文本还是图像形式的显式记忆,其存储量都随轨迹延长而持续扩大。这不仅占用了大量资源,更使模型在冗杂的记忆库中检索有效信息变得愈发困难,即“记忆爆炸”问题。

▲图1| JanusVLN,利用仅RGB视频,将视觉语义和空间几何解耦,从而构建了一种新颖的、固定大小的双隐式记忆。这种记忆在导航过程中会进行增量更新,而其空间几何部分则可以进一步可视化成深度信息和点云。
究其根源,在于现有模型大多沿用为2D图文任务设计的视觉编码器,天然地“重语义、轻空间”,无法充分利用RGB图像中蕴含的丰富三维世界线索。

破局:JanusVLN的双重隐式记忆范式
受人脑在导航时左右半球协同处理语义与空间信息的启发,JanusVLN构建了一套全新的记忆系统,其核心创新点如下:
语义与空间解耦:
JanusVLN创新地将记忆系统一分为二:
语义记忆负责回答“这是什么”,
空间几何记忆负责回答“它在哪”。
二者被建模为独立的隐式神经表征——即神经网络处理后的键值(KV)缓存,而非原始数据。
这种紧凑、高效的表征形式从根本上解决了显式记忆的膨胀问题。

单目RGB驱动的3D感知:
JanusVLN巧妙集成了一个预训练的3D视觉几何基础模型(VGGT)作为其空间编码器。
该模型仅需普通RGB视频流,便能推断出场景的三维结构,赋予智能体强大的“立体视觉”。
这使其摆脱了对昂贵、稀有的深度或激光雷达传感器的依赖,具备了更广泛的应用潜力。

▲图2| JanusVLN框架。给定一个仅包含RGB的视频流和导航指令,JanusVLN利用双编码器分别提取视觉-语义和空间-几何特征。同时,它将初始和最近滑动窗口的历史关键值缓存到双隐式记忆中,以方便特征重用并防止冗余计算。最后,这两个互补特征被融合并输入到LLM中,以预测下一个动作。
恒定开销的增量式更新:
为实现记忆大小恒定,JanusVLN设计了一种新颖的混合增量更新策略。
通过维护一个保留初始场景信息的“初始窗口”和一个聚焦近期环境的“滑动窗口”,模型既能“不忘初心”,又能“与时俱进”。
决策时,模型仅处理当前帧,并与大小固定的隐式记忆高效交互,彻底避免了对历史观测的重复计算,实现了推理效率的飞跃。

实验成果:性能全面领先
我们在两大权威VLN基准VLN-CE和RxR-CE上对J对JanusVLN进行了全面评估,结果全面领先。
定量分析:
降维超越:相较于依赖全景图、深度图等多种昂贵数据源的先进方法,仅使用单目RGB的JanusVLN,在成功率(SR)指标上实现了高达10.5%至35.5% 的绝对提升。
同类最佳:与同样使用RGB输入但采用显式记忆的SOTA方法(如NaVILA, StreamVLN)相比,JanusVLN在SR指标上取得了3.6%至10.8%的领先优势,再次印证了双隐式记忆范式的优越性。

▲表1 | 与SOTA方法在VLN-CE R2R Val-Unseen分割上的比较。外部数据包括标准R2R/RxR-CE数据集以外的任何来源(例如EnvDrop、DAgger、通用VQA等)。StreamVLN*使用EnvDrop作为外部数据。NaVILA*排除了人类跟随数据。所有结果均来自各自论文。一个训练样本是一个动作或一个QA对。Pano、0do、Depth和S.RGB分别代表全景视图、测距、深度以及单色RGB。
卓越泛化:在更具挑战性的跨语言、跨区域RxR-CE数据集上,JanusVLN同样刷新了SOTA记录,SR指标领先此前最佳方法3.3%至30.7%,展示了其强大的泛化能力。
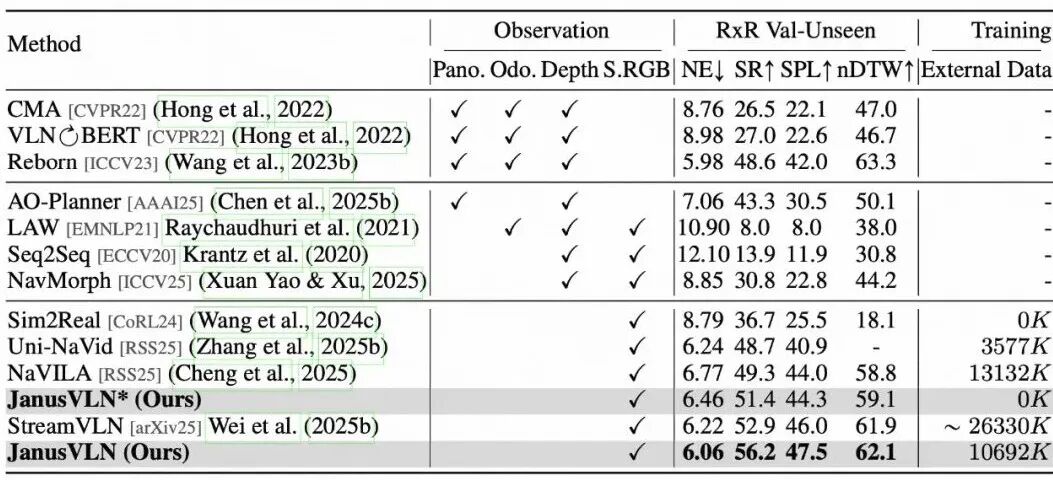
▲表2 | 与SOTA方法在VLN-CE RxR验证未见数据集上的比较
定性分析:
可视化结果显示,在面对需要精细空间推理的指令时(如“走向离你最远的黄色椅子”),JanusVLN能够凭借其空间几何记忆,准确理解场景的远近、内外、左右等三维关系,做出精准的导航决策,成功完成其他模型难以应对的挑战。

▲图4 | JanusVLN在真实世界上的定性结果。

总结与展望
本文提出的JanusVLN框架,通过引入开创性的双重隐式神经记忆范式,成功地将语义理解与空间感知解耦,从根本上解决了传统VLN模型在记忆机制上面临的核心瓶颈。
JanusVLN不仅在性能上刷新了领域SOTA,更重要的是,它推动VLN研究从“2D语义驱动”迈向了“3D时空协同”的新纪元。仅需单目RGB视频流,便能赋予模型强大的三维空间推理能力,并以极低的计算开销实现高效导航。
相信JanusVLN所倡导的隐式记忆与时空解耦思想,将为未来构建更强大、更高效、更接近人类认知能力的具身智能体提供关键的理论基石和技术路径。
编辑|zengshuang
审编|具身君
工作投稿|商务合作|转载
:SL13126828869(微信号)

【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文