
论文题目:Group Sequence Policy Optimization
论文地址:https://arxiv.org/pdf/2507.18071

创新点
GSPO在序列级别进行裁剪(clipping)、奖励(rewarding)和优化,而不是在标记级别。这种设计使得优化目标与奖励的单位保持一致,从而提高了训练的稳定性和效率。
GSPO能够有效解决Mixture-of-Experts (MoE)模型在强化学习训练中的稳定性问题。MoE模型由于其稀疏激活特性,在使用GRPO算法时容易出现专家激活波动,导致训练无法正常收敛。
GSPO的设计使得强化学习训练过程更加简洁,减少了对复杂基础设施的依赖。例如,GSPO可以直接使用推理引擎返回的序列似然进行优化,而无需重新计算,这在部分rollout和多轮RL场景中尤其有益。
方法
本文提出了一种名为Group Sequence Policy Optimization(GSPO)的强化学习算法,用于训练大型语言模型。该算法的核心在于重新定义了重要性比率,将其基于序列似然而非传统的标记(token)级别重要性比率。具体而言,GSPO通过计算整个序列的似然比来衡量从旧策略采样得到的响应与当前策略的偏差,这与重要性采样的基本原理相一致。此外,GSPO在优化过程中采用了序列级别的裁剪、奖励和优化机制,而不是在标记级别进行操作。这种方法不仅避免了标记级别重要性权重的高方差问题,还确保了优化目标与奖励单位的一致性,从而提高了训练的稳定性和效率。
训练奖励曲线
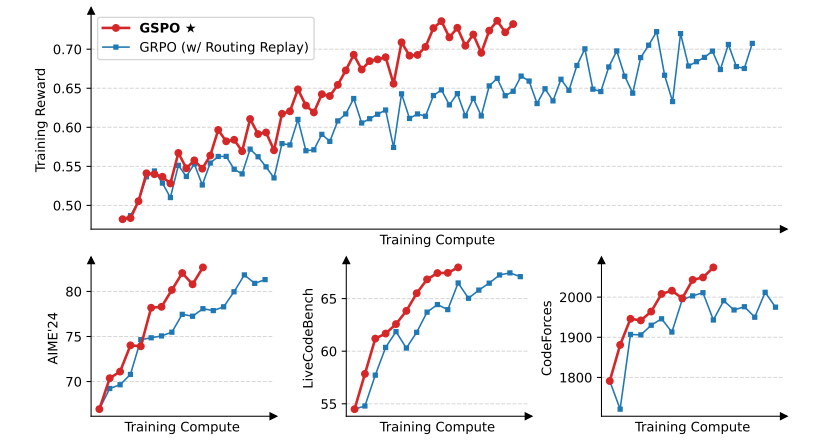
本图展示了使用GSPO和GRPO算法训练语言模型时的训练奖励随训练计算量的变化情况。图中可以看出,GSPO在整个训练过程中表现稳定,随着训练计算量的增加,训练奖励持续提升。相比之下,GRPO算法的训练奖励波动较大,且在相同训练计算量下,GSPO的训练奖励显著高于GRPO。这表明GSPO在训练效率和稳定性方面具有明显优势,能够更有效地利用训练计算资源,实现模型性能的持续提升。
裁剪比例对比
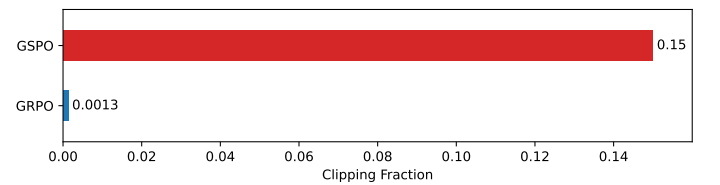
本图比较了GSPO和GRPO在训练过程中裁剪的标记比例。GSPO的裁剪比例远高于GRPO,这意味着GSPO在训练时排除了更多的“离策略”样本。尽管如此,GSPO仍然能够实现更高的训练效率。这一现象表明,GRPO的标记级别重要性权重引入了大量噪声,导致样本利用效率低下。而GSPO通过序列级别的裁剪,能够更有效地筛选出有用的样本,从而提高训练效果。
GRPO中路由重放策略的效果
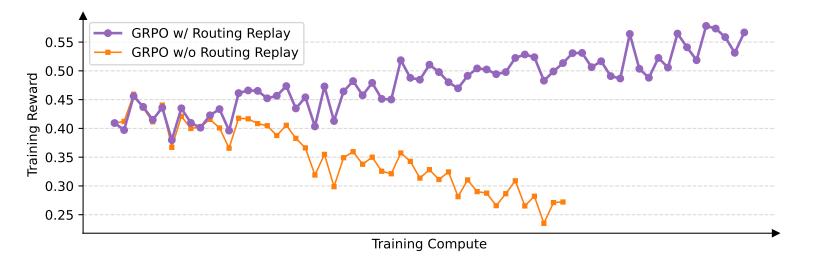
本图展示了在Mixture-of-Experts(MoE)模型的强化学习训练中,GRPO算法在有无路由重放策略时的训练奖励对比。路由重放策略是一种用于稳定GRPO训练的技术,通过缓存并重用旧策略中的专家激活模式来减少专家激活的波动。图中可以看出,使用路由重放策略的GRPO能够正常收敛,而没有该策略的GRPO训练奖励波动剧烈,无法正常收敛。这说明路由重放策略对于GRPO训练MoE模型至关重要。然而,GSPO无需依赖此类复杂策略,即可实现稳定训练,这进一步证明了GSPO在处理MoE模型时的优越性。
-- END --

关注“学姐带你玩AI”公众号,回复“RL优化”
领取2025强化学习优化方案合集+开源代码











