👇扫码免费加入AI知识星球,如您有工作需要分享,欢迎联系:aigc_to_future

作者:Xiaoxiao Ma等

文章链接:https://arxiv.org/pdf/2510.09012
Git链接:https://github.com/krennic999/ARsample

亮点直击
受图像信息稀疏且分布不均的现象启发,而这种特性可通过 token 的熵反映,本文提出了一种面向自回归(AR)图像生成的熵驱动采样策略,该策略可基于熵动态地调整采样行为。 与传统的采样方法(如 top-K 或 top-p)不同,本方法在不修改模型或增加推理成本的情况下,提升了图像质量和结构稳定性,并适用于多种类型的 AR 生成框架。 进一步将熵感知的思想扩展到推测解码中,实现了推理时间减少 15% 的同时,在多个基准上保持了视觉保真度。
总结速览
解决的问题
当前自回归(Autoregressive, AR)图像生成模型在采样阶段存在以下问题:
图像 token 相较于文本 token 信息密度低、空间分布不均,导致语言模型常用的采样策略(如固定 top-K、top-p)不适用。 采样过程中难以平衡内容多样性与结构稳定性:高随机性会造成结构混乱,低随机性则导致图像平淡或过度平滑。 现有方法未考虑图像不同区域的信息差异,因而在生成质量和推理速度上均存在瓶颈。
提出的方案
提出一种基于熵感知(entropy-informed)的自回归采样策略,核心思想是利用预测 logits 的空间熵来指导采样过程:
动态温度控制(Dynamic Temperature Control):
根据 token 分布的空间熵自适应调整采样温度; 对低熵区域(简单或同质区域)引入更高随机性; 对高熵区域(复杂或信息密集区域)采用更严格采样,从而在丰富细节与保持结构间取得平衡。
在 speculative decoding 中引入基于熵的接受规则; 在保证质量几乎无损的情况下,实现加速采样。
应用的技术
信息熵计算:利用预测 token 分布的熵衡量局部信息密度。 动态温度调整机制:在推理阶段按区域实时调整温度,而无需额外训练或显著计算开销。 推测解码优化:在 speculative decoding 框架中引入熵感知接受规则以减少无效采样步骤。 兼容多种 AR 框架:可直接应用于基于掩码(mask-based)和多尺度(scale-wise)的生成模型。
达到的效果
生成质量提升:在多个基准数据集和多种 AR 模型上显著提高图像质量和结构一致性。 多样性与对齐平衡优化:同时增强内容丰富性、文本一致性与结构连贯性。 推理速度提升:在保持近乎无损的图像质量下,推理成本降低约 **15%**(仅为传统加速方法的约 85% 成本)。 通用性强:方法可无缝集成至不同类型的自回归图像生成模型,具备良好的泛化性。
方法
首先介绍自回归图像生成的基础知识。基于图像与文本生成的差异,从熵的角度提出一种在生成过程中调整 token 级随机性的方式,并进一步将这一观点扩展到加速方法中。
预备知识与动机
自回归图像生成。 在典型的自回归生成过程中,一幅图像 被量化为一组离散的 token ,其中每个 token , 表示 VQ-VAE 码本的大小。图像 token 由 transformer 顺序生成,第 个 token 依赖于之前生成的 token。该过程可建模为, 其中 ,且 表示在位置 处 token 的类别分布。
在文本条件生成任务中,完整的图像序列是在一段文本 token 前缀条件下生成的。在每一步中,会应用一种采样方法(如 top-K 或 top-p)从 中选择一个 token。而采样策略的选择会显著影响生成图像的质量,如下图 2(b) 所示。

图像与文本生成的差异。与文本相比,图像中的信息密度更低且分布高度不均。例如,图像中常包含大面积的纯色区域或视觉上相似的内容,而文本中的相邻 token 通常是不同的。为说明这一差异,我们将图像和文本的嵌入序列分段为相等长度,计算每段的平均频谱,并可视化其分布(如图 2(a))。结果显示,图像片段的平均频谱分布更分散,包含大量低频区域;而文本片段的分布更紧凑且均匀。
这种差异对采样提出了挑战:固定参数(如 top-K 或 top-p)虽然在语言生成中有效,但直接应用于所有图像 token 时表现不佳。它们未能考虑空间可变性,从而导致区域性伪影:
过于确定性的采样会损失细节,生成平坦区域、过度平滑或简单背景; 过于随机的采样会破坏语义一致性和结构连贯性,导致伪影、肢体扭曲或纹理混乱。
熵与图像内容的关系。 本文证明了预测 token 分布的熵是图像局部信息密度的有效指标。在每一步生成过程中,计算所有 个码本条目的对数似然熵 ,其定义为:

如下图3所示,内容较为简单的区域(例如纯色区域)通常表现出较低的熵,而更加复杂的前景区域(例如物体、结构和纹理)则具有较高的熵。低熵区域对应于集中在少数 token 上的尖峰分布,表明模型具有较高的置信度。相反,高熵区域表现出更均匀的分布,反映出在 token 选择上的更大不确定性和更高的信息密度。这些观察结果验证了熵作为衡量图像信息密度的可靠代理指标。

熵感知的动态温度
[Autoregressive Model Beats Diffusio]论文中的方法分析生成过程中 logits 的熵分布,将其离散化为若干区间,并在每个区间内调整 token 的温度以控制采样随机性。随后,通过 FID 和 CLIP-Score 指标分析图像质量与文本对齐之间的关系,结果如图 3(c) 所示。我们的发现如下:在大多数熵区间内,调整随机性会导致图像质量与文本对齐之间的权衡,尤其是在熵范围为 的 token 上。 在高熵区域()中,降低随机性有助于提升图文一致性。 在极低熵区域()中,增加采样随机性可持续提升视觉质量,同时对文本对齐几乎没有影响。
这些发现表明,token 级的采样应具有熵感知性:在推理过程中,低熵 token 应分配相对更高的随机性以增强生成图像的质量和视觉丰富性,而高熵 token 应更谨慎地采样以保持清晰的结构、细节和文本一致性。
为了更好地适应真实推理场景,引入了一种动态温度机制,在每个 token 级别上调整采样随机性。具体而言,在计算每个位置预测分布的熵之后,我们通过预定义的映射函数确定温度值。

其中, 表示当前 token 位置的熵, 表示最大温度, 设定温度下界, 控制温度随熵增大的衰减速率。随后,得到的温度 被用于重新缩放预测的 logits,如下所示:

然后,通过应用 ,不同 token 之间的 logits 差异被放大(当 时)或缩小(当 时),这使得概率分布更加集中或分散,从而实现了基于区域内容分布的动态采样调整。
适配更多自回归模型
此外,许多近期的方法偏离了严格的下一 token 预测,转而采用了诸如掩码预测或尺度级生成等范式。我们表明,所提出的基于熵的策略在这些设置中仍然有效。在从 transformer 获得多个 token 级别的 logit 分布后,我们直接将公式 应用于它们。如下表1 所示,这种方法在标准评估指标上持续提升了性能。此外,对于不同的范式,可以结合特定的设计来进一步提升性能:

掩码预测模型。对于基于掩码的模型,在每个前向步骤中会获得一个覆盖所有图像 token 的完整概率分布。在采样之后,应用了一个基于 token 置信度的动态掩码机制。我们观察到,这种掩码策略对生成结果的质量也有显著影响(见下图4)。使用一个软分类分布从所有候选 token 中选择 个在当前时间步 被接受:


其中 是预测的 token 概率, 是公式 中定义的动态温度, 是从标准 Gumbel 分布中采样的。

这里, 返回第 高的置信度分数,置信度较低的 token 会被掩码。 和 分别表示当前和前一个时间步被接受的 token 掩码,而 表示 的逐元素取反。每个时间步 接受的 token 数量 由预定义的调度器决定。这种设计进一步鼓励了低熵区域的随机性,同时增强了高熵区域的准确性,从而提高了图像质量。
尺度级模型同时生成每个尺度内的 token。为较早的尺度分配更大的随机性,同时减少较晚尺度的随机性,可以在不损害图像丰富性的前提下产生更准确的结果。具体来说,我们定义了一个随着尺度增加而减小的温度项。对于第 尺度的 token, 的计算公式为:

其中 表示尺度索引且 ; 是第 尺度 token 的 logits,形状为 。 是公式 中定义的动态温度。 控制 跨尺度的衰减率,在实验中设置为 。
自回归加速
本文进一步探索利用熵来加速自回归生成。现有的推测性解码方法通常通过一个草稿模型生成多个候选 token,随后使用目标模型进行验证步骤。当草稿模型和目标模型共享同一模型时,该过程简化为比较连续两次迭代的置信度分数。具体来说,比较第 步的概率 和第 步的概率 。然后基于这两个分布计算 token 的接受概率。

在实践中,如果 则接受一个 token,其中 是从均匀分布 中抽取的,这自然地平衡了采样多样性所需的随机性和生成过程中的准确性。
为了使该过程具有熵感知能力,本文提出了一个对接受规则的简单修改。由于低熵区域更具可预测性并允许更高的随机性,而高熵区域需要更严格的验证,我们通过一个基于熵的因子 来缩放阈值 ,其中 是常数。这种动态调整能够基于局部不确定性实现更高效的生成。
为了提高稳定性,将 重写为 ,将其视为 ,其中噪声项控制接受的随机性。本文用一个衰减因子 来缩放此项,其中 是熵,使得高熵 token 的验证更具确定性,而低熵区域则保持接近均匀。结合上述两种策略,最终的接受规则可以表述为

其中 是当前 token 的熵, 和 是常数,分别设置为 和 。
这种动态接受标准更有效地分配了推理预算——在置信区域更宽松,在模糊区域更严格,从而以最小的性能损失减少推理时间。
实验
实现细节
选择了四个代表性模型进行比较:基于下一 token 预测的原始 AR 模型 LlamaGen 和 Lumina-mGPT,基于掩码的模型 Meissonic,以及尺度级模型 STAR。所有模型都在其原始推理设置下进行评估(例如,Lumina-mGPT 使用 CFG=4 和 top-K=2000,LlamaGen 使用 CFG=7.5)。本文使用 LlamaGen 官方的 Stage-1 模型来评估采样策略,而 Stage-2 由于其性能较差(FID 53.42,CLIP-Score 21.47)导致质量差异难以观察,仅用于加速分析。
FID 和 CLIP-Score 在 MS-COCO 2017 验证集上进行测试,以评估图像质量和提示跟随能力。此外,采用 DPG-bench 和 HPS来评估生成图像的语义保真度和感知质量。所有实验均在 A100 GPU 上进行。
采样质量
如前面表 1 和下图 5–6 所示,动态温度采样策略有效地适应了图像中不同信息密度的区域,从而在生成输出中带来更稳定的结构和更清晰的细节。根据每个模型固有的采样机制,本文的方法在不同方法上产生了不同程度的改进。特别是,它在 Meissonic 和 LlamaGen 上实现了 DPG 约 4 分的提升,同时视觉质量也有显著增强。此外,将本文的方法与掩码和尺度级策略相结合,可以进一步提高生成性能。结果参见前面表 1 中的“+Prob”(仅将动态温度应用于 logits)和“+Masking / +Scale-wise”(基于掩码或尺度应用温度)。


推理加速
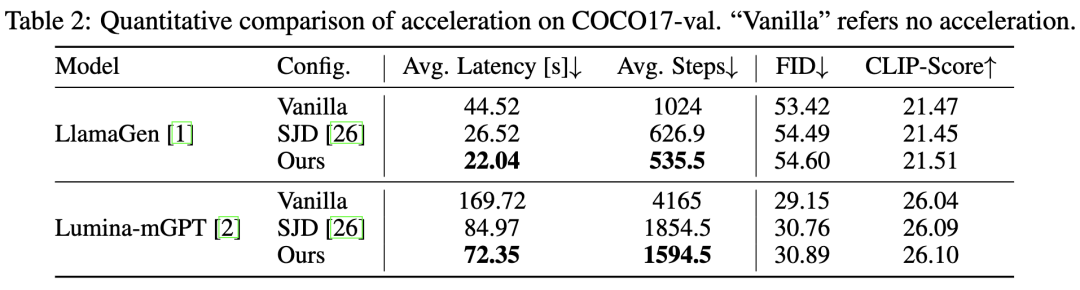
通过与现有的基于视觉的推测性解码方案集成,并利用熵自动控制接受条件,本文的方法节省了约 15% 的推理成本,图像生成质量几乎没有损失,如下表 2 和图 7 所示。这种基于熵的方法显著减少了推理步骤数和延迟,同时仍保持了与原始推测性解码方法相当的图像质量。

消融实验与讨论
公式 中的参数。熵感知动态温度中参数的影响如下图 8(a) 所示。可以观察到,较小的 或 值会导致较高的 FID 和较低的 CLIP-Score,这主要是由于随机性降低和采样过程过于确定。同时,随着 增大,FID 呈现先下降后上升的趋势。这是因为 控制着不同温度的比例。当 过小时,大多数 token 被分配了非常低的温度,导致 FID 上升。反之,当 过大时,图像内容变得过于混乱,同样导致 FID 增加。CLIP-Score 则随着 增大而持续下降。

接受率。本文提出基于预测分布的熵来动态控制现有推测性解码方法中的接受率。通过调整阈值 的尺度和随机性,在保持质量的同时降低了延迟。如表 3 和图 9 所示,仅控制 的尺度会降低推理成本但损害性能,尤其是图像质量。相比之下,联合调整尺度和随机性实现了更好的权衡,能够以最小的推理开销实现高质量生成。


与不同自回归模型的兼容性。 本文的采样方法为某些模型带来了显著的性能提升——例如,LlamaGen 和 Meissonic 的 DPG 指标超过基线 3 分以上。相比之下,像 Lumina-mGPT 这样训练有素的模型收益有限。这种差异源于多种因素,例如生成范式(图 4 讨论的基于掩码方法固有的采样限制)、训练数据集和迭代次数(例如,是否在大规模数据上进行了充分训练)。尽管如此,这些模型仍然可以利用熵进行进一步加速。
与 top-K 和 CFG 的结合。进一步分析了本文的方法与 top-K 采样和 CFG 结合时的性能,如图 8(b) 所示;与 top-p 和温度采样的结果见补充材料。通过结合所提出的方法,FID 指标对采样参数的敏感性降低,从而在保持图文对齐的同时实现更好的保真度。
影响熵的因素。与具有固定tokenization规则的文本生成不同,自回归图像生成依赖于预训练的tokenizers,并且底层模型的差异——包括参数规模、数据质量和训练语料库——导致了不同的熵分布和最佳采样参数。经验表明,较高的 CFG 和较大的分辨率会导致较低的平均熵(见下表 4)。

失败案例讨论。尽管本文基于熵的动态采样策略带来了显著的性能改进,但也观察到几个失败案例,其中语义信息与熵图之间的关系变得不太一致(见下图 10)。在某些情况下,诸如人脸之类的区域表现出意外的高熵,而复杂背景却获得较低的熵值。因此,基于此类熵模式调整温度可能导致结构扭曲和过于平滑的细节。这种模糊性可能会限制进一步的性能提升,特别是对于经过精心优化的模型。

结论
首先指出了自回归图像和文本生成需要不同的采样策略,因为它们具有不同的信息分布。从这个角度出发,发现熵能有效表示图像信息密度,为改进和加速图像生成提供了新的可能性。由于 本文的方法涉及无需训练的参数调整,这种方法可以进一步集成到训练或微调框架中,加速训练、提升推理速度、提高稳定性并减少超参数依赖性。
参考文献
[1] Towards Better & Faster Autoregressive Image Generation: From the Perspective of Entropy
技术交流社区免费开放
涉及 内容生成/理解(图像、视频、语音、文本、3D/4D等)、大模型、具身智能、自动驾驶、深度学习及传统视觉等多个不同方向。这个社群更加适合记录和积累,方便回溯和复盘。愿景是联结数十万AIGC开发者、研究者和爱好者,解决从理论到实战中遇到的具体问题。倡导深度讨论,确保每个提问都能得到认真对待。


技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!
