
在机器人操控领域,如何充分利用多种传感器输入,以全面提升模型对物理世界的感知与动作生成,是一个亟待解决的问题。
近日,北京大学仉尚航团队、北京人形机器人创新中心和香港中文大学的研究团队提出了一种名为 MLA(multisensory language-action)的新型多感官-语言-动作模型,利用无编码器的多模态对比学习对齐机制,以及未来状态预测等方法,在大语言模型内构建多模态统一特征空间,该方法在多个复杂、高交互性的真机任务,以及模拟器任务中取得SOTA表现,展示出鲁邦的物理场景理解和操纵交互能力!
论文题目:MLA: A Multisensory Language-Action Model for Multimodal Understanding and Forecasting in Robotic Manipulation
论文链接 : https://arxiv.org/abs/2509.26642
项目主页: https://sites.google.com/view/open-mla
代码链接 : https://github.com/ZhuoyangLiu2005/MLA


文章简介
视觉-语言-动作(VLA)模型通过继承视觉-语言模型(VLM)并学习动作生成,在机器人操作任务中展现了出色的泛化能力。
大多数现有的VLA模型主要关注如何理解视觉与语言信息以生成动作,而机器人在实际应用中,还必须感知并与空间物理世界进行交互。
这一差距凸显了对机器人多感官信息的全面理解的迫切需求,而这种理解对于实现复杂的、涉及接触的控制任务至关重要。
为此,我们提出了multisensory language-action(MLA)模型,能够协同感知异构感官模态,并预测未来的多模态目标,从而促进对物理世界的建模。

在评估中,MLA模型在复杂、接触丰富的真实世界任务中,分别比现有最先进的2D和3D VLA方法高出12%和24%,同时在未见过的配置上也展现出更强的泛化能力。

▲图1|(a)与依赖2D图像和人工指令生成动作的传统VLA方法不同,(b)我们提出了MLA多感官语言-动作模型,它能够协同处理多种机器人专用感官模态,并预测这些模态的未来状态,从而增强机器人控制中的物理动态建模能力。(c)MLA在多种真实世界和仿真任务中实现了最先进(SOTA)的性能。©️【深蓝具身智能】编译

研究背景
近年来,机器人模仿学习通过专家演示有效训练策略,已能完成多样化的视觉-语言操作任务。
与此同时,基于海量互联网数据预训练的视觉-语言模型(VLM)展现出强大的通用推理能力。
结合两者,研究者提出了视觉-语言-动作(VLA)模型,在融合机器人演示数据后,具备将人类指令与视觉观察映射为控制信号的能力,表现出卓越的泛化与操作性能。
然而,现有VLA多依赖2D视觉输入,难以捕捉空间依赖和物理动态。
为提升感知能力,一些研究引入3D几何和触觉信号,但需额外模态编码器,降低效率;且若缺乏多感官预训练,LLM骨干难以有效对齐新增模态。
另一些工作尝试通过预测未来状态建模物理动态,如生成子目标图像或深度图,但在预测完整点云与触觉交互方面仍显不足,而这两者对理解复杂接触场景与运动规划至关重要。
因此,一个关键问题随之出现——
“如何将多感官模态整合为统一的表征,并预测其未来状态,从而协同增强VLA模型对物理世界的理解与动作生成能力?”

方法引言及概述
具体做法是将3D点云和触觉位置投影到2D图像平面,利用位置对应关系进行token级对比学习,在LLM嵌入空间中实现多模态特征对齐,从而获得更强的表征能力。

为增强对物理场景的理解,MLA引入未来多感官生成的后训练策略,使用轻量Transformer解码器预测未来2D图像、3D点云及触觉状态,覆盖语义、几何与交互信息。
这一策略仅在训练阶段使用,不影响推理效率,却能为动作生成提供丰富特征。
在数据上,我们先在57万条大规模图像-动作轨迹上预训练LLM,再在下游任务上进行监督微调,同时引入无编码器多模态对齐与未来多感官生成训练,使模型具备多感官感知、理解与动作生成能力。

六个真实机器人实验(单臂与双臂任务)表明,MLA取得SOTA成功率,并在未见物体与环境下展现强泛化性。在RLBench模拟器测试中也获得竞争力表现(模拟触觉未使用)。
我们的主要贡献如下:
提出了MLA,这是一种多感官语言-动作模型,采用无编码器的多模态对齐机制,将LLM本身重新用于直接对齐和解释图像、点云和触觉信息。
为了进一步增强MLA对物理动态的理解,引入了一种未来多感官生成的后训练策略,使其能够推理语义、几何和交互信息,从而为动作生成提供更稳健的条件。
通过预训练、监督微调(SFT)和后训练的渐进式流程,MLA在复杂的真实世界任务中(包括单臂和双臂操作)实现了SOTA的成功率,并展现了强大的泛化能力。

MLA模型架构
如图2所示,MLA建立在Prismatic VLM的LLM骨干上。
不同于依赖视觉编码器的传统VLA,MLA使用轻量级tokenizer将多感官输入直接转换为共享token序列,并将LLM重用为统一模型,同时引入基于Transformer的解码器预测未来多模态状态。

▲图2|MLA整体框架。a) MLA通过无编码器多模态对齐直接整合RGB图像、点云与触觉信号,并利用token级对比学习对齐;输出层采用未来多感官生成后训练,为动作生成提供稳健条件。b) MLA遵循三阶段训练:大规模预训练、跨模态对齐的监督微调,以及带未来状态预测的后训练。©️【深蓝具身智能】编译
图像 tokenizer
对于每个输入图像 , 图像 tokenizer (Vision Tokenizer) 将其转换为紧凑的 token 序列。图像被划分为大小为 的不重叠 patch, 从而得到长度为 的 token 序列, 批量大小为 , 嵌入维度为 , 即 。
三维点云 tokenizer
给定原始点云 , 我们的三维 tokenizer 将点划分为以采样锚点为中心的局部组。参考之前的工作, 该分词器由三个模块组成, 每个模块包含最远点采样 (FPS) 用于下采样、k 近邻 (KNN) 用于局部聚合,以及可学习的线性层用于特征编码。经过三维 tokenize 后,我们得到由 个 token 组成的紧凑表征,即 。
触觉分词器
我们设计轻量 MLP 将低维触觉信号嵌入共享 token 空间,每个机械手指传感器输出法向力、切向力及方向信息,经 MLP 生成触觉 token 。
LLM 骨干网络
基于 LLaMA-2 7B,图像、点云、触觉和语言 token 投影到共享嵌入 统一处理,扩散动作头的噪声 token 追加序列末端,通过 MLP 嵌入时间步与噪声,实现多感官动作生成,无需模态特定编码器。
未来预测解码器
基于四层堆叠的 Transformer 解码器,从 LLM 最终隐藏状态预测未来感官观测,将统一多模态嵌入映射到图像、点云和触觉向量,并由对应未来状态监督。
无编码器的多模态对齐机制

正负样本对的构建

图像 - 点云对齐
触觉 - 图像与点云对齐
在单臂臂设置中, 由于触觉嵌入由单个 token 组成, 因此每个触觉 token 都会产生一个正样本对 和 , 其余 token 则作 为负样本。
我们采用单向对比损失, 将触觉嵌入拉近到其对应的正样本 token:
整体的对比学习目标是三个损失的加和:
通过这一对比学习目标, 模型能够有效地捕捉一致的语义和空间信息, 使多模态特征能够在 LLM 的统一嵌入空间中无缝整合。
未来多模态生成
尽管部分VLA利用未来观测预测建模物理动态,但在处理多样的机器人特有模态方面仍不足。
为强化MLA对物理场景的理解,我们提出未来多感官生成后训练策略,联合预测未来的图像、点云与触觉模态。
图像预测
采用Transformer解码器,以LLM末层特征为输入,通过MSE损失监督未来关键帧生成。关键帧依据关节速度变化与动作转换确定,且仅在深度图前景区域计算损失。
点云预测
参考PointMAE,使用FPS采样中心点并通过KNN分组局部patch,Transformer解码器预测点云坐标,以Chamfer距离监督,从粗到细重建三维结构。
触觉预测
输出低维触觉嵌入,以MSE损失监督。通过联合预测多模态未来状态,MLA在语义、几何与交互层面获得更全面表征。这些预测损失仅用于后训练阶段,不影响推理效率。
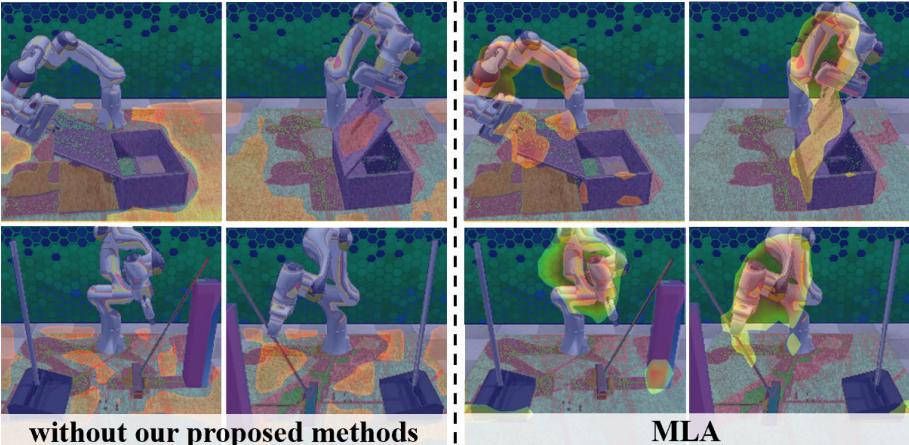
图3展示了在RLBench模拟器中一部分生成的结果。

▲图4|MLA在RLbench上部分任务中的生成效果,对于图像和点云都可以精确生成机械臂位姿和局部特征©️【深蓝具身智能】编译
整体训练策略
大规模预训练
我们整合Open-X-Embodiment、RoboMIND等数据集,构建超过57万条轨迹的大规模数据集。预训练阶段仅使用图像和语言输入训练MLA,共10个epoch,其余模态保留token位置以便后续训练。动作生成损失 采用DDPM标准,通过最小化预测噪声与真实噪声的MSE优化。
监督微调
在这一阶段,我们将预训练模型进一步适配到高质量的任务特定数据集上,并采用所提出的无编码器多模态对齐机制。此时,引入了所有多感官模态,包括图像、点云、触觉信号和语言指令。我们结合所提出的对比损失函数(详见4.3节),以增强MLA的跨模态对齐能力和多模态表征能力。整体的训练目标函数为:
后训练
最后,模型进行未来多感官生成的后训练。
在此阶段,训练数据和输入模态与监督微调(SFT)阶段相同。此外,训练中加入了未来多模态预测监督,使模型能够捕捉物理动态,从而实现更稳健的动作生成。
整体的监督损失为:
需要注意的是,我们先进行SFT,再进行后训练,以逐步赋予模型在真实物理世界中从多感官输入整合感知、理解与动作生成的能力。
在推理阶段,我们使用DDIM进行采样,采样步数为 n(例如 n=4)。

MLA实验结果
真机实验
真实世界实验设置
单臂实验在Franka Research3机械臂上进行,评估四个复杂接触任务;
双臂实验由两台Franka机械臂完成两项任务。
单臂配备两台RealSense D455相机(第三人称和手腕视角,跨模态对齐仅用第三人称)及每个夹爪两个触觉传感器(Tashan TS-E-A);双臂使用三台D455相机(一台第三人称,两台手腕视角)。
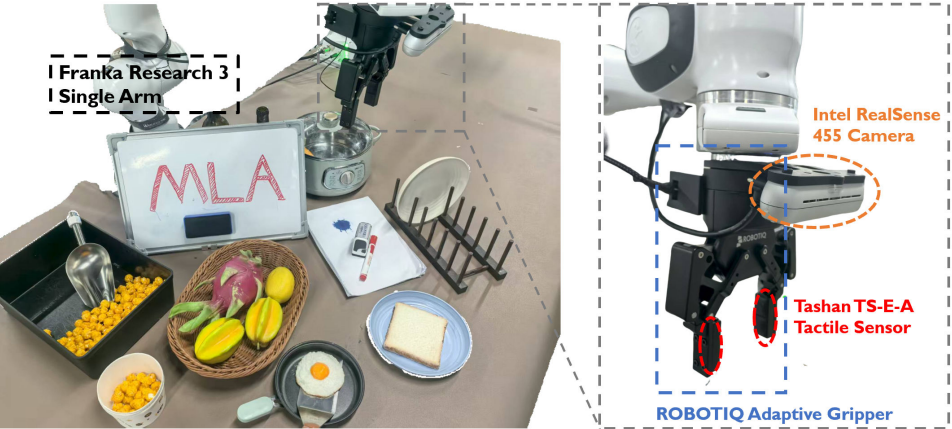
▲图4|MLA的单臂场景配置©️【深蓝具身智能】编译
自采集数据
单臂实验四个接触任务:印章按压、白板擦拭、餐具放置、铲鸡蛋放面包;
双臂实验两项协作任务:舀爆米花入碗、开锅取玉米。所有示范通过Gello平台采集,每任务200条高质量轨迹。
训练与评估
MLA在SFT阶段训练300 epoch,后训练100 epoch,使用AdamW优化器。基线模型(π0和SpatialVLA)按官方预训练参数和训练方法微调。
每任务使用相同相机视角,测试时进行15次rollout评估。

▲图5|MLA的真机实验结果,每个模型都测试了15条rollout,物体位置均存在略微移动,成功与否由人类判断©️【深蓝具身智能】编译
实验结果
如图5所示,MLA在六个任务中表现出色,平均比π0和SpatialVLA高出12%和24%。
在“擦白板”任务中,MLA利用触觉精确调节末端执行器动作。
其优势来源于更有效的多感官对齐与解读,以及未来多感官状态预测,提升了物理环境感知和动作生成的稳健性。
消融实验
为了验证我们提出的各项贡献,我们在两个真实世界任务上进行了消融实验,包括“将印章按压在纸上”和“将鸡蛋放在面包上”两个任务。
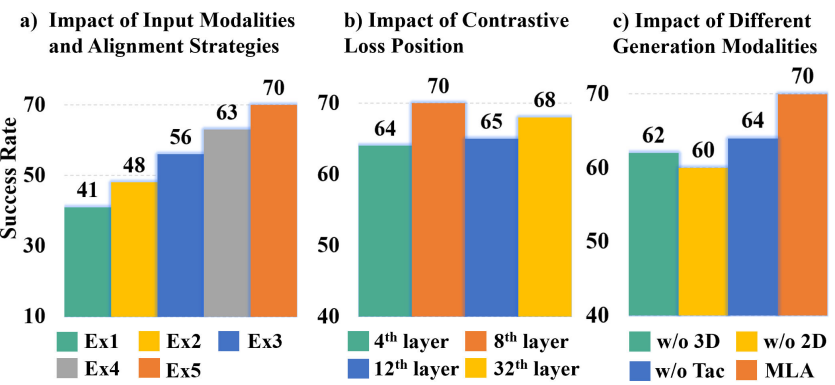
▲图6|消融实验,我们系统评估了MLA中各个部分的贡献 ©️【深蓝具身智能】编译
无编码器多模态对齐的影响
如图6(a),不同输入模态和对齐策略对性能影响明显:
Ex1:仅2D图像;Ex2:图像+点云,简单token拼接;Ex3:图像+点云+触觉,简单token拼接;Ex4:所有模态,图像级对比对齐;Ex5:所有模态,token级对比对齐(我们的方法)。
结果显示,Ex3突出语义、空间和交互感知的重要性,Ex5显著优于Ex1–Ex4。
表明基于位置的一致性约束和精细token级对齐增强了多模态表征(对比Ex4提升7%)。
对比损失位置的影响
图6(b)显示,在LLM第8层施加token级对比学习性能最佳,因为此时特征对齐发生在相对较浅的层,同时保留了足够的后续Transformer层用于未来状态预测和动作生成。
在第32层施加自监督学习效果有限,因为最终隐藏状态已经针对多个目标进行了优化。
多模态数据编码方法
使用额外2D/3D编码器性能下降约7%,且降低推理效率;重用LLM作为统一感知模块更优。
未来状态生成的模态影响
图6(c)表明,缺少任一模态的未来状态生成都会降低准确率,完整生成语义、空间与交互信息有助于稳健动作生成。预测未来关键帧优于相邻帧(70% vs 64%),避免冗余信息影响动作规划。
泛化实验
如表1所示,我们在两种泛化场景下对比MLA与π0:
未见操作物体(鸡蛋替换为生菜并更换盘子颜色)和未见复杂背景(操作物体周围增加杂乱物体)。

▲表1|泛化性实验结果。"Object"和"Background"分别指代未见过的操作物体和复杂背景。图像展示了四种泛化测试场景,红色方框标明了关键差异点。 ©️【深蓝具身智能】编译
在最具挑战任务“铲鸡蛋放面包上”中,MLA在物体变化下成功率几乎不降,在复杂背景下仍保持40%成功率。

▲put egg backpot

▲put egg backflower

▲put egg lemon
结果表明,MLA凭借强大的多模态感知和未来状态预测能力,在语义与环境变化下展现出稳健的操作推理能力。
模拟器实验
模拟基准测试
我们在RLBench基准测试中进行了10个任务的实验,该基准基于CoppeliaSim模拟器。
对于每个任务,我们使用官方运动规划库收集了100条示范轨迹。
训练与评估细节
由于模拟环境中的触觉感知不够真实,我们仅向MLA及所有基线方法提供图像和点云模态。我们从相关领域中选择了若干最先进(SOTA)基线,包括:
OpenVLA、π0、HybridVLA、SpatialVLA、UP-VLA以及DreamVLA*
对于每个基线,我们加载了官方发布的预训练检查点。所有任务均进行联合训练,每个任务的评估使用20次rollout。

实验结果
如表2所示,MLA在10个任务中的平均得分达81%,显著优于π0(65%)、SpatialVLA(46%)等基线,尤其在“放酒入架”“浇水”“电话归位”等复杂任务上表现突出。
结果验证了多模态对齐与未来多感官生成后训练的有效性,使MLA具备更强的表征与动作生成能力。
值得注意的是,即便缺乏触觉等昂贵传感器,方法仍保持优异性能。

总结
我们提出了MLA,一种多感官语言-动作模型,通过无编码器多模态对齐整合2D视觉、3D几何与触觉信息,并利用未来多感官生成增强物理理解。
编辑|zhuoyang
审编|具身君
研究单位:北京大学,北京人形机器人创新中心,香港中文大学
工作投稿|商务合作|转载
:SL13126828869(微信号)


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文