
近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。在扩散去噪的多步过程中,通过进行再掩码 SFT 和 RL 训练,为每个 token 输出一个去掩码置信度,RemeDi 能够从序列中已经生成的内容中识别无法确定的位置进行再掩码(remask),从而修正错误内容并提升文本质量,在各方面都超越了现有的扩散语言模型。该模型还具有可变长生成(variable-length generation)能力,打破了现有中大规模扩散语言模型仅支持定长生成的限制,提高了模式能力的灵活性。

论文地址:https://arxiv.org/abs/2509.23653
代码与模型地址:https://github.com/maple-research-lab/RemeDi
背景
扩散语言模型已成为自回归语言模型的有力替代方案。这一类方法首先定义了一个将文本逐步破坏为噪声的前向过程,然后让模型学习从噪声中恢复出干净文本的逆向过程。在这一类方法中,当前最主流的是基于掩码的扩散语言模型。该方案要求模型在训练中学习恢复被掩码的 token,而已经被恢复的 token 则在之后的生成步骤中保持不变,直到生成结束。这其中蕴含了一则假设:每一步中预测的 token 都必然是正确的,无需修正,直接可以当作最后的生成内容。这一假设显然过于理想 —— 生成过程中,模型不可避免地会产生预测错误,而我们应当赋予模型通过自我反思发现并修正这些错误的能力。
为解决这一问题,提出一种面向扩散语言模型的自我反思式生成范式 —— 再掩码(remask),并基于这一范式训练了具有「再掩码」能力的扩散语言模型 RemeDi。如图所示,RemeDi 具备发现错误 token,并通过再掩码将其修正的能力:模型首先生成了 “left”,但随后在生成完整句子的语义表示时,发现 “left for the pies” 这一表述与实际含义不符,因此,将 “left” 一词再掩码,修改为更合适的 “used”。可以看出,通过再掩码,模型能利用在后续步骤中生成的上下文信息,识别较早步骤中存在的错误,将其改正,并基于更丰富的上下文信息进行更精确的预测。

用置信度识别「再掩码」目标
为了让 RemeDi 能够通过再掩码修改已经生成的文本内容,一个核心的挑战是让模型能够找到需要修改的 token,执行再掩码操作。为此,我们对网络结构进行了修改,让其在预测序列中每个 token 输出分布的同时,能够为每个 token 额外预测一个置信度分数。整个模型采用了一种双流协同的模型结构:
TPS(Token Prediction Stream):负责对掩码位置给出候选 token 分布
 ,类似常规的扩散语言模型;
,类似常规的扩散语言模型;UPS(Unmasking Policy Stream):为序列每一个位置输出一个置信度分数
 ,表示模型在这一步输出时,该位置上结果的确定度。分数高即说明模型认为,这一步的结果有更大的概率是正确的,无需再被掩码。与此同时,得分较低的位置就应当仍然保持掩码状态,或是被再掩码,直到模型能依赖更多上下文做出更准确的预测。
,表示模型在这一步输出时,该位置上结果的确定度。分数高即说明模型认为,这一步的结果有更大的概率是正确的,无需再被掩码。与此同时,得分较低的位置就应当仍然保持掩码状态,或是被再掩码,直到模型能依赖更多上下文做出更准确的预测。
基于这一模型结构,RemeDi 按如下方式逐步执行去噪推理步骤:以上一步的结果  作为输入,UPS 模块首先会为序列中每一个位置预测
作为输入,UPS 模块首先会为序列中每一个位置预测  ,决定哪些位置不再需要被掩码。然后,对于那些不需要掩码的位置,如果输入本身就已经不是掩码 token,我们会直接保留输入 token 值;否则,我们会基于 TPS 输出的
,决定哪些位置不再需要被掩码。然后,对于那些不需要掩码的位置,如果输入本身就已经不是掩码 token,我们会直接保留输入 token 值;否则,我们会基于 TPS 输出的  采样该位置的输出 token。与 “生成即固定” 的传统掩码扩散生成范式不同,RemeDi 在每一步都会依赖输出的置信度决定需要 / 不需要掩码的部分。因此,模型有可能对已经生成的 token 预测出较低的置信度,将其「再掩码」,使其后续可以依据更充分的上下文重写,使推理过程具备 “边写边改” 的能力。
采样该位置的输出 token。与 “生成即固定” 的传统掩码扩散生成范式不同,RemeDi 在每一步都会依赖输出的置信度决定需要 / 不需要掩码的部分。因此,模型有可能对已经生成的 token 预测出较低的置信度,将其「再掩码」,使其后续可以依据更充分的上下文重写,使推理过程具备 “边写边改” 的能力。

此外,在语言生成任务中,许多场景下的输出并非固定长度。如果模型只能在固定长度下生成,将导致资源浪费或生成结果被压缩、截断。因此,使扩散语言模型具备灵活的不定长生成能力 (variable-length generation)是必要的。在 RemeDi 中,我们采用分块自回归生成的方法实现这一点:模型每次会通过一个完整的反向扩散过程生成一段长为 L=32 的序列。完成后,如果该序列中没有生成结束符,则将已生成的这一段序列拼接在上下文中,继续往后生成下一段长为 L=32 的序列,如此重复直到生成结束符为止。与自回归模型类似,我们采用分块因果注意力掩码机制,确保在生成时,每个 token 能看到自己所在的 block 内的其他 token,和之前已生成 block 内的 token,而无法看到未来将要生成的 block。

在实验中,我们基于 LLaDA 的权重继续训练,将其改造成一个具有不定长生成能力的分块扩散模型。上面表 4 中的 baseline 模型即展示了不定长生成模型在经过再掩码训练前的性能。
两阶段训练,赋予「再掩码」能力
1.Remask SFT(监督微调阶段)
传统的掩码扩散语言模型通常通过在输入序列上随机掩码进行有监督微调(SFT)。与之不同的是,RemeDi 在反向扩散过程中还需要能够找到潜在的不正确 token 并再掩码。我们在 SFT 过程中将这类不正确 token 视为除掩码 token 之后的第二类噪声。因此,在 SFT 阶段,我们不仅要训练模型从掩码 token 恢复原文本的能力,同时也需要训练识别那些需要再掩码的不正确 token。
我们从干净文本 引入两类噪声构造训练样本
引入两类噪声构造训练样本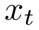 :首先,随机采样一个扩散时间
:首先,随机采样一个扩散时间 ,并设定对应的随机掩码比率
,并设定对应的随机掩码比率 以及不正确 token 的比率
以及不正确 token 的比率 。我们以比例
。我们以比例 随机掩码一部分 token;接着,在剩余未被掩码的位置中,以比例
随机掩码一部分 token;接着,在剩余未被掩码的位置中,以比例 采样一个子集,并把其中的每个 token 随机替换为一个其他 token,用以模拟反向扩散过程中可能出现的不正确 token。
采样一个子集,并把其中的每个 token 随机替换为一个其他 token,用以模拟反向扩散过程中可能出现的不正确 token。
由于在反向扩散过程中,噪声水平(定义为 mask token 的数量)应当单调递减。由于在 SFT 设计中,长度为 L 的输入序列中,所有不正确 token 都必须被重新掩码,因此需要满足以下不等式约束:

以确保输出中掩码位置的数量单调减少。若该不等式不成立,则在下一步重新掩码所有不正确 token 会增加总的掩码数量,从而违反扩散过程中掩码比例应逐步减少的基本原则。
基于上述约束,我们选择噪声调度为 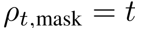 ,以及
,以及 ,其中 r 为常数。在实验中我们设定 r=0.1,此时不难验证在
,其中 r 为常数。在实验中我们设定 r=0.1,此时不难验证在 区间上,上述不等式总是成立。
区间上,上述不等式总是成立。
在实际训练过程中,除了常规的 token 预测损失外,我们还需要在所有 token 位置上使用二元交叉熵(BCE)目标函数监督模型预测的  。我们按以下规则构造对应的训练标签 y:
。我们按以下规则构造对应的训练标签 y:
掩码 tokens ,即
 。此类 token 标签为 y=1,表示该 token 应保持不被掩码;
。此类 token 标签为 y=1,表示该 token 应保持不被掩码;可见但错误的 tokens 即
 。此类 token 标签为 y=0,表示该 token 应被掩码;
。此类 token 标签为 y=0,表示该 token 应被掩码;可见且正确的 tokens,即
 。对这一类 token,我们会赋予软标签
。对这一类 token,我们会赋予软标签 ,即模型预测出对应真值
,即模型预测出对应真值 的概率。该概率越高,说明预测出真值的可能性越大,因此该 token 更不应该被掩码。
的概率。该概率越高,说明预测出真值的可能性越大,因此该 token 更不应该被掩码。
整个再掩码微调算法流程如下图:

2.Remask RL(强化学习阶段)
在完成 Remask SFT 训练后,我们进一步通过基于结果的强化学习对模型进行微调。根据实验室先前的研究,反向扩散过程中的每一步中间结果都可以视为大模型的一个「思考」步骤,而基于结果的强化学习可以优化整个生成轨迹,提升模型生成正确最终答案的概率。这种面向扩散语言模型的大模型推理范式称为扩散式「发散思维链」,在机器之心的往期报道中已有详细阐述。()
在具备「再掩码」能力的 RemeDi 模型中,这一扩散式「发散思维链」同样也包含了 N 个去噪步骤。对于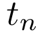 时刻的第 n 步,我们将从
时刻的第 n 步,我们将从  生成
生成  的去噪过程拆解为两部分策略:
的去噪过程拆解为两部分策略:
1)去掩码策略:UPS 为每个 token 位置生成一个置信度分数  ,表示模型多大程度上确信该位置上的 token 是正确的(若已去掩码)或可预测的(若仍为掩码)。在推理时,我们根据该置信度对所有 token 排序,并优先为置信度高的位置去掩码。在 RL 训练中,我们基于 Plackett–Luce 模型构造解掩码策略:根据
,表示模型多大程度上确信该位置上的 token 是正确的(若已去掩码)或可预测的(若仍为掩码)。在推理时,我们根据该置信度对所有 token 排序,并优先为置信度高的位置去掩码。在 RL 训练中,我们基于 Plackett–Luce 模型构造解掩码策略:根据  无放回地顺序采样该步骤的去掩码位置集合
无放回地顺序采样该步骤的去掩码位置集合 。这一去掩码位置集合的采样概率为:
。这一去掩码位置集合的采样概率为:
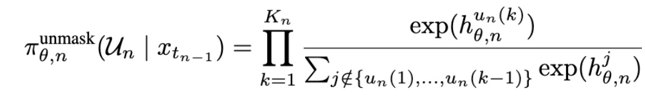
2)Token 预测策略:对于包含在去掩码位置集合  中的每一个位置,如果
中的每一个位置,如果 ,则模型会依据
,则模型会依据 采样预测 token 值;否则,该位置 token 值保持输入不变。这一步中,给定
采样预测 token 值;否则,该位置 token 值保持输入不变。这一步中,给定 和
和  采样
采样 的概率为:
的概率为:

综合上述两个策略,在一个去噪步骤中,基于上一步结果 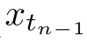 采样
采样  的最终概率可建模为:
的最终概率可建模为:

该策略可用于基于结果的强化学习,鼓励所有能够得到正确答案的完整轨迹 。
。
实验结果
在同规模与相近计算预算下,RemeDi 在数学推理、代码生成与通用问答三类任务上均取得稳定提升。其中,仅采用 Remask SFT 带来显著增益;在此基础上加入 Remask RL,多数基准再获得进一步提升。


我们在不同类型的任务上对再掩码次数进行了统计,可以看出:对输出约束更强的任务(如代码生成)会更频繁触发再掩码。

而具体的生成示例也表明,通过再掩码机制,RemeDi 可以实现纠错、插入、删除等多种文本修改手段。


总结
这篇文章介绍了由西湖大学 MAPLE 实验室推出的,具有再掩码反思机制的扩散语言模型,RemeDi。基于额外的置信度预测,RemeDi 能够识别生成过程中的错误,并通过「再掩码」机制重新预测,从而做到生成过程中的自我反思与优化。针对「再掩码」机制设计的有监督训练与强化学习算法确保了这一机制的有效性。实验结果表明 RemeDi 在数学推理、代码生成、通用知识问答等多个任务上都取得了超越其他扩散语言模型的性能。这些结果说明「再掩码」能有效提升扩散语言模型的文本生成质量,值得进一步探讨。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com