编辑:+0、冷猫
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。
即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
这种现象在现实使用中远比在标准化基准测试中更明显。当用户与 ChatGPT 等主流 LLM 进行长时间、多轮的复杂对话时,会明显感觉到模型开始变「笨」,变得难以聚焦、遗忘关键信息。

来自 MIT 的研究者从一个直观的想法出发:也许可以把超长上下文切分,分别交给模型处理,再在后续调用中合并结果,以此避免衰退问题?
基于此,他们提出了递归语言模型(Recursive Language Models,RLMs),这是一种通用的推理策略:语言模型将输入上下文视作变量,对其进行分解并递归式交互。
将上下文视为一个可操作的「变量」:主模型(root LM)在一个类似 Jupyter Notebook 的编程环境(REPL)中工作,完整的上下文只是一个它能用代码访问的变量,而不是直接的输入。
递归调用自身或小模型:主模型可以编写代码来查看、切分、过滤(比如用 grep)这个巨大的上下文变量,然后把小块的任务外包给一个个小的、临时的 LLM 调用(递归调用)。
综合结果:主模型收集这些「外包」任务的结果,最终形成答案。
研究者还设计了一个具体实现:在一个 Python REPL 环境中调用 GPT-5 或 GPT-5-mini,并将用户的 prompt 存入变量中进行迭代式处理。
结果很惊人:在能获取到的最难的长上下文评测集之一 OOLONG 上,使用 GPT-5-mini 的 RLM 正确答案数量是直接使用 GPT-5 的两倍以上,而且平均每次调用的成本更低。
研究者还基于 BrowseComp-Plus 构建了一个全新的长上下文 Deep Research 任务。在该任务中,RLM 显著优于 ReAct + 推理时索引 / 检索等方法。令人意外的是,即使推理时输入超过 1000 万 tokens,RLM 的性能也没有出现衰减。
他们相信,RLM 很快会成为一个强大的范式。
同时,相比于仅依赖 CoT 或 ReAct 风格的代理模型,显式训练以递归式推理为核心机制的 RLM,很可能成为推理时扩展能力领域的下一个里程碑。

博客文章:https://alexzhang13.github.io/blog/2025/rlm/
原帖压缩总结见推文:https://x.com/a1zhang/status/1978469116542337259
博客作者为 MIT CSAIL 的 Alex Zhang 和 Omar Khattab。
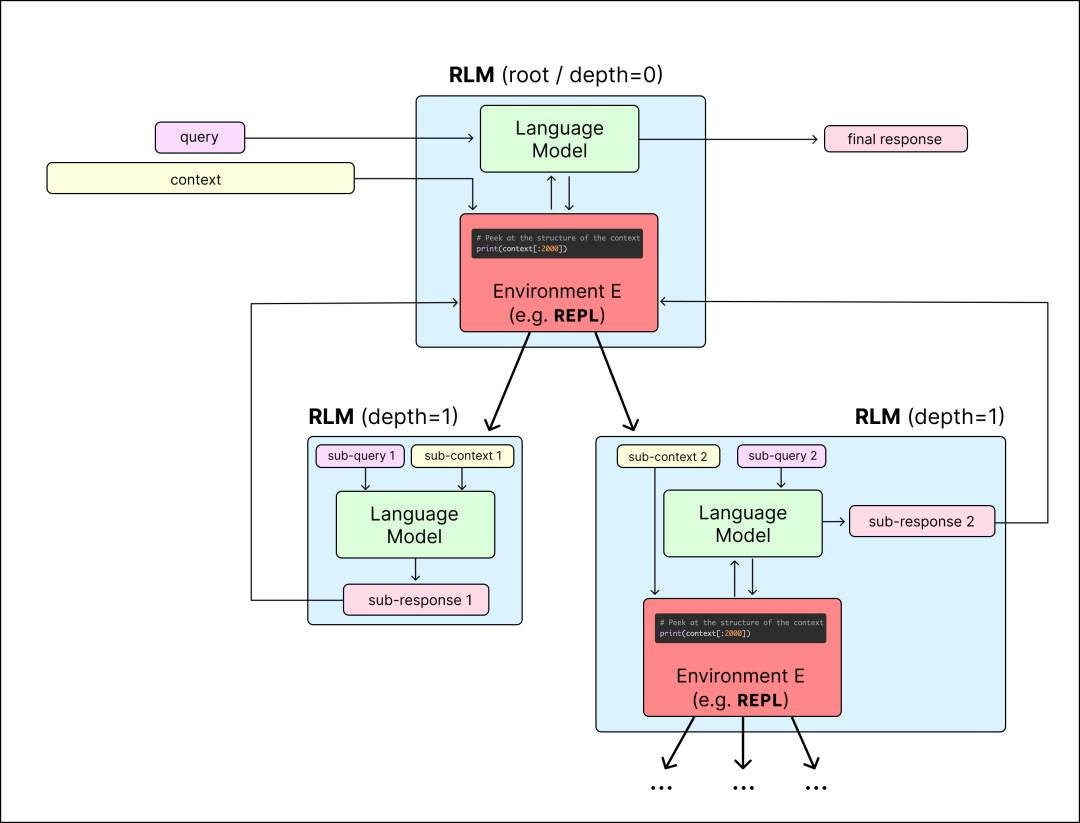
这是一个递归语言模型 (RLM) 调用的示例。它作为一种从文本到文本(text → text)的映射,但比标准的语言模型调用更灵活,并且可以扩展到近乎无限的上下文长度。RLM 允许语言模型与一个环境(在此实例中为 REPL 环境)进行交互,该环境存储着可能非常庞大的上下文。在其中,模型可以递归地子查询「自身」、调用其他 LM 或其他 RLM,从而高效地解析这些上下文并提供最终的响应。
评论区的反馈也非常积极,并且进行了很多深入的讨论。



递归语言模型 RLM
RLM 的通用性与其底层语言模型本身相同。实际上,从用户角度来看,RLM 的调用方式与普通模型调用并没有区别,但它在内部可以生成(递归式的)LM 子调用来完成中间计算。
当你向一个 RLM 发起查询时,「根」语言模型(root LM)可以把整个上下文当作可操作的环境来探索和处理。它会通过递归调用(R)LM,将对任意结构或任意长度上下文的处理任务分解并逐级委托,从而实现可扩展的推理能力。

递归语言模型(RLM)调用取代了传统的语言模型调用。它为用户提供了一种「仿佛上下文无限大」的体验,但在底层,语言模型会自动对上下文进行管理、分区,并根据需要递归调用自身或其他 LM,从而避免出现 context rot(上下文退化)问题。
研究者将这一机制实现为一个类似 Jupyter 的 REPL 环境:
核心思想是:将用户的 prompt 存入一个 Python 变量中,然后提供一个 REPL 循环给 LLM,让它可以在不一次性读取全部内容的前提下,主动尝试理解和操作 prompt。
「根」语言模型(root LM)通过编写代码并查看每个单元格的输出,与这个环境进行交互;在此过程中,它还可以在 REPL 环境中递归调用其他 LM 或 RLM,以此在上下文中进行导航和解析。
这种方式要比任何「分块(chunking)」策略都更加通用且更智能。研究者认为:应该让语言模型自己决定如何探索、拆解并递归地处理长 prompt,而不是由人为制定固定的切分策略。

RLM 框架实例为根 LM 提供了在 Python 笔记本环境中分析上下文的能力,并能在任何存储在变量中的字符串上启动递归 LM 调用(深度 = 1)。LM 通过输出代码块进行交互,并能在其上下文中接收(截断的)输出版本。完成时,它输出带有 FINAL (…) 标签的最终答案,或者可以选择使用代码执行环境中的字符串 FINAL_VAR (…)。
这种结构在实际使用中带来了多项明显的优势:
根语言模型(root LM)的上下文窗口很少被「塞满」 —— 因为它从不直接读取完整上下文,它接收的输入规模增长得很慢。
root LM 拥有灵活的上下文访问策略 —— 它可以只查看部分上下文,或者对上下文块进行递归处理。例如,当任务是寻找「needle-in-the-haystack」信息或需要多跳推理时,root LM 可以先通过正则表达式(regex)等方式粗略筛选上下文范围,再对筛选结果发起递归式 LM 子调用。这对于任意长度的上下文输入尤其有价值,因为对整个长文档现检索(on-the-fly indexing)通常代价很高。
理论上,RLM 能处理任何可以加载到内存的模态数据 —— root LM 可以完全掌控数据的查看与转换方式,并在此基础上继续向递归 LM 发起子查询。
RLM 框架的一个显著优势在于:可以在一定程度上解释它的行为轨迹,理解它是如何一步步推理并得出最终答案的。研究团队编写了一个简易可视化工具,用来观察 RLM 的推理路径,展示了 RLM 实际在「动手做什么」。

令人振奋的早期结果
研究者一直在寻找能够真实反映长上下文任务场景的基准测试,例如 长时间多轮的 Claude Code 会话。他们希望通过这些任务重点突出当今前沿模型面临的两类核心限制:
1. 上下文退化现象 —— 模型性能随着上下文长度增加而退化;
2. 系统层面的约束 —— 模型在处理超大型上下文时出现的架构或交互瓶颈。
激动人心的成果 — 处理上下文退化
RLMs 旨在解决上下文退化问题,即当你有一个很长的 Claude Code 或 Cursor 实例时,它无法正确处理你的长历史记录的奇怪现象。
OOLONG 是一个具有挑战性的新型长上下文基准,其中模型在极其密集的上下文中回答查询。研究者选择了一个特别困难的分割点,在 OOLONG 基准测试的 trec_coarse 数据集上报告结果,GPT-5 在 132-263k token 上下文中得分约为 33%。
与此同时,一个使用 GPT-5-mini 的 RLM 在 132k 情况下以超过 114%(即超过两倍)的低查询成本优于 GPT-5,在 263k 情况下以 49% 的成本优于 GPT-5!

RLM (GPT-5-mini) 比 GPT-5 高出 34 分以上(约增长 114%),并且几乎每个查询的成本都相同(研究者发现中位数查询更便宜,因为有些异常昂贵的查询)。

RLM (GPT-5-mini) 比 GPT-5 高出 15 分以上(约 49% 的提升),并且平均每个查询的成本更低。
令人兴奋的结果 — 超大上下文
RLM 的设计目标之一,就是在无需额外辅助结构的情况下,处理近乎无限长度的上下文。
BrowseComp-Plus(BC+) 是一个 DeepResearch 任务基准,模型需要通过检索多个离线文档,来回答多跳组合性问题(multi-hop compositional questions)。
在目前的初步实验中,研究者从 BC+ 中抽取了一个小规模的查询子集,然后直接将不同数量的文档(从 10 份扩展到 1000 份,对应约 10 万到 1000 万 tokens)原样塞进上下文中。实验结果显示:基于 GPT-5 的 RLM 在跨越这些规模时性能并未下降,甚至优于采用 ReAct + 检索循环(retriever loops)的方法。

研究者在 BrowseComp-Plus 上对 20 个随机查询绘制了各种方法的性能和每个答案的 API 成本,随着上下文文档数量的增加。只有迭代方法(RLM、ReAct)在 100 篇文档以上时仍保持合理性能。
这些实验结果令人振奋:在没有进行任何额外的微调或架构改动的前提下,就能够在真实基准上处理超过 1000 万 tokens 规模的上下文,并且完全不依赖检索器(retriever)!
思考与总结
RLM 不是 agent,也不只是作总结。一个系统中使用多次 LM 调用的想法并不新颖 —— 从广义上讲,这正是多数 Agent 框架所做的事情。在现实中,最接近的例子是 ROMA Agent,它会分解问题并运行多个子代理来解决每一部分。另一个常见的例子是 Cursor 和 Claude Code 这样的代码助手,它们会在上下文越来越长时对历史进行摘要或裁剪。这些方法通常是从任务或问题的角度来理解多轮 LM 调用的分解。而研究者们坚持认为,LM 调用可以从上下文的角度进行分解,而分解方式应完全由语言模型自己来决定。
固定格式对 scaling laws 的价值。从 CoT、ReAct、指令微调、推理模型等理念中,得到的经验是:以可预测或固定的格式向模型呈现数据,对于提升性能至关重要。基本思路是,如果能将训练数据的结构约束到模型预期的格式,就可以用合理的数据量显著提升模型性能。将这些理念应用到改进 RLM 之上,或许可以作为另一条扩展轴。
随着 LM 的进步,RLM 也会进步。最后,RLM 调用的性能、速度和成本与底层模型能力的提升直接相关。如果明天最强的前沿语言模型可以合理处理 1000 万 token 的上下文,那么一个 RLM 就可以合理处理 1 亿 token 的上下文(可能成本还只有一半)。
研究者认为,RLM 与现代 Agent 是两种根本不同的押注方向。Agent 是基于人类 / 专家的直觉来设计如何将问题拆分为语言模型可以消化的形式。而 RLM 的设计原则是,应该由语言模型自己决定如何拆分问题,使之可被语言模型消化。
研究者坦言:「我个人并不知道最终什么会奏效,但我很期待看到这个思路会走向何处!」

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com