
题目:TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios
论文地址:https://arxiv.org/pdf/2505.12891
代码地址:https://github.com/sylvain-wei/TIME

创新点
本文创新性地设计了一个多层次评估框架,用于系统评估大型语言模型(LLMs)在真实世界场景中的时间推理能力。该框架将时间推理任务划分为三个渐进层次:基础时间理解与检索(Level-1)、时间表达式推理(Level-2)和复杂时间关系推理(Level-3)。
本文构建的TIME基准测试包含三个子数据集(TIME-WIKI、TIME-NEWS、TIME-DIAL),分别模拟了知识密集型场景、动态新闻事件和长对话交互中的时间推理挑战。
方法
本文的主要研究方法围绕构建和评估一个名为TIME的多层次基准测试展开,以系统评估大型语言模型(LLMs)在真实世界场景中的时间推理能力。首先,研究设计了多层次的任务框架,将时间推理任务划分为三个渐进层次:基础时间理解与检索(Level-1)、时间表达式推理(Level-2)和复杂时间关系推理(Level-3)。每个层次包含多个子任务,如时间信息提取、时间顺序判断、时间间隔计算、共时性分析、时间线重构和反事实推理等,以全面评估模型在不同时间推理维度的能力。
TIME基准测试的总体架构与挑战概述
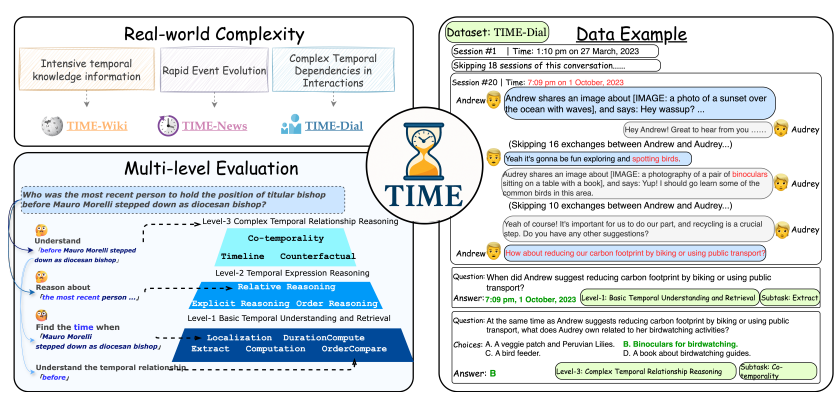
本图以系统化框架呈现了TIME基准测试的核心设计逻辑,揭示了其如何通过分层任务结构应对真实世界时间推理的三大核心挑战。图的左侧部分首先提炼出现实场景中时间推理的复杂性特征:高密度时间信息(如知识库中实体间交错的时间属性)、快速变化的事件动态(如新闻事件随时间演进的因果链)以及社交互动中隐含的时间依赖(如长对话中通过相对时间词回指历史事件)。这些挑战直接映射到中央的三级任务体系——Level-1基础时间理解与检索聚焦显式时间信息的提取与定位(如从文本中识别时间点、计算事件间隔);
TIME基准测试数据集构建流程:从原始数据到QA对的系统化生成
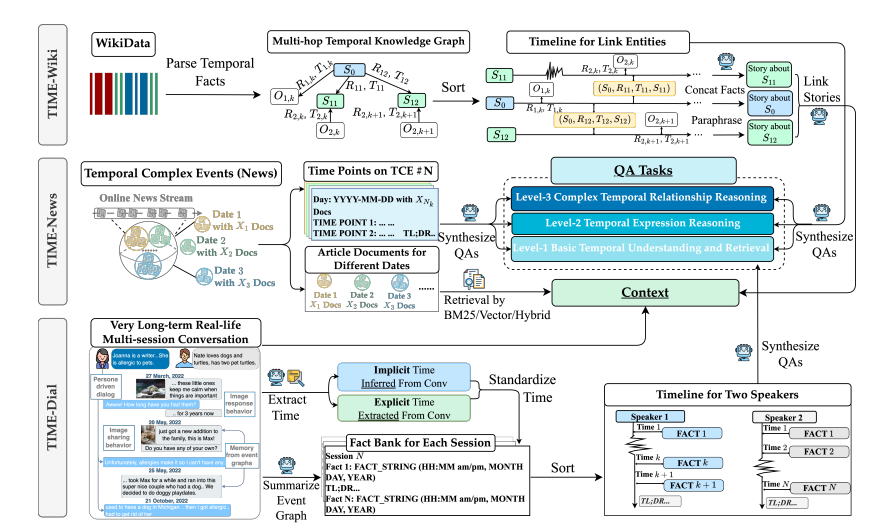
本图以流程图形式系统展示了TIME基准测试中三个子数据集(TIME-WIKI、TIME-NEWS、TIME-DIAL)的完整构建过程,覆盖从原始数据采集到最终问答对(QA)生成的全部技术环节。整个流程通过“数据-任务-评估”的闭环设计,确保TIME基准测试既能覆盖时间推理的微观能力(如时间表达式解析),又能检验宏观场景下的综合应用(如动态事件跟踪与多轮对话时间依赖处理),为LLMs的时间推理能力提供系统性诊断工具。
TIME基准测试中LLMs时间推理能力的多维度评估与性能对比
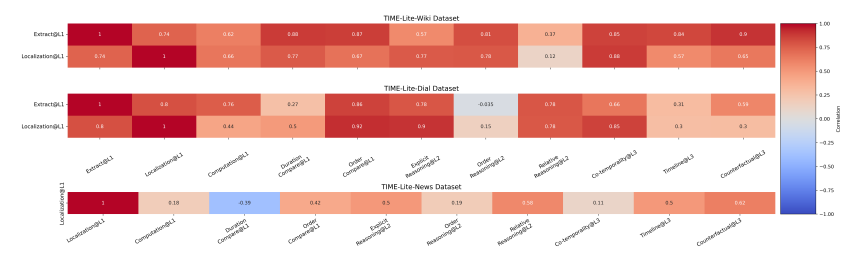
本图通过多维度可视化对比了不同大型语言模型(LLMs)在TIME基准测试中的时间推理能力,系统揭示了模型性能随任务层级、数据集类型及测试时缩放策略的变化规律。其核心分析框架涵盖三个层面:首先,图表横向对比了主流LLMs(如GPT-4、DeepSeek-V3、Qwen2等)在TIME-WIKI、TIME-NEWS、TIME-DIAL三个子数据集上的表现,发现模型在静态知识型任务(TIME-WIKI)与动态场景型任务(TIME-NEWS/TIME-DIAL)中呈现显著差异。其次,纵向分层展示了模型在三级任务体系中的性能递减趋势。所有模型在Level-1基础任务(如时间点提取、间隔计算)中均表现优异(准确率>85%),但在Level-2时间表达式推理(如相对时间推断)中平均下降12.7%,在Level-3复杂关系推理(如共时性分析、时间线重构)中进一步下降21.4%。这一趋势表明,现有LLMs的时间推理能力随任务复杂度的提升而快速衰减,尤其在需要多跳推理和上下文整合的场景中表现薄弱。
实验

本表通过结构化表格系统呈现了12种主流大型语言模型(LLMs)在TIME基准测试三个子数据集(TIME-WIKI、TIME-NEWS、TIME-DIAL)上的时间推理性能,结合任务层级(Level-1/Level-2/Level-3)与测试时缩放策略(TTS)的对比,揭示了模型能力差异、性能衰减规律及优化空间。其核心发现可归纳为以下层面:从模型维度看,参数规模与架构差异显著影响时间推理表现。闭源模型(如GPT-4、Claude-3.5)在Level-1基础任务中占据优势(准确率>90%),尤其在TIME-WIKI的显式时间检索任务中表现稳定;而开源模型(如DeepSeek-V3、Qwen2)在Level-2/Level-3任务中通过TTS策略(如思维链CoT)实现性能追赶,例如DeepSeek-V3在TIME-NEWS的Level-2任务中应用CoT后准确率从76.2%提升至82.7%,接近GPT-4的84.1%。这表明开源模型通过推理优化可部分弥补数据与架构的差距。本表通过量化对比清晰呈现了现有LLMs在时间推理任务中的能力边界:基础检索能力接近人类水平,但动态场景下的高阶推理能力仍需突破。这一发现为开发更强大的时间感知模型提供了关键依据。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码











