克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
英伟达桌面超算,邪修玩法来了!
两台DGX Spark串联一台苹果Mac Studio,就能让大模型推理速度提升至2.77倍。

这是GitHub三万星大模型框架作者EXO Lab团队发布的最新成果。

这个EXO Labs,专门研究把大模型放到各种家用设备上运行。
之前,还有,都是这家工作室的手笔。
这次他们又把DGX Spark和M3 Ultra结合,利用它们各自的优势,在大模型部署上整出了新活。
那么,这套邪修组合具体是如何实现的呢?
PD分离+流式传输,让设备各司其职
要想理解如何结合两种设备的优势,需要先了解大模型推理的工作方式。
大模型的推理,主要分为Prefill和Decode两个阶段。
Prefill处理提示并为每个Transformer层构建一个KV缓存,Decode阶段则是根据构建好的整个KV缓存生成token。
两个阶段任务不同,对硬件性能的侧重也不一样,整体上来说Prefill更吃算力,而Decode吃内存带宽。
具体来说,Prefill阶段计算量随提示长度呈二次增长,利用Flash Attention等技术,可以优化为线性增长,但计算量依然庞大,因此主要受制于计算能力;
到了Decode阶段,KV缓存已经计算完毕,不需要再重新运算,矩阵-矩阵乘法变成了运算量更低的向量-矩阵乘法比,对算力的需求降低,主要受制于内存带宽。
再看EXO Labs手里的两种设备,DGX Spark算力强但是带宽不行,Mac Studio搭载的M3 Ultra则刚好相反,内存带宽高但算力不如DGX Spark。
具体来说,DGX Spark有100TFLOPS的fp16算力,M3 Ultra只有26TFLOPS;而M3 Ultra有256GB@819GB/s的内存,DGX Spark却只有128GB@273GB/s。

所以,EXO Labs的思路就是把Prefill和Decode阶段分开,分别分配给擅长的设备,DGX Spark负责Prefill,Mac则负责Decode,这也就是AI Infra业界常说的PD分离。
最简单的PD方式就是先把Prefill做完,然后再传输给Decode设备进行Decode。
但这就增加了两个阶段之间的通信成本,如果传输时间过长,效果可能适得其反。
所以,进行PD分离运算需要解决的关键问题是,就是KV缓存传输。
这里EXO Labs运用了流式传输的思想。
我们在网上看电影、刷B站时,并不需要把整个视频文件加载完才能开始播放,而是将一小段加载到内存之后就可以观看,后面的内容边看边加载,这就是流式传输。
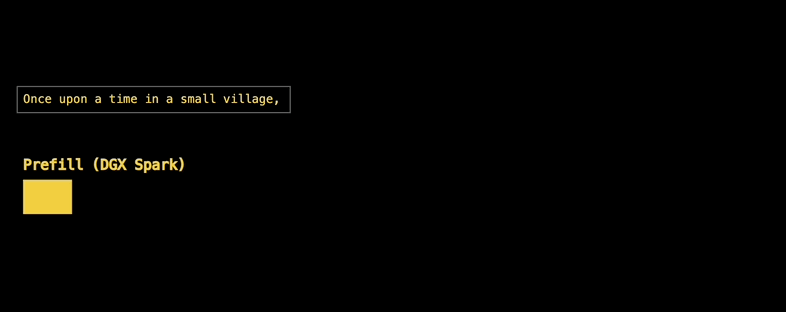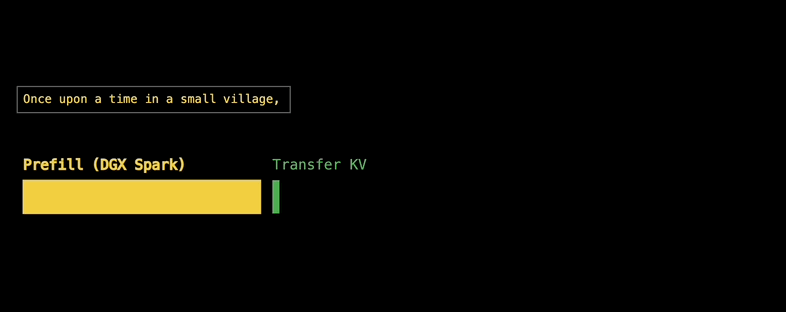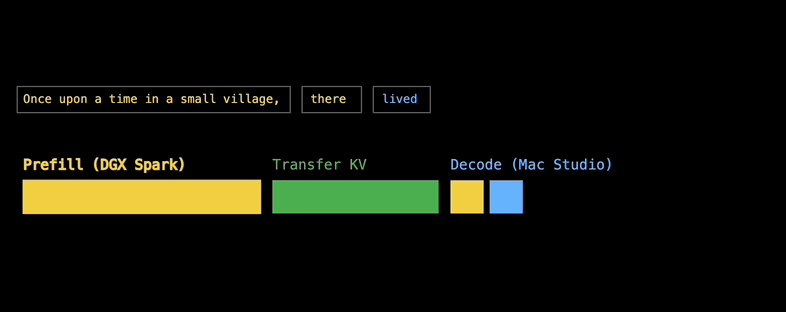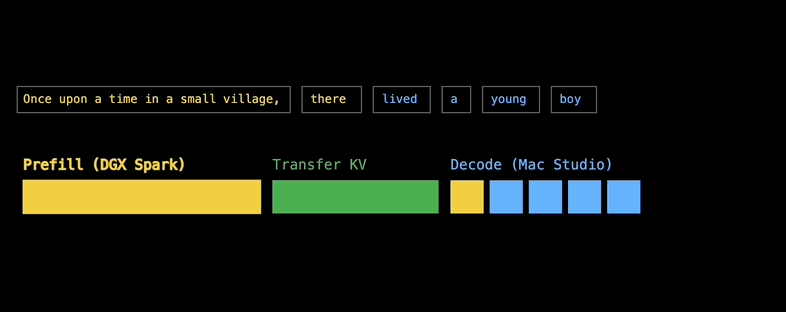
音视频可以边传边看,KV缓存也可以边算边传,因为大模型当中包含了多个Transformer层,使得KV缓存不一定非要以一个Blob的形式到达Decode设备,而是可以逐层到达。
第1层的Prefill完成后,其KV缓存就开始传输到给M3 Ultra去Decode,同时第2层的Prefill则在DGX Spark上开始,每一层的通信都与后续层的计算重叠。
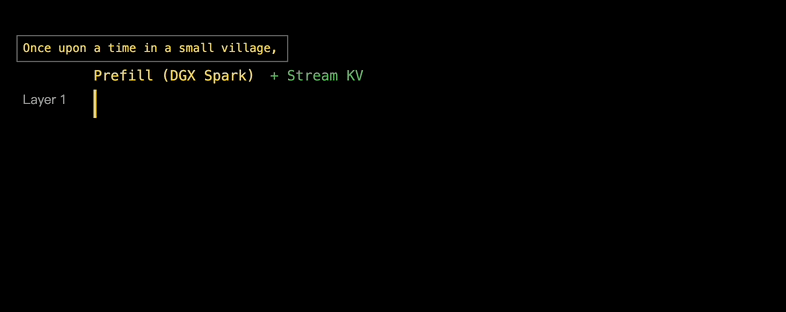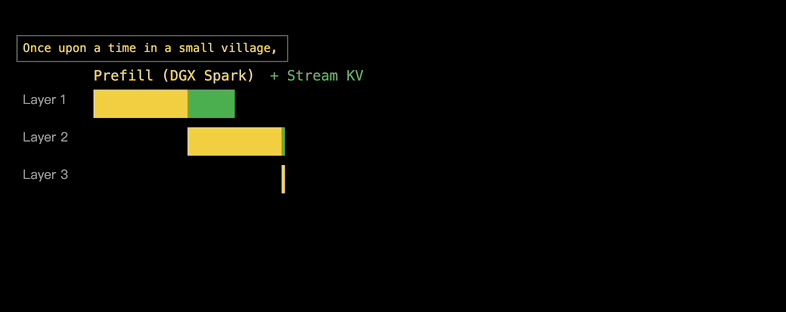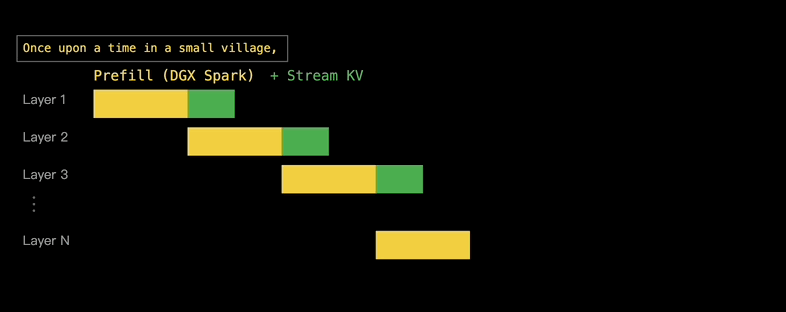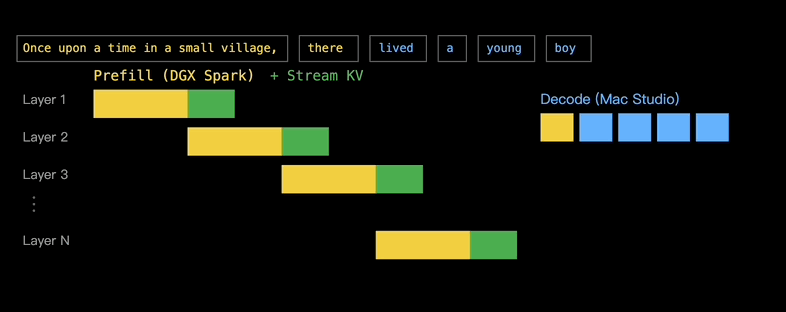
实际上, EXO还会在处理层的过程中传输该层的KV向量,因为KV向量的计算是在最繁重的计算步骤之前进行的。
利用EXO框架,PD分离、逐层KV流以及硬件感知都可以自动完成。
启动EXO时,它会自动发现连接的所有设备,并针对计算吞吐量、内存带宽、内存容量和网络特性对每个设备进行分析。
给定一个模型和拓扑结构, EXO就会规划哪个设备应该处理Prefill,哪个设备应该处理Decode,是否需要跨层流水线,何时传输KV对,以及如何在网络条件发生变化时进行调整。
最终,在DGX Spark和Mac Studio的组合下,Llama-3.1 8B在Prefill阶段的速度提升至了Mac的3.79倍,Decode速度提升至DGX Spark的3.37倍,整体提升至Mac Studio的2.77倍。

Three More Things
EXO这种PD分离的做法,英伟达自己也在进行尝试,其即将推出的Rubin CPX平台将使用计算密集型Rubin CPX处理器进行Prefill,配备巨大HBM3e内存带宽的标准Rubin芯片则负责Decode。

再说EXO团队这次用的DGX Spark,最近正在进行配送,马斯克、奥特曼还有LeCun都收到了,其中还有老黄亲自送货上门。

另外,AI性能也有一定提升。
在M5芯片的MacBook Pro上,首个Token生成速度(主要受Prefill影响)提升到了M1的6.4倍、M4的3.55倍。
另外,也有更快的图像/视频生成、更快的微调,以及更高的吞吐量。

不过宣传上说的是性能的又一次跃升,但仔细一看,M5甚至不如M4 Max,M4 Max又甚至不如M3 Ultra……
而EXO的这波操作下,M3 Ultra的含金量似乎更高了。
参考链接:
[1]https://blog.exolabs.net/nvidia-dgx-spark/
[2]https://www.tomshardware.com/software/two-nvidia-dgx-spark-systems-combined-with-m3-ultra-mac-studio-to-create-blistering-llm-system-exo-labs-demonstrates-disaggregated-ai-inference-and-achieves-a-2-8-benchmark-boost
[3]https://x.com/awnihannun/status/1978465715121250801










