
机器人学习3D操作任务(如从桌上拿起杯子),长期面临“数据效率低”的瓶颈——动辄需要数百次演示。核心挑战在于如何让视觉语言模型(VLA)真正理解3D场景并精准指导机器人动作(即输入输出对齐)。
中科院自动化所联合字节跳动Seed发布的BridgeVLA,不仅让机器人仅用3个示范轨迹就能达到96.8%的成功率,还斩获了CVPR 2025 GRAIL workshop的COLOSSEUM Challenge冠军!
注:以下涉及到的代码部分为小编基于自己的理解进行的复现,非作者团队开源内容。期待与各位读者就技术细节展开探讨,同时向论文作者团队致以诚挚感谢,其研究成果为我们提供了重要启发!

机器人学习困境
当前最先进的视觉-语言-动作模型(VLAs)面临一个尴尬的困境:
2D VLA模型的优势与痛点:
能利用预训练模型的丰富知识;具备强大的语言理解能力;在开放词汇任务上表现优异。但是需要大量数据(每个任务需要数百个轨迹);对3D空间理解有限;难以处理精确的空间定位任务
3D机器人策略的优势与局限:
样本效率高(约10个示范即可);能充分利用3D空间结构;在精确操作任务上表现出色。但是缺乏语言理解能力;泛化能力较弱;难以处理开放词汇指令。
这就像让一个人戴着眼罩去抓东西——虽然最终可能成功,但效率极低。现有的3D VLA模型试图结合两者优势,但它们通常将动作转换为没有空间结构的token序列:
输入不匹配:VLM在2D图像上预训练,但3D VLA直接输入3D信息,造成严重的分布偏移;
输出不对齐:将空间动作转换为离散token序列,丢失了关键的空间结构信息;
预训练浪费:无法充分利用大规模预训练模型中的知识。

范式转变:
从Next Token到Heatmap
BridgeVLA的核心创新在于它采用了输入输出对齐的策略,将预训练和微调的输入输出对齐到统一的2D空间,成功"bridge"了VLM和VLA之间的鸿沟:
输入对齐:3D→2D的智能转换
不同于传统3D VLA使用3D位置编码或3D信息注入,BridgeVLA采用了一种优雅的解决方案:
三视图正交投影:
将3D点云从三个正交方向(顶部、前方、右侧)投影成2D图像
每个视角捕获场景的不同空间信息
三个视图共同构成完整的3D空间表示

▲图1 | 概述。BridgeVLA是一个新颖的3D VLA模型,在统一的2D图像空间中对输入和输出进行对齐。它使用2D热图在目标定位上进行预训练,并在3D操作的动作预测上进行微调。在仿真和现实环境中的实验结果表明,它能够高效且有效地学习3D操作。©️【深蓝具身智能】编译
这种设计的妙处在于:
格式兼容:保持了与预训练VLM的2D输入格式完全一致
信息保留:正交投影保留了空间中的距离和角度关系
避免偏移:消除了3D到2D的分布偏移问题
计算高效:避免了处理高维3D数据的计算开销
输出对齐:从Next Token Prediction到Heatmap Prediction
这是BridgeVLA最大的创新点!传统方法将动作转换为离散的token序列,就像把一幅画描述成一串数字——信息损失巨大。
BridgeVLA创新性地使用2D热力图来表示动作:
热力图的数学表示:
其中,表示位置处的概率密度是目标位置的中心。
多视图融合策略: 对于所有感兴趣的对象,通过平均和归一化融合概率图:
这种表示方法的优势在于:
空间结构保持:热力图天然保留了2D空间结构信息;
精确定位:可以达到像素级的定位精度;
直观可解释:热力图可视化让动作预测过程一目了然;
反投影简单:可以直接反投影到3D空间确定精确位置。
可扩展的预训练策略:赋予VLM空间感知能力
BridgeVLA采用精心设计的两阶段训练策略:
预训练阶段的创新设计:
数据来源:使用RoboPoint数据集的12万张目标检测图像
输入格式:图片-目标文本对(如"Find all instances of cup")
处理流程: VLM处理图像和文本,输出包含空间信息的token
提取对应图像位置的token并重新排列
通过可学习的凸上采样(Convex Upsample)还原成原始分辨率的热力图
使用交叉熵损失监督热力图预测
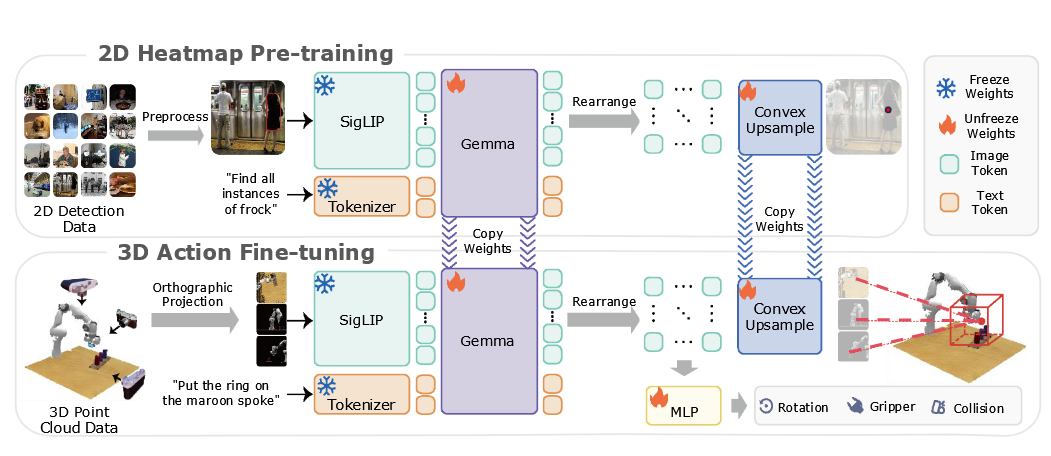
▲图 2 | 模型架构。(a) 2D热图预训练:我们在2D物体检测数据集上训练BridgeVLA。模型接收一张图像和描述目标物体的语言作为输入,输出一个2D热图,突出显示与目标物体相对应的感兴趣区域。请注意,这里显示的边界框仅用于说明目的;在输入模型的图像中并不存在。(b) 3D动作微调:模型接收3D点云的三个正交投影图像和语言指令作为输入。它输出三个2D热图,在所有三个视图中突出显示下一个关键帧中末端执行器的位置。对于剩余的动作组件,它使用MLP处理图像特征标记来预测下一个关键帧的旋转动作、抓取器动作和碰撞标志。©️【深蓝具身智能】编译
微调阶段的精巧实现:
输入处理:
从RGB-D图像重建3D点云
生成三个正交投影视图
与语言指令一起输入预训练的VLM
动作预测:
为每个视图生成2D热力图
将三个热力图反投影到3D空间
在均匀分布的3D网格点中找到得分最高的位置
该位置即为下一关键帧的末端执行器目标
其他组件预测:
旋转:离散化为72个角度bin,使用MLP预测
夹爪状态:二元分类(开/关)
碰撞标志:指示是否需要避障
知识保留的验证: 研究团队发现,即使经过机器人动作数据的密集微调,模型仍能准确预测预训练数据集中的目标检测任务。这证明了预训练知识被成功保留,为泛化能力奠定了基础。

技术细节深度解析
损失函数的精心设计
BridgeVLA的总损失函数包含四个精心平衡的部分:
各部分详解:
: 平移动作的交叉熵损失, 监督热力图预测的准确性;
: 旋转动作的交叉熵损失, 72个离散角度的分类任务;
: 夹爪状态的二元交叉熵损失;
: 碰撞避免标志的二元交叉熵损失。
粗到细的多级预测策略
这种策略借鉴了计算机视觉中的经典思想:
两步预测流程:
(1)粗预测阶段:
a. 在完整的3D点云上进行初步预测
b. 快速定位大致目标区域
c. 计算效率高,但精度有限
(2)细预测阶段:
a. 在预测位置周围裁剪一个立方体区域
b. 对裁剪后的点云进行放大
c. 进行第二次前向传播,获得精确位置
d. 显著提升了毫米级操作的成功率
数据增强策略
为了提高模型的鲁棒性,BridgeVLA同样采用了数据增强:
随机刚体变换:同时应用于点云和ground-truth动作
保持一致性:确保增强后的数据仍然物理合理
提升泛化:让模型适应各种空间变换
数据增强策略
# BridgeVLA伪代码实现

全方位验证:
屠榜三大基准测试
RLBench:18个复杂任务的全面胜利
RLBench包含了机器人操作的各种挑战性任务:
任务类型分析:
(1)非抓取操作(如slide block、push buttons):BridgeVLA展现出对精确控制的掌握;
(2)拾取放置(如stack cups、place wine):在空间推理上表现卓越;
(3)高精度插入(如insert peg、light bulb in):成功率提升最为显著。

▲表1 | RLBench上的结果。"平均排名"列报告了每种方法在所有18个任务中的平均排名,较低的值表示整体性能更好。BridgeVLA在18个任务中的10个任务中取得了最佳性能。©️【深蓝具身智能】编译
关键性能指标:
(1)平均成功率:81.4% → 88.2%(提升6.8%)
(2)平均排名:2.5 → 1.9(18个任务中排名第一)
(3)最大提升:Insert Peg任务从40%提升到88%(提升48%!)

▲RLBench 任务演示
深度分析:BridgeVLA在需要精确空间定位的任务上优势尤为明显。
例如在Insert Peg任务中,需要将销钉精确插入孔中,容错空间极小。传统方法由于缺乏精确的空间表示,成功率仅40%,而BridgeVLA通过热力图实现了像素级定位,成功率飙升至88%。
COLOSSEUM:斩获CVPR 2025 workshop冠军
COLOSSEUM是评估泛化能力的终极测试场,包含14种不同的环境扰动:

▲表2 | COLOSSEUM基准测试的结果。该表显示了14种泛化设置下的成功率。"平均排名"列报告了每种方法在所有扰动中的平均排名,较低的值表示整体性能更好。与最先进的基准相比,BridgeVLA将平均成功率提高了7.3%。©️【深蓝具身智能】编译
扰动类型:
(1)物体属性变化:纹理(TEXTURE)、颜色(COLOR)、大小(SIZE)
(2)环境因素变化:光照(Light Color)、背景(Background)、桌面(Table)
(3)视角变化:相机姿态(Camera Pose)
(4)干扰因素:添加干扰物体(Distractor)

▲COLOSSEUM 任务演示
性能表现:
(1)平均成功率:56.7% → 64.0%(提升7.3%)
(2)最具挑战的"All Perturbations"设置:15.6% → 18.7%
(3)在14种扰动中:13种排名均第一
鲁棒性分析: BridgeVLA在各种扰动下都保持了稳定的性能,特别是在Table Color(75.7%)和Background Texture(74.8%)等视觉干扰下表现优异。这得益于热力图表示对目标物体的精确定位,减少了背景干扰的影响。
GemBench:四层递增挑战的全面领先
GemBench通过四个递增难度的层次全面评估模型能力:
层次化测试设计:
L1(Novel Placements):相同物体的新位置
BridgeVLA成功率:91.1%,展现了强大的空间泛化能力;
L2(Novel Rigid Objects):未见过的刚性物体
BridgeVLA成功率:65.0%,在处理新物体形状和颜色组合上表现出色;
L3(Novel Articulated Objects):未见过的关节物体
BridgeVLA成功率:43.8%,在处理复杂机械结构上仍保持领先;
L4(Novel Long-Horizon Tasks):需要多步骤的复杂任务
所有方法都表现不佳(接近0%),当前技术的共同局限

▲GemBench任务演示
真实机器人实验:远超现有Baseline
实验设置:
硬件平台:Franka Research 3机械臂 + 平行夹爪
感知设备:ZED 2i深度相机
任务数量:13个基础任务
数据收集:通过示教方式收集专家轨迹

▲图3 | 真实机器人实验和结果。我们使用Franka Research 3机器人手臂和ZED 2i相机来捕获场景的点云。为了评估模型的性能,我们设计了7种不同的设置,包括一个基本设置和六个泛化设置。实验结果表明,BridgeVLA比最先进的基准方法RVT-2的性能平均高出32%。©️【深蓝具身智能】编译
七大测试场景的详细分析:
Basic(基础设置):
a. 3轨迹训练:96.8%成功率
b. 10轨迹训练:98.5%成功率
c. 证明了极致的数据效率
Distractor(干扰物):
a. 添加视觉相似的干扰物体
b. BridgeVLA:91%(RVT-2:70%)
c. 热力图的精确定位有效抵抗了干扰

▲干扰物任务演示
Lighting(光照变化):
a. 关闭灯光的极端条件
b. BridgeVLA:56%(RVT-2:10%)
c. 展现了对光照变化的鲁棒性

▲光照变化任务演示
Background(背景变化):
a. 使用三种不同桌布
b. BridgeVLA:100%(RVT-2:63%)
c. 完美适应背景变化

▲背景变化任务演示
Height(高度变化):
a. 物体放置在9.5cm高的抽屉上
b. BridgeVLA:80%(RVT-2:28%)
c. 3D空间理解能力的体现

▲高度变化任务演示
Combination(组合泛化):
a. 13种新的物体-技能组合
b. BridgeVLA:65%(RVT-2:15%)
c. 语言理解和空间推理的完美结合

▲组合泛化任务演示
Category(类别泛化):
a. 7个完全未见过的物体类别
b. BridgeVLA:30%(RVT-2:20%)
c. 仍有改进空间,但已超越基线

▲类别泛化任务演示

深层原因:
BridgeVLA为何如此高效
VLA新范式的确立
从"Next Token Prediction"到"Heatmap Prediction"的转变,是思维范式的革新:
传统范式:将空间问题转化为序列问题,信息损失严重
BridgeVLA范式:保持空间问题的空间表示,信息完整保留
完美的输入输出对齐
通过精心设计,BridgeVLA实现了多层次的对齐:
模态对齐:3D和2D信息的无缝转换
分辨率对齐:输入图像和输出热力图保持相同分辨率
语义对齐:预训练和微调任务的语义一致性
预训练知识的充分利用
解决了预训练模型应用于机器人的核心难题:
知识迁移:视觉理解能力完整迁移到机器人任务
语言理解:保留了VLM的语言理解能力
空间感知:通过热力图预训练增强了空间感知能力

总结
BridgeVLA不仅是一个技术突破,更代表了3D VLA发展的新范式。
这项斩获CVPR 2025 workshop冠军的工作,它成功证明了通过正确的设计选择,我们可以同时实现"efficient"和"effective"——用极少的数据达到极高的性能。
编辑|JeffreyJ
审编|具身君
论文题目:BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
论文作者:Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, Tieniu Tan
代码主页:https://bridgevla.github.io/
项目主页:https://bridgevla.github.io/home_page.html
论文链接:https://arxiv.org/abs/2506.07961
 【深蓝全域交流星球】
【深蓝全域交流星球】🔹大佬专访:每月访问 1 位领域先锋代表,打破交流限制
🔹具身智能特别栏目:即将上线至星球
🔹学术沙龙:北京、上海、杭州……多个城市巡回举办
🔹学术速递:每天至少 2 篇AI领域最新论文成果
🔹一作问答:不定期分享前沿工作,梳理形成万字技术文档

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文










