“如果说2024是大模型‘卷参数’元年,那2025就是‘卷落地’生死局。”
——SuperCLUE团队在10月16日放出的25页报告,用1260道全新考题、33位中外选手、6大硬核任务,给行业扔了一颗深水炸弹。
看完就能判断:自家业务到底该买谁家的API?到底还要不要自研?以及,距离AGI,我们还有多少GPU要烧?
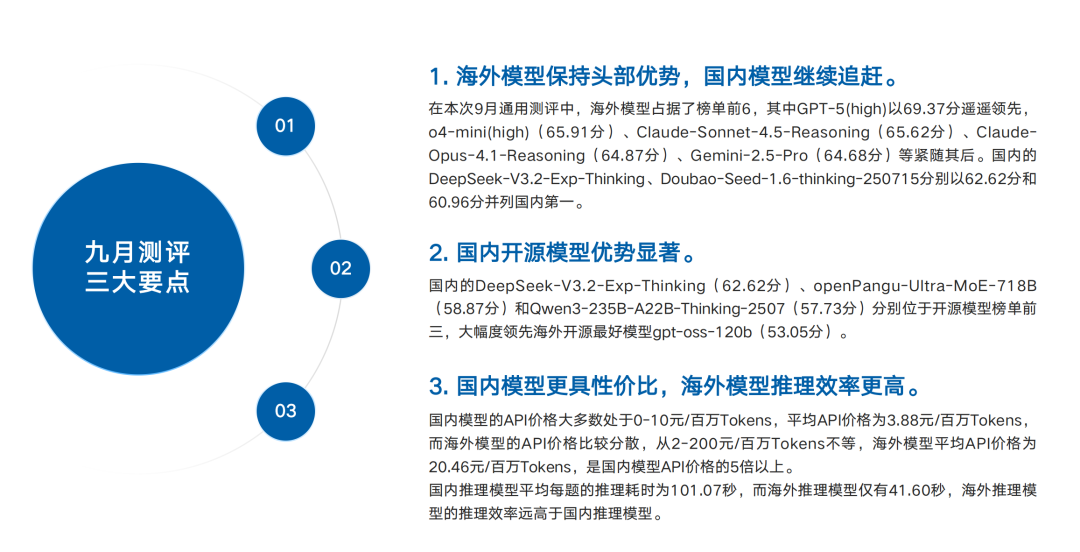
01|先上主榜:GPT-5(high)69.37分屠榜,国产TOP1 DeepSeek-V3.2-Exp-Thinking 62.62分,差距仍差1个「身位」
SuperCLUE九月总榜采用“六大任务平均分”,1260题100%原创题库,2个月一换,防止刷题过拟合。
海外军团包揽前6,平均分66.09;国产TOP5均值61.01,差5分——别小看这5分,在68→63区间,每1分都意味着几十亿美元的算力/数据/算法代差。
国内第一梯队座次
① DeepSeek-V3.2-Exp-Thinking 62.62
② Doubao-Seed-1.6-thinking-250715 60.96
③ ERNIE-X1.1 60.3
后面的Qwen3-Max、openPangu-Ultra-MoE-718B咬得非常紧,分差<0.8,国产“内战”比海外“群殴”还刺激。
02|开源战场:国产9/10霸榜,DeepSeek-V3.2-Exp-Thinking甩最强海外开源gpt-oss-120b 9.57分!

海外开源唯一排进前十的gpt-oss-120b仅53.05分,被国产前三轮番碾压。
更狠的是,Qwen3-235B-A22B-Thinking-2507、GLM-4.6、GLM-4.5把4-10名全部包圆,「开源=国产」已成铁事实。
一句话结论:如果今年你还用Llama-3-70B做中文业务PoC,老板可能得重新评估预算ROI。
03|价格维度:国产API平均3.88元/百万token,海外20.46元,相差5×!性价比之王诞生
把榜单横过来,按“得分/元”做散点图,右上角「高性价比区」清一色国产:
DeepSeek-V3.2-Exp-Thinking:62.62分,价格<5元
Doubao-Seed-1.6-thinking:60.96分,价格<3元
Qwen3-235B-A22B-Thinking:57.73分,价格<4元
而海外模型扎堆「低性价比区」:Claude-Opus-4.1-Reasoning高达213.9元/百万token,得分64.87,贵出天际。
采购建议:预算有限、又要推理质量,国产开源+API调用直接“真香”;土豪项目追求SOTA,再考虑GPT-5(high)或Claude-Sonnet-4.5-Reasoning。
04|速度维度:海外推理41.60秒/题,国产101.07秒/题,2.4倍时差决定「实时场景」生死
高效能区被海外包揽,国内无一入围。
如果你的场景是「对话客服/实时质检/语音交互」,对首token延迟<500ms是硬门槛,国产模型还得靠蒸馏、投机解码、边缘缓存做工程补课;否则再便宜也上不了生产。
05|六大能力拆解:国产在「代码、Agent、幻觉控制、指令遵循」四项领先,数学&科学仍落后

关键洞察
数学&科学仍是“卡脖子”硬核区,需要持续喂高质量中文STEM数据。
智能体Agent国产几乎追平,意味着「大模型+工具」落地,国产已能替代。
幻觉控制国产第一梯队>80分,金融、医疗、法律这些“说错一句话就赔钱”的场景,可以大胆试水国产。
06|Agent场景深扒:步数>8、轮数>5,所有模型得分雪崩;「数学计算」平均分仅44.47!
SuperCLUE把Agent拆成15个真实场景,每题最多24步、8轮对话。
票证系统、即时消息、购物系统,TOP5平均分>75,模型“像人”程度最高。
车辆控制、股票交易、数学计算,直接跌到59.9/57.9/44.5——只要涉及多步数值推理,所有模型集体“降智”。
落地启示
先做“查询类Agent”:订票、查库存、发通知,成功率高。
慎做“计算类Agent”:自动投研、量化交易、自动驾驶策略,必须加「符号验证/规则引擎」兜底,单靠大模型必翻车。
交互步数最好≤4轮,超过8轮用户体验断崖式下跌。
07|代码生成隐藏彩蛋:Web Coding是分水岭,独立函数大家都能80+,Web应用平均42.6!
所有模型在「独立函数生成」子任务标准差仅2.51,拉不开差距;一到「Web Coding」标准差飙升到10.84,瞬间分层。
国产TOP3 Web Coding得分:
Qwen3-Max 52.4
GLM-4.5 51.8
DeepSeek-V3.2 50.6
距离Claude-Sonnet-4.5的73.65还有20分鸿沟。
业务提示:如果今年你要用AI生成“可交付”前端项目,仍建议海外第一梯队;国产适合做“函数级”Copilot,全栈生成还需人肉Review。
08|幻觉控制死亡曲线:任务越开放,模型越胡说
SuperCLUE把幻觉拆成4档:
文本摘要 → 阅读理解 → 多文本问答 → 对话补全
国产/海外平均分依次递减,对话补全直接跌到61.2 vs 53.9。
防控锦囊
摘要/改写:用检索增强RAG+原文定位,基本可控。
开放对话:必须「事实性校验+置信度阈值+拒绝回答」三连,否则分分钟“造词条”。
医疗、法律场景:建议「国产第一梯队+规则知识图谱」双保险,别迷信单一大模型。
09|指令遵循:海外模型鲁棒性碾压,5条叠加指令国产平均分只剩25.15!
报告把指令复杂度从1条拉到5条,国产平均分由82.1→25.2,海外由90.0→39.1,差距越拉越大。
工程化解法
少样本+思维链:把复杂指令拆3步,让模型先复述再执行,准确率+18%。
动态限宽:每轮只给当前步骤指令,历史指令放system prompt,减少遗忘。
关键场景用「GPT-4/Claude」小流量兜底,国产模型做80%低成本分流。
10|与人类一致性验证:SuperCLUE得分 vs Chatbot Arena,Spearman 0.9108,几乎锁死
很多老板担心“刷榜≠体验”,SuperCLUE团队拿自己得分去对齐英文社区最权威的LMArena,结果相关系数0.91,P值<1e-6。
翻译成人话:在SuperCLUE排名高的模型,真人盲测也喜欢。以后采购直接按榜单砍价,不用再“拍脑袋”。
11|AGI不是一蹴而就,但商业闭环已经到来
SuperCLUE这份报告最震撼我的,不是谁第一谁垫底,而是「国产模型在80%场景已具备可替代性」。
剩下的20%,数学、科学、复杂指令、实时交互,是下一阶段「数据-算力-算法」硬攻坚。
对于产业人,别再问“大模型行不行”,而要问“在我这个细分场景,哪一款模型、哪一种工程化组合,能让我在6个月内回本”。






 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。