
论文名称:Ask-to-Clarify: Resolving Instruction Ambiguity through Multi-turn Dialogue 论文链接:https://arxiv.org/abs/2509.15061
写在前面&出发点
具身智能体的最终目标是成为能够与人类主动交互的协作者,而不仅仅是被动遵循指令的执行者。这要求智能体能够根据人类反馈调整自身行为。

近年来,视觉-语言-动作模型(VLA)的发展为实现这一目标提供了一条有前景的路径。然而,目前大多数基于VLA的具身智能体以一种简单的单向模式运行:即接收指令后便直接执行,没有任何与用户的交流。在指令通常具有模糊性的真实世界场景中,这种被动的方法往往会失效。针对这一问题,本文提出了Ask-to-Clarify框架。该框架首先通过多轮对话提出问题以解决指令的模糊性,随后以端到端的方式为真实世界的具身任务生成动作。
本工作的贡献
任务与框架设计:
提出了一项新的具身智能体协作任务及相应的框架。该任务要求智能体在执行指令前,先通过提问的方式主动消除指令的模糊性,随后完成任务执行。为解决该任务,本文设计了一个结合视觉-语言模型(VLM)和扩散模型的框架,其中VLM用于提出问题,扩散模型用于生成动作。此外,本文引入了一个连接模块,用于平滑衔接两个子模块,使得VLM的输出能为扩散模型提供更加稳定可靠的条件输入。训练策略设计:
提出了一种两阶段的“知识隔离”训练策略。该策略首先在第一阶段训练中赋予模型与人类交互的能力;随后,在第二阶段训练中,通过冻结视觉-语言模型的参数,保持其交互能力,并进一步训练扩散模型以提升其在具身任务中的执行能力。实验验证:
在多个真实世界任务中对所提出的框架进行了系统评估,实验结果验证了Ask-to-Clarify框架在任务执行中的有效性。
方法介绍
本文提出的Ask-to-Clarify框架由两个核心组件构成:一个用于人机协作的视觉-语言模型,以及一个用于动作生成的扩散模型。此外,本文设计了一个连接模块,将视觉-语言模型的输出转化为扩散模型的条件输入。该模块根据任务指令,对观测信息进行调整,从而生成更优、更可靠的动作条件。
在训练策略方面,Ask-to-Clarify框架采用了两阶段的“知识隔离”训练方法。首先,在特定的交互式对话数据上微调协作组件,使其具备处理模糊指令的能力;随后,在保持协作组件参数冻结的前提下,引入动作生成组件并进行联合训练。该策略有效保留了协作能力,同时优化了扩散专家在动作生成方面的性能。训练完成后,Ask-to-Clarify框架能够在面对模糊指令时先行提问,随后再生成相应的动作,实现完整的端到端流程。
任务定义
设想一个具身智能体在家庭环境中根据人类指令执行任务的情境。例如,当桌面上只有一个杯子时,指令“请把杯子递给我”是正确的,智能体可以直接执行该指令。然而,当桌面上存在多个杯子时,该指令是模糊的。在这种情况下,一个具备协作能力的智能体应当主动向人类用户提问以获取更多信息从而解决指令的模糊性。然而,现有的视觉-语言-动作模型尚不具备此类能力,这在很大程度上限制了它们在现实人类环境中的应用。
为了评估具身智能体是否能够通过提问消除指令的模糊性,并基于用户回答推理出正确的用户意图,本文提出了一项新的任务。该任务包含两个步骤:首先,智能体需要与人类用户进行交互,通过提问从模糊指令中推理出正确指令;其次,智能体应基于该正确指令成功执行相应任务。该任务要求智能体在行动之前主动提出问题以应对模糊指令,相比于现有任务中仅要求智能体单向执行指令的设置,本任务更贴近现实世界中的交互需求。
形式上,给定一个模糊指令 和视觉观测信息 ,智能体通过多轮对话完成消歧。在每一轮交互中,智能体根据模糊指令、视觉观测以及之前的用户回答 ,生成一个问题 ,并接收来自用户的回答 。
经过 轮对话后,智能体根据所有的问题与回答推理出正确指令 ,随后基于该指令与视觉观测生成动作序列 ,以完成任务。
训练策略
为训练一个能够与人类交互并以端到端方式生成低层级动作的协作型具身智能体框架,本文提出了一种两阶段的“知识隔离”训练策略。该策略首先赋予模型解决指令模糊的能力,随后在保持该能力不遗忘的前提下,使模型具备端到端生成动作的能力。
阶段一:应对模糊指令
Ask-to-Clarify框架解决指令模糊性的能力是从专门解决模糊性问题的交互对话数据中学习得到的。本文首先构建包含多个相似物体的场景,这些物体在部分而非全部属性上有所不同,例如,两个仅在颜色上存在差异的方块。然后,本文利用大语言模型(LLM)基于构件好的的场景生成模糊指令、问答对以及正确的指令。最后,本文使用这些生成的内容来构建对话数据。通过这个过程,本文构造了解决模糊性问题的交互对话数据集。
本文使用上述交互对话数据来训练Ask-to-Clarify框架的协作组件。为了确保该框架能够在提问和行动之间无缝切换,本文在此训练阶段向预训练的视觉语言模型中添加了新的标记(token)。因此,Ask-to-Clarify框架学会使用<AMBG>标记来表示指令是模糊的,并进而提出问题。一旦通过对话解决了模糊性,Ask-to-Clarify框架会使用<NOT\_AMBG>标记来标识其已生成的正确指令,并将该指令作为输入。在接收到正确指令后,Ask-to-Clarify框架会根据指令和视觉观测输出<ACT>或<REJ>,即只有当目标物体出现在观测范围内时才执行动作,否则拒绝执行。
在此训练阶段,本文通过解耦动作组件,将重点完全放在视觉语言模型上。本文冻结了视觉编码器,仅微调VLM中的大语言模型部分,以利用VLM预训练阶段学到的知识。通过这种方式,本文高效地调整了协作组件,使其能够在具身任务中针对模糊指令提出问题,并从中用户回答中推断出正确的指令。
阶段二:端到端动作生成
在此阶段,本文通过分层式的框架设计提供了一种端到端的动作生成方法,同时通过知识隔离机制保留了上一阶段学到的解决指令模糊性的能力。这一阶段的目标是构建一个能够在执行动作前通过交互来应对模糊指令的具身智能体。
本文通过冻结Ask-to-Clarify框架的协作组件来实现知识隔离。这可以防止在具身任务训练过程中发生对话能力的灾难性遗忘。本文将这种方法称为“知识隔离”,因为本文通过在训练期间隔离存储知识的容器来保护这些知识。
为了平滑地连接VLM和扩散模型,本文引入了一个连接模块,为后者创建可靠的条件。该模块首先从VLM的输出中提取指令和视觉观测,然后利用指令来调整视觉观测。模块的输出整合了关于环境和人类意图的全面信息。因此,它为扩散模型专家提供了最优条件,从而能够成功生成动作。 在训练数据方面,本文使用带有正确指令的专家演示。这使得Ask-to-Clarify框架具备了在真实世界中执行具身任务的能力。通过这种两阶段的知识隔离训练策略,本文训练出了一个协作式具身智能体,它能够通过多轮对话应对模糊指令,并执行真实世界的具身任务。

推理过程
在推理阶段,Ask-to-Clarify框架作为一个协作式具身智能体,首先与人类用户进行对话,然后基于对话中推理出的正确指令执行实际任务。
为视觉-语言模型的交互能力与扩散模型的具身能力之间的无缝衔接,本文引入了一个无需训练的信号检测器,在推理过程中充当路由器的角色。该检测器接收来自 VLM 输出末尾的信号标记,并据此决定接下来的行为流程。
在训练的第一阶段中,本文引入了四种信号标记:<AMBG>、<NOT_AMBG>、<ACT> 和 <REJ>。这些标记覆盖了真实世界中常见的模糊指令与具身任务的所有可能情境。
当接收到一条指令时,Ask-to-Clarify框架的协作模块首先判断其是否存在模糊性。对于正确的指令,模型直接输出<ACT>,进入任务执行阶段。而对于模糊指令——这在现实人类环境中非常常见——模型输出以<AMBG>标记的问题,并等待用户的回答。每一轮问答都会被追加至对话历史中,作为下一轮推理的输入。
经过多轮问答后,协作模块通过对话推理出正确的指令,并以<NOT_AMBG>标记。信号检测器随后会从VLM的输出中提取该正确指令,并将其重新输入至VLM。VLM根据正确指令与当前视觉观测,输出<ACT>或<REJ>,分别表示是否执行动作——仅当目标物体在视觉观测中出现时,模型才执行任务,否则拒绝执行。

实验
Ask-to-Clarify框架旨在构建一个具身协作智能体。为了实现该具身智能体,本文提出了一种两阶段的知识隔离训练策略,以有效训练Ask-to-Clarify框架。该框架主要由协作组件与动作组件构成。
其中,协作组件用于与人类进行交互,动作组件则以端到端的方式生成动作指令。为了实现协作组件与动作组件之间的平滑衔接,本文引入了连接模块,使得协作输出能够更有效地引导动作生成过程。
为验证所提出框架的有效性,本文在真实环境中开展了一系列实验。首先,本文通过真实场景实验评估框架在训练过程中是否获得了Ask-to-Clarify能力,并考察其整体性能。在这些实验中,智能体需首先通过与用户的对话解决指令模糊性,随后根据推理出的正确指令执行任务。
接着,本文对关键设计进行了消融实验,重点考察训练策略与连接模块的影响。此外,本文还设计了用于评估框架协作能力的实验。最后,本文测试了Ask-to-Clarify框架在非理想环境中的鲁棒性,例如弱光条件或存在干扰物的场景。
机器人平台
本文在真实环境中使用xArm 7执行实验。该机械臂具有7个自由度及1个自由度的抓取器。本文通过官方提供的xArm API控制机器臂,并使用RealSense D435摄像头作为腕部视角和第三人称视角的摄像头。
任务设计
本文设计了一组真实场景下的任务以评估框架性能。在每个任务中,模型需首先从模糊指令中推理出正确指令,并据此生成动作。本文共设计了8个具体任务,分为以下三类:
将水果放在盘子上 → 将 Object放在盘子上,其中Object∈{苹果、桃子、橘子}(共 3 个任务)。将水从杯子倒入盘子中 → 将水从 Color杯子倒入盘子中,其中Color∈{红色、绿色、白色}(共 3 个任务)。堆叠积木 → 将 Color1积木堆叠在Color2积木上,其中(Color1,Color2)∈{(蓝色, 黄色), (黄色, 蓝色)}(共 2 个任务)。
训练数据
在第一阶段训练中,本文采用Qwen3-235B-A22B生成交互式对话数据。在第二阶段训练中,本文使用Meta Quest 3进行遥操作,为每个任务手动采集了10条专家演示。
实验结果
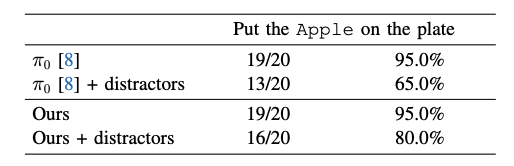
和baseline模型的比较: 对比了SOTA的自回归式VLA(Pi0-FAST)、串行VLA(OpenVLA-OFT)、并行VLA(Pi0)。 Ask-to-Clarify框架的性能显著超过baseline模型。 部分baseline模型(Pi0-FAST、OpenVLA-OFT)无法完成任务的原因是其不同指令的相似度太高。


训练策略: 消融了训练策略和连接模块。 两阶段的“知识隔离”训练策略&连接模块使得模型具有Ask-to-Clarify能力。 连接模块可以重建VLM和扩散模型在第一阶段训练中被破坏的连接。

协作能力: 通过与外接了VLM的Pi0对比,体现Ask-to-Clarify框架的协作能力。

低光照场景: 和训练数据相比,减少了50%的光照。 Ask-to-Clarify框架在低光照场景下的表现优于Pi0。

干扰物: 添加了和目标物体相似的干扰物,测试模型的鲁棒性。 Ask-to-Clarify框架在有干扰物的场景下的表现优于Pi0。
总结
在现实世界中执行复杂任务时,如何理解模糊指令并将其转化为具体行动,一直是人工智能领域的重要挑战。本文提出了 Ask-to-Clarify框架,旨在解决这一问题。该框架通过多轮对话先推断用户的意图并得到正确指令,再端到端地生成动作,从而完成真实环境中的具身任务。
这个协作框架由两个核心模块构成:
协作模块:基于标准的视觉语言模型,负责与用户进行语言交互,理解并澄清任务需求; 动作模块:采用预训练的扩散模型,用于生成具体的动作。
为了让这两个模块高效协同,本文还设计了一个连接模块,该模块能够根据语言指令调整视觉观察结果,从而为扩散模型提供更可靠的输入条件。
在训练过程中,本文提出了一种两阶段的知识隔离训练策略。该策略在保持视觉语言模型交互能力的同时,细化动作模块的能力,使其能够根据用户意图生成连续、准确的动作序列,最终实现端到端的动作生成。
在推理过程中,系统还配备了一个信号检测器,作为“路由器”,根据当前任务状态自动在“提问”与“执行”之间切换,从而实现自然且流畅的人机协作。
为验证框架的有效性,本文进行了多项真实世界实验。实验结果表明,该框架不仅能通过对话澄清不正确的指令,还能高可靠性地生成动作并完成具身任务。此外,论文还设计了一系列消融实验,深入剖析了框架中各模块的作用与设计思路,为后续研究提供了有价值的参考。
参考
[1] Ask-to-Clarify: Resolving Instruction Ambiguity through Multi-turn Dialogue











