
用于芯片互联基础设施的光学技术
谷歌采用软件定义网络方法,通过光路交换机管理网络路由。一个NxN光路交换机本质上就像一个拥有N条进站轨道和N条出站轨道的大型火车站。任何进站的列车都可以被转接到任何出站轨道上,但这需要在站内重新配置。列车不能“折返”或通过另一条进站轨道送回,它们只能被路由到N条出站轨道之一。
这种方法的好处在于,网络可以组合出更小的逻辑TPU切片——用于不同的工作负载——其规模可从芯片互联基础设施网络层理论最大的9,216颗芯片进行划分。通过在更大的集群中进行切片,并围绕网络中的故障重新路由芯片互联路径,集群的可用性得以提升。
与诸如Arista Tomahawk 5这类电子包交换交换机不同(其总带宽固定,并进一步分割为多个较小带宽的端口),光路交换机允许任何带宽的光纤连接到其端口。与电子包交换相比,光路交换机的延迟也更低,因为进入光路交换机的光信号只是从输入端口反射到输出端口。而对于电子包交换,光信号在进入交换机时必须转换为电信号——这是光路交换机通常比电子包交换机能效更高的一个关键原因。电子包交换允许数据包从任何端口路由到任何端口,而光路交换机只允许你将一个“输入”端口路由到任何其他“输出”端口。
来源:谷歌
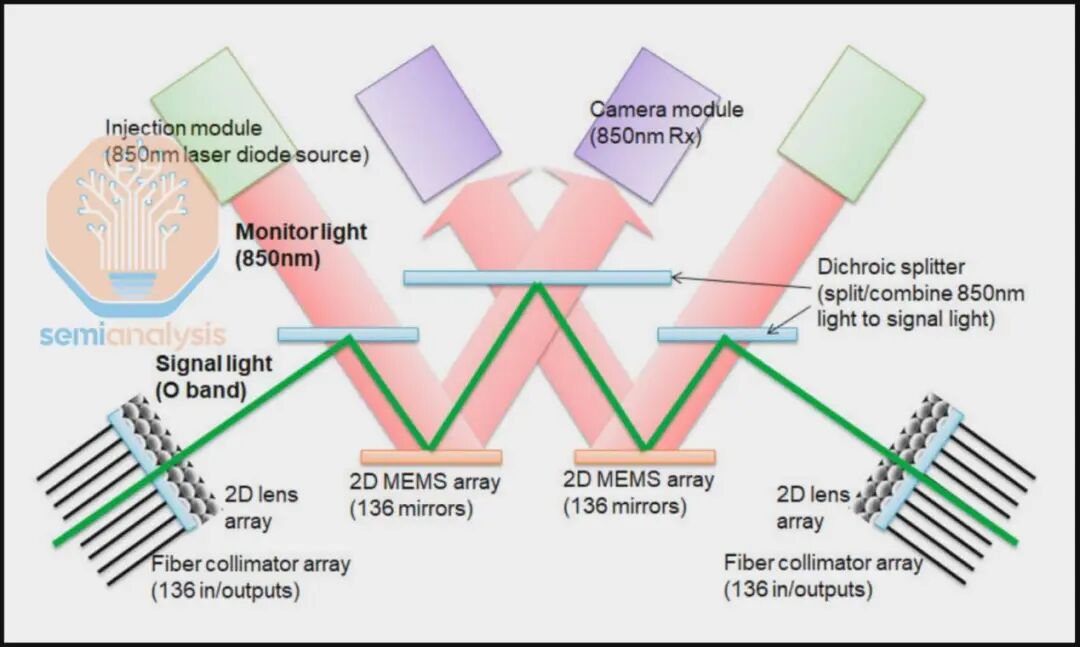
光路交换机端口仅路由单根光纤。这对标准的双工光模块构成了挑战,因为带宽是通过多根光纤传输的,这会降低光路交换机的有效端口密度和带宽。为解决此问题,采用了全光环路光模块,将所有波长合并到单根光纤上,以便连接到一个光路交换机端口。阿波罗项目通过两步创新性地实现了这一点。首先,通过粗波分复用技术将8个波长(每个波长对应一个100G通道)复用,在一对光纤上传输800G,而非使用8对光纤。其次,在波分复用光模块上集成一个光环行器,以实现全双工数据流,从而将需求从一对光纤减少到仅需一根光纤。

来源:谷歌
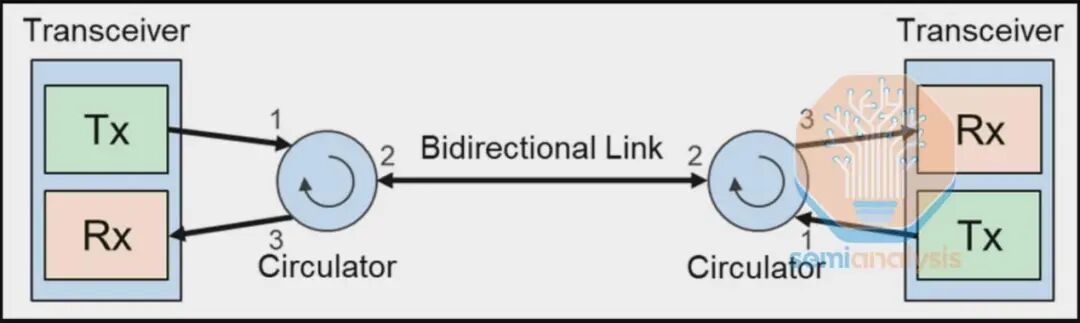
该环行器通过将光模块上的发送和接收光纤合并到一根送往光路交换机的光纤上,形成了一个双向链路。
来源:谷歌
连接多个64 TPU立方体
谷歌的芯片互联基础设施纵向扩展网络独特之处在于,它允许以三维环面配置连接多个64 TPU的4x4x4立方体,从而创建超大规模的计算世界。TPUv7宣称的最大世界规模为9,216个TPU,但目前谷歌支持将TPU配置为从4个TPU一直到2,048个TPU之间的多种不同切片规模。

来源:谷歌
尽管谷歌能够创新地实现令人印象深刻的9,216个TPU纵向扩展集群,但在任意时间点上,在增量增大至约8,000个TPU的块规模上运行训练工作负载的边际效益是递减的。这是因为更大的块规模更容易出现故障和中断,从而降低了切片可用性(其定义为芯片互联基础设施集群能够形成一个连续的三维环面切片的时间比例)。

来源:谷歌
对于可以完全容纳在一个4x4x4立方体内的切片,我们可以简单地利用机架内的铜缆互联以及立方体表面/边/角上的光模块(如需完成三维环面连接则进行回绕)从该立方体中划分出这些切片。
为了解回绕和立方体间连接是如何建立的,让我们首先看看如何在4x4x4拓扑中创建一个64 TPU的切片。我们可以使用对应于一个物理64 TPU机架的单位4x4x4立方体(64个TPU)来构建此拓扑。4x4x4立方体内部的所有8个TPU都可以使用铜缆完全连接到所有6个邻居。如果一个TPU在给定轴向上没有内部邻居,它将回绕并连接到立方体对侧的TPU。例如,TPU 4,1,4在Z+方向没有内部邻居,因此它将使用一个800G光模块连接到一个分配给Z轴的光路交换机,该光路交换机被配置为将此连接指向立方体的Z-侧,连接到TPU 4,1,1。在Y-方向,TPU 1,1,1将使用一个光模块连接到Y轴光路交换机,以链接到TPU 1,4,1的Y+侧,依此类推。

来源:SemiAnalysis,谷歌
4x4x4立方体的每个面将通过16个不同的光路交换机连接——每个面上的每个TPU对应一个光路交换机。
例如,在下图中,在X+面上,TPU 4,3,2连接到光路交换机X,3,2的输入端。光路交换机X,3,2的输入端也将连接到9,216 TPU集群中所有144个4x4x4立方体的X+面上的相同TPU索引位置(4,3,2)。然后,光路交换机X,3,2的输出端将连接到集群中每个立方体的相同TPU索引位置,但这次是在X-面上——因此它将连接到集群所有144个立方体上的TPU 1,3,2。下图说明了立方体A的X+面上的所有16个TPU如何通过16个光路交换机连接到立方体B的X-面上的16个TPU。
这些连接允许任何立方体的任何“+”面连接到任何其他立方体的“-”面,从而在形成切片时实现立方体的完全可互换性。
有两点约束需要简要指出。首先,给定面上同一索引位置的TPU永远无法直接连接到不同索引位置的TPU——因此TPU 4,3,2永远无法被配置为连接到TPU 1,2,3。其次,由于光路交换机本质上充当配线面板——连接在输入端的TPU无法“回环”连接到同样连接在该光路交换机输入端的任何其他TPU——例如,TPU 4,3,2永远无法连接到TPU 4,3,3。因此,任何“+”面上的TPU永远无法连接到任何其他立方体的“+”面,任何“-”面上的TPU也永远无法连接到任何其他立方体的“-”面。

来源:SemiAnalysis,谷歌
让我们扩大规模,看看如何设置一个4x4x8拓扑。在此配置中,我们通过沿Z轴连接两个64 TPU的4x4x4立方体来扩展切片。在这种情况下,光路交换机将重新配置TPU 4,1,4所连接的光端口,使其现在连接到TPU 4,1,5,而不是像独立的4x4x4拓扑那样回绕到TPU 4,1,1。延伸开来,我们将有16个光连接从两个4x4x4 TPU立方体各自的Z-和Z+面延伸出来,总计64根光纤连接到16个Z轴光路交换机。
需要提醒读者的是,下图中描绘的立方体A和立方体B在物理上不一定彼此相邻。相反,它们通过光路交换机连接,并且可能各自位于数据中心内完全不同的位置。

来源:SemiAnalysis,谷歌
我们现在将转向一个更大的拓扑——16x16x16拓扑,这将我们带到4,096个TPU。在此拓扑中,我们总共使用48个光路交换机来连接64个立方体(每个立方体64个TPU)。在下图中,每个多色立方体代表一个64 TPU的4x4x4立方体。以右下角的4x4x4立方体为例——该立方体通过光路交换机沿Y轴连接到相邻的立方体。
9216个TPU的最大世界规模是通过144个4x4x4立方体构建的,每个立方体需要96个光连接,总计需要13824个端口。将此总端口需求除以288(每个光路交换机有144个输入端口和144个输出端口),意味着我们需要48个144x144的光路交换机来支持这个最大世界规模。

来源:SemiAnalysis,谷歌
原文媒体:SemiAnalysis
原文作者:Dylan Patel; Myron Xie; Daniel Nishball
原文链接:
https://newsletter.semianalysis.com/p/tpuv7-google-takes-a-swing-at-the











