要问哪个是当下最流行的模型结构,那必然是Transformer。尤其近几年,因为LLM大行其道,我们对Transformer的探索热情成倍上升。
具体体现在各方大佬发布的诸多成果上,比如李飞飞团队的FlowMo、字节seed出品的SAIL、何恺明CVPR2025新作、微软Spectformer...CVPR/ICLR/nature methods等顶会顶刊上相关研究也数目繁多,可谓盛况空前。
细看之下,Transformer目前主要有两大创新路径:改进和应用。我根据这两类整理了16篇最新成果,基本都是顶会顶刊且有代码,方便大家作参考,好针对Transformer不同组件做创新,实现加速或提效。
扫码添加小享,回复“流行模型”
免费获取全部论文+开源代码

改进
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
方法:论文提出SAIL模型,单Transformer架构,直接处理图像和文本,无需预训练视觉编码器。它靠混合注意力机制与多模态位置编码提升性能,数据可扩展性强、视觉表征能力优,随预训练数据增多表现更好,在视觉任务中出色。

创新点:
SAIL模型用单Transformer架构,直接处理图像和文本,不用预训练视觉编码器。 SAIL有混合注意力机制,图像块双向、文本因果,还有多模态旋转位置编码。 经大规模预训练和扩展,SAIL在多模态任务表现与模块化MLLM相当,视觉表征任务出色。

SpectFormer: Frequency and Attention is what you need in a Vision Transformer
方法:SpectFormer是新型视觉Transformer架构,结合频谱层与多头注意力层。初始层用频谱层捕捉图像局部特征(如线条、边缘),深层用多头注意力层处理全局特征及长距离依赖,在图像分类任务中性能提升显著。

创新点:
提出SpectFormer架构,结合频谱层和多头注意力层,提升视觉Transformer性能。 频谱层置于架构初期,捕捉图像局部频率信息,如线条和边缘;多头注意力层置于深层,处理全局特征和长距离依赖。 在ImageNet等数据集上,SpectFormer-L达85.7% top-1准确率,优于纯频谱或纯注意力Transformer。

扫码添加小享,回复“流行模型”
免费获取全部论文+开源代码

应用
Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer
方法:哈尔洛3(Hallo3)是一种新型的肖像动画技术,它运用基于Transformer的预训练视频生成模型,通过身份数字参考网络保持面部特征一致性,并利用语音音频驱动视频生成,从而创造出高度动态且逼真的肖像动画。

创新点:
提出首个基于预训练Transformer的视频生成模型用于肖像动画,能生成高度动态、逼真视频,解决非正面视角等挑战。 设计身份数字参考网络,结合因果3D变分自编码器与Transformer层确保面部身份一致。 探索多种语音音频条件和运动帧机制,实现语音驱动连续视频生成,提升连贯性与真实性。
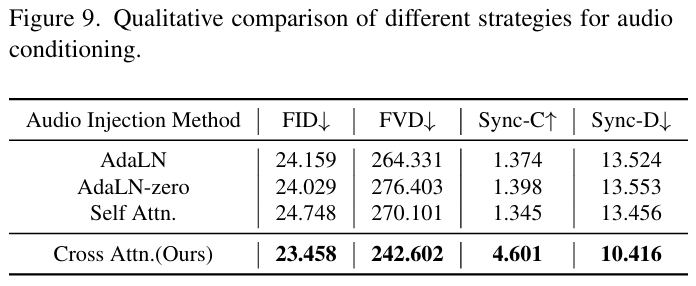
Haploomni: Unified single transformer for multimodal video understanding and generation
方法:HaploOmni是一种高效的单Transformer模型,用于多模态视频理解和生成。它通过多模态预热策略利用先验知识,并采用特征预缩放和多模态AdaLN技术来提升跨模态兼容性,以较低的训练成本实现了优异的性能。

创新点:
提出多模态预热策略,利用先验知识扩展模型能力。 引入特征预缩放和多模态AdaLN技术,解决跨模态兼容性挑战。 在多个图像和视频理解和生成基准测试中,以有限的训练成本实现了与先进统一模型相媲美的性能。

扫码添加小享,回复“流行模型”
免费获取全部论文+开源代码
