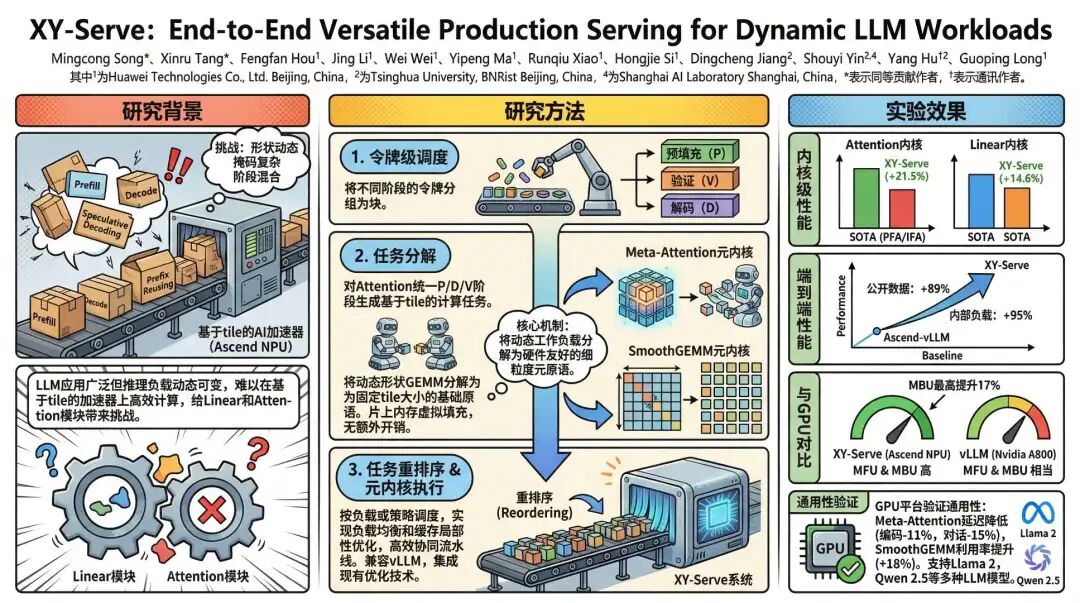
在大模型推理系统中,输入/输出长度高度动态、注意力掩码结构复杂多变、Prefill/Decode/Verify 阶段混合调度等问题,正严重制约 AI 加速器(尤其是华为昇腾 NPU等基于分块(tile-based)编程模型的专用芯片)的吞吐效率。面对行业对低延迟、高性价比推理服务的迫切需求,华为与清华大学联合团队推出 XY-Serve —— 一个原生适配昇腾 NPU、端到端的通用 LLM 推理系统。
其核心成果令人瞩目:在昇腾 NPU 上,端到端吞吐量最高提升 95% ;Linear 算子平均提速 14.6% ,Attention 算子平均提速 21.5% ,甚至在 MFU(模型计算利用率)和 MBU(内存带宽利用率)上与 NVIDIA A800 GPU 持平,部分场景下 MBU领先高达 17% 。

XY-Serve 如何实现这一突破?其背后的技术创新与产业价值,值得每一位关注 AI 基础设施的人深入理解。
核心看点
XY-Serve 直面 LLM 生产部署中的“动态性”挑战:用户请求的输入输出长度千差万别,而Prefix Reusing(前缀复用)、Speculative Decoding(推测解码)、SplitFuse(分块融合)等先进优化技术在提升理论效率的同时,却进一步加剧了计算负载的不规则性,导致传统推理框架在 AI 加速器上效率骤降。
为解决这一核心矛盾,XY-Serve 提出了一套“硬件-算法-系统”协同的创新方案。它通过任务分解与重排序机制,将高度动态的 Prefill(预填充)、Decode(解码)和 Verify(验证)三阶段工作负载,统一抽象为一系列细粒度、硬件友好的元原语(meta-primitives)。在此基础上,团队分别设计了Meta-Attention和SmoothGEMM两大核心算子,实现了对任意动态形状的高效、无缝支持。该技术不仅在昇腾 NPU 上创下性能新高,其通用设计理念也成功在 GPU 平台复现,展现了强大的跨平台潜力。
研究背景

当前主流的 LLM 推理系统普遍面临“动态性困境”。传统的推理引擎,如基于SIMT(单指令多线程)架构的 GPU,可通过硬件级的线程屏蔽机制优雅地处理动态负载。然而,以华为昇腾 NPU为代表的分块式 AI 加速器,其计算单元以固定尺寸的数据块(tile)为单位进行处理。一旦输入矩阵的形状不匹配预设的分块尺寸,就必须引入复杂的填充(padding),这不仅浪费计算资源,还会产生额外的内存开销,严重拖累性能。

更棘手的是,现代推理优化技术本身就在制造动态性。Prefix Reusing通过复用缓存中的历史K/V Cache(键值缓存)来加速请求处理,但这使得每次 Prefill 的输入长度变得不可预测。Speculative Decoding则引入了全新的 Verify 阶段,它需要处理一个动态长度的待验证 token 序列和一个结构复杂的掩码,完全不同于标准的因果掩码。这些技术的叠加,使得一个推理批次内可能同时存在 Prefill、Decode 和 Verify 三种截然不同的计算模式,传统的“分而治之”策略(为每种模式编写独立内核)变得极其低效且难以维护。

XY-Serve 的创新切入点,正是在于解耦。它不再试图为每一种可能的动态组合编写专属内核,而是构建一个统一的抽象层,将所有动态性“消化”在内核之外,暴露出规整、高效、可并行的计算任务给底层硬件。
核心贡献

1. 任务分解与重排序:构建硬件友好的统一抽象
XY-Serve 首先通过Token-wise Scheduling(按 Token 调度)将用户请求拆解为细粒度的 token 块,并混合 Prefill、Decode 和 Verify 的 token。随后,Task Decomposition(任务分解)模块将这些动态的计算负载(无论是 Attention 还是 Linear)逻辑性地拆解成一系列固定尺寸的元原语(meta-primitives),物理数据布局无需任何改动。例如,对于任意形状的 GEMM,它被分解为一组固定 tile size 的基本 GEMM 单元。分解后,Task Reordering(任务重排序)模块会对这些单元进行智能调度,通过对称轮询(symmetrical round-robin)等策略将计算负载均衡地分配给各个 AI 核心,最大化硬件并行效率。

2. Meta-Attention:统一处理所有动态 Attention 场景
团队设计了Meta-Attention内核,它将所有 Attention 计算统一为 GEMM-Softmax-GEMM 的基本模式。无论输入来自 Prefill、Decode 还是复杂的 Verify 阶段,内核都无需区分。针对昇腾 NPU独特的Cube Core(矩阵计算单元)与Vector Core(向量计算单元)分离的架构,Meta-Attention 实现了精巧的分块式 Cube-Vector 协同流水线。它能根据序列长度动态选择三阶段或四阶段流水,甚至为纯 Decode 任务设计了专用的两阶段流水线,将 QK 计算移至 Vector Core 并与 Softmax 融合,从而有效缓解了 Decode 阶段的内存瓶颈。此外,它通过按行动态生成推测掩码的方式,高效支持了任意长度的Speculative Decoding。实验证明,其 Attention 内核性能平均超越现有 SOTA 库 21.5% 。
3. SmoothGEMM:虚拟填充实现任意形状的高效支持
对于 Linear 模块中的 GEMM 操作,XY-Serve 提出了SmoothGEMM方案。其核心是片上虚拟填充(virtual padding):在片上缓冲区中按固定 tile size 分配内存,但在从 HBM(高带宽内存)读取和写回数据时,仅操作有效数据区域。这样,计算单元始终处理的是规整的矩阵乘法,享受极致优化,而动态形状带来的“毛刺”被巧妙地在内存访问层屏蔽。结合离线性能调优(offline profiling)为固定形状生成最优的核间任务分配策略(如swizzling),SmoothGEMM 不仅支持任意输入长度,还将 Linear 性能平均提升 14.6% 。

在端到端评估中,XY-Serve 在公开数据集上相比 Ascend-vLLM,QPS 最高提升 89% ;在内部工业级负载上,性能提升更是高达 95% 。更值得一提的是,当将 Meta-Attention 和 SmoothGEMM 迁移到 GPU 平台后,依然能获得11%-15%的延迟降低和18%的硬件利用率提升,充分验证了其方法的通用性。
行业意义
XY-Serve 的推出,为国产 AI 加速器(如昇腾 NPU)的生态建设注入了强劲动力。它提供了一套系统性的方法论,证明了通过精巧的软硬件协同设计,完全可以克服分块式架构在处理动态负载时的固有劣势,甚至达到与顶尖 GPU 比肩的效率。这对于推动我国人工智能基础设施的自主可控具有重要战略意义。
其设计理念——将动态性抽象为规整的元任务——为整个 LLM 推理系统领域提供了新的思路。它不仅完美兼容Prefix Reusing、PagedAttention、Speculative Decoding等前沿优化技术,更为未来可能出现的、更复杂的动态调度策略(如解耦式 LLM 部署中的角色动态切换)奠定了坚实基础。可以预见,XY-Serve 所倡导的这种“面向动态性而生”的推理系统架构,将有力推动大模型推理服务向更高性能、更低成本、更广普及的方向变革。
论文标题:《XY-Serve: End-to-End Versatile Production Serving for Dynamic LLM Workloads》
论文链接:https://doi.org/10.1145/3760250.3762228
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对










