> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对

引言:当模型能“记住整本书”,它才能真正“思考”
在大语言模型(LLM)竞赛日益白热化的今天,上下文长度早已不再是衡量模型能力的唯一指标。从32K到128K,再到百万甚至千万级token窗口,硬件和架构的突破让“看得更长”成为可能。然而,“看得长”不等于“想得深”——许多模型在面对超长输入时,依然难以完成需要跨段落、跨文档、多跳推理的复杂任务。它们或许能定位“针”,却无法编织“线”,更谈不上构建“网”。
近日,阿里通义实验室发布了其最新研究成果 QwenLong-L1.5。这项研究没有聚焦于底层架构创新,而是提出了一套端到端、系统化的后训练(Post-Training)方案,成功地将一个30B参数的基础模型,训练至在多项长上下文推理基准上性能直逼GPT-5和Gemini-2.5-Pro的顶尖水平。还通过其独创的“记忆增强智能体(Memory-Augmented Agent)”框架,将推理能力无缝扩展至100万至400万token的超长文档。

本文将深入剖析这项工作,揭示其如何通过高质量合成数据、稳定的强化学习(RL)训练方法以及创新的记忆管理架构,三位一体地攻克长上下文推理的三大核心难题。

论文链接:https://huggingface.co/papers/2512.12967
PaperScope解读:https://www.paperscope.ai/hf/2512.12967
一、研究背景:后训练阶段的“无人区”
当前关于扩展上下文长度的研究,大多集中在预训练和中间训练阶段,例如通过位置编码外推、注意力机制优化等手段来“撑大”模型的窗口。然而,通义实验室的研究团队敏锐地指出,这仅仅是解决了“容量”问题。真正的挑战在于“能力”——即模型如何在如此庞大的信息海洋中,有效提取、关联、推理并最终回答复杂问题。
这一能力的缺失,很大程度上源于后训练阶段的系统性空白。现有的开源或商业模型,其长上下文能力往往是预训练窗口扩展后的副产品,缺乏专门为之设计的高质量训练数据和针对性的优化算法。其结果便是,模型虽然能“装下”整本《战争与和平》,但在回答一个需要贯穿全书人物关系和情节发展的多跳问题时,依然显得力不从心。
QwenLong-L1.5正是为了填补这一“无人区”而生。它的目标不是简单地做一个“大胃王”模型,而是要打造一个具备深度理解、全局推理和持久记忆能力的“思考者”。
二、核心创新:三位一体的后训练方案
QwenLong-L1.5的突破并非来自单一技术点,而是一个环环相扣、协同增效的完整体系。它从数据、算法、架构三个层面同时发力,构建了一套可复现、可扩展的长上下文训练范式。
2.1 高质量合成数据:从“找针”到“织网”
如果说模型是“思考者”,那么数据就是它的“思维食粮”。以往的长上下文数据集,如经典的“大海捞针”(Needle in a Haystack, NIAH)任务,主要测试模型能否在海量文本中定位到一个孤立的事实。这更像是对模型感知能力的考验,而非推理能力。
QwenLong-L1.5彻底改变了数据构建的范式。其核心思想是:将长文档解构成原子事实(atomic facts)及其背后的关系,再通过程序化的方式,合成出需要多跳(multi-hop)推理才能解答的复杂问题。
具体而言,团队设计了一套精密的合成流水线(见图1):
-
构建语料库:汇集了来自开源代码库、学术论文、专业文档、经典文学和对话数据等五大类、总计92亿token的高质量文本。 -
合成问答对:针对不同任务类型,采用三种核心技术:
-
基于知识图谱(KG):从文档中抽取三元组构建跨文档知识图,再采样复杂的多跳路径来生成问题,例如因果分析、时序推理等。 -
基于结构化表格(Structured Tabular Data Engine):将分散在多个文档中的统计表格聚合为一个统一的数据表,然后通过NL2SQL生成复杂的数值计算问题,如“计算2013年电力部门与2014年燃气部门运营成本的差额”。 -
多智能体自进化框架(MASE):由三个LLM智能体(提议者、求解者、验证者)协同工作,从简单问题开始,不断迭代生成更复杂、更多样化的通用长上下文任务,如观点分析、长上下文学习等。 -
严格验证:通过“知识接地检查”和“上下文鲁棒性检查”两大关卡,确保生成的问题必须依赖于特定上下文,且答案不会因上下文扰动而失效。
这套方法最终产出了14.1K个高质量、高难度的训练样本,其平均输入长度(34K tokens)和最大长度(近120K tokens)远超前代模型,为模型的深度训练奠定了坚实基础。

2.2 稳定的强化学习:在长上下文的“风暴”中驾驭训练
在长上下文场景下进行强化学习(RL)训练,如同在惊涛骇浪中驾驶一艘巨轮——不稳定性是最大的敌人。由于上下文过长,正确与错误的推理路径往往高度相似(ROUGE-L相似度高达45.37%,远高于短上下文任务的27.71%),这使得奖励信号极易被错误分配,导致训练崩溃。
为了解决这一难题,QwenLong-L1.5提出了一系列创新的RL策略:
-
任务平衡采样与任务特异性优势估计:传统RL训练中,不同任务的数据分布差异会导致奖励估计偏差。QwenLong-L1.5在采样时确保每个批次中各类任务(如多选、多跳推理、数值计算等)的样本数量均衡,并在计算优势函数(Advantage)时,仅在同类任务内部进行标准化,从而为不同任务提供了更精准、更公平的梯度信号。 -
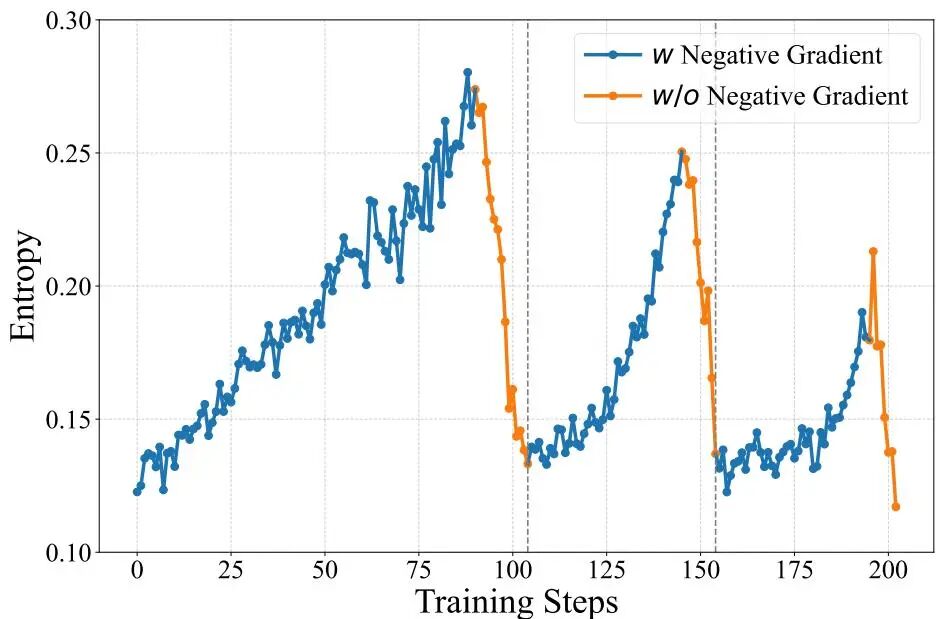
自适应熵控策略优化(AEPO):这是该工作的另一大亮点。AEPO算法动态监控模型在训练过程中的策略熵(即输出的随机性)。当熵过高(模型过于“放飞自我”)时,它会屏蔽掉负奖励样本的梯度,只保留正样本进行优化,起到“收缩”探索范围的作用;反之,当熵过低(模型陷入“思维定式”)时,它又会重新引入负梯度,以防止模型“躺平”并鼓励其继续探索。这种动态平衡机制(见图2)极大地提升了长上下文RL训练的稳定性,使得模型能够持续、稳定地在越来越长的序列上进行优化。
2.3 记忆增强架构:突破物理窗口的极限
即使将上下文窗口扩展到128K或256K,面对动辄百万甚至千万token的书籍、代码库或法律文件,模型依然会“力不从心”。QwenLong-L1.5没有选择无止境地堆砌算力去追求更大的窗口,而是另辟蹊径,引入了记忆增强智能体(Memory Agent)。
这个框架将超长文档推理任务重新定义为一个序列决策过程。模型不再试图一次性“吞下”所有内容,而是像一个勤奋的读者一样——分块(chunk)。在处理每个块时,它会基于当前块的内容、原始问题的核心以及历史记忆,来更新其内部的“记忆状态”(memory state),并生成一个“导航计划”(navigational plan),以指导其在下一个块中重点关注哪些信息。

经过对所有块的迭代处理,所有相关信息被“折叠”(fold)进一个紧凑的记忆表示中。最后,模型基于这个凝聚了全局信息的记忆,生成最终的答案。整个过程通过多阶段融合RL训练,将单次通过推理(single-pass reasoning)和迭代式记忆处理(iterative memory-based processing)的能力无缝融合到一个统一的模型中。

三、实验结果:全面超越,直指标杆
QwenLong-L1.5的性能提升是全方位且显著的。在六大主流长上下文推理基准(如Frames, MRCR, CorpusQA等)上,其平均得分达到71.82,相比其基线模型Qwen3-30B-A3B-Thinking-2507(61.92)提升了9.9分。
尤其值得关注的是,其性能已经比肩甚至超越了多个顶尖的轻量级推理模型,如DeepSeek-R1-0528、Gemini-2.5-Flash-Thinking,并且与GPT-5和Gemini-2.5-Pro等旗舰模型的性能相当。在MRCR(多针检索)基准上,它更是取得了82.99分的SOTA成绩,充分证明了其在复杂信息检索和消歧能力上的强大实力。

更进一步,在1M至4M token的超长上下文任务上,QwenLong-L1.5的记忆智能体框架大放异彩。相比基线模型的单次推理模式,其性能提升了15.26分;相比基线模型自身的记忆智能体版本,也高出9.48分。这清晰地表明,其提出的长上下文数据合成与RL训练方法,不仅能提升单次推理能力,还能有效赋能记忆管理能力。
值得一提的是,这种长上下文能力的提升并非“偏科”,而是带来了广泛的泛化效益。在科学推理(AIME25, GPQA-Diamond)、工具使用智能体(BFCL-V4)以及长对话记忆(LongMemEval)等通用领域,QwenLong-L1.5均取得了显著进步。特别是在LongMemEval上,15.6分的巨大提升直接验证了其在对话场景下的核心价值——真正记住并理解用户的长期意图。

四、总结与展望
这项工作不仅极大地提升了开源模型的长上下文能力,其背后的方法论——从数据合成到训练稳定性的精细调控,再到精心设计的记忆增强框架——也为整个社区提供了宝贵的参考。未来,团队计划将这一框架扩展到多模态、长输出生成(如报告撰写)等更广阔的场景,并探索构建一个“数据飞轮”,让经过训练的强大模型反过来生成更高质量的训练数据,形成自我进化的良性循环。
对于开发者和研究者而言,QwenLong-L1.5不仅是一个强大的工具,更是一份详尽的“食谱”,指引着如何亲手“烹饪”出具备深度长上下文推理能力的下一代语言模型。
-- 完 --










